Wprowadzenie
System Comarch ERP Enterprise składa się z kilku baz danych. Struktura każdej używanej bazy danych w Comarch ERP Enterprise jest taka sama.
Grupa docelowa
- Administratorzy
- Programiści z zaawansowaną wiedzą
Definicje pojęć
Obiekt biznesowy – model danych Comarch ERP Enterprise opiera się na obiektach biznesowych. Zawierają one tylko dane i dlatego są również określane jako kontenery danych. Przetwarzanie tych danych jest realizowane za pomocą logiki aplikacji, która przeprowadza transformacje stanu danych. Odpowiednie fragmenty rzeczywistości zostały zamodelowane za pomocą obiektów biznesowych, uwzględniając w miarę możliwości trzecią postać normalną, tj. jednostki zostały utworzone z jak najmniejszą redundancją, co skutkowało dużą liczbą obiektów biznesowych. Opis ich struktury jest obiektem deweloperskim. Instancja obiektu biznesowego jest wyrażeniem opisu przechowywanego jako obiekt deweloperski. Persistence service może odczytywać, zapisywać i usuwać instancje obiektów biznesowych. Jego opis jest często dostępny w znormalizowanej formie. Rzeczywista zmienna biznesowa może być opisana przez więcej niż jeden obiekt biznesowy, przy czym tylko jeden z nich zawsze istnieje jako główny. Z tego powodu obiekty biznesowe są grupowane w jednostkę biznesową, w której jeden specjalnie oznaczony działa jako przedstawiciel grupy. Ten przedstawiciel i jego grupa stają się jednostką biznesową.
Baza danych – jest rodzajem schematu bazy danych. Baza danych zawiera dane, które są ustrukturyzowane zgodnie z powiązanym schematem bazy danych.
Schemat bazy danych – zawiera informacje strukturalne obiektów, które mogą być przechowywane w bazie danych.
Opis obiektu – zawiera metadane do generowania Bussines object, Part lub View.
Part – są kontenerami danych dla danych strukturalnych. Part może być używana jako złożony atrybut w obiekcie biznesowym lub w części. Part nie mogą być przechowywane bezpośrednio w bazie danych, a jedynie osadzone w obiekcie biznesowym.
Tabela – obiekt biznesowy jest przechowywany w bazie danych w jednej lub kilku tabelach.
Opis tabeli – służy jako szablon dla definicji tabeli i tabeli. Każdy obiekt biznesowy ma opis tabeli. Schemat tabeli, w której przechowywane są instancje obiektu biznesowego, może pochodzić z opisu tabeli. Opis tabeli jest generowany na podstawie opisu obiektu.
Definicja tabeli – opisuje schemat tabeli. Definicja tabeli zawiera niezależny od bazy danych opis kolumn i indeksów tabeli.
Opis
Podstawy
Baza danych systemu Comarch ERP Enterprise składa się z zestawu tabel i widoków. Tabela posiada schemat, który opisuje jej strukturę oraz zawartość, która jest ustrukturyzowana zgodnie ze schematem. Widok ma tylko jeden schemat. Zawartość widoku jest obliczana na podstawie innych tabel. Schemat bazy danych składa się ze schematów tabel i widoków w niej zawartych.
Każda tabela i każdy widok znajduje się w dokładnie jednej bazie danych. Każda operacja może uzyskać dostęp tylko do tabel i widoków w dokładnie jednej bazie danych. Każda operacja wpływa tylko na konkretną bazę danych.
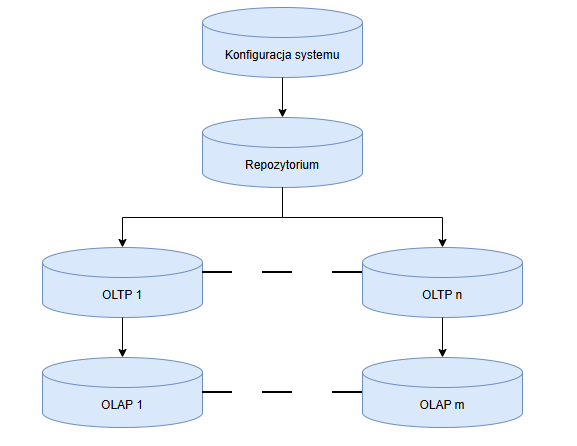
Każda baza danych Comarch ERP Enterprise jest podzielona na kategorie w zależności od jej zawartości i przeznaczenia:
- Konfiguracja systemu
- Repozytorium
- OLTP
- OLAP
Schemat jest identyczny dla wszystkich baz danych o tym samym typie zawartości w spójnym systemie Comarch ERP Enterprise (zwanym dalej „systemem ERP”).
Każda tabela i każdy widok w bazie danych zostały utworzone przez system ERP przy użyciu obiektów deweloperskich. Dane zapisane w obiektach deweloperskich w pełni opisują schemat obiektu bazy danych.
Zmiany schematu bazy danych
Tworzenie schematu bazy danych
Obiekt biznesowy składa się z atrybutów, indeksów, relacji i innych danych. Typy danych atrybutów obiektu biznesowego mogą składać się z prostych typów danych, takich jak ciągi lub liczby, lub złożonych typów danych, takich jak tablice (o stałej długości) i części (Part). Wszystkie te dane są podsumowane w opisie obiektu biznesowego.
Opis obiektu jest wersjonowany w repozytorium jako obiekt deweloperski, tzn. jeśli opis obiektu jest zawarty w zadaniu deweloperskim, otrzymuje nowy numer wersji.
| Opis obiektu Item | |
| Nazwa atrybutu | Typ danych |
| guid | Guid |
| number | String (10) |
| description | String (200) |
| size | Array [3] Decimal(10,2) |
| value | PartDomesticAmount |
| Nazwa indeksu | Definicja indeksu |
| PrimaryKey | PrimaryKey(guid) |
| ByNumber | SecondaryKey(number) |
Opis tabeli jest generowany z opisu obiektu w procesie rozwoju za pomocą polecenia crtbo. Opis tabeli składa się z atrybutów i indeksów i służy jako szablon dla schematu bazy danych tabeli. Wszystkie atrybuty opisu tabeli mają proste typy danych. Wszystkie złożone atrybuty opisu obiektu, takie jak części i tablice, są konwertowane na proste atrybuty w opisie tabeli. W przypadku części, oprócz atrybutów części tworzony jest atrybut Boolean, aby wskazać, czy część została ustawiona, czy null.
