W automatyzacji procesów kluczową rolę odgrywają dane możliwe do odczytu maszynowego. W celu zapewnienia maszynowej czytelności danych opracowano różne techniki. Do takich technik zaliczają się między innymi kody kreskowe (barcode) oraz czcionki OCR. W niektórych obszarach zastosowań wykorzystywane są również tzw. kody 2D lub kody matrycowe.
Moduł zarządzania wydrukami systemu obsługuje stosowanie (generowanie) kodów kreskowych oraz czcionek OCR w dokumentach takich jak formularze i raporty. W standardzie systemu zawarte są już specjalne czcionki oraz dodatkowe funkcje, obsługujące wiele typów kodów kreskowych oraz czcionek OCR/MICR.
Grupa docelowa
Niniejszy artykuł jest skierowany przede wszystkim do projektantów raportów, czyli osób tworzących raporty oraz dokumenty dla systemu przy użyciu Crystal Reports.
Dla administratorów systemu istotny jest rozdział Instalacja, w którym opisano, jakie oprogramowanie oraz w jakich lokalizacjach należy zainstalować.
Wprowadzenie
Z biegiem czasu opracowano różne techniki umożliwiające maszynowy odczyt danych. Niniejszy artykuł koncentruje się przede wszystkim na technikach stosowanych powszechnie w handlu oraz w przemyśle.
Najczęściej wykorzystywane są różne odmiany tak zwanych kodów kreskowych. Czcionki OCR oraz MICR znajdują zastosowanie głównie w obszarze rachunkowości.
Ponieważ zasadnicza część artykułu poświęcona jest kodom kreskowym (barcodes), w pierwszej kolejności przedstawiono krótkie wyjaśnienie, czym są kody kreskowe oraz do jakich celów są wykorzystywane. Zaprezentowano również przykładowe warianty kodów kreskowych.
Czym są kody kreskowe?
Kod kreskowy to układ pasków o różnej szerokości lub wysokości, które są drukowane naprzemiennie w kolorze czarnym lub białym.
Kody kreskowe służą do reprezentowania (kodowania) liczb i znaków w taki sposób, aby można je było szybko i łatwo odczytać za pomocą specjalnych urządzeń odczytujących (tzw. skanerów kodów kreskowych).
Różnice między poszczególnymi kodami kreskowymi polegają na:
- złożoności pod względem urządzeń generujących lub odczytujących
- zakresie obsługiwanego zestawu znaków
- zapotrzebowanie na miejsce
- zapobieganie błędom, wykrywanie błędów, poprawie błędów
Istnieją również „standardy” specyficzne dla danego kraju i branży.
Poniższa tabela przedstawia różne warianty kodów kreskowych. Jak widać, informacje nie zawsze są kodowane za pomocą szerokości pasków lub spacji, ale czasami tylko za pomocą długości. W przypadku DataMatrix nie można mówić o kodach kreskowych – jest to tak zwany kod 2-D lub matrycowy:
| Typ/Symbol | Kod kreskowy | Dane |
| Kod128 |  |
1234ABCabc |
| EAN-13 |  |
4012345678901 |
| POSTNET | 12345-6789 | |
| DataMatrix |  |
Test kodu DataMatrix w systemie. |
Struktura kodów kreskowych
Podstawowa struktura kodu kreskowego została tutaj wyjaśniona (a przykładzie kodu 128. Te same zasady często mają zastosowanie do innych wariantów kodów kreskowych.
Kod kreskowy składa się z równoległych, naprzemiennych ciemnych pasków i jasnych spacji. Informacje zawarte są albo tylko w liniach, ale najczęściej także w odstępach. Odstępy i paski są określane jako elementy (kodu kreskowego).

Poszczególne znaki w kodzie kreskowym są definiowane przez jednoznaczną sekwencję elementów o różnej szerokości. Większość kodów wykorzystuje dwie lub cztery różne szerokości elementów.
Najwęższy element określany jest mianem modułu. Szerokość tego najwęższego elementu nazywana jest szerokością modułu lub oznaczana symbolem X. Szerokość pozostałych elementów jest zazwyczaj definiowana jako wielokrotność szerokości modułu.
Pierwszym znakiem kodu kreskowego jest zawsze jednoznaczny znak startowy, natomiast ostatnim znakiem jest znak stopu. Na podstawie tych znaków możliwe jest rozpoznanie typu kodu kreskowego oraz jego orientacji (kierunku odczytu). Oba te znaki są wymagane niezależnie od właściwych danych użytkowych.
Wiele kodów kreskowych umożliwia dodatkowo zastosowanie cyfry kontrolnej (oznaczonej na powyższej ilustracji jako Check Char). Skaner może zostać skonfigurowany w taki sposób, aby podczas odczytu obliczał cyfrę kontrolną i porównywał ją z wartością odczytaną. Cyfry kontrolne stanowią najskuteczniejszy sposób zwiększenia niezawodności odczytu. Niektóre kody kreskowe są również samokontrolujące, co oznacza, że na podstawie liczby szerokich i wąskich elementów przypadających na znak można stwierdzić, czy znak został poprawnie rozpoznany.
Przed i za kodem kreskowym znajdują się jasne strefy ciszy (oznaczane na powyższej ilustracji jako Quiet Zone). Ich szerokość musi w przypadku większości kodów kreskowych wynosić co najmniej dziesięciokrotność szerokości modułu lub minimum 2,5 mm.
Często informacja zakodowana w kodzie kreskowym jest dodatkowo prezentowana w postaci tekstowej (np. poniżej kodu kreskowego). Umożliwia to odczyt danych przez człowieka, czyli bez użycia urządzeń technicznych, takich jak skaner.
Drukowanie kodów kreskowych
Istnieją kilka sposobów drukowania kodów kreskowych:
- drukarki specjalistyczne (np. do etykiet)
- drukowanie grafik (bitmapowych lub wektorowych), które są generowane za pomocą specjalistycznego oprogramowania
- stosowanie specjalnych czcionek kodów kreskowych.
Każde z powyższych rozwiązań posiada, w zależności od obszaru zastosowania, określone zalety i wady. Z punktu widzenia zarządzania wydrukami w systemie kluczowe jest jednak to, aby dane rozwiązanie współpracowało z Crystal Reports oraz było w możliwie największym stopniu niezależne od drukarki (raport utworzony raz powinien móc być drukowany na różnych urządzeniach bez konieczności wprowadzania zmian).
Wymagania te są najlepiej spełniane poprzez zastosowanie czcionek kodów kreskowych. Z tego względu pozostałe metody drukowania kodów kreskowych nie są w dalszej części dokumentu omawiane.
Czcionki kodów kreskowych
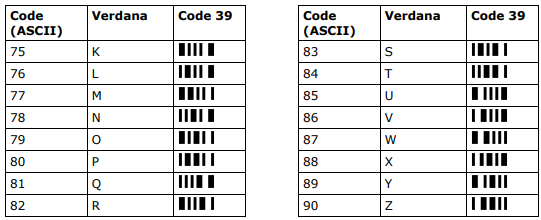
Czcionki kodów kreskowych (font) działają tak samo jak zwykłe czcionki tekstowe (np. Verdana, Courier, Symbol itd.): dla każdego kodu znaku (np. „83”) zdefiniowana jest określona reprezentacja graficzna (np. litera „S” w czcionce Verdana lub „S” w czcionce Symbol).
Poniższa tabela przedstawia różnice w sposobie wyświetlania kodów znaków w zależności od zastosowanej czcionki. Jako czcionkę standardową wykorzystano tutaj Verdana (jest to czcionka domyślna używana w niniejszym dokumencie). W ostatniej kolumnie zaprezentowano te same kody znaków w postaci „znaków kodu kreskowego” (Code 39).
Jak można zauważyć, pojedynczy znak z zestawu znaków kodu kreskowego zawiera wszystkie elementy (paski i przerwy) niezbędne do zakodowania danego znaku.

Kod kreskowy zazwyczaj reprezentuje więcej niż jeden znak. Podobnie jak w przypadku zwykłego tekstu, ciągi znaków mogą być również reprezentowane za pomocą czcionek kodów kreskowych i w ten sposób kodowane jako kody kreskowe. Ciąg znaków ABC123, który jest wyświetlany w czcionce Verdana jako ABC123, pojawia się w czcionce Code 39 jako:

Nie jest to jednak jeszcze prawidłowy kod kreskowy, ponieważ nadal brakuje co najmniej znaków początkowych i końcowych. Dla Code 39 użytego tutaj jako przykład, znak „*” (ASCII 42) jest określony jako znak startu i stopu. W tym przypadku (kod 39) wystarczy dodać „*” do rzeczywistej informacji po prawej i lewej stronie, tj. po prostu przekształcić ABC123 w *ABC123*:

Jeżeli dodatkowo zostaną uwzględnione strefy ciszy po lewej i prawej stronie kodu kreskowego, czyli zapewniony zostanie odpowiedni odstęp od innych elementów na stronie, kod kreskowy może zostać prawidłowo odczytany przez skaner.
To proste podejście działa jednak wyłącznie w przypadku niektórych standardów kodów kreskowych (np. Code 39 lub Codabar). W standardach, które wymagają stosowania cyfry (lub znaku) kontrolnego, musi ona być zawarta bezpośrednio w danych albo obliczona przed wygenerowaniem wydruku. Ponadto niektóre standardy kodów kreskowych wykorzystują zestawy znaków, których nie da się bezpośrednio (1:1) odwzorować na drukowalne znaki ASCII lub Unicode. W takich przypadkach dane muszą zostać wcześniej „przetransformowane”, zanim będzie możliwe ich wygenerowanie przy użyciu czcionki. To samo dotyczy standardów, w których sposób kodowania zależy od pozycji znaku lub znaków sąsiednich.
Ogólna procedura polega zatem na tym, aby nie drukować danych bezpośrednio, lecz wcześniej przekształcić je — przy użyciu odpowiednich narzędzi — w ciąg znaków zgodny z zastosowaną czcionką kodu kreskowego. Dlatego w standardowym zakresie dostawy systemu znajdują się nie tylko czcionki obsługujące różne standardy kodów kreskowych, lecz także dodatkowe funkcje dla Crystal Reports, umożliwiające obliczanie sekwencji znaków wymaganych przez daną czcionkę.
Poniższa tabela ma na celu zobrazowanie tego mechanizmu na przykładach.
| Typ kodu | Code 39 | Code 128 | Interleaved 2 of 5 | EAN-13 |
| Dane | 12345ABCDE | 1234ABCabc | 1234567890 | 401234567890 |
| Funkcja | Code39 | Code128 | I2of5 | EAN13 |
| Wynik 1 | !12345ABCDE! | Í,BÈABabc(Î | Ë-CYo{Ì | Y(0B23EF*QRSTKL( |
| Czcionka | C39* | C128* | I25* | UPCEANL |
| Wynik 2 |  |
 |
 |
Rozmiar czcionki
Drukowanie kodów kreskowych za pomocą czcionek ma tę zaletę, że rozmiar wyjściowy może być skalowany w szerokim zakresie, a tym samym dostosowany do dostępnej przestrzeni. Należy jednak zawsze przestrzegać specyfikacji odpowiedniego standardu. Określają one na przykład wartość nominalną i/lub minimalne i maksymalne wartości szerokości modułu. Zazwyczaj istnieją również pewne specyfikacje dotyczące wysokości paska. Na przykład w przypadku kodów o zmiennej długości minimalna wysokość jest często określana jako 15% całkowitej długości kodu kreskowego, tj. im więcej znaków jest zakodowanych, tym większa jest minimalna wysokość paska. Próba dostosowania za pomocą rozmiaru czcionki, jednocześnie zmieni całkowitą długość i szerokość modułu.
Idealnym rozwiązaniem byłaby możliwość niezależnego skalowania czcionki w osi X i Y, jednak tylko nieliczne programy to umożliwiają (Crystal Reports nie obsługuje takiej funkcjonalności). Dlatego przy doborze odpowiedniego rozmiaru czcionki należy zastosować inne podejście: rozmiar czcionki służy wyłącznie do określenia szerokości modułu, a tym samym całkowitej szerokości kodu kreskowego. Natomiast wysokość pasków uzyskuje się poprzez wybór odpowiedniego wariantu czcionki.
Dostarczane czcionki występują w różnych wariantach wysokości, oznaczonych na przykład jako XS, S, M, L, XL oraz XXL. We wszystkich wariantach szerokość modułu pozostaje taka sama, natomiast różni się wysokość pasków. Należy zatem wybrać ten wariant, który najlepiej spełnia wymagania specyfikacji standardu oraz dostępne warunki przestrzenne.
Kody kreskowe w Crystal Reports
Aby móc drukować kody kreskowe w Crystal Reports, należy zainstalować odpowiednie czcionki. W większości przypadków wymagane jest dodatkowe oprogramowanie (np. do dodawania znaków początku i końca oraz do obliczania cyfr kontrolnych, sekcja Czcionki kodów kreskowych). Głównym składnikiem takiego oprogramowania jest zazwyczaj specjalna biblioteka DLL z dodatkowymi funkcjami dla Crystal Reports. Ten typ biblioteki DLL jest również znany jako User Function Library lub UFL.
Najpopularniejsze (1-D) kody kreskowe i niezbędne UFL są już zawarte w systemie. Zastosowane czcionki zostały licencjonowane od firmy IDAutomation, Inc. i mogą być używane wyłącznie w połączeniu z systemem. Rozszerzenie funkcjonalności o dodatkowe typy kodów kreskowych lub kody dwuwymiarowe (2D) jest zasadniczo możliwe. Wymagane w tym celu czcionki oraz narzędzia pomocnicze mogą być nabywane m.in. od firmy IDAutomation, Inc.. Oprócz niej istnieją również inni dostawcy, których rozwiązania są kompatybilne z Crystal Reports.
Szczegółowe informacje dotyczące korzystania z dostarczonych czcionek oraz funkcji w Crystal Reports znajdują się w rozdziale Wykorzystanie kodów kreskowych w Crystal Reports.
Instalacja
Podczas instalacji należy pamiętać, że czcionki i dodatkowe oprogramowanie są wymagane nie tylko podczas tworzenia (projektowania) lub dostosowywania raportów (pliki *.rpt), ale także podczas uruchamiania.
Aby uprościć instalację, programy instalacyjne sterownika ODBC i (SOM) zostały rozszerzone tak, aby instalowały również czcionki kodów kreskowych i dodatkowe oprogramowanie (UFL), jeśli jest wymagane. Oba programy instalacyjne różnią się jednak ustawieniami domyślnymi. Na przykład program instalacyjny sterownika ODBC nie instaluje żadnych czcionek kodów kreskowych ani dodatkowego oprogramowania w ustawieniu domyślnym. Program instalacyjny dla SOM instaluje już niewielki wybór często używanych czcionek kodów kreskowych i niezbędnego dodatkowego oprogramowania w ustawieniu standardowym. W przypadku obu programów instalacyjnych wymagane czcionki można jednak wybrać ręcznie, wybierając instalację niestandardową (Custom).
Czcionki do zainstalowania można wybrać w kreatorze instalacji. Zazwyczaj dostępnych jest kilka wariantów czcionek dla każdego typu kodu kreskowego, na przykład z tekstem lub bez.
Poniższa tabela pokazuje, które czcionki są przypisane do poszczególnych funkcji lub która funkcja musi być zainstalowana, aby móc korzystać z określonej czcionki.
| Kod kreskowy | Wariant | Czcionki |
| Code 39 | Standard | IDAutomationC39* |
| Extended (full ASCII) | IDAutomationXC39* | |
| Human readable fonts (Standard Code 39) | IDAutomationHC39* | |
| Human readable fonts (Extended Code 39) | IDAutomationXHC39* | |
| Codabar | With no text below the barcode | IDAutomationCB* |
| With text below the barcode | IDAutomationHCB* | |
| Code 128 | Standard Code 128 | IDAutomationC128* |
| Human readable fonts (code set B) | IDAutomationHbC128* | |
| Human readable fonts (code set C) | IDAutomationHcC128* | |
| UPC/EAN | IDAutomationUPCEAN* | |
| Interleaved 2 of 5 | With no text below the barcode | IDAutomationI25* |
| With text below the barcode | IDAutomationHI25* | |
| MSI/Plessey | With no text below the barcode | IDAutomationMSI* |
| With text below the barcode | IDAutomationHMSI* | |
| MICR E13B | E-13B IDAutomationMICR* MICR |
|
| MICR CMC-7 | IDAutomationCMC7* | |
| POSTNET | IDAutomationFIM IDAutomationPLANET* IDAutomationPOSTNET* |
|
| OCR Fonts | IDAutomationA1euro IDAutomationOCRa IDAutomationOCRb* |
Szczegółowy opis różnych typów kodów kreskowych i powiązanych czcionek można znaleźć w sekcji Specyfikacje.
Dodatkowe oprogramowanie (UFL dla Crystal Reports) jest instalowane automatycznie, jeśli wybrano co najmniej jedną (pod)funkcję.
Warunki licencji
Czcionki dostarczone wraz z systemem i opisane tutaj do wyświetlania kodów kreskowych są licencjonowane przez IDAutomation.com, Inc.. Czcionki te mogą być używane wyłącznie w połączeniu z Comarch ERP Enterprise.
Instalowanie dodatkowych czcionek
Czcionki kodów kreskowych dostarczane z systemem i powiązanym oprogramowaniem obsługują najpopularniejsze (1-D) kody kreskowe. Zasadniczo możliwe jest jednak dodanie kolejnych kodów kreskowych (lub kodów 2-D). Wielu producentów oferuje czcionki kodów kreskowych. Wybierając i instalując je, należy jednak upewnić się, że istnieje odpowiednie wsparcie dla Crystal Reports oraz że czcionki i wszelkie niezbędne dodatkowe oprogramowanie muszą być zainstalowane zarówno na komputerach klienckich (projekt raportu), jak i na komputerze SOM.
Używanie kodów kreskowych w Crystal Reports
W tym rozdziale opisano, w jaki sposób czcionki kodów kreskowych dostarczone z systemem mogą być używane w Crystal Reports do drukowania kodów kreskowych. Zakłada się, że wymagane czcionki kodów kreskowych i powiązane oprogramowanie są już zainstalowane.
Jeśli dodatkowe oprogramowanie zostało poprawnie zainstalowane, funkcje są dostępne w edytorze formuł Crystal Reports w sekcji Funkcje/Funkcje dodatkowe.
Instrukcje
Tworzenie pola formuły
W pierwszym kroku należy utworzyć pole formuły, które na podstawie wybranego pola danych (w tym przypadku: {app_general_Item.number}) przy użyciu odpowiedniej funkcji (w tym przypadku: IDAutomationFontEncoderCode128) obliczy ciąg znaków, który następnie zostanie wyświetlony za pomocą przypisanej czcionki (w tym przypadku: IDAutomationC128M).
Aby utworzyć nowe pole formuły, należy postępować w następujący sposób:
-
W Eksploratorze pól kliknąć prawym przyciskiem myszy pozycję Pola formuł, aby otworzyć menu kontekstowe.
-
W menu kontekstowym wybrać opcję Nowe….
-
W wyświetlonym oknie dialogowym wprowadzić nazwę pola formuły (np. Code128), a następnie nacisnąć przycisk Użyj edytora.
Uruchomienie edytora formuł
-
Zostanie otwarty edytor formuł.
-
W folderze Funkcje (środkowa kolumna) otworzyć podfolder Dodatkowe funkcje, a następnie podfolder Visual Basic-UFLs (u2lcom.dll).
-
Wybrać odpowiednią funkcję (dwuklik). W tym przykładzie użyta zostanie funkcja IDAutomationFontEncoderCode128.
Wybór funkcji
-
W tym przypadku funkcja oczekuje dwóch parametrów: właściwych danych (DataToFormat) w postaci tekstu oraz liczby (ReturnType), która określa typ oczekiwanego wyniku. W tym przykładzie używane jest pole danych {app_general_Item.number} oraz wartość „0” (ma zostać zwrócony ciąg znaków dla czcionki kodu kreskowego). Dane zawsze należy przekazywać jako tekst (String). Jeśli nie są dostępne w tej postaci, należy je przekonwertować przy użyciu dodatkowych funkcji.
Formuła z parametrami
-
Po poprawnym i kompletnym zdefiniowaniu formuły można ją zapisać i zamknąć edytor formuł.
W niektórych przypadkach pożądane jest wyświetlenie nie tylko kodu kreskowego, lecz także czytelnego tekstu (zapisu jawnego). Dla wielu czcionek kodów kreskowych dostępne są warianty, które automatycznie dodają taki tekst pod kodem kreskowym. Istnieją jednak zastosowania, w których rozwiązanie to jest niepraktyczne — na przykład gdy konieczne jest samodzielne określenie pozycji, treści lub formatowania tekstu.
W tym celu niektóre funkcje posiadają parametr ReturnType. Przekazanie wartości „1” powoduje, że funkcja zwraca ciąg znaków przeznaczony do wyświetlenia jako zapis jawny. Wynik zależy od typu kodu kreskowego i oprócz właściwych danych może zawierać również cyfrę kontrolną lub dodatkowe formatowanie.
Aby wyświetlić taki tekst, należy zdefiniować kolejne pole formuły. W tym przykładzie otrzymuje ono nazwę Code128Text. W tym celu należy powtórzyć kroki od 1 do 8, przy czym:
-
w kroku 3 jako nazwę formuły należy wprowadzić Code128Text,
-
w kroku 7 należy przekazać wartość „1” jako parametr ReturnType.
Korzystanie z pola formuły
Utworzone pola formuły mogą być teraz używane w raporcie (zamiast właściwych pól danych). Można je na przykład przeciągnąć z Eksploratora pól bezpośrednio do projektu raportu (np. do sekcji szczegółów).
Pola formuły w widoku projektu
Po przełączeniu do widoku podglądu można zobaczyć, jakie wyniki zwracają pola formuły.
W przypadku niektórych kodów kreskowych (np. Code 128 oraz Interleaved 2 of 5) ciągi znaków są przekształcane w większym stopniu niż w innych (np. Code 39). Może więc się zdarzyć, że wynik będzie wyglądał na „zaszyfrowany” lub że na początku bądź na końcu pojawią się „nietypowe” znaki.
Następnie należy ponownie przełączyć się do widoku projektu i dla pola formuły, które ma wyświetlać kod kreskowy (w tym przykładzie Code128), zmienić czcionkę (w tym przypadku IDAutomationC128M).
W kolejnym kroku należy dostosować rozmiar czcionki, uwzględniając specyfikację danego kodu kreskowego oraz używanego skanera (patrz rozdział Wskazówki dotyczące drukowania). Na końcu należy dopasować rozmiar pola tak, aby kod kreskowy był wyświetlany w całości.
Efekt tego przykładu w podglądzie wygląda następująco:
Przegląd
Niniejszy rozdział zawiera przegląd kodów kreskowych oraz czcionek OCR i MICR dostarczanych wraz z Comarch ERP Enterprise lub przez system obsługiwanych.
Należy zwrócić uwagę, że istnieją również standardy, które nie definiują własnego kodu kreskowego (symboliki), lecz opierają się na już istniejącym standardzie (symbolice). W przypadku takich „pochodnych” standardów zazwyczaj określane są jedynie bardziej szczegółowe wymagania dotyczące wybranych parametrów (rozmiar, dane, cyfra kontrolna itp.). Przykładami są EAN 128 (lub UCC 128), bazujący na Code 128, oraz SSC-14, oparty na Interleaved 2 of 5.
W pierwszej części przeglądu przedstawiono wszystkie kody kreskowe i czcionki wraz z przykładowymi danymi (indeks wizualny). Druga część zawiera skróconą informację, które konkretne czcionki i funkcje należy stosować dla danego typu kodu kreskowego lub standardu. Szczegółowy opis znajduje się w rozdziale Specyfikacje.
Przykłady
Poniższa tabela przedstawia wszystkie kody kreskowe oraz czcionki OCR i MICR dostępne w Comarch ERP Enterprise wraz z przykładowymi danymi (indeks wizualny):
| Typ | Dane / symbol |
|---|---|
| Codabar |  |
| Code 2/5 Interleaved |  |
| Code 39 |  |
| Code 39 Extended |  |
| Code 128 |  |
| EAN-8 |  |
| EAN-13 |  |
| EAN-13 z dodatkiem 2 |  |
| EAN-13 z dodatkiem 5 |  |
| EAN-18 / NVE / SSCC-18 |  |
| EAN-128 / UCC-128 |  |
| FIM |  |
| IMICR CMC-7 | |
| MICR E13-B |  |
| MSI / Plessey |  |
| OCR-A | |
| OCR-B | 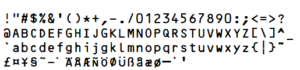 |
| PLANET | |
| POSTNET | |
| SCC-14 (ITF-14) |  |
| SCC-14 (EAN-128) |  |
| UPC-A |  |
| UPC-E |  |
Skrócona informacja
Poniższa tabela przedstawia, które czcionki oraz które funkcje są przewidziane dla danego kodu kreskowego lub określonej symboliki. Oprócz czcionek podano również zalecaną minimalną lub nominalną wielkość czcionki.
| Standard | Symbolika | Czcionka | Wielkość czcionki | Funkcje |
|---|---|---|---|---|
| Codabar | Codabar | CB*, HCB* | 12 pt | Codabar |
| Code 2/5 Interleaved | Code 2/5 Interleaved | I25*, HI25* | 12 pt | I2of5, I2of5Mod10 |
| Code 39 | Code 39 | C39*, HC39* | 12 pt | Code39, Code39Mod43 |
| Code 39 Extended | Code 39 (extended) | XC39*, XHC39* | 12 pt | |
| Code 128 | Code 128 | C128*, HbC128*, HcC128* | 12 pt | Code128, Code128a, Code128b, Code128c |
| EAN-8 | EAN/UPC | UPCEANM | 20 pt (nominalnie) | EAN8 |
| EAN-13 | EAN/UPC | UPCEANL | 20 pt (nominalnie) | EAN13 |
| EAN/UCC-18 / SSCC-18 | EAN-128 | C128* | X = 0,25 mm | SSCC18, Code128 |
| EAN/UCC-128 | Code 128 | C128* | X = 0,25 mm | UCC128, Code128 |
| FIM | FIM | FIM | 36 pt (48 pt) | |
| JAN | EAN/UPC | UPCEANL | 20 pt (nominalnie) | EAN13 |
| MICR CMC-7 | CMC-7 | CMC7 | 12 pt (nominalnie) | |
| MICR E13-B | MICR | MICR | 12 pt (nominalnie) | |
| MSI / Plessey | MSI / Plessey | MSI*, HMSI* | 12 pt | MSI |
| OCR-A | A1euro OCRa | 9 pt (nominalnie) (12 pt) | ||
| OCR-B | OCRb | 14 pt (nominalnie) | ||
| PLANET | PLANET | PLANET* | 12 pt (nominalnie) | Postnet |
| POSTNET | POSTNET | POSTNET* | 12 pt (nominalnie) | Postnet |
| SCC-14 (ITF-14) | Code 2/5 Interleaved | I25*, HI25* | X = 1,016 mm (nominalnie) | I2of5Mod10 |
| SCC-14 (EAN-128) | EAN-128 | C128* | X = 1,016 mm (nominalnie) | SCC14, Code128 |
| UPC-A | EAN/UPC | UPCEANL | 20 pt (nominalnie) | UPCa |
| UPC-E | EAN/UPC | UPCEANL | 20 pt (nominalnie) | UPCe |
| USPS (EAN128) | EAN-128 | C128L | 20 pt (nominalnie) | USPS_EAN128, Code128 |
Specyfikacje
Przedstawione tutaj opisy standardów kodów kreskowych oraz czcionek mają na celu ułatwienie ich stosowania w kontekście Comarch ERP Enterprise. Szczegółowe informacje dotyczące poszczególnych standardów są zazwyczaj dostępne w odpowiednich organizacjach normalizacyjnych (ANSI, DIN/EN, AIM, EAN itd.) – patrz rozdział Dalsze informacje.
Dodatkowe informacje dotyczące czcionek kodów kreskowych są dostępne na stronie: http://www.idautomation.com/.