W opisie tabeli każdy atrybut może być identyfikowany przez ścieżkę atrybutu lub nazwę kolumny. W ścieżce atrybutu atrybuty złożone są oddzielone kropkami ., a indeks pól tablicy jest ujęty w nawiasy kwadratowe []. Nazwa kolumny jest obliczana na podstawie ścieżki atrybutu, ale nie zawiera znaków specjalnych i dlatego może być również używana jako nazwa kolumny w schemacie bazy danych tabeli. Nazwa tabeli i nazwy indeksów są również konwertowane na notację, która może być użyta w schemacie bazy danych. Opis tabeli jest używany zarówno do generowania tabel bazy danych, jak i podczas uzyskiwania dostępu do tabeli bazy danych. Na przykład ścieżki atrybutów lub nazwy kolumn są używane podczas konwersji OQL na SQL.
Podczas tworzenia opisu tabeli, numer wersji opisu obiektu jest przenoszony do opisu tabeli.
| Opis tabeli ITEM 6.0 | ||
| Ścieżka atrybutu | Nazwa kolumny | Typ danych |
| guid | GUID | Guid |
| number | Number001 | String (10) |
| description | DESCRIPTION | String (200) |
| size[0] | SIZE|0| | Decimal(10,2) |
| size[1] | SIZE|1| | Decimal(10,2) |
| size[2] | SIZE|2| | Decimal(10,2) |
| value | VALUE | boolean |
| value.amount1 | VALUEAMOUNT1 | Decimal(21,6) |
| value.amount12 | VALUEAMOUNT2 | Decimal(21,6) |
| value.amount3 | VALUEAMOUNT3 | Decimal(21,6) |
| value.excact | VALUEEXCACT | byte |
| Nazwa indeksu | Nazwa indeksu bazy danych | Definicja indeksu |
| PrimaryKey | |10O2TVTPE600 | PrimaryKey(GUID) |
| ByNumber | |10O2TVTPE602 | SecondaryKey(NUMBER001) |
W każdej bazie danych, w której generowany jest obiekt biznesowy, definicja tabeli jest również zapisywana w bazie danych w tym samym czasie, w którym tworzona jest tabela bazy danych. Definicja tabeli jest kompletnym opisem schematu tabeli bazy danych, który jest niezależny od używanego systemu zarządzania bazą danych (DBMS). Definicja tabeli pobiera dane schematu z opisu tabeli. Definicja tabeli i aktywna tabela w bazie danych tworzą jednostkę. Schemat aktywnych tabel odpowiada dokładnie danym w definicji tabeli.
| Definicja tabeli Item | |
| Aktywny 6.0Tymczasowy – | |
| Nazwa kolumny | Typ danych |
| Number001 | String (10) |
| DESCRIPTION | String (200) |
| SIZE|0| | Decimal(10,2) |
| SIZE|1| | Decimal(10,2) |
| SIZE|2| | Decimal(10,2) |
| VALUE | boolean |
| VALUEAMOUNT1 | Decimal(21,6) |
| VALUEAMOUNT2 | Decimal(21,6) |
| VALUEAMOUNT3 | Decimal(21,6) |
| VALUEEXCACT | byte |
| Nazwa indeksu bazy danych | Definicja indeksu |
| |10O2TVTPE600 | PrimaryKey(GUID) |
| |10O2TVTPE602 | SecondaryKey(NUMBER001) |
Poniższy proces jest podsumowany od wprowadzenia opisu obiektu do wygenerowania tabeli bazy danych.
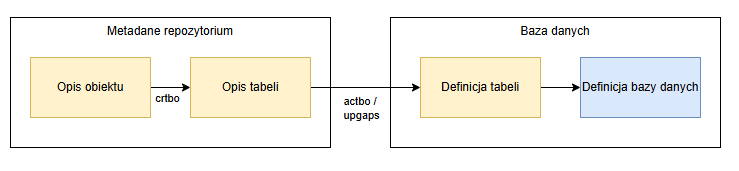
Dla każdego opisu obiektu istnieje dokładnie jeden opis tabeli. Opis tabeli nie musi być zgodny z definicjami tabel w bazach danych. Odchylenia mogą jednak wystąpić tylko wtedy, gdy system jest rozwijany lub gdy aktualizacje oprogramowania nie są w pełni aktywowane. Odchylenia są zatem dozwolone tylko w systemach, w których trwają prace rozwojowe. We wszystkich innych systemach jest to błąd.
Opis tabeli i definicje tabel zawierają również numer wersji opisu obiektu, na podstawie którego zostały utworzone.
Aktywacja zmian schematu bazy danych
Jeśli schemat tabeli bazy danych zostanie zmieniony, dane z poprzednio aktywnej tabeli muszą zostać przeniesione do tabeli z nowym schematem. Każda zmiana schematu bazy danych obiektu biznesowego przebiega zatem w następujący sposób:
- Wygenerowanie tabeli tymczasowej z nowym schematem
- Przeniesienie danych z aktywnej tabeli do tabeli tymczasowej
- Zastąpienie tabeli aktywnej tabelą tymczasową i zapisanie definicji tabeli
Po wygenerowaniu tabeli tymczasowej definicja tabeli nie jest jeszcze zmieniana w odniesieniu do schematu bazy danych. Jednak w definicji tabeli jest odnotowane, że została wygenerowana tabela tymczasowa określonej wersji. Tabela tymczasowa ma przedrostek QC przed nazwą aktywnej tabeli.
Oprócz tabeli tymczasowej istnieje również tabela błędów, która ma schemat aktywnej tabeli. Wszystkie rekordy danych, których nie można było przenieść do tabeli tymczasowej, są zapisywane w tabeli błędów.
Podczas przesyłania danych z aktywnej tabeli do tabeli tymczasowej, dane mogą być uzupełniane lub zmieniane za pomocą aktualizacji. Ten program aktualizacji jest wykonywany automatycznie za każdym razem, gdy dane są przesyłane. Transfer danych z aktywnej tabeli do tabeli tymczasowej jest określany poniżej jako konwersja.