Codabar
Właściwości
| Właściwość | Opis |
|---|
| Specyfikacja (standard) | EN 798, ANSI/AIM BC3-1995 |
| Synonimy | NW-7, USD-4, 2 of 7 |
| Obszary zastosowania | sektor medyczny (banki krwi), biblioteki, FedEx |
| Zestaw znaków (zakres) | kod numeryczny z 6 dodatkowymi znakami specjalnymi (cyfry 0–9, -, $, :, /, ., +). Długość zmienna (brak z góry określonej długości) |
| Znaki startu / stopu | znaki „A”, „B”, „C” i „D” mogą być wykorzystywane aplikacyjnie jako znaki startu lub stopu |
| Cyfra kontrolna | brak |
| Budowa | każdorazowo 4 kreski i 3 przerwy, przy czym stosowane są albo 2 szerokie i 5 wąskich elementów, albo 3 szerokie i 4 wąskie elementy |
| Samokontrola | tak |
| Współczynnik druku „V” | stosunek elementów szerokich do wąskich musi mieścić się w zakresie od 2,25:1 do 3:1 |
| Strefy ciszy | 10-krotna szerokość modułu (10 X) lub 0,1 cala (2,54 mm) |
| Gęstość informacji | 5,5 mm/cyfrę przy szerokości modułu X = 0,3 mm oraz współczynniku druku V = 3:1 |
| Zaleta | oprócz znaków 0–9 możliwe jest przedstawienie dodatkowych 6 znaków specjalnych |
| Wada | niska gęstość informa |
Czcionki
Dla Codabar dostępne są czcionki w dwóch wariantach:
-
bez tekstu (IDAutomationCB*)
-
z tekstem poniżej kodu kreskowego (IDAutomationHCB*)
Dla każdego z wariantów dostępnych jest dodatkowo 6 podwariantów różniących się wysokością kresek:
-
XS (19,2%)
-
S (34,6%)
-
M (57,7%)
-
L (100%)
-
XL (142,3%)
-
XXL (230,8%)
Zalecana wielkość czcionki dla wszystkich wariantów i podwariantów wynosi 12 punktów. Przy tej wielkości czcionki dla wszystkich wariantów i podwariantów uzyskuje się zalecaną minimalną szerokość modułu wynoszącą około 0,19 mm, czyli 7,5 mil (1 mil = 1/1000″).
Wysokość kresek zależy od wybranego podwariantu oraz wielkości czcionki. Na przykład wysokość kresek w wariancie „L” przy wielkości czcionki 12 punktów wynosi około 12,7 mm, czyli 1/2″.
Poniższe tabele przedstawiają czcionki przy wielkości 12 punktów.
Codabar bez tekstu
| Czcionka | Przykład („1234567890”) |
|---|---|
| IDAutomationCBXS | |
| IDAutomationCBS | |
| IDAutomationCBM |  |
| IDAutomationCBL |  |
| IDAutomationCBXL |  |
| IDAutomationCBXXL |  |
Codabar z tekstem
| Czcionka | Przykład („1234567890”) |
|---|---|
| IDAutomationHCBXS | |
| IDAutomationHCBS | |
| IDAutomationHCBM |  |
| IDAutomationHCBL |  |
| IDAutomationHCBXL |  |
| IDAutomationHCBXXL |  |
Funkcje dla raportów Crystal Reports
Dla Codabar dostępna jest następująca funkcja (Visual Basic UFLs):
IDAutomationFontEncoderCodabar
Funkcja ta dodaje do przekazanego ciągu znaków literę „A” na początku (znak startu) oraz literę „B” na końcu (znak stopu).
Funkcję tę można w Crystal Reports odtworzyć również jako formułę, np.:'A' + {Table.Field} + 'B'
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg znaków, który ma zostać rozszerzony o znak startu i stopu. Ciąg może zawierać wyłącznie cyfry 0–9 oraz znaki specjalne „-”, „$”, „:”, „/”, „.”, „+”. |
Przykłady
| DataToEncode | Wynik | IDAutomationHCBM (12 pt) |
|---|---|---|
| 1234567890 | A1234567890B | A1234567890B |
Kod 2/5 z przeplotem
Właściwości
| Właściwość | Opis |
|---|---|
| Specyfikacja (standard) | EN 801, ANSI/AIM BC2-1995 |
| Synonimy | USS ITF 2/5, ITF |
| Powiązane standardy | ITF-14, EAN-14, SSC-14, DUN-14 |
| Obszary zastosowania | numeracja artykułów, zastosowania przemysłowe |
| Zestaw znaków (zakres) | kod numeryczny (cyfry 0–9). Długość zmienna (brak z góry określonej długości), możliwa jest jednak wyłącznie parzysta liczba cyfr |
| Cyfra kontrolna | opcjonalna (Modulo 10) |
| Budowa | każdorazowo 2 szerokie i 3 wąskie kreski lub 2 szerokie i 3 wąskie przerwy. Cyfry są przedstawiane naprzemiennie (interleaved) przy użyciu kresek i przerw (1., 3., 5., … cyfra jako kreski; 2., 4., 6., … cyfra jako przerwa) |
| Samokontrola | tak |
| Współczynnik druku „V” | stosunek elementów szerokich do wąskich musi mieścić się w zakresie od 2:1 do 3:1 (co najmniej 2,25:1, jeżeli szerokość modułu X jest mniejsza niż 0,50 mm) |
| Strefy ciszy | 10-krotna szerokość modułu (10 X) lub 0,1 cala (2,54 mm) |
| Gęstość informacji | 2,7 mm/cyfrę przy szerokości modułu X = 0,3 mm oraz współczynniku druku V = 3:1 |
| Zaleta | wysoka gęstość informacji |
| Wada | niewielka tolerancja |
Czcionki
Dla Code 2/5 Interleaved dostępne są czcionki w dwóch wariantach:
-
bez tekstu (I25*)
-
z tekstem poniżej kodu kreskowego (HI25*)
Dla każdego z wariantów dostępnych jest dodatkowo 6 podwariantów różniących się wysokością kresek:
-
XS (12,5%)
-
S (25%)
-
M (70,8%)
-
L (100%)
-
XL (137,5%)
-
XXL (250%)
Stosunek elementów wąskich do szerokich wynosi 2,75.
Zalecana wielkość czcionki dla wszystkich wariantów i podwariantów wynosi 12 punktów. Przy tej wielkości czcionki dla wszystkich wariantów i podwariantów uzyskuje się zalecaną minimalną szerokość modułu wynoszącą około 0,21 mm, czyli 8 mil (1 mil = 1/1000″).
Wysokość kresek zależy od wybranego podwariantu oraz wielkości czcionki. Na przykład wysokość kresek w wariancie „L” przy wielkości czcionki 12 punktów wynosi około 12,7 mm, czyli 1/2″.
Poniższe tabele przedstawiają czcionki przy wielkości 12 punktów.
Code 2/5 Interleaved bez tekstu
| Czcionka | Przykład („1234567890”) |
|---|---|
| IDAutomationI25XS | |
| IDAutomationI25S | |
| IDAutomationI25M |  |
| IDAutomationI25L |  |
| IDAutomationI25XL |  |
| IDAutomationI25XXL |  |
Code 2/5 Interleaved z tekstem
| Czcionka | Przykład („1234567890”) |
|---|---|
| IDAutomationHI25XS | |
| IDAutomationHI25S |  |
| IDAutomationHI25M |  |
| IDAutomationHI25L |  |
| IDAutomationHI25XL |  |
| IDAutomationHI25XXL |  |
Funkcje dla raportów Crystal Reports
W przypadku Code 2/5 Interleaved ciągi cyfr są kodowane parami jako kreski (pierwsza cyfra) i przerwy (druga cyfra). Czcionki IDAutomationI25* oraz IDAutomationHI25* obsługują ten mechanizm przez łączenie sekwencji kresek dla takich „podwójnych cyfr” w pojedynczy znak Unicode. Aby możliwe było wygenerowanie ciągu cyfr przy użyciu tych czcionek, cyfry muszą zostać wcześniej przeliczone na sekwencję znaków Unicode. Do tego celu służy funkcja IDAutomationFontEncoderI2of5.
Funkcja ta uzupełnia również znaki startu i stopu. W przypadku Code 2/5 Interleaved cyfry kontrolne zazwyczaj nie są stosowane, ponieważ kod ten jest już „samokontrolujący”.
W niektórych zastosowaniach specjalnych wymagana jest jednak dodatkowa cyfra kontrolna (patrz ITF-14 lub SCC-14). W takich przypadkach należy zastosować funkcję IDAutomationFontEncoderI2of5Mod10.
IDAutomationFontEncoderI2of5
Funkcja ta obsługuje jako parametr wyłącznie ciągi cyfr zawierające parzystą liczbę cyfr.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg znaków przeznaczony do zakodowania jako Code 2/5 Interleaved. Dopuszczalne są cyfry (0–9), a liczba cyfr musi być parzysta (w przeciwnym razie automatycznie zostanie dodane 0 na początku). Nie należy podawać znaków startu i stopu. |
Przykłady
| DataToEncode | Wynik | IDAutomationHI25M (12 pt) |
|---|---|---|
| 1234567890 | Ë-CYo{Ì |  |
| 123456789 | Ë”8NdzÌ |  |
IDAutomationFontEncoderI2of5Mod10


Kod 39
Właściwości
| Właściwość | Opis |
|---|---|
| Specyfikacja (standard) | EN 800, ANSI/AIM BC1-1995 |
| Powiązane standardy | LOGMARS |
| Obszary zastosowania | elektronika, przemysł, administracja publiczna oraz handel |
| Zestaw znaków (zakres) | kod alfanumeryczny (cyfry 0–9, 26 liter oraz 7 znaków specjalnych). Przy użyciu kodowania dwuznakowego możliwe jest rozszerzenie na pełny zestaw znaków ASCII (patrz Rozszerzony zestaw znaków (Code 39 Extended)). Długość zmienna (brak z góry określonej długości) |
| Znaki startu / stopu | znak „*” jest używany zarówno jako znak startu, jak i znak stopu |
| Znak kontrolny | opcjonalny (Modulo 43) |
| Właściwość | Opis |
|---|---|
| Budowa | kod dyskretny. Każdorazowo 5 kresek i 4 przerwy, przy czym (z wyjątkiem znaków specjalnych) stosowane są 3 szerokie i 6 wąskich elementów. Przerwy pomiędzy znakami nie przenoszą informacji |
| Samokontrola | tak |
| Szerokość modułu „X” | w systemach otwartych szerokość modułu X nie powinna być mniejsza niż 7,5 mil (0,19 mm) |
| Współczynnik druku „V” | stosunek elementów szerokich do wąskich musi mieścić się w zakresie od 2:1 do 3:1 (co najmniej 2,25:1, jeżeli szerokość modułu X jest mniejsza niż 0,50 mm) |
| Wysokość kresek | wysokość kresek powinna wynosić co najmniej 15% całkowitej szerokości lub 0,25 cala (6,35 mm). Całkowitą szerokość można w przybliżeniu obliczyć według wzoru: B = (C + 2)16X |
| Strefy ciszy | 10-krotna szerokość modułu (10 X) lub 0,1 cala (2,54 mm) |
| Gęstość informacji | 4,8 mm/cyfrę przy szerokości modułu X = 0,3 mm oraz współczynniku druku V = 3:1 |
| Zaleta | możliwość przedstawienia znaków alfanumerycznych |
| Wada | niska gęstość informacji, niewielka tolerancja |
Rozszerzony zestaw znaków (Code 39 Extended)
Istnieje wariant Code 39, określany jako Extended Code 39, który obsługuje pełny zestaw znaków ASCII. Osiąga się to przez kodowanie wszystkich małych liter, znaków specjalnych oraz znaków sterujących jako sekwencji dwóch znaków. W tym celu znaki „+”, „/”, „%” oraz „$” są wykorzystywane jako znaki „przełączające”.
Ponieważ w Extended Code 39 znaki te są interpretowane inaczej niż w standardowym Code 39, urządzenia odczytujące muszą być odpowiednio skonfigurowane (automatyczne rozpoznanie zazwyczaj nie jest możliwe).
Extended Code 39 nie zdobył dużej popularności, ponieważ w takich zastosowaniach częściej stosowany jest Code 128. Obsługuje on również wszystkie znaki ASCII, a jednocześnie zapewnia większą gęstość zapisu.
Comarch ERP Enterprise oraz dostarczone czcionki i funkcje kodów kreskowych zapewniają jedynie ograniczone wsparcie dla Extended Code 39. Czcionki IDAutomationXC39* oraz IDAutomationXHC39* automatycznie dokonują prawidłowego odwzorowania znaków ASCII na dwuznakowe kody. Nie jest jednak dostępna specjalna funkcja służąca do dodawania znaków startu, stopu ani znaków kontrolnych – należy je dodać ręcznie.
Również spacje wymagają specjalnego traktowania (zastępowane są znakiem „~”).
Czcionki
Dla Code 39 dostępne są czcionki w dwóch wariantach:
-
bez tekstu (C39*)
-
z tekstem poniżej kresek (HC39*)
Dla rozszerzonego wariantu Code 39 (Extended Code 39) dostępne są dodatkowo dwa warianty (patrz wyżej):
-
bez tekstu (XC39*)
-
z tekstem poniżej kresek (XHC39*)
Dla każdego wariantu dostępnych jest dodatkowo 6 podwariantów różniących się wysokością kresek:
-
XS (21,2%)
-
S (42,3%)
-
M (71,2%)
-
L (100%)
-
XL (150%)
-
XXL (227,3%)
Zalecana wielkość czcionki dla wszystkich wariantów i podwariantów wynosi 12 punktów. Przy tej wielkości czcionki dla wszystkich wariantów i podwariantów uzyskuje się zalecaną minimalną szerokość modułu wynoszącą około 0,21 mm, czyli 8 mil (8/1000″). Wysokość kresek zależy od wybranego podwariantu oraz wielkości czcionki.
Na przykład wysokość kresek w wariancie „L” przy wielkości czcionki 12 punktów wynosi około 12,7 mm, czyli 1/2″.
Poniższe tabele przedstawiają czcionki przy wielkości 12 punktów.
Code 39 bez tekstu
| Czcionka | Przykład („12345ABCDE“) |
|---|---|
| IDAutomationC39XS | |
| IDAutomationC39S | |
| IDAutomationC39M |  |
| IDAutomationC39L |  |
| IDAutomationC39XL |  |
| IDAutomationC39XXL |  |
Code 39 z tekstem
| Czcionka | Przykład („12345ABCDE“) |
|---|---|
| IDAutomationHC39XS | |
| IDAutomationHC39S |  |
| IDAutomationHC39M |  |
| IDAutomationHC39L |  |
| IDAutomationHC39XL |  |
| IDAutomationHC39XXL |  |
Code 39 Extended bez tekstu
| Czcionka | Przykład („1234ABCabc“) |
|---|---|
| IDAutomationXC39XS | |
| IDAutomationXC39S | |
| IDAutomationXC39M |  |
| IDAutomationXC39L |  |
| IDAutomationXC39XL |  |
| IDAutomationXC39XXL |  |
Code 39 Extended z tekstem
| Czcionka | Przykład („1234ABCabc“) |
|---|---|
| IDAutomationXC39XS | |
| IDAutomationXC39S |  |
| IDAutomationXC39M |  |
| IDAutomationXC39L |  |
| IDAutomationXC39XL |  |
| IDAutomationXC39XXL |  |
Funkcje dla raportów Crystal Reports
Dla Code 39 dostępne są następujące funkcje (Visual Basic UFLs):
-
IDAutomationFontEncoderCode39
-
IDAutomationFontEncoderCode39Mod43
Pierwsza funkcja dodaje jedynie znaki startu i stopu („!”), pozostawiając przekazane dane bez zmian (wyjątek stanowią spacje). Druga funkcja dodatkowo wstawia znak kontrolny (Modulo 43), lecz poza tym działa identycznie.
Dla Code 39 Extended nie są dostępne specjalne funkcje. W przypadku użycia czcionek IDAutomationC39* lub IDAutomationHC39* można stosować funkcje przeznaczone dla Code 39. Należy jednak pamiętać, że wymagane dla rozszerzonego zestawu znaków kodowanie nie jest realizowane przez te funkcje – dodają one jedynie znaki startu, stopu oraz ewentualnie znak kontrolny.
Funkcje przeznaczone dla Code 39 nie są kompatybilne z czcionkami IDAutomationXC39* ani IDAutomationXHC39*. Czcionki te samodzielnie realizują wymagane kodowanie dwuznakowe dla rozszerzonego zestawu znaków. Znaki startu i stopu („*”) należy jednak dodać ręcznie (np. za pomocą formuły). Jeżeli wymagany jest znak kontrolny, musi on zostać również obliczony i dodany ręcznie.
W takim przypadku zastosowanie tych czcionek przynosi niewielkie korzyści i zaleca się zamiast tego użycie czcionek IDAutomationC39* lub IDAutomationHC39* (czyli ręczne kodowanie rozszerzonego zestawu znaków, natomiast cyfra kontrolna dodawana za pomocą funkcji).
IDAutomationFontEncoderCode39
Funkcja ta dodaje na początku i na końcu przekazanego ciągu znaków znak „!”. Znak ten jest interpretowany przez czcionki IDAutomationC39* oraz IDAutomationHC39* jako znak startu i stopu.
W przeciwieństwie do funkcji IDAutomationFontEncoderCode128 przekazane znaki zazwyczaj nie są przekształcane. Wyjątek stanowią spacje, które są zastępowane znakiem „=”. Czcionka IDAutomationC39* została zaprojektowana w taki sposób, aby ze znaku „=” generować kod kreskowy odpowiadający znakowi spacji.
Uwaga: w przypadku czcionek IDAutomationC39* oraz IDAutomationHC39* zarówno znak „*”, jak i „!” mogą być używane do generowania znaków startu i stopu. W czcionkach IDAutomationXC39* oraz IDAutomationXHC39* dla Code 39 Extended dozwolony jest wyłącznie znak „*”, dlatego funkcja ta nie może być stosowana z tymi czcionkami.
Uwaga: pod warunkiem, że w danych nie występują spacje, funkcję tę można w Crystal Reports łatwo odtworzyć jako formułę, na przykład:
'*' + {Table.Field} + '*'
Formuła ta działa również z czcionkami IDAutomationXC39* oraz IDAutomationXHC39*.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg znaków, który ma zostać rozszerzony o znaki startu i stopu |
Przykłady
| DataToEncode | Wynik | IDAutomationHC39M (12 pt) |
|---|---|---|
| 1234567890 | !1234567890! |  |
| ABCDEFGHIJ | !ABCDEFGHIJ! |  |
| abcdefghij | !abcdefghij! |  |
| +A+B+C+D+E | !+A+B+C+D+E! |  |
IDAutomationFontEncoderCode39Mod43
Funkcja ta dodaje na początku i na końcu przekazanego ciągu znaków znak „!”. W razie potrzeby spacje są przekształcane w znak „=” (patrz IDAutomationFontEncoderCode39). Dodatkowo obliczany jest znak kontrolny (Modulo 43), który zostaje wstawiony przed znakiem stopu.
Uwaga: podobnie jak IDAutomationFontEncoderCode39, funkcja ta nie jest kompatybilna z czcionkami IDAutomationXC39* oraz IDAutomationXHC39*.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg znaków, który ma zostać rozszerzony o znak startu, znak kontrolny oraz znak stopu. Małe litery są automatycznie zamieniane na wielkie litery. |
| ReturnType | wartość numeryczna określająca, jakie dane mają zostać zwrócone przez funkcję: 0 – wymagany ciąg znaków dla czcionek IDAutomationC39* lub IDAutomationHC39* wraz ze wszystkimi znakami sterującymi (np. znaki startu, znak kontrolny i znak stopu). 1 – dane w postaci czytelnej wraz ze znakiem kontrolnym, ale bez znaków startu i stopu. 2 – wyłącznie znak kontrolny. |
Przykłady
| DataToEncode | Wynik (0, 1, 2) | IDAutomationHC39M (12 pt) |
|---|---|---|
| 1234567890 | !12345678902!, 12345678902, 2 | !12345678902! |
| ABCDEFGHIJ | !ABCDEFGHIJG!, ABCDEFGHIJ, G | !ABCDEFGHIJG! |
| abcdefghij | !ABCDEFGHIJG!, ABCDEFGHIJ, G | !ABCDEFGHIJG! |
| +A+B+C+D+E | !+A+B+C+D+E7!, +A+B+C+D+E7, 7 | !+A+B+C+D+E7! |
Kod 128
Kod 128 to uniwersalny kod kreskowy, który obsługuje wszystkie 128 znaków z zestawu znaków ASCII.
Właściwości
| Właściwość | Opis |
|---|
| Specyfikacja (standard) | EN 799, ANSI/AIM BC4-1999 |
| Powiązane standardy | EAN/UCC 128, SSCC-18, SCC-14 |
| Obszary zastosowania | logistyka |
| Zestaw znaków (zakres) | • wszystkie 128 znaków ASCII (0–127) • 4 znaki sterujące (FCN1–FCN4) • 4 znaki sterujące do wyboru zestawu znaków • 3 znaki startu • 1 znak stopu |
| Długość | zmienna (brak z góry określonej długości) |
| Znaki startu / stopu | specjalne, niedrukowalne kody. Trzy różne kody startowe (do wyboru zestawu znaków) |
| Cyfra kontrolna | obowiązkowa (Modulo 103) |
| Budowa | kod ciągły z czterema różnymi szerokościami elementów (1-, 2-, 3- i 4-krotność). Każdy znak składa się z 3 kresek i 3 przerw, które łącznie mają zawsze szerokość 11 modułów (X). Jedyny wyjątek stanowi znak stopu, który składa się z 4 kresek i 3 przerw i ma łącznie szerokość 13 modułów. |
| Samokontrola | tak |
| Odczyt dwukierunkowy | tak |
| Szerokość modułu „X” | w systemach otwartych szerokość modułu X nie powinna być mniejsza niż 7,5 mil (0,19 mm) |
| Strefy ciszy | 10-krotna szerokość modułu (10 X) lub 0,1 cala (2,54 mm) |
| Gęstość informacji | 11 modułów/znak (5,5 modułu/znak w zestawie znaków C) |
| Narzut | 35 modułów (znaki startu, kontrolny i stopu) |
| Zaleta | możliwość przedstawienia znaków alfanumerycznych |
| Wada | niewielka tolerancja |
Czcionki
Dla Code 128 dostępne są czcionki w trzech wariantach:
-
bez tekstu (C128*)
-
z tekstem (zestaw znaków „B”) poniżej kresek (HbC128*)
-
z tekstem (zestaw znaków „C”) poniżej kresek (HcC128*)
Uwaga: wersje z tekstem są rzadko stosowane, ponieważ zawierają również znak kontrolny (Modulo 103). Zazwyczaj zaleca się użycie wariantu bez tekstu oraz dodatkowe wydrukowanie danych jako tekstu przy użyciu standardowej czcionki nad lub pod kodem kreskowym.
Dla każdego wariantu dostępnych jest dodatkowo 6 podwariantów różniących się wysokością kresek:
-
XS (12,5%)
-
S (25%)
-
M (50%)
-
L (100%)
-
XL (125%)
-
XXL (200%)
Zalecana wielkość czcionki dla wszystkich wariantów i podwariantów wynosi 12 punktów. Przy tej wielkości czcionki dla wszystkich wariantów i podwariantów uzyskuje się zalecaną minimalną szerokość modułu wynoszącą około 0,21 mm, czyli 8 mil (8/1000″).
Wysokość kresek zależy od wybranego podwariantu oraz wielkości czcionki. Na przykład wysokość kresek w wariancie „L” przy wielkości czcionki 12 punktów wynosi około 12,7 mm, czyli 1/2″.
Poniższe tabele przedstawiają czcionki przy wielkości 12 punktów.
Code 128 bez tekstu
| Czcionka | Przykład („1234ABCabc“) |
|---|---|
| IDAutomationC128XS | Í,BÈABCabc(Î |
| IDAutomationC128S | Í,BÈABCabc(Î |
| IDAutomationC128M | Í,BÈABCabc(Î |
| IDAutomationC128L | Í,BÈABCabc(Î |
| IDAutomationC128XL | Í,BÈABCabc(Î |
| IDAutomationC128XXL | Í,BÈABCabc(Î |
Code 128 z tekstem (zestaw znaków „B”)
| Czcionka | Przykład („1234ABCabc“) |
|---|---|
| IDAutomationHbC128XS | Ì1234ABCabc.Î |
| IDAutomationHbC128S | Ì1234ABCabc.Î |
| IDAutomationHbC128M | Ì1234ABCabc.Î |
| IDAutomationHbC128L | Ì1234ABCabc.Î |
| IDAutomationHbC128XL | Ì1234ABCabc.Î |
| IDAutomationHbC128XXL | Ì1234ABCabc.Î |
Code 128 z tekstem (zestaw znaków „C”)
| Czcionka | Przykład („1234567890“) |
|---|---|
| IDAutomationHcC128XS | Í,BXnzuÎ |
| IDAutomationHcC128S | Í,BXnzuÎ |
| IDAutomationHcC128M | Í,BXnzuÎ |
| IDAutomationHcC128L | Í,BXnzuÎ |
| IDAutomationHcC128XL | Í,BXnzuÎ |
| IDAutomationHcC128XXL | Í,BXnzuÎ |
Funkcje dla raportów Crystal Reports
W celu wykonania obliczeń wymaganych dla Code 128 (znak kontrolny) oraz przekształceń zestawu znaków dostępne są następujące funkcje (Visual Basic UFLs):
-
IDAutomationFontEncoderCode128
-
IDAutomationFontEncoderCode128a
-
IDAutomationFontEncoderCode128b
-
IDAutomationFontEncoderCode128c
W większości przypadków zaleca się stosowanie funkcji IDAutomationFontEncoderCode128, ponieważ obsługuje ona pełny zestaw znaków ASCII oraz automatycznie dobiera odpowiednie i optymalne zestawy znaków dla Code 128.
IDAutomationFontEncoderCode128
Funkcja ta obsługuje wszystkie znaki ASCII od 0 do 127. Wymagany lub optymalny zestaw znaków jest wybierany automatycznie, a w razie potrzeby dynamicznie zmieniany. Obsługiwany jest również standard EAN/UCC-128. Dodatkowe informacje na ten temat znajdują się w sekcji EAN/UCC 128.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg znaków przeznaczony do zakodowania jako Code 128. Dozwolone są wszystkie znaki ASCII (0–127). Nie należy podawać znaków startu, kontrolnych ani znaków stopu. |
| ReturnType | wartość numeryczna określająca, jakie dane mają zostać zwrócone przez funkcję: 0 – wymagany ciąg znaków dla czcionki IDAutomationC128 wraz ze wszystkimi znakami sterującymi (np. znaki startu, kontrolny i stopu). 1 – dane w postaci czytelnej, czyli w ASCII, bez znaków startu, stopu i innych znaków sterujących specyficznych dla Code 128. 2 – wyłącznie znak kontrolny. |
Przykłady
| DataToEncode | Wynik (0, 1, 2) | IDAutomationC128M (12 pt) |
|---|---|---|
| 1234567890 | Í,BXnzuÎ, 1234567890, u | Í,BXnzuÎ |
| ABCDEFGHIJ | ÌABCDEFGHIJvÎ, ABCDEFGHIJ, v | ÌABCDEFGHIJvÎ |
| abcdefghij | ÌabcdefghijÃÎ, abcdefghij, Ã | ÌabcdefghijÃÎ |
IDAutomationFontEncoderCode128a
Funkcja ta akceptuje wyłącznie znaki z zestawu znaków „B” (ASCII 32–127), jednak generuje je w taki sposób, aby skaner rozpoznawał je jako znaki z zestawu „A” (ASCII 0–95). Może to być przydatne w sytuacjach, gdy wymagane są znaki sterujące z zestawu „A”, ale nie mogą być one bezpośrednio wprowadzone lub przekazane.
Przykładowo, jeżeli wymagany jest znak ASCII 0 (NUL), zamiast niego należy przekazać znak „`” (ASCII 96).