Po całkowitym przekonwertowaniu zawartości aktywnej tabeli do nowej tabeli tymczasowej, aktywna tabela może zostać zastąpiona przez tabelę tymczasową bez utraty danych. Tabela tymczasowa jest aktywowana w następujący sposób:
- Usunięcie aktywnej tabeli
- Zmiana nazwy tabeli tymczasowej na aktywną
- Zastąpienie definicji tabeli
Przykład zmiany schematu danych
Poniższy przykład opisuje sposób przeprowadzania zmiany schematu danych w systemie ERP. W tym przykładzie nowy atrybut type jest dodawany do obiektu biznesowego Item. Najpierw wygenerowano nowy opis tabeli na podstawie zmienionego opisu obiektu.
| Opis tabeli ITEM 3.0 | ||
| Ścieżka atrybutu | Nazwa kolumny | Typ danych |
| guid | GUID | Guid |
| number | Number001 | String (10) |
| type | TYPE001 | Short |
| Nazwa indeksu | Nazwa indeksu bazy danych | Definicja indeksu |
| PrimaryKey | |10O2TVTPE600 | PrimaryKey(GUID) |
| ByNumber | |10O2TVTPE602 | SecondaryKey(NUMBER001) |
Definicja tabeli i aktywna tabela bazy danych, na której ma zostać przeprowadzona zmiana schematu danych, nadal mają stary schemat.
| Definicja tabeli Item | |
| Aktywny 2.0Tymczasowy – | |
| Nazwa kolumny | Typ danych |
| GUID | Guid |
| Number001 | String (10) |
| Nazwa indeksu bazy danych | Definicja indeksu |
| |10O2TVTPE600 | PrimaryKey(GUID) |
| |10O2TVTPE602 | SecondaryKey(NUMBER001) |
| ITEM | |
| GUID12A545417BF4… | NUMBER001VSD0780VSD0781… |
Tabela tymczasowa jest generowana w bazie danych (np. przez crtbo, upgaps, rgzbo) przy użyciu nowego opisu tabeli. Tymczasowa tabela ma schemat nowego opisu tabeli. Nowy schemat nie jest jeszcze przenoszony do definicji tabeli, ale początkowo zapisywany jest tylko numer wersji nowej tabeli.
| Definicja tabeli Item | |
| Aktywny 2.0Tymczasowy 3.0 | |
| Nazwa kolumny | Typ danych |
| GUID | Guid |
| Number001 | String (10) |
| Nazwa indeksu bazy danych | Definicja indeksu |
| |10O2TVTPE600 | PrimaryKey(GUID) |
| |10O2TVTPE602 | SecondaryKey(NUMBER001) |
| ITEM | |
| GUID12A545417BF4… | NUMBER001VSD0780VSD0781… |
| QCITEM | ||
| GUID | NUMBER001 | TYPE001 |
Definicja tabeli, tabele aktywne i tymczasowe po wygenerowaniu tabeli tymczasowej
Po wygenerowaniu tabeli tymczasowej dane (np. za pomocą actbo, cnvbo, upgaps, rgzbo) są przenoszone z tabeli aktywnej do tabeli tymczasowej.
Przesyłanie danych z aktywnej tabeli do tabeli tymczasowej:
| Definicja tabeli Item | |
| Aktywny 2.0Tymczasowy 3.0 | |
| Nazwa kolumny | Typ danych |
| GUID | Guid |
| Number001 | String (10) |
| Nazwa indeksu bazy danych | Definicja indeksu |
| |10O2TVTPE600 | PrimaryKey(GUID) |
| |10O2TVTPE602 | SecondaryKey(NUMBER001) |

Po transferze tabela tymczasowa zawiera wszystkie dane z tabeli aktywnej i może je teraz zastąpić (np. za pomocą actbo, rgzbo lub upgaps). Z tego powodu aktywna tabela jest usuwana, a nazwa tabeli tymczasowej jest zmieniana na nazwę tabeli aktywnej. Jednocześnie definicja tabeli jest zmieniana na aktualną wersję.
| Definicja tabeli Item | |
| Aktywny |
|
| Nazwa kolumny | Typ danych |
| GUID | Guid |
| Number001 | String (10) |
| TYPE001 | Short |
| Nazwa indeksu bazy danych | Definicja indeksu |
| |10O2TVTPE600 | PrimaryKey(GUID) |
| |10O2TVTPE602 | SecondaryKey(NUMBER001) |
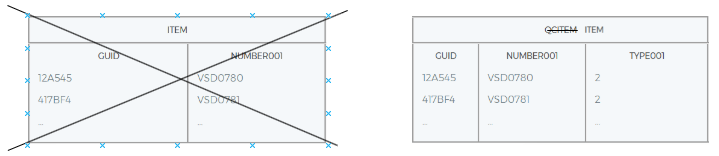
Po zmianie schematu danych definicja tabeli i tabela mają schemat nowego opisu tabeli.
| Definicja tabeli Item | |
| Aktywny 3.0Tymczasowy |
|
| Nazwa kolumny | Typ danych |
| GUID | Guid |
| Number001 | String (10) |
| TYPE001 | Short |
| Nazwa indeksu bazy danych | Definicja indeksu |
| |10O2TVTPE600 | PrimaryKey(GUID) |
| |10O2TVTPE602 | SecondaryKey(NUMBER001) |
| ITEM | ||
| GUID12A545
417BF4 … |
NUMBER001VSD0780
VSD0781 … |
TYPE0012
2 … |
Nowa aktywna tabela i definicja tabeli
Zależność czasowa
Obiekty biznesowe mogą być opcjonalnie zależne od czasu. W przypadku obiektów biznesowych zależnych od czasu, atrybuty validFrom i validUntil są automatycznie tworzone podczas generowania schematu obiektu biznesowego.
- Atrybut validFrom zawiera datę od której instancja obiektu biznesowego jest ważna. Atrybut validFrom jest dołączany jako atrybut klucza do wszystkich unikalnych kluczy, gdy obiekt biznesowy jest generowany w bazie danych.
- Atrybut validUntil zawiera od której instancja obiektu biznesowego stała się nieważna.
| Opis obiektu Item | |
| Nazwa atrybutu | Typ danych |
| guid | Guid |
| number | String (10) |
| validFrom | Timestamp |
| validUntil | Timestamp |
| Nazwa indeksu | Definicja indeksu |
| PrimaryKey | PrimaryKey(guid) |
| ByNumber | SecondaryKey(number) |

| Opis tabeli ITEM 3.0 | ||
| Ścieżka atrybutu | Nazwa kolumny | Typ danych |
| guid | GUID | Guid |
| number | NUMBER001 | String (10) |
| description | DESCRIPTION | String (200) |
| validFrom | VALIDFROM | TimeStamp |
| validUntil | VALIDUNTIL | TimeStamp |
| Nazwa indeksu | Nazwa indeksu bazy danych | Definicja indeksu |
| PrimaryKey | |10O2TVTPE600 | PrimaryKey(GUID) |
| ByNumber | |10O2TVTPE602 | SecondaryKey(NUMBER001) |
| Definicja tabeli Item | |
| Nazwa kolumny | Typ danych |
| GUID | Guid |
| Number001 | String (10) |
| VALIDFROM | TimeStamp |
| VALIDUNTIL | TimeStamp |
| Nazwa indeksu bazy danych | Definicja indeksu |
| |10O2TVTPE600 | PrimaryKey(GUID, VALIDFROM) |
| |10O2TVTPE602 | SecondaryKey(NUMBER001, VALIDFROM) |
Przykład obiektu biznesowego zależnego od czasu
Ponieważ atrybut validFrom został dołączony do unikalnych kluczy, baza danych nie może już sprawdzać, czy unikalny klucz jest naprawdę unikalny. Niedozwolone jest na przykład, aby klucz biznesowy był inny w dwóch wersjach identycznego obiektu biznesowego.