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg znaków przeznaczony do zakodowania jako Code 128 (zestaw znaków „A”). Dozwolone są wyłącznie znaki z zestawu „B” (ASCII 32–127). Nie należy podawać znaków startu, kontrolnych ani znaków stopu. |
Przykłady
| DataToEncode | Wynik | IDAutomationC128M (12 pt) |
|---|---|---|
| 1234567890 | Ë1234567890@Î | Ë1234567890@Î |
| ABCDEFGHIJ | ËABCDEFGHIJuÎ | ËABCDEFGHIJuÎ |
| abcdefghij | Ëabcdefghij~Î | Ëabcdefghij~Î |
IDAutomationFontEncoderCode128b
Funkcja ta akceptuje wyłącznie znaki z zestawu znaków „B” (ASCII 32–127) i zwraca je w tej samej postaci, co oznacza, że skaner odczyta dokładnie tę samą sekwencję znaków.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg znaków przeznaczony do zakodowania jako Code 128 (zestaw znaków „B”). Dozwolone są wyłącznie znaki z zestawu „B” (ASCII 32–127). Nie należy podawać znaków startu, kontrolnych ani znaków stopu. |
Przykłady
| DataToEncode | Wynik | IDAutomationHbC128M (12 pt) |
|---|---|---|
| 1234567890 | Ì1234567890AÎ | Ì1234567890AÎ |
| ABCDEFGHIJ | ÌABCDEFGHIJvÎ | ÌABCDEFGHIJvÎ |
| abcdefghij | ÌabcdefghijÃÎ | ÌabcdefghijÃÎ |
IDAutomationFontEncoderCode128c
Za pomocą tej funkcji możliwe jest bardzo efektywne kodowanie ciągów numerycznych. W zestawie znaków „C” każdej parze cyfr odpowiada jeden kod. Funkcja ta akceptuje zatem wyłącznie cyfry (0–9), a liczba cyfr musi być zawsze parzysta.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg cyfr przeznaczony do zakodowania jako Code 128. Liczba cyfr musi być parzysta. Nie należy podawać znaków startu, kontrolnych ani znaków stopu. |
| ReturnType | wartość numeryczna określająca, jakie dane mają zostać zwrócone przez funkcję: 0 – wymagany ciąg znaków dla czcionki IDAutomationC128 lub IDAutomationHcC128 wraz ze wszystkimi znakami sterującymi (np. znaki startu, kontrolny i stopu). 1 – dane w postaci czytelnej, czyli w ASCII, bez znaków startu, stopu i innych znaków sterujących specyficznych dla Code 128. 2 – wyłącznie znak kontrolny. |
Przykłady
| DataToEncode | Wynik (0, 1, 2) | IDAutomationHcC128M (12 pt) |
|---|---|---|
| 1234567890 | Í,BXnzuÎ, 123456789085, 85 | Í,BXnzuÎ |
| 123456789 | Í!7McyiÎ, 012345678973, 73 | Í!7McyiÎ |
EAN-8
EAN-8 jest wariantem EAN-13 i jest stosowany w przypadku, gdy na opakowaniu nie ma wystarczającej ilości miejsca na kod EAN-13. Oszczędność miejsca wynika z pominięcia kodu producenta.
W konsekwencji kod produktu nie może być już nadawany przez producenta, lecz musi zostać uzyskany w (krajowej) organizacji EAN.
Zmniejszenie liczby znaków skutkuje krótszym kodem kreskowym, a tym samym również mniejszą wysokością kresek.
Właściwości
Ogólne właściwości EAN-8 są identyczne z właściwościami EAN-13 i dlatego nie są tutaj ponownie przedstawiane.
Czcionki
EAN-8, podobnie jak EAN-13, jest generowany przy użyciu czcionki IDAutomationUPCEAN*. Ogólne informacje dotyczące tej czcionki, jej wariantów oraz wskazówki dotyczące drukowania znajdują się w odpowiedniej sekcji dotyczącej EAN-13.
Standard EAN-8 definiuje – analogicznie do EAN-13 – „rozmiar nominalny”. W tym rozmiarze szerokość modułu („X”) wynosi 0,330 mm (tak jak w EAN-13). Całkowite wymiary symbolu (łącznie ze strefami ciszy oraz tekstem czytelnym) wynoszą 26,73 mm × 21,31 mm. Zaleca się, aby rozmiar nominalny był zachowany.
Dopuszczalne są jednak współczynniki powiększenia w zakresie od 0,8 do 2,0, co umożliwia optymalizację jakości druku dla danego urządzenia wyjściowego.
Aby wygenerować symbol EAN-8 w rozmiarze nominalnym, należy zastosować wariant „M” czcionki (IDAutomationUPCEANM) w wielkości 20 punktów. Wspomniane współczynniki powiększenia (0,8–2,0) odpowiadają wielkościom czcionki od 18 do 36 punktów. Pozostałe warianty czcionek (XSnoHR, XS, S, L) nie spełniają zaleceń dla EAN-8, jednak mogą być użyteczne w specyficznych zastosowaniach.
Poniższa tabela przedstawia przybliżone proporcje dla wielkości 20 punktów:
| XSnoHR | XS | S | M | L | |
|---|---|---|---|---|---|
| Szerokość modułu (X) | 0,330 mm | ||||
| Szerokość całkowita | 26,73 mm | ||||
| Wysokość całkowita | 8,0 mm | 10,4 mm | 16,5 mm | 21,2 mm | 25,9 mm |
| Wysokość kresek | 8,0 mm | 6,2 mm | 12,8 mm | 17,8 mm | 22,8 mm |
Poniższa tabela przedstawia przykłady wariantów czcionki przy wielkości 20 punktów:
| Czcionka | Przykład („4012345“) |
|---|---|
| IDAutomationUPCEANXSnoHR | (4012*NOPP( |
| IDAutomationUPCEANXS | (4012*NOPP( |
| IDAutomationUPCEANS | (4012*NOPP( |
| IDAutomationUPCEANM | (4012*NOPP( |
| IDAutomationUPCEANL | (4012*NOPP( |
Funkcje dla Crystal Reports
Aby możliwe było wykorzystanie czcionek IDAutomationUPCEAN*, dane muszą zostać odpowiednio przygotowane. Dla standardu EAN-8 należy zastosować funkcję IDAutomationFontEncoderEAN8.
IDAutomationFontEncoderEAN8
Funkcja ta oblicza ciąg znaków wymagany przez czcionkę IDAutomationUPCEAN*.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg cyfr przeznaczony do zakodowania jako EAN-8. Dozwolone są cyfry od 0 do 9. Oprócz 7 cyfr danych można również podać cyfrę kontrolną (patrz przykłady poniżej). W takim przypadku podana cyfra kontrolna nie jest wykorzystywana – zawsze jest ona obliczana na podstawie danych. Przekazany ciąg znaków może zawierać znak „-”, np. w celu poprawy czytelności. Znaki te są automatycznie usuwane i nie są uwzględniane jako dane. W przypadku nieprawidłowych danych generowany jest kod EAN-8 składający się wyłącznie z zer. |
Przykłady
| DataToEncode | Wynik | IDAutomationUPCEANL (20 pt) |
|---|---|---|
| 4012345 | (4012*NOPP( | (4012*NOPP( |
| 40123455 | (4012*NOPP( | (4012*NOPP( |
| 40123451 | (4012*NOPP( | (4012*NOPP( |
| 40-12345 | (4012*NOPP( | (4012*NOPP( |
| ABC | (0000*KKKK( | (0000*KKKK( |
| 1234 | (0000*KKKK( | (0000*KKKK( |
EAN-13
Standard EAN-13 został opracowany przez organizację International Article Numbering Association (EAN). Opiera się on na standardzie UPC-A (patrz UPC-A) i w przeciwieństwie do niego został zaprojektowany do zastosowań międzynarodowych.
Właściwości
| Właściwość | Opis |
|---|
| Specyfikacja (standard) | EN 797 |
| Powiązane standardy | EAN-8, UPC-A, JAN |
| Obszary zastosowania | handel (POS) |
| Zestaw znaków (zakres) | kod numeryczny, cyfry (0–9) |
| Długość | stała długość: 12 cyfr + cyfra kontrolna; opcjonalne rozszerzenie o 2 lub 5 cyfr |
| Budowa | 11 elementów. Wszystkie kreski i przerwy przenoszą informację. |
| Samokontrola | tak |
| Zaleta | wysoka gęstość informacji |
| Wada | bardzo małe tolerancje |
Czcionki
Kody kreskowe dla EAN-13, EAN-8, UPC-A, UPC-E oraz JAN są generowane przy użyciu czcionki IDAutomationUPCEAN. Czcionka ta jest dostępna w 5 wariantach: cztery z tekstem (XS, S, M, L) oraz jeden bez tekstu (XSnoHR).
Standard EAN-13 definiuje „rozmiar nominalny”. W tym rozmiarze szerokość modułu („X”) wynosi 0,330 mm. Całkowite wymiary symbolu (łącznie ze strefami ciszy oraz tekstem czytelnym) wynoszą 37,29 mm × 25,91 mm. Zaleca się, aby rozmiar nominalny był zachowany.
Dopuszczalne są jednak współczynniki powiększenia w zakresie od 0,8 do 2,0, co umożliwia optymalizację jakości druku dla danego urządzenia wyjściowego.
Aby wygenerować symbol EAN-13 w rozmiarze nominalnym, należy zastosować wariant „L” czcionki (IDAutomationUPCEANL) w wielkości 20 punktów. Wspomniane współczynniki powiększenia (0,8–2,0) odpowiadają wielkościom czcionki od 18 do 36 punktów.
Przy wyborze konkretnej wielkości czcionki należy uwzględnić rozdzielczość drukarki, ponieważ wynikają z niej zarówno minimalne wielkości, jak i możliwe wartości skokowe. Przykładowo firma IDAutomation, Inc. zaleca przy rozdzielczości 300 dpi lub 203 dpi stosowanie wielkości czcionki 20 pt lub 25 pt albo wartości większych niż 30 pt.
Pozostałe warianty czcionek (XSnoHR, XS, S, M) nie spełniają zaleceń dla EAN-13. Przy zbyt małej wysokości może zostać utracona możliwość odczytu symbolu niezależnie od jego orientacji. W specyficznych zastosowaniach czcionki te mogą jednak być użyteczne.
Poniższa tabela przedstawia przybliżone proporcje dla wielkości 20 punktów:
| XSnoHR | XS | S | M | L | |
|---|---|---|---|---|---|
| Szerokość modułu (X) | 0,330 mm | ||||
| Szerokość całkowita | 37,3 mm | ||||
| Wysokość całkowita | 8,0 mm | 10,4 mm | 16,5 mm | 21,2 mm | 25,9 mm |
| Wysokość kresek | 8,0 mm | 6,2 mm | 12,8 mm | 17,8 mm | 22,8 mm |
Poniższa tabela przedstawia przykłady wariantów czcionki przy wielkości 20 punktów:
| Czcionka | Przykład („401234567890“) |
|---|---|
| IDAutomationUPCEANXSnoHR | Y(0B23EF*QRSTKL( |
| IDAutomationUPCEANXS | Y(0B23EF*QRSTKL( |
| IDAutomationUPCEANS | Y(0B23EF*QRSTKL( |
| IDAutomationUPCEANM | Y(0B23EF*QRSTKL( |
| IDAutomationUPCEANL | Y(0B23EF*QRSTKL( |
Funkcje dla Crystal Reports
Aby możliwe było wykorzystanie czcionek IDAutomationUPCEAN*, dane muszą zostać odpowiednio przygotowane. Dla standardu EAN-13 należy zastosować funkcję IDAutomationFontEncoderEAN13.
IDAutomationFontEncoderEAN13
Funkcja ta oblicza ciąg znaków wymagany przez czcionkę IDAutomationUPCEAN*.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg cyfr przeznaczony do zakodowania jako EAN-13. Dozwolone są cyfry (0–9). Oprócz 12 cyfr danych można również podać cyfrę kontrolną oraz/lub dwu- lub pięciocyfrowy kod dodatkowy (Add-On) – patrz przykłady poniżej. Podana cyfra kontrolna nie jest wykorzystywana, ponieważ zawsze jest obliczana na podstawie danych. Przekazany ciąg znaków może zawierać znaki „-” oraz „+”, np. w celu poprawy czytelności. Znaki te są automatycznie usuwane i nie są uwzględniane jako dane. W przypadku nieprawidłowych danych generowany jest kod EAN-13 składający się wyłącznie z zer. |
Przykłady
| DataToEncode | Wynik | IDAutomationUPCEANL (20 pt) |
|---|---|---|
| 401234567890 | Y(0B23EF*QRSTKL( | Y(0B23EF*QRSTKL( |
| 4012345678901 | Y(0B23EF*QRSTKL( | Y(0B23EF*QRSTKL( |
| 4012345678902 | Y(0B23EF*QRSTKL( | Y(0B23EF*QRSTKL( |
| 40-12345-67890 | Y(0B23EF*QRSTKL( | Y(0B23EF*QRSTKL( |
| DataToEncode | Wynik | IDAutomationUPCEANL (20 pt) |
|---|---|---|
| 40123456789012 | Y(0B23EF*QRSTKL( +#!$ | Y(0B23EF*QRSTKL( +#!$ |
| 401234567890112 | Y(0B23EF*QRSTKL( +#!$ | Y(0B23EF*QRSTKL( +#!$ |
| 40-12345-67890+12 | Y(0B23EF*QRSTKL( +#!$ | Y(0B23EF*QRSTKL( +#!$ |
| 40-12345-67890-1+12 | Y(0B23EF*QRSTKL( +#!$ | Y(0B23EF*QRSTKL( +#!$ |
| DataToEncode | Wynik | IDAutomationUPCEANL (20 pt) |
|---|---|---|
| 40123456789012345 | Y(0B23EF*QRSTKL( +=!$!@!&!, | Y(0B23EF*QRSTKL( +=!$!@!&!, |
| 401234567890112345 | Y(0B23EF*QRSTKL( +=!$!@!&!, | Y(0B23EF*QRSTKL( +=!$!@!&!, |
| 40-12345-67890+12345 | Y(0B23EF*QRSTKL( +=!$!@!&!, | Y(0B23EF*QRSTKL( +=!$!@!&!, |
| 40-12345-67890-1+12345 | Y(0B23EF*QRSTKL( +=!$!@!&!, | Y(0B23EF*QRSTKL( +=!$!@!&!, |
| ABC | U(000000*KKKKKK( | U(000000*KKKKKK( |
| 1234 | U(000000*KKKKKK( | U(000000*KKKKKK( |
| 4012345678901234 | U(000000*KKKKKK( | U(000000*KKKKKK( |
EAN/UCC 128
Standard EAN/UCC 128 nie definiuje własnej symboliki, lecz specjalny format danych. Format ten umożliwia zakodowanie wielu informacji jednocześnie w jednym kodzie kreskowym.
Znaczenie poszczególnych informacji jest określane przez tak zwane Application Identifier (AI), które są każdorazowo umieszczane jako prefiks przed właściwymi danymi.