Referencje do obiektów
Atrybuty dowolnego typu i dowolnej liczby mogą być używane w kluczu podstawowym obiektu biznesowego. Wartości atrybutów klucza głównego określonego obiektu biznesowego są zakodowane jako sekwencja bajtów w SAS. Długość tej sekwencji bajtów zależy od liczby i rozmiaru atrybutów klucza głównego i dlatego jest bardzo różna. Ta sekwencja bajtów jest również określana jako klucz podstawowy obiektu biznesowego.
Obiekty biznesowe mogą mieć dowolny klucz. Nie jest zatem możliwe bezpośrednie odwołanie z obiektu biznesowego do dowolnego obiektu biznesowego, który nie jest znany w momencie projektowania. Opcją odniesienia może być klucz podstawowy obiektu biznesowego, do którego należy się odwołać. Może on jednak mieć dowolną długość.
Odniesienia do obiektów rozwiązują ten problem. Jeśli klucz podstawowy jest dłuższy niż zdefiniowana długość, wówczas odwołanie do obiektu tworzy się pośrednio. Odwołanie do obiektu jest używane jako odniesienie. Jeśli odwołanie do obiektu ma zostać rozwiązane, oryginalny klucz podstawowy jest określany dla odwołania do obiektu.
Jeśli obiekt z długim kluczem podstawowym jest ponownie wywoływany przez odniesienie do obiektu, klucz podstawowy ma przypisany unikalny identyfikator w obiekcie biznesowym:
com.cisag.sys.kernel.obj.ObjectReference
i jest przechowywany. Odniesienia do obiektów są używane na przykład w tabelach NLS atrybutów możliwych do zlokalizowania.
Klucze podstawowe i odniesienia do obiektów nie mogą być obliczane ani rozwiązywane za pomocą narzędzi bazy danych. Z tego powodu nie jest możliwe utworzenie JOIN w SQL poprzez odwołanie do obiektu.
Podczas projektowania modelu danych należy zatem zadbać o to, aby obiekty biznesowe miały klucze podstawowe, które są jak najkrótsze (np. Guid), aby uniknąć tworzenia odniesień do obiektów.
SBLOBs
System ERP rozpoznaje dwa typy obiektów BLOB (Binary Large OBjects):
- BLOB (Binary Large OBjects) – zawartość BLOB jest całkowicie ładowana do pamięci głównej przez Persistence service podczas otwierania obiektu biznesowego. Obiekty BLOB są zapisywane bezpośrednio w tabeli, w której zapisywany jest również obiekt biznesowy.
- SBLOB (Streamable Binary Large OBjects) – zawartość SBLOB nie jest ładowana przez Persistence service podczas ładowania obiektu biznesowego, ale tylko w małych blokach, gdy zawartość jest dostępna. Zawartość SBLOB jest przechowywana w oddzielnym obiekcie biznesowym:com.cisag.sys.kernel.obj.SBLOBFragmentprzechowywanym w oddzielnym obiekcie biznesowym. SBLOB mają między innymi ograniczenia dotyczące zarządzania transakcjami. Z tego powodu SBLOB powinny być używane tylko w ramach silnika systemu ERP.
Przechowywanie BLOB
KnowledgeStore wymaga BLOB-ów o nieograniczonej długości. Te obiekty BLOB są przechowywane w tabeli BLOB_STORAGE. Tabela ta nie należy do żadnego obiektu biznesowego. Nie można uzyskać dostępu do tej tabeli bezpośrednio za pomocą żadnego publicznego interfejsu programowania.
Używanie Knowledge Store może powodować, iż tabela BLOB_STORAGE może rosnąć. Należy o tym pamiętać podczas konfigurowania systemu bazy danych.
Atrybuty możliwe do zlokalizowania
Atrybut string może być oznaczony jako lokalny w systemie ERP. W takim przypadku atrybut ten może nie tylko przechowywać wartość, ale także tłumaczenie dla każdego skonfigurowanego języka bazy danych. Każda baza danych systemu ERP ma dokładnie jeden język wiodący i dowolną liczbę języków dodatkowych. Wartość atrybutu w języku podstawowym może być odczytywana i zapisywana szczególnie efektywnie. Wartości w językach drugorzędnych są przechowywane w oddzielnych obiektach biznesowych (tabela NLS).
| Opis obiektu Item | |
| Nazwa atrybutu | Typ danych |
| guid | Guid |
| number | String (10) |
| description | String (65) (ML) |
| Nazwa indeksu | Definicja indeksu |
| PrimaryKey | PrimaryKey(guid) |
| ByNumber | SecondaryKey(number) |
| Opis obiektu Item_DESCRIPTION | |
| Nazwa atrybutu | Typ danych |
| objectReference | Byte[54] |
| language | String (4) |
| X_guid | Guid |
| value | String (65) |
| Nazwa indeksu | Definicja indeksu |
| PrimaryKey | PrimaryKey(objectReference,language) |
| ByObjectPk | SecondaryKey(X_guid,language) |
Przykład obiektu z atrybutem umożliwiającym lokalizację
Tabela NLS zawiera rekord danych z tłumaczeniem atrybutu zlokalizowanego dla każdego rekordu danych w tabeli głównej i dla każdego języka dodatkowego. Tabela NLS jest automatycznie generowana przez narzędzie crtbo, gdy generowany jest obiekt biznesowy z atrybutem lokalizacji. Atrybuty wygenerowanej tabeli NLS pochodzą z obiektu głównego:
| Atrybut | Opis |
| objectReference | Odniesienie do obiektu jest unikalną identyfikacją głównego obiektu. |
| validFrom | Jeśli główny obiekt jest zależny od czasu, tabela NLS zawiera również datę obowiązywania, dzięki czemu wartości atrybutu lokalnego mogą być również zapisywane jako zależne od czasu. Jeśli obiekt nie jest zależny od drugiego, tabela NLS nie ma atrybutu validFrom. |
| language | Tabela NLS zawiera tłumaczenie atrybutu zlokalizowanego dla każdego dodatkowego języka w bazie danych. Atrybut language określa, które tłumaczenie zawiera atrybut value. |
| X_pk1, …, X_pknKlucz główny obiektu głównego | Klucz główny obiektu głównego jest zapisywany dla każdej wartości atrybutu lokalnego w tabeli NLS, dzięki czemu można użyć JOIN między tabelą główną a tabelami NLS. |
| value | Tłumaczenie zlokalizowanego atrybutu dla języka dodatkowego określonego w atrybucie language. |
Gdy zapisywana jest nowa instancja obiektu biznesowego, tworzony jest rekord danych dla każdego języka pomocniczego bazy danych we wszystkich tabelach NLS należących do tego obiektu. Jeśli instancja obiektu biznesowego zostanie usunięta, rekordy danych należące do tego obiektu zostaną usunięte z tabel NLS. Im więcej języków dodatkowych jest tworzonych w bazie danych, tym bardziej czasochłonne jest tworzenie i usuwanie obiektów biznesowych z tak zlokalizowanymi atrybutami.
| Item | ||
| guid | number | description |
| A1B4 | 0001 | Papier |
| 4CA8 | 0002 | Śrubokręt |
| Item_DESCRIPTION |
|||
| objectReference | language | X_guid | value |
| D468A1B4 | en | A1B4 | Paper |
| D468A1B4 | it | A1B4 | Carta |
| D4684CA8 | en | 4CA8 | Screw |
| D4684CA8 | it | 4CA8 | Cacciavite |
Przykład zawartości tabeli ze zlokalizowanym atrybutem.
Jeśli obiekt biznesowy ma być odczytywany w języku podstawowym, dostęp do tabeli NLS nie jest konieczny. Jeśli jednak obiekt biznesowy ma być odczytywany w języku dodatkowym, wartość jest odczytywana z odpowiedniej tabeli NLS dla każdego atrybutu, który można zlokalizować. Dostęp do odczytu wartości w języku dodatkowym jest zatem bardziej złożony niż w języku podstawowym.
Mapowanie typów danych systemu ERP
Mapowanie typów danych w Comarch ERP Enterprise zależy od używanego systemu DBMS. Gdy tabela bazy danych jest generowana z opisu tabeli, typy danych kolumn są mapowane do bazy danych w następujący sposób:
| Typ danych | Oracle 9i/10g | SQL-Server | DB2/400 | PostgreSQL |
| binary(l) | RAW(l) | VARBINARY(l) | VARCHAR(l) FOR BITDATA | BYTEA |
| blob | BLOB | VARBINARY(MAX) | BLOB(16M) | BYTEA |
| boolean | CHAR(1) | CHAR(1) | CHAR(1) | BOOLEAN |
| byte | NUMBER(3) | SMALLINT | SMALLINT | SMALLINT |
| char | NCHAR(1) | NCHAR(1) | GRAPHIC(1) CCSID 13488 | VARCHAR(1) |
| Clob | CLOB | NVARCHAR(MAX) | DBCLOB(16M) CCSID 13488 | TEXT |
| decimal(l,s) | NUMBER(l,s) | DECIMAL(l,s) | DECIMAL(l,s) | DECIMAL(l,s) |
| double | DOUBLE PRECISION | DOUBLE PRECISION | DOUBLE PRECISION | DOUBLE PRECISION |
| float | FLOAT | REAL | REAL | DOUBLE PRECISION |
| guid | RAW(16) | BINARY(16) | CHAR(16) FOR BIT DATA | UUID |
| int | NUMBER(10,0) | INT | INTEGER | INT |
| long | NUMBER(19,0) | BIGINT | BIGINT | BIGINT |
| short | NUMBER(5,0) | SMALLINT | SMALLINT | SMALLINT |
| String(l) | NVARCHAR2(l) | NVARCHAR(l) | VARGRAPHIC(l) CCSID 13488 | VARCHAR(l) |
| timestamp | NUMBER(17,0) | DECIMAL(17) | TIMESTAMP | TIMESTAMP |
| varstring(l) | NVARCHAR2(l) | NVARCHAR(l) | VARGRAPHIC(l) CCSID 13488 | VARCHAR(l) |
| valueset | NUMBER(5,0) | SMALLINT | SMALLINT | SMALLINT |
Typ danych Timestamp nie może być zapisany bezpośrednio w Oracle 9i/10g i SQL Server, ponieważ typy danych czasu obsługiwane przez te DBMS nie mają wymaganej dokładności 1 ms. Znacznik czasu jest zapisywany w tych systemach DBMS jako liczba w następujący sposób:
yyyyMMddhhmmssSSSS
- y – rok
- M – miesiąc
- d – dzień miesiąca
- h – godzina dnia
- m – minuta
- s – sekunda
- S – milisekunda
Typ danych boolean jest przechowywany we wszystkich DBMS jako CHAR(1). Wartość:
- 0 – oznacza fałsz
- 1 – oznacza prawdę
Dostęp za pomocą SQL
W przypadku dostępu do bazy danych zarządzanej przez system ERP za pomocą SQL, należy zwrócić uwagę na następujące kwestie:
- nazwy tabel i atrybutów w bazie danych różnią się od nazw używanych w systemie ERP
- mapowanie typów danych systemu ERP na typy danych SQL jest specyficzne dla bazy danych
- obiekty biznesowe mogą być zależne od czasu, więc rekord danych może istnieć w kilku wersjach. Należy to wziąć pod uwagę, zwłaszcza w przypadku połączeń z danymi podstawowymi.
- atrybuty możliwe do zlokalizowania muszą być rozwiązywane ręcznie za pomocą klucza głównego.
- odwołania do obiektów nie mogą być rozwiązywane za pomocą SQL
- SBLOB nie mogą być wyszukiwane za pomocą SQL.
Dostęp za pośrednictwem sterownika ODBC systemu ERP lub aplikacji systemu ERP jest prostszy niż bezpośredni dostęp za pomocą SQL.