Właściwości
Z technicznego punktu widzenia EAN-128 opiera się na symbolice Code 128. Różnica polega jedynie na tym, że bezpośrednio po znaku startu wstawiany jest dodatkowy znak sterujący (FCN1).
Standard EAN-128 definiuje minimalną szerokość modułu równą 0,250 mm (0,00984″) oraz maksymalną szerokość modułu równą 1,016 mm (0,040″). W zależności od zastosowania mogą obowiązywać dodatkowe, bardziej restrykcyjne ograniczenia. Minimalna wysokość kresek została określona na poziomie 32 mm (1,25″).
Application Identifier
Application Identifier (AI) określa nie tylko znaczenie następujących po nim danych, lecz także ich długość oraz format. Dla niektórych AI zdefiniowana jest stała długość, natomiast dla innych długość jest zmienna (do 30 znaków). W zależności od AI dane mogą mieć charakter numeryczny lub alfanumeryczny. AI definiują również format daty oraz liczbę miejsc po przecinku.
Poniższa tabela przedstawia przykładowe identyfikatory AI:
| AI | Zawartość danych | Format |
|---|---|---|
| 00 | Serial Shipping Container Code (SSCC) – numer jednostki wysyłkowej (NVE) | 18 cyfr |
| 01 | Shipping Container Code (SCC) – EAN jednostki handlowej | 14 cyfr |
| 02 | numer EAN towarów zawartych w jednostce transportowej | 14 cyfr |
| 10 | numer partii / numer serii | 1–20 znaków |
| 11 | data produkcji | 6 cyfr (YYMMDD) |
| 12 | termin płatności | 6 cyfr (YYMMDD) |
| 13 | data pakowania | 6 cyfr (YYMMDD) |
| 15 | data minimalnej trwałości | 6 cyfr (YYMMDD) |
| 17 | data ważności | 6 cyfr (YYMMDD) |
| 20 | wariant produktu | 2 cyfry |
| 21 | numer seryjny | 1–20 znaków |
| 22 | HIBCC Quantity, Date, Batch and Link | 1–29 znaków |
| 23x | numer partii (rozwiązanie przejściowe) | 1–19 znaków |
| 240 | dodatkowa identyfikacja produktu producenta | 1–30 znaków |
| 241 | numer części klienta | 1–30 znaków |
| 250 | numer seryjny zintegrowanego komponentu | 1–30 znaków |
| 251 | odniesienie do jednostki podstawowej | 1–30 znaków |
| 30 | ilość (jednostka handlowa o zmiennej ilości) | 1–8 cyfr |
| 310y | masa netto w kilogramach | 6 cyfr |
| 311y | długość / wymiar 1 w metrach | 6 cyfr |
| 312y | szerokość / wymiar 2 w metrach | 6 cyfr |
| 313y | wysokość / wymiar 3 w metrach | 6 cyfr |
| 314y | powierzchnia w metrach kwadratowych | 6 cyfr |
| 315y | objętość netto w litrach | 6 cyfr |
| 316y | objętość netto w metrach sześciennych | 6 cyfr |
| 330y | masa brutto w kilogramach | 6 cyfr |
| 331y | długość kontenera / wymiar 1 w metrach | 6 cyfr |
| 332y | szerokość kontenera / wymiar 2 w metrach | 6 cyfr |
| 333y | wysokość kontenera / wymiar 3 w metrach | 6 cyfr |
| 334y | powierzchnia kontenera w metrach kwadratowych | 6 cyfr |
| 335y | objętość brutto w litrach | 6 cyfr |
| 336y | objętość brutto w metrach sześciennych | 6 cyfr |
| 37 | liczba jednostek handlowych w jednostce transportowej | 1–8 cyfr |
| 400 | numer zamówienia klienta | 1–29 znaków |
| 410 | „dostawa do” – numer identyfikacyjny jednostki | 13 cyfr |
| 411 | „faktura do” – numer identyfikacyjny jednostki | 13 cyfr |
| 412 | „dostawa od” – numer identyfikacyjny jednostki | 13 cyfr |
| 420 | „dostawa do” – kod pocztowy (krajowy) | 1–9 znaków |
| 421 | „dostawa do” – kod kraju ISO + kod pocztowy | 4–12 znaków |
| 8001 | produkty w rolkach: szerokość, długość, średnica rdzenia | 14 cyfr |
| 8002 | Electronic Serial Number (ESN) dla telefonów komórkowych | 1–20 znaków |
| 8003 | identyfikacja EAN/UCC dla opakowań wielokrotnego użytku (GRAI) | 14 cyfr + 1–16 znaków |
| 8004 | identyfikacja EAN/UCC dla obiektów indywidualnych (GIAI) | 1–30 znaków |
| 8005 | cena jednostkowa | 6 cyfr |
| 8020 | numer referencyjny płatności | 1–25 znaków |
| 90 | dane uzgodnione między partnerami handlowymi | 1–30 znaków |
| 91–96 | wewnętrzne kody przedsiębiorstwa (np. materiały, transport) | 1–30 znaków |
| 97–99 | wewnętrzne kody przedsiębiorstwa (handel, dowolny tekst) | 1–30 znaków |
Czcionki
Dla EAN/UCC-128 wykorzystywana jest czcionka IDAutomationC128* (Code 128).
Funkcje dla Crystal Reports
Następujące funkcje (Visual Basic UFL) są dostępne do wykonywania obliczeń (znaki kontrolne) i konwersji zestawów znaków wymaganych dla EAN 128:
– IDAutomationFontEncoderCode128
– IDAutomationFontEncoderCodeUCC128
– IDAutomationFontEncoderCodeSCC14
– IDAutomationFontEncoderCodeSSCC18
– IDAutomationFontEncoderCodeUSPSEAN128 (patrz USPS)
– IDAutomationFontEncoderCodeMod10
IDAutomationFontEncoderCode128
Ogólne właściwości tej funkcji opisano w sekcji IDAutomationFontEncoderCode128. W niniejszej sekcji przedstawiono właściwości specyficzne dla EAN-128.
W przeciwieństwie do funkcji IDAutomationFontEncoderCodeUCC128, IDAutomationFontEncoderCodeSCC14, IDAutomationFontEncoderCodeSSCC18 lub IDAutomationFontEncoderCodeUSPSEAN128, w tym przypadku wymagany dla EAN-128 znak sterujący „FCN1” musi zostać podany jawnie. Dodatkowe kody FCN1 mogą być wymagane przy stosowaniu identyfikatorów AI o zmiennej długości.
Aby wstawić kod FCN1 do kodu kreskowego, należy wprowadzić do kodowanej sekwencji znak Unicode 0xCA (Ê).
Uwaga:
W zależności od AI (np. 00 i 01) niektóre dane wymagają dodatkowej cyfry kontrolnej (Modulo 10). Jeżeli nie jest ona dostępna, można ją obliczyć za pomocą funkcji IDAutomationFontEncoderCodeMod10.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg znaków przeznaczony do zakodowania jako Code 128. Dozwolone są wszystkie znaki ASCII (0–127). Nie należy podawać znaków startu, kontrolnych ani znaków stopu. |
| ReturnType | wartość numeryczna określająca, jakie dane mają zostać zwrócone przez funkcję: 0 – wymagany ciąg znaków dla czcionki IDAutomationC128 wraz ze wszystkimi znakami sterującymi (np. znaki startu, kontrolny i stopu). 1 – dane w postaci czytelnej (ASCII), bez znaków startu i stopu oraz innych znaków sterujących specyficznych dla Code 128, jednak z ewentualnym dodatkowym formatowaniem. 2 – wyłącznie znak kontrolny. |
Przykłady
| DataToEncode | RT | Wynik | IDAutomationC128L (20 pt) |
|---|---|---|---|
| Ê0174012345678900 | 0 | ÍÊ!j!7McyÂLÎ | ÍÊ!j!7McyÂLÎ |
| Ê0174012345678900 | 1 | (01) 74012345678900 | |
| Ê0174012345678900 | 2 | L | |
| Ê0012345678901234567 | 0 | ÍÊÂ,BXnz,BXkJÎ | ÍÊÂ,BXnz,BXkJÎ |
| Ê0012345678901234567 | 1 | (00) 123456789012345675 | |
| Ê0012345678901234567 | 2 | J | |
| Ê0114012345678908Ê15041231Ê101234 | 0 | ÍÊ!.!7Mcy(Ê/$,?Ê*,BJÎ | ÍÊ!.!7Mcy(Ê/$,?Ê*,BJÎ |
| Ê0114012345678908Ê15041231Ê101234 | 1 | (01) 14012345678908 (15) 041231 (10) 1234 | |
| Ê0114012345678908Ê15041231Ê101234 | 2 | J |
IDAutomationFontEncoderUCC128
Funkcja ta może być stosowana w przypadku, gdy pierwsza cyfra kontrolna (Modulo 10) została już obliczona (lub gdy nie ma potrzeby jej obliczania). Funkcja przekształca przekazany ciąg znaków w taki sposób, aby mógł on zostać wygenerowany przy użyciu czcionki IDAutomationC128*.
Znaki startu, pierwszy znak FCN1, druga cyfra kontrolna (Modulo 103) oraz znak stopu są dodawane automatycznie. Jeżeli wymagane są dodatkowe znaki FCN1, można je wstawić przy użyciu znaku Unicode 0xFA (ú) – jest to możliwe wyłącznie na parzystych pozycjach w ciągu znaków.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg znaków przeznaczony do zakodowania jako Code 128 (EAN-128) |
Przykłady
| DataToEncode | Wynik | IDAutomationC128L (20 pt) |
|---|---|---|
| 0174012345678900 | ÍÊ!j!7McyÂLÎ | ÍÊ!j!7McyÂLÎ |
| 00340123450000000017 | ÍÊÂB!7MÂÂÂÂ1]Î | ÍÊÂB!7MÂÂÂÂ1]Î |
IDAutomationFontEncoderSCC14
Funkcja ta przygotowuje przekazany ciąg znaków jako Shipping Container Code (SCC) w taki sposób, aby mógł on zostać wygenerowany przy użyciu czcionki IDAutomationC128*.
Znaki startu, FCN1, Application Identifier (01), pierwsza cyfra kontrolna (Modulo 10), druga cyfra kontrolna (Modulo 103) oraz znak stopu są obliczane i dodawane automatycznie.
| Parametr | Opis |
|---|---|
| DataToEncode | liczba zawierająca od 13 do 17 cyfr (w praktyce wykorzystywanych jest 13 cyfr – Application Identifier (01) oraz cyfra kontrolna są zawsze obliczane na nowo). Liczba składa się z następujących elementów: • 1-cyfrowy Packaging Indicator • 12-cyfrowy numer EAN-13 (bez cyfry kontrolnej) • cyfra kontrolna (Modulo 10)Nawiasy (dla AI) oraz spacje są automatycznie usuwane. W przypadku nieprawidłowych danych generowany jest kod kreskowy składający się wyłącznie z zer. |
| ReturnType (RT) | wartość numeryczna określająca, jakie dane mają zostać zwrócone przez funkcję: 0 – wymagany ciąg znaków dla czcionek IDAutomationC128* wraz ze wszystkimi znakami sterującymi (np. znaki startu, kontrolne i stopu). 1 – dane w postaci czytelnej wraz z cyfrą kontrolną, ale bez znaków startu i stopu. 2 – wyłącznie cyfra kontrolna. |
Przykłady
| DataToEncode | RT | Wynik | IDAutomationC128L (20 pt) |
|---|---|---|---|
| 7401234567890 | 0 | ÍÊ!j!7McyÂLÎ | ÍÊ!j!7McyÂLÎ |
| 7401234567890 | 1 | (01) 7 4012345 67890 0 | |
| 7401234567890 | 2 | 0 |
Dla przykładowych danych wejściowych równoważne wyniki uzyskuje się również dla następujących zapisów:
-
74012345678900
-
74012345678909
-
017401234567890
-
0174012345678900
-
997401234567890
-
(01)7401234567890
-
Ê017401234567890
-
Ê0174012345678900
-
Ê9974012345678900
IDAutomationFontEncoderSSCC18
Funkcja ta przygotowuje przekazany ciąg znaków jako Serial Shipping Container Code (SSCC) w taki sposób, aby mógł on zostać wygenerowany przy użyciu czcionki IDAutomationC128*.
Znaki startu, FCN1, Application Identifier (00), pierwsza cyfra kontrolna (Modulo 10), druga cyfra kontrolna (Modulo 103) oraz znak stopu są obliczane i dodawane automatycznie.
| Parametr | Opis |
|---|---|
| DataToEncode | liczba zawierająca od 17 do 21 cyfr (w praktyce wykorzystywanych jest 17 cyfr – Application Identifier oraz cyfra kontrolna są zawsze obliczane na nowo). Liczba składa się z następujących elementów: • 1-cyfrowa „cyfra rozszerzenia” • 7–9-cyfrowy „numer bazowy” • 8–10-cyfrowe, indywidualne (kolejne) oznaczenie jednostki logistycznej • cyfra kontrolna (Modulo 10)Nawiasy (dla AI) oraz spacje są automatycznie usuwane. W przypadku nieprawidłowych danych generowany jest kod kreskowy składający się wyłącznie z zer. |
| ReturnType (RT) | wartość numeryczna określająca, jakie dane mają zostać zwrócone przez funkcję: 0 – wymagany ciąg znaków dla czcionek IDAutomationC128* wraz ze wszystkimi znakami sterującymi (np. znaki startu, kontrolne i stopu). 1 – dane w postaci czytelnej wraz z cyfrą kontrolną, ale bez znaków startu i stopu. 2 – wyłącznie cyfra kontrolna. |
Przykłady
| DataToEncode | RT | Wynik | IDAutomationC128L (20 pt) |
|---|---|---|---|
| 12345678901234567 | 0 | ÍÊÂ,BXnz,BXkJÎ | ÍÊÂ,BXnz,BXkJÎ |
| 12345678901234567 | 1 | (00) 1 2345678 901234567 5 | |
| 12345678901234567 | 2 | 5 |
Równoważne wyniki uzyskuje się również dla następujących zapisów:
-
123456789012345675
-
123456789012345670
-
0012345678901234567
-
00123456789012345675
-
9912345678901234567
-
(00)12345678901234567
-
Ê0012345678901234567
-
Ê00123456789012345675
-
Ê99123456789012345675
| DataToEncode | RT | Wynik | IDAutomationC128L (20 pt) |
|---|---|---|---|
| 34012345000000001 | 0 | ÍÊÂB!7MÂÂÂÂ1]Î | ÍÊÂB!7MÂÂÂÂ1]Î |
| 34012345000000001 | 1 | (00) 3 4012345 000000001 7 | |
| 34012345000000001 | 2 | 7 |
IDAutomationFontEncoderMod10
Niektóre zastosowania EAN-128, takie jak Serial Shipping Container Code (AI = 00) lub Shipping Container Code (AI = 01), wykorzystują dodatkową (drugą) cyfrę kontrolną (Modulo 10) dla danych użytkowych. Funkcja ta może być użyta do jej obliczenia.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg znaków składający się z cyfr (0–9), dla którego ma zostać obliczona cyfra kontrolna (Modulo 10) |
Przykład
Wartość „34012345000000001” ma zostać wygenerowana jako SSCC-18. Za pomocą funkcji
IDAutomationFontEncoderMod10(„34012345000000001”) można najpierw obliczyć cyfrę kontrolną. W tym przypadku wynikiem jest „7”.