Zmiany w bazie danych
SQL powinien być używany tylko do odczytu bazy danych. Jeśli dane w bazie danych zostaną zmienione, a SAS jest uruchomiony, dane w pamięci podręcznej SAS mogą nie być już zgodne z danymi w bazie danych. Może to prowadzić do niespójności, a tym samym do utraty danych. Ponadto modele danych większości jednostek biznesowych są tak złożone, że konsekwencje i zależności zmiany nie zawsze są rozpoznawalne. Zdecydowanie odradzanym jest wprowadzanie zmian w bazie danych systemu ERP za pomocą SQL. Jeśli ręczne zmiany są nieuniknione, możesz użyć aplikacji Polecenia OQL.
Przywracanie bazy
Kopia zapasowa bazy danych powinna być zawsze tworzona i przywracana jako całość. Przywracanie pojedynczych tabel nie jest zalecane ze względu na złożony model danych, ponieważ zależności przywracanej tabeli zazwyczaj nie są znane.
Jeśli aktualizacje oprogramowania ze zmianami w modelu danych zostały zaimportowane do systemu po utworzeniu kopii zapasowej, która ma zostać przywrócona, wówczas bazy danych nie mogą być przywracane pojedynczo. Należy również zauważyć, że zawartość bazy danych OLAP jest obliczana na podstawie bazy danych OLTP. Przywrócenie bazy danych OLTP bez przywrócenia bazy danych OLAP może prowadzić do niespójnych stanów.
Informacje o bazie danych
Konfiguracja bazy danych jest przechowywana w bazie konfiguracyjnej. Jednak niektóre dane konfiguracyjne wpływają na zawartość bazy danych i dlatego nie można ich zmienić lub można je zmienić tylko po reorganizacji bazy danych. Duplikatem tych danych konfiguracyjnych są informacje o bazie danych. Informacje o bazie danych obejmują następujące dane:
| Dane | Opis |
| System | System, do którego należy baza danych, jest zapisany w informacjach o bazie danych. Z wyjątkiem bazy konfiguracyjnej, każda baza danych należy do dokładnie jednego systemu. |
| Zawartość | Zawartość bazy danych nie może i nigdy nie może się zmienić. Zawartość bazy danych wpływa między innymi na schemat bazy danych. |
| Sterownik systemu ERP | W zależności od sterownika systemu ERP dane mogą być zapisywane w różny sposób w bazie danych. Zmiana sterownika systemu ERP dla istniejącej bazy danych jest niedozwolona. |
| Język wiodący | Tekst atrybutu zlokalizowanego w języku podstawowym znajduje się w obiekcie biznesowym. Zmiana konfiguracji bez reorganizacji tłumaczeń spowodowałaby wyświetlenie nieprawidłowego tłumaczenia języka podstawowego. |
| Języki dodatkowe | Tłumaczenia atrybutu zlokalizowanego w językach dodatkowych można znaleźć w odpowiedniej tabeli NLS. Zmiana konfiguracji bez reorganizacji tłumaczeń skutkuje zbyt dużą lub zbyt małą liczbą tłumaczeń w tabeli NLS.Oprócz dodatkowych języków samej bazy danych OLTP, dodatkowe języki bazy danych repozytorium są również przechowywane w bazie danych OLTP. Języki dodatkowe bazy danych repozytorium są używane dla obiektów biznesowych z danymi podstawowymi konfiguracji typu danych (wyświetlanie), których atrybuty wielojęzyczne mają być wyświetlane w języku wyświetlania. |
Ograniczenia specyficzne dla DBMS
System ERP powinien oferować taką samą funkcjonalność we wszystkich DBMS. Ponieważ systemy DBMS różnią się zakresem funkcji, system ERP musi ukrywać te różnice lub sprawdzać je jako ograniczenie ogólnie niezależne od systemu DBMS. Jest to jedyny sposób, aby zapewnić, że system ERP zachowuje się identycznie na wszystkich systemach DBMS.
Ograniczenia Oracle
1000 kolumn na klauzulę join
Suma wszystkich kolumn wszystkich tabel użytych w klauzuli join instrukcji SELECT musi być mniejsza niż 1000.
Tabela A – ma 400 kolumn
Tabela B – ma 500 kolumn
Tabela C – ma 300 kolumn
Polecenie:
SELECT … FROM A JOIN (B JOIN C ON …) ON … – przekracza limit 1000 kolumn.
Podczas gdy polecenie:
SELECT … FROM A, B, C – nie przekracza tego limitu.
W przypadku Oracle instrukcje SQL są generowane przez system ERP w taki sposób, że limit 1000 kolumn w klauzuli join jest osiągany znacznie rzadziej, a zatem znacznie rzadziej prowadzi do błędów.
Maksymalnie 4000 bajtów na atrybut
Atrybut może mieć maksymalny rozmiar 4000 bajtów. Oznacza to, że ciągi znaków mogą mieć maksymalną długość 2000 znaków.
Pusty ciąg jest identyczny z NULL
W Oracle pusty ciąg znaków jest identyczny z NULL. Różni się to od innych DBMS i prowadzi do innego zachowania zapytań dla pustych ciągów.
create table T(a varchar(10) primary key, b varchar(10));
insert into T values (’1′,’a’);
insert into T values (’2′,”);
Zapytanie:
select * from T where b=”;
zwraca pusty zestaw wyników w Oracle. We wszystkich innych bazach danych zapytanie to zwraca wiersz: 2.
Aby skorygować ten błąd, pusty znak jest zapisywany zamiast pustego ciągu we wszystkich bazach danych. System ERP mapuje pusty ciąg w sposób przezroczysty na pusty znak, dzięki czemu zmiana jest niezauważalna i nie może na nią wpływać.
System ERP usuwa wszystkie dołączone spacje (rtrim) w Business Objects. Nie jest zatem możliwe zapisanie ciągu znaków ze spacją z poziomu aplikacji. Ta zamiana jest przeprowadzana we wszystkich bazach danych w celu osiągnięcia identycznego zachowania we wszystkich bazach danych.
Jednak to zastąpienie staje się zauważalne, jeśli na przykład używany jest operator LIKE. Wyrażenia takie jak LIKE _ znajdują również spacje, a zatem także wiersze, które system ERP zapisał jako pusty ciąg.
Jeśli pusty ciąg jest używany jako stała w OQL, jest on zastępowany pustym znakiem. Na przykład a=” jest zastępowane przez a=’ ’, a LIKE ” jest zastępowane przez LIKE ’ ’.
Sterownik ODBC systemu ERP korzysta również z Persistence service systemu ERP. Ponieważ zamiana odbywa się w Persistence service, jest ona równie przejrzysta dla sterownika ODBC, jak i dla aplikacji.
Zamiana ta jest widoczna, gdy inne programy uzyskują dostęp do bazy danych systemu ERP bezpośrednio przez SQL. W przypadku takich dostępów należy uwzględnić obsługę pustych ciągów znaków, a także mapowanie znaczników timestamps, tekstów, guidów, obiektów blob itp. Wszystkie te typy danych mają częściowo złożoną reprezentację w bazie danych, która może być łatwo rozwiązana tylko przez system ERP.
Brak automatycznego RTRIM dla atrybutów łańcuchowych
W przeciwieństwie do innych systemów DBMS, ORACLE rozróżnia ciągi dla porównań, które różnią się tylko spacjami poniżej. Nie jest to problematyczne, ponieważ końcowe spacje w atrybutach łańcuchów są zawsze obcinane.
Ograniczenia nałożone przez serwer SQL
Maksymalnie 8192 bajtów na wiersz
Suma rozmiaru wszystkich kolumn w wierszu bez kolumn VARCHAR nie może przekroczyć 8192 bajtów. Jeśli wiersz z kolumnami VARCHAR jest większy niż 8192 bajty, wówczas więcej niż jeden blok jest używany do zapisania tego wiersza, a czasy dostępu do tabel są skrócone. Podczas generowania opisu tabeli sprawdzany jest całkowity rozmiar kolumn i w razie potrzeby generowane jest ostrzeżenie lub komunikat o błędzie.
4.11.3 Ograniczenia wynikające z DB2/400
Transakcje nie są całkowicie odizolowane
W przypadku DB2 for the iSeries usunięcia i niektóre zmiany są widoczne dla wszystkich innych transakcji, nawet jeśli transakcja modyfikująca nie została jeszcze zakończona zatwierdzeniem.
W przeciwieństwie do innych baz danych, iSeries zapisuje wszystkie zmiany natychmiast do tabeli i zapisuje stary stan w dzienniku. Po wycofaniu iSeries przywraca dane przy użyciu dziennika. Jeśli rekordy danych są zmieniane lub wstawiane, wymagana jest blokada dla tych rekordów danych. Wszystkie wybory są dokonywane w tabeli, która została już zmieniona i nie korzystają z dziennika.
W rezultacie serwer iSeries nigdy nie zwraca nieprawidłowych danych do systemu ERP. Jeśli jednak transakcje zmiany są otwarte, nie wszystkie dane zostaną znalezione. Z tego powodu wszystkie usunięcia są przeprowadzane w systemie ERP tak późno, jak to możliwe. Szczególnie krytyczne punkty są wyraźnie zabezpieczone w aplikacjach za pomocą blokad logicznych, dzięki czemu zachowanie iSeries ponownie staje się mniej krytyczne.
Środki te nie rozwiązują jednak problemu, a jedynie zmniejszają prawdopodobieństwo odczytu niespójnych danych. Oznacza to, że podczas produktywnego korzystania z systemu iSeries ryzyko niespójnego odczytu danych pozostaje niskie.
Ograniczenia wynikające z PostgreSQL
Wszystkie identyfikatory SQL w cudzysłowach
PostgreSQL konwertuje wszystkie identyfikatory SQL, takie jak nazwy tabel, nazwy kolumn i nazwy indeksów, na małe litery. Comarch ERP Enterprise używa jednak dużych liter dla identyfikatorów SQL. Z tego powodu wszystkie identyfikatory SQL muszą być ujęte w podwójne cudzysłowy.
Stała długość typu danych GUID
Typ danych GUID ma stałą długość 16 bajtów w PostgreSQL. Oznacza to, że identyfikatory GUID o mniejszej długości nie mogą być przechowywane w PostgreSQL. Jednak identyfikatory GUID o długości mniejszej niż 16 bajtów są nieprawidłowe – niezależnie od PostgreSQL.
Nazwa bazy danych w ścieżce dostępu
Nazwa bazy danych musi być określona w ścieżce dostępu do bazy danych PostgreSQL:
jdbc:postgresql://<host>:<port>/<dbName>.
Wielkie/małe litery
Można użyć właściwości systemu ERP com.cisag.sys.kernel.caching.CaseSensi-tivityMode, aby wpłynąć na obsługę dużych/małych liter.
Możliwe wartości to
- 1 – duże/małe litery mogą być wprowadzane i wyszukiwane we wszystkich polach tekstowych.
- 2 – wielkość liter nie ma znaczenia przy wyszukiwaniu opisów.
- 3 – wielkość liter nie ma znaczenia przy wyszukiwaniu identyfikatorów i oznaczeń.
- 4 (wartość domyślna)- w polach identyfikacyjnych można wprowadzać tylko wielkie litery.
W trybie rozróżniania wielkości liter 3 lub 4 wszystkie pola identyfikacyjne, z wyjątkiem wyjątków zarejestrowanych w klasie Java com.cisag.app.general.log.CaseSensitivityRegistry, są wyszukiwane wielkimi literami. Warunkiem wstępnym jest to, że zawartość wszystkich pól identyfikacyjnych w bazie danych jest już zapisana wielkimi literami. Podczas wyszukiwania wszystkie wzorce wyszukiwania są konwertowane na duże litery przed ich wykonaniem w bazie danych. Oznacza to, że baza danych nie musi już zmieniać wielkości liter podczas wykonywania zapytania, dzięki czemu baza może korzystać z indeksów pól identyfikacyjnych podczas wykonywania zapytań.
Jeśli następnie ustawiony zostanie tryb czułości wielkości liter 3 lub 4 w systemie, możliwe jest, że w polu identyfikacyjnym znajdują się rekordy danych z małymi literami. Te rekordy danych nie mogą zostać odnalezione podczas wyszukiwania. Dlatego przed ustawieniem trybu czułości wielkości liter 3 lub 4 upewnij się, że wszystkie pola identyfikacyjne we wszystkich tabelach zawierają tylko wielkie litery.
Jeśli aktywny jest tryb czułości na wielkość liter 3 lub 4, w polach identyfikacyjnych można wprowadzać tylko wielkie litery. W takim przypadku nie możesz zapisywać małych liter w polach identyfikacyjnych.