Application Identifier dla SSCC to „00”. Trzy elementy można następnie połączyć:
"00" + "34012345000000001" + "7"
Otrzymany wynik można przekazać do funkcji IDAutomationFontEncoderUCC128, aby uzyskać wymagany ciąg znaków dla czcionki IDAutomationC128L. Alternatywnie można użyć funkcji IDAutomationFontEncoderCode128(), jednak w takim przypadku należy dodatkowo poprzedzić dane znakiem Unicode 0xCA (Ê), aby funkcja dodała wymagany dla EAN-128 kod FCN1.
Uwaga:
Dla opisanego przypadku dostępna jest specjalna funkcja IDAutomationFontEncodeSSCC18, która upraszcza ten proces. Przykład ten ma na celu jedynie pokazanie, w jaki sposób można samodzielnie przygotować analogiczną funkcję dla podobnych zastosowań.
MSI/Plessey
Właściwości
| Właściwość | Opis |
|---|
| Obszary zastosowania | przemysł, biblioteki |
| Zestaw znaków (zakres) | kod numeryczny (cyfry 0–9) |
| Długość | zmienna (brak z góry określonej długości) |
| Cyfra kontrolna | Modulo 10 |
| Budowa | każdorazowo 4 kreski i 4 przerwy |
| Samokontrola | nie |
| Zaleta |
| Wada | niska gęstość informacji |
Czcionki
la MSI (Plessey) dostępne są czcionki w dwóch wariantach:
-
bez tekstu (MSI*)
-
z tekstem (HMSI*)
Dla każdego wariantu dostępne są dodatkowo 4 podwarianty różniące się wysokością kresek:
-
XS (25%)
-
S (50%)
-
M (100%)
-
L (125%)
Zalecana wielkość czcionki dla wszystkich wariantów i podwariantów wynosi 12 punktów. Przy tej wielkości czcionki uzyskuje się szerokość modułu wynoszącą około 0,21 mm, czyli 8 mil (1 mil = 1/1000″).
Wysokość kresek zależy od wybranego podwariantu oraz wielkości czcionki. Na przykład wysokość kresek w wariancie „M” wynosi około 25,4 mm, czyli 1″.
Poniższe tabele przedstawiają czcionki przy wielkości 12 punktów.
MSI bez tekstu
| Czcionka | Przykład („1234567890“) |
|---|---|
| IDAutomationMSIXS | (12345678903) |
| IDAutomationMSIS | (12345678903) |
| IDAutomationMSIM | (12345678903) |
| IDAutomationMSIL | (12345678903) |
MSI z tekstem
| Czcionka | Przykład („1234567890“) |
|---|---|
| IDAutomationHMSIXS | (12345678903) |
| IDAutomationHMSIS | (12345678903) |
| IDAutomationHMSIM | (12345678903) |
| IDAutomationHMSIL | (12345678903) |
Funkcje dla Crystal Reports
Dla MSI (Plessey) dostępna jest następująca funkcja (Visual Basic UFLs):
IDAutomationFontEncoderMSI
Funkcja ta dodaje na początku przekazanego ciągu znaków znak „(” (znak startu), a na końcu znak „)” (znak stopu). Dodatkowo obliczana jest cyfra kontrolna, która zostaje wstawiona przed znakiem stopu.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg cyfr przeznaczony do zakodowania jako MSI (Plessey). Dozwolone są wyłącznie cyfry (0–9), liczba cyfr nie jest ograniczona. Nie należy podawać znaków startu, kontrolnych ani znaków stopu. |
| ReturnType | wartość numeryczna określająca, jakie dane mają zostać zwrócone przez funkcję: 0 – wymagany ciąg znaków dla czcionek IDAutomationMSI* lub IDAutomationHMSI* wraz ze wszystkimi znakami sterującymi (np. znaki startu, kontrolny i stopu). 1 – dane w postaci czytelnej wraz z cyfrą kontrolną, ale bez znaków startu i stopu. 2 – wyłącznie cyfra kontrolna. |
Przykłady
| DataToEncode | Wynik (0, 1, 2) | IDAutomationMSIS (12 pt) |
|---|---|---|
| 123456789 | (1234567897), 123456789, 7 | (1234567897) |
| 1234567890 | (12345678903), 1234567890, 3 | (12345678903) |
UPC-A
Właściwości
| Właściwość | Opis |
|---|
| Specyfikacja (standard) | EN 797 |
| Powiązane standardy | EAN-13, UPC-E |
| Obszary zastosowania | handel w USA i Kanadzie (POS) |
| Zestaw znaków (zakres) | kod numeryczny, cyfry (0–9) |
| Długość | stała długość: 11 cyfr + cyfra kontrolna; opcjonalne rozszerzenie o 2 lub 5 cyfr |
| Budowa | 11 elementów. Wszystkie kreski i przerwy przenoszą informację. |
| Samokontrola | tak |
| Zaleta | wysoka gęstość informacji |
| Wada | bardzo małe tolerancje |
Czcionki
UPC-A, podobnie jak EAN-13, jest generowany przy użyciu czcionki IDAutomationUPCEAN*. Ogólne informacje dotyczące tej czcionki, jej wariantów oraz wskazówki dotyczące drukowania znajdują się w odpowiedniej sekcji dotyczącej EAN-13.
Poniższa tabela przedstawia przykłady wariantów czcionki przy wielkości 20 punktów:
| Czcionka | Przykład („01234567890“) |
|---|---|
| IDAutomationUPCEANXSnoHR | U(a12345*QRSTKp(u |
| IDAutomationUPCEANXS | U(a12345*QRSTKp(u |
| IDAutomationUPCEANS | U(a12345*QRSTKp(u |
| IDAutomationUPCEANM | U(a12345*QRSTKp(u |
| IDAutomationUPCEANL | U(a12345*QRSTKp(u |
Funkcje dla Crystal Reports
Aby możliwe było wykorzystanie czcionek IDAutomationUPCEAN*, dane muszą zostać odpowiednio przygotowane. Dla standardu UPC-A należy zastosować funkcję IDAutomationFontEncoderUPCa.
IDAutomationFontEncoderUPCa
Funkcja ta oblicza ciąg znaków wymagany przez czcionkę IDAutomationUPCEAN*.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg cyfr przeznaczony do zakodowania jako UPC-A. Dozwolone są cyfry od 0 do 9. Oprócz 11 cyfr danych można również podać cyfrę kontrolną oraz/lub dwu- lub pięciocyfrowy kod dodatkowy (Add-On) – patrz przykłady poniżej. Podana cyfra kontrolna nie jest wykorzystywana, ponieważ zawsze jest obliczana na podstawie danych. Przekazany ciąg znaków może zawierać znaki „-” oraz „+”, np. w celu poprawy czytelności. Znaki te są automatycznie usuwane i nie są uwzględniane jako dane. W przypadku nieprawidłowych danych generowany jest kod UPC-A składający się wyłącznie z zer. |
Przykłady
| DataToEncode | Wynik | IDAutomationUPCEANL (20 pt) |
|---|---|---|
| 01234567890 | U(a12345*QRSTKp(u | U(a12345*QRSTKp(u |
| 012345678905 | U(a12345*QRSTKp(u | U(a12345*QRSTKp(u |
| 012345678902 | U(a12345*QRSTKp(u | U(a12345*QRSTKp(u |
| 0-12345-67890 | U(a12345*QRSTKp(u | U(a12345*QRSTKp(u |
| DataToEncode | Wynik | IDAutomationUPCEANL (20 pt) |
|---|---|---|
| 0123456789012 | U(a12345*QRSTKp(u+#!$ | U(a12345*QRSTKp(u+#!$ |
| 01234567890512 | U(a12345*QRSTKp(u+#!$ | U(a12345*QRSTKp(u+#!$ |
| 0-12345-67890+12 | U(a12345*QRSTKp(u+#!$ | U(a12345*QRSTKp(u+#!$ |
| 0-12345-67890-5+12 | U(a12345*QRSTKp(u+#!$ | U(a12345*QRSTKp(u+#!$ |
| DataToEncode | Wynik | IDAutomationUPCEANL (20 pt) |
|---|---|---|
| 0123456789012345 | U(a12345*QRSTKp(u+=!$!@!&!, | U(a12345*QRSTKp(u+=!$!@!&!, |
| 01234567890112345 | U(a12345*QRSTKp(u+=!$!@!&!, | U(a12345*QRSTKp(u+=!$!@!&!, |
| 0-12345-67890+12345 | U(a12345*QRSTKp(u+=!$!@!&!, | U(a12345*QRSTKp(u+=!$!@!&!, |
| ABC | U(a00000*KKKKKk(U | U(a00000*KKKKKk(U |
| 1234 | U(a00000*KKKKKk(U | U(a00000*KKKKKk(U |
| 012345678901234 | U(a00000*KKKKKk(U | U(a00000*KKKKKk(U |
UPC-E
UPC-E jest skróconą formą UPC-A. Stosowany jest w przypadku, gdy na opakowaniu brakuje miejsca na pełny kod UPC-A. W przeciwieństwie do EAN-8 kod producenta jest w nim zachowany. Skrócenie uzyskuje się poprzez kompresję (pomijanie zer).
Właściwości
Ogólne właściwości UPC-E są identyczne z właściwościami UPC-A i dlatego nie są tutaj ponownie przedstawiane.
Czcionki
UPC-E jest generowany – podobnie jak EAN-13 i UPC-A – przy użyciu czcionki IDAutomationUPCEAN*. Ogólne informacje dotyczące tej czcionki, jej wariantów oraz wskazówki dotyczące drukowania znajdują się w odpowiedniej sekcji dotyczącej EAN-13.
Poniższa tabela przedstawia przykłady wariantów czcionki przy wielkości 20 punktów:
| Czcionka | Przykład („01234500006“) |
|---|---|
| IDAutomationUPCEANXSnoHR | U(B23EF6)u |
| IDAutomationUPCEANXS | U(B23EF6)u |
| IDAutomationUPCEANS | U(B23EF6)u |
| IDAutomationUPCEANM | U(B23EF6)u |
| IDAutomationUPCEANL | U(B23EF6)u |
Funkcje dla Crystal Reports
Aby możliwe było wykorzystanie czcionek IDAutomationUPCEAN*, dane muszą zostać odpowiednio przygotowane. Dla standardu UPC-E należy zastosować funkcję IDAutomationFontEncoderUPCe.
IDAutomationFontEncoderUPCe
Funkcja ta oblicza ciąg znaków wymagany przez czcionkę IDAutomationUPCEAN*. W zależności od tego, czy dane mogą zostać skompresowane, zwracany jest ciąg znaków dla UPC-E lub UPC-A.
| Parametr | Opis |
|---|---|
| DataToEncode | ciąg cyfr przeznaczony do zakodowania jako UPC-E lub UPC-A. Dozwolone są cyfry od 0 do 9. Oprócz 11 cyfr danych można również podać cyfrę kontrolną oraz/lub dwu- lub pięciocyfrowy kod dodatkowy (Add-On) – patrz przykłady poniżej. Podana cyfra kontrolna nie jest wykorzystywana, ponieważ zawsze jest obliczana na podstawie danych. Przekazany ciąg znaków może zawierać znaki „-” oraz „+”, np. w celu poprawy czytelności. Znaki te są automatycznie usuwane i nie są uwzględniane jako dane. W zależności od tego, czy numer może zostać „skompresowany” zgodnie ze standardem UPC-E, generowany jest ciąg znaków dla UPC-E lub UPC-A. W przypadku nieprawidłowych danych generowany jest kod UPC-A o wartości „00005000000”. |
Przykłady
| DataToEncode | Wynik | IDAutomationUPCEANL (20 pt) |
|---|---|---|
| 01234500006 | U(B23EF6)u | U(B23EF6)u |
| 0-12345-00006 | U(B23EF6)u | U(B23EF6)u |
| 01234500004 | U(a12345*KKKKOl(V | U(a12345*KKKKOl(V |
| 0-12345-00004 | U(a12345*KKKKOl(V | U(a12345*KKKKOl(V |
| 01234000004 | U(B234EE)v | U(B234EE)v |
| 0-12340-00004 | U(B234EE)v | U(B234EE)v |
| 0123000001234 | U(BC312D)X+@!& | U(BC312D)X+@!& |
| 01230000012534 | U(BC312D)X+@!& | U(BC312D)X+@!& |
| 0-12300-00012+34 | U(BC312D)X+@!& | U(BC312D)X+@!& |
| 0-12300-00012-5+34 | U(BC312D)X+@!& | U(BC312D)X+@!& |
| 0120000012345678 | U(B21C3A)y+[!,!.!_!: | U(B21C3A)y+[!,!.!_!: |
| 01200000123945678 | U(B21C3A)y+[!,!.!_!: | U(B21C3A)y+[!,!.!_!: |
| 0-12000-00123+45678 | U(B21C3A)y+[!,!.!_!: | U(B21C3A)y+[!,!.!_!: |
| ABC | U(A00FA4)u | U(A00FA4)u |
| 1234 | U(A00FA4)u | U(A00FA4)u |
| 012345678901234 | U(A00FA4)u | U(A00FA4)u |
OCR-A/OCR-B
Technologia OCR (Optical Character Recognition) umożliwia odczyt znaków i tekstów bezpośrednio, czyli bez konieczności stosowania specjalnego kodowania. W celu ograniczenia nakładu pracy oraz zapewnienia możliwie wysokiej niezawodności rozpoznawania opracowano specjalne czcionki OCR. W idealnym przypadku mogą być one odczytywane zarówno przez człowieka, jak i przez urządzenia.