W trybie czułości na wielkość liter 2, 3 lub 4 wszystkie opisy, oprócz wyjątków zarejestrowanych w klasie Java com.cisag.app.general.log.CaseSensitivityRegistry, są wyszukiwane dużymi/małymi literami. W tym celu wzorzec wyszukiwania i pole bazy danych są konwertowane na duże litery podczas wykonywania zapytania. Jest mało prawdopodobne, aby baza danych mogła użyć indeksu do ograniczenia do pól opisu podczas wykonywania zapytania wyszukiwania. Dlatego też, jeśli część pola opisu jest zawarta w indeksie, pole to nie jest wyszukiwane niezależnie od wielkich/małych liter, aby baza danych mogła użyć indeksu do wyszukiwania.
Ograniczenia specyficzne dla języka
Systemy DBMS działają z różnymi algorytmami sortowania, z których każdy działa z różnymi tabelami sortowania. Oznacza to, że każdy system DBMS sortuje ciągi znaków inaczej dla każdego języka. Aby można było użyć sortowania bazy danych, należy określić, czy jest ono zgodne z systemem ERP.
Sortowanie bazy danych jest zgodne z systemem ERP, jeśli ma unikalną kolejność znaków Unicode do porównywania, grupowania i sortowania ciągów znaków. Sortowanie wybrane dla języka powinno sortować zgodnie z oczekiwaniami użytkownika tak dalece, jak to możliwe.
Oracle, SQL Server i DB2/400
Poniższa tabela zawiera listę zalecanych domyślnych ustawień bazy danych w odniesieniu do używanego systemu DBMS i głównego języka skonfigurowanego dla bazy danych w systemie ERP. W przypadku baz danych DBMS DB2/400 i Oracle ustawienia te są wprowadzane automatycznie przez system ERP; baza danych MS SQL Server musi zostać odpowiednio skonfigurowana podczas jej tworzenia.
| Język | DBMS | ||
| DB2/400(LANGID, sortowanie tabeli) | Serwer MS-SOL(Zestawienie) | Oracle(NLS_SORT) | |
| Niemiecki | DEU, QSYS/QLA10111U | Latin1_General_CS_AS | NIEMIECKI |
| Angielski | ENG, QSYS/QLA1011DU | Latin1_General_CS_AS | WEST_EUROPEAN |
| Francuski | FRA, QSYS/QLA10129U | French_CS_AS | FRANCUSKI |
| Włoski | ITA, QSYS/QLA10118U | Latin1_General_CS_AS | WŁOSKI |
| Chorwacki | HRV, QSYS/QLA20366U | Croatian_CS_AS | CHORWACJA |
| Holenderski | NLD, QSYS/QLA10025U | Latin1_General_CS_AS | HOLENDERSKI |
| Polski | PLK, QSYS/QLA20366U | Polish_CS_AS | POLSKI |
| Rosyjski | RUS, QSYS/QRUS0401U | Cyrillic_CS_AS | ROSJA |
| Słowacki | SKY, QSYS/QLA20366U | Slovak_CS_AS | SŁOWAK |
| Słoweński | SLO, QSYS/QLA20366U | Slovenian_CS_AS | SŁOWENIA |
| Czechy | CSY, QSYS/QLA20366U | Czech_CS_AS | CZECHY |
| Turecki | TRK, QSYS/QTRK0402U | Turkish_CS_AS | TURCJA |
| Węgierski | HUN, QSYS/QLA20366U | Hungarian_CS_AS | WĘGRY |
| Chiński | CHS, QSYS/QBCHS04B0U | Chinese_Simplified_Pinyin_100_BIN2 | BINARY |
Odpowiednie zestawienia systemu ERP są dostarczane wraz z nośnikiem instalacyjnym dla wymienionych ustawień. Są one używane do symulacji sortowania ciągów znaków w pamięci głównej, tak aby użytkownik zauważył jak najmniejszą różnicę między sortowaniami.
PostgreSQL
PostgreSQL nie rozpoznaje tabel sortowania dla specjalnych języków. Sortowanie jest oparte na używanym systemie operacyjnym. Oznacza to, że sortowanie w bazie danych może być różne w różnych wersjach systemu Windows i Linux. Comarch ERP Enterprise wykorzystuje standardowe sortowanie Java dla odpowiedniego języka podstawowego bazy danych na serwerze aplikacji. Mogą wystąpić rozbieżności między sortowaniem bazy danych specyficznym dla systemu operacyjnego a sortowaniem na serwerze aplikacji. Im większe rozbieżności, tym większe prawdopodobieństwo wystąpienia niespójności w Comarch ERP Enterprise, np. podczas przewijania w niestandardowych listach.
Przełączanie awaryjne bazy danych
Większość systemów zarządzania bazami danych (DBMS) posiada mechanizmy przełączania awaryjnego. Oznacza to, że kilka instancji bazy danych działa równolegle w tej samej bazie danych lub w lustrzanej bazie danych. Jeśli instancja bazy danych nie jest już dostępna z powodu błędu, inna instancja bazy danych może przejąć zadania uszkodzonej instancji. Często istnieje kilka sposobów konfiguracji przełączania awaryjnego dla systemu bazy danych w systemie DBMS. Konfiguracje obsługiwane przez Comarch ERP Enterprise można znaleźć w dokumentacji instalacyjnej.
Poziom izolacji transakcji
System ERP wykorzystuje co najmniej poziom izolacji transakcji READ_COMMITTED dla wszystkich połączeń z bazą danych. Przy tym poziomie izolacji transakcji system bazy danych zwraca tylko dane, które zostały zapisane w bazie danych przez pomyślnie zakończoną transakcję (z zatwierdzeniem) w odpowiedzi na zapytanie. Dane z transakcji, które nie zostały jeszcze zakończone, nie są widoczne w tych połączeniach.
Interaktywne wyszukiwanie dialogowe zazwyczaj obejmuje stosunkowo złożone zapytania. Tylko niewielka część danych wynikowych zapytania jest używana przez program. Są to zazwyczaj klucze podstawowe wybranego obiektu biznesowego. Wszystkie wartości pochodzące z wyszukiwania dialogowego są sprawdzane przez aplikację, ponieważ wynik wyszukiwania może być zawsze nieaktualny, a zatem niespójny. Ponieważ wszyscy użytkownicy wyszukiwania dialogowego muszą oczekiwać, że wynik będzie nieaktualny i niespójny, READ_COMMITTED można pominąć w przypadku wyszukiwania interaktywnego.
Z tego powodu system ERP używa poziomu izolacji transakcji READ_UNCOMMITTED dla iSeries i serwera MS SQL. Złożone zapytania mogą być przetwarzane szybciej w tych systemach DBMS z poziomem izolacji transakcji READ_UNCOMMITTED niż z poziomem izolacji transakcji READ_COMMITTED.