Głównym obszarem zastosowania tych czcionek są dokumenty w obrocie płatniczym (czeki, polecenia przelewu itp.). Najczęściej wykorzystywane są dwie czcionki:
- OCR-A (DIN 66008, ANSI X-3.17-1981)
- OCR-B (DIN 66009, ANSI X-3.49-1982)
Czcionka OCR-B charakteryzuje się lepszą czytelnością dla człowieka. Wybór odpowiedniej czcionki zależy zazwyczaj od obszaru zastosowania oraz standardów obowiązujących w danym kraju.
Czcionki
Dla OCR-A dostępne są następujące czcionki (warianty):
| Czcionka | Zastosowanie |
|---|---|
| IDAutomationA1euro | specjalny wariant z symbolami do druku czeków. Dla „Size I” należy stosować wielkość czcionki 9 punktów |
| IDAutomationOCRa | standardowa czcionka dla OCR-A. Dla „Size I” należy stosować 9 pt, a dla „Size II” 12 punktów |
Dla OCR-B dostępne są następujące czcionki (warianty):
| Czcionka | Zastosowanie |
|---|---|
| IDAutomationOCRb | standardowa czcionka dla OCR-B. Dla „Size I” należy stosować wielkość czcionki 14 punktów |
| IDAutomationOCRbn | wariant o nieco mniejszej szerokości, przeznaczony dla drukarek drukujących zbyt szeroko |
Zestaw znaków czcionek OCR-A i OCR-B obejmuje małe i wielkie litery, cyfry oraz różne znaki specjalne.
Zestaw znaków (Unicode / A1euro / OCRa / OCRb)
Poniższa tabela przedstawia zestaw znaków dostępnych dla czcionek A1euro, OCRa oraz OCRb wraz z odpowiadającymi im wartościami Unicode:
| Unicode | A1euro | OCRa | OCRb |
|---|---|---|---|
| ! (0x21) | ! | ! | ! |
| ” (0x22) | „ | „ | „ |
| # (0x23) | # | # | # |
| $ (0x24) | $ | $ | $ |
| % (0x25) | % | % | % |
| & (0x26) | & | & | & |
| ’ (0x27) | ’ | ’ | ’ |
| ( (0x28) | ( | ( | ( |
| ) (0x29) | ) | ) | ) |
| * (0x2A) | * | * | * |
| + (0x2B) | + | + | + |
| , (0x2C) | , | , | , |
| – (0x2D) | – | – | – |
| . (0x2E) | . | . | . |
| / (0x2F) | / | / | / |
| 0 (0x30) | 0 | 0 | 0 |
| 1 (0x31) | 1 | 1 | 1 |
| 2 (0x32) | 2 | 2 | 2 |
| 3 (0x33) | 3 | 3 | 3 |
| 4 (0x34) | 4 | 4 | 4 |
| 5 (0x35) | 5 | 5 | 5 |
| 6 (0x36) | 6 | 6 | 6 |
| 7 (0x37) | 7 | 7 | 7 |
| 8 (0x38) | 8 | 8 | 8 |
| 9 (0x39) | 9 | 9 | 9 |
| : (0x3A) | : | : | : |
| ; (0x3B) | ; | ; | ; |
| < (0x3C) | < | < | < |
| = (0x3D) | = | = | = |
| > (0x3E) | > | > | > |
| ? (0x3F) | ? | ? | ? |
| @ (0x40) | @ | @ | @ |
| A (0x41) | A | A | A |
| B (0x42) | B | B | B |
| C (0x43) | C | C | C |
| D (0x44) | D | D | D |
| E (0x45) | E | E | E |
| F (0x46) | F | F | F |
| G (0x47) | G | G | G |
| H (0x48) | H | H | H |
| I (0x49) | I | I | I |
| J (0x4A) | J | J | J |
| K (0x4B) | K | K | K |
| L (0x4C) | L | L | L |
| M (0x4D) | M | M | M |
| N (0x4E) | N | N | N |
| O (0x4F) | O | O | O |
| P (0x50) | P | P | P |
| Q (0x51) | Q | Q | Q |
| R (0x52) | R | R | R |
| S (0x53) | S | S | S |
| T (0x54) | T | T | T |
| U (0x55) | U | U | U |
| V (0x56) | V | V | V |
| W (0x57) | W | W | W |
| X (0x58) | X | X | X |
| Y (0x59) | Y | Y | Y |
| Z (0x5A) | Z | Z | Z |
| [ (0x5B) | [ | [ | [ |
| \ (0x5C) | \ | \ | \ |
| ] (0x5D) | ] | ] | ] |
| ^ (0x5E) | ^ | ^ | ^ |
| _ (0x5F) | _ | _ | _ |
| ` (0x60) | ` | ` | ` |
| a (0x61) | a | a | a |
| b (0x62) | b | b | b |
| c (0x63) | c | c | c |
| d (0x64) | d | d | d |
| e (0x65) | e | e | e |
| f (0x66) | f | f | f |
| g (0x67) | g | g | g |
| h (0x68) | h | h | h |
| i (0x69) | i | i | i |
| j (0x6A) | j | j | j |
| k (0x6B) | k | k | k |
| l (0x6C) | l | l | l |
| m (0x6D) | m | m | m |
| n (0x6E) | n | n | n |
| o (0x6F) | o | o | o |
| p (0x70) | p | p | p |
| q (0x71) | q | q | q |
| r (0x72) | r | r | r |
| s (0x73) | s | s | s |
| t (0x74) | t | t | t |
| u (0x75) | u | u | u |
| v (0x76) | v | v | v |
| w (0x77) | w | w | w |
| x (0x78) | x | x | x |
| y (0x79) | y | y | y |
| z (0x7A) | z | z | z |
| { (0x7B) | { | { | { |
| | (0x7C) | | | | | | |
| } (0x7D) | } | } | } |
| ~ (0x7E) | ~ | ~ | ~ |
| £ (0xA3) | £ | £ | £ |
| ¤ (0xA4) | ¤ | ||
| ¥ (0xA5) | ¥ | ¥ | ¥ |
| § (0xA7) | § | ||
| ¨ (0xA8) | ¨ | ||
| – (0xAD) | − | − | − |
| ´ (0xB4) | ´ | ||
| À (0xC0) | À | À | |
| Á (0xC1) | Á | Á | |
| Â (0xC2) | Â | Â | |
| Ã (0xC3) | Ã | Ã | |
| Ä (0xC4) | Ä | Ä | Ä |
| Å (0xC5) | Å | Å | Å |
| Æ (0xC6) | Æ | Æ | Æ |
| Ñ (0xD1) | Ñ | Ñ | Ñ |
| Ö (0xD6) | Ö | Ö | Ö |
| Ø (0xD8) | Ø | Ø | Ø |
| Ú (0xDA) | Ú | Ú | |
| Ü (0xDC) | Ü | Ü | Ü |
| ß (0xDF) | ß | ||
| å (0xE5) | å | ||
| æ (0xE6) | Æ | ||
| ø (0xF8) | Ø | ||
| ˙ (0x2D9) | ˙ | ||
| ˜ (0x2DC) | ˜ | ˜ | |
| ‘ (0x2018) | ‘ | ‘ | ‘ |
| ’ (0x2019) | ’ | ’ | ’ |
MICR
E-13B
CMC-7
POSTNET
Kod kreskowy POSTNET (POSTal Numeric Encoding Technique) został opracowany przez United States Postal Service (USPS) i służy do kodowania adresów pocztowych w USA.
W odróżnieniu od większości innych kodów kreskowych, w POSTNET i PLANET informacje nie są kodowane poprzez różne szerokości elementów, lecz poprzez różne wysokości kresek.
Kodowane dane obejmują:
- standardowy kod ZIP (5 cyfr),
- tzw. kod ZIP+4 (9 cyfr),
- pełny Delivery Point Code (11 cyfr).
Kod kreskowy POSTNET zawsze zawiera cyfrę kontrolną (Modulo 10).
PLANET
Kod kreskowy PLANET jest nowszym typem kodu i jest wykorzystywany przez USPS do obsługi odpowiedzi (Business Reply Mail), sortowania oraz śledzenia przesyłek (tracking).
FIM
Czcionki
Dla POSTNET oraz PLANET dostępne są po dwa warianty czcionek: wariant standardowy oraz wariant, w którym szerokość kresek jest zmniejszona o około 10% (n: Narrow).
Zalecana wielkość czcionki dla wszystkich wariantów wynosi 12 punktów. Przy tej wielkości uzyskiwane są wymiary określone w standardzie USPS.
POSTNET / PLANET
| Czcionka | Przykład („1234567890“) |
|---|---|
| IDAutomationPOSTNET | (12345678905) |
| IDAutomationPOSTNETn | (12345678905) |
| IDAutomationPLANET | (12345678905) |
| IDAutomationPLANETn | (12345678905) |
Funkcje dla Crystal Reports
Dla POSTNET oraz PLANET dostępna jest następująca funkcja (Visual Basic UFL):
- IDAutomationFontEncoderPostnet
USPS wykorzystuje od 10.01.2004 również kody kreskowe oparte na EAN-128 (np. do potwierdzeń doręczenia). Do przygotowania danych dla czcionki IDAutomationC128L można zastosować następującą funkcję:
- IDAutomationFontEncoderUSPS_EAN128
IDAutomationFontEncoderPostnet
Funkcja ta dodaje na początku przekazanego ciągu znaków znak „(” (znak startu), a na końcu znak „)” (znak stopu). Dodatkowo obliczana jest cyfra kontrolna, która zostaje wstawiona przed znakiem stopu.
| Parametr | Opis |
|---|---|
| DataToEncode | dane przeznaczone do zakodowania jako POSTNET lub PLANET. Obsługiwane są formaty ZIP, ZIP+4 oraz ZIP+4 + Delivery Point. Dane mogą zawierać znak „-” i/lub spacje – są one automatycznie usuwane. |
| ReturnType | wartość numeryczna określająca, jakie dane mają zostać zwrócone przez funkcję: 0 – wymagany ciąg znaków dla czcionek IDAutomationPOSTNET* lub IDAutomationPLANET* wraz ze wszystkimi znakami sterującymi (np. znaki startu, kontrolny i stopu). 1 – dane w postaci czytelnej wraz z cyfrą kontrolną, ale bez znaków startu i stopu. 2 – wyłącznie cyfra kontrolna. |
Przykłady
| DataToEncode | Wynik (0, 1, 2) | IDAutomationPOSTNET (12 pt) |
|---|---|---|
| 12345 | (123455), 123455, 5 | (123455) |
| 123456789 | (1234567895), 1234567895, 5 | (1234567895) |
| 12345-6789 | (1234567895), 1234567895, 5 | (1234567895) |
| 98765-4321-01 | (987654321014), 987654321014, 4 | (987654321014) |
IDAutomationFontEncoderUSPS_EAN128
Funkcja ta przygotowuje ciąg znaków przekazany jako USPS Delivery Confirmation w taki sposób, aby mógł on zostać prawidłowo wydrukowany przy użyciu czcionki IDAutomationC128*.
W ramach tego procesu automatycznie obliczane i wstawiane są:
-
kod startowy (Start Code)
-
znak FNC1
-
Application Identifier – 91
-
pierwsza cyfra kontrolna (Modulo 10)
-
druga cyfra kontrolna (Modulo 103)
-
kod stopu (Stop Code)
| Parametr | Opis |
| DataToEncode | Liczba 19- lub 20-cyfrowa (wykorzystywanych jest wyłącznie pierwszych 19 cyfr; cyfra kontrolna jest zawsze obliczana ponownie).Skład:
|
| ReturnType | Wartość liczbowa określająca, jakie dane ma zwrócić funkcja:
|
Przykład
| DataToEncode | Wynik (0, 1, 2) | IDAutomationC128L (20 pt) |
| 0112345678912345678 | ÍÊ{!,BXn{7McpJÎ9101 1234 5678 9123 4567 800 |  |
Instrukcje drukowania
Na to, czy wydrukowany kod kreskowy może zostać poprawnie odczytany przez skaner (a najlepiej przez każdy skaner), wpływa wiele czynników. Wymagania stawiane drukarkom i skanerom są w szczególności silnie uzależnione od gęstości kodu kreskowego. Z tego względu większość specyfikacji kodów kreskowych określa minimalne wartości lub zakresy dopuszczalne dla szerokości modułu oraz proporcji pomiędzy elementami wąskimi i szerokimi, tak aby zapewnić minimalny poziom kompatybilności pomiędzy urządzeniami drukującymi i odczytującymi.
Wysokość kodu kreskowego jest zazwyczaj mniej krytyczna, powinna jednak być wystarczająco duża, aby kod mógł zostać niezawodnie odczytany nawet wtedy, gdy skaner jest trzymany pod niewielkim kątem.
W przypadku drukarek należy pamiętać, że dysponują one ograniczoną rozdzielczością, co oznacza, że linie nie mogą być drukowane dowolnie cienko ani dowolnie gęsto. W praktyce często nie da się w pełni wykorzystać nawet rozdzielczości nominalnej (np. 600×600 dpi w typowych drukarkach laserowych), ponieważ rzeczywisty rozmiar punktów drukujących może znacząco różnić się od teoretycznego rastra — w zależności od technologii druku (laserowa, termiczna, atramentowa, igłowa itp.). Przykładem takiego zjawiska jest rozlewanie się atramentu w drukarkach atramentowych.
Skaner może niezawodnie odczytać kod kreskowy tylko wtedy, gdy drukarka rzeczywiście drukuje czarne i białe linie o jednakowej szerokości jako (niemal) jednakowo szerokie. To samo dotyczy relacji pomiędzy liniami cienkimi i grubymi: linie o podwójnej szerokości muszą być również fizycznie dwukrotnie szersze na wydruku.
Należy również pamiętać, że same skanery, w zależności od konstrukcji oraz odległości odczytu, mogą stawiać różne wymagania wobec drukowanego kodu kreskowego. Przykładowo szerokość modułu musi być większa niż średnica wiązki światła używanej do skanowania. Równie istotny jest kontrast pomiędzy jasnymi i ciemnymi liniami.
Rozmiar czcionki
Aby wydrukowany kod kreskowy mógł być odczytany, podczas drukowania muszą zostać zachowane wzajemne proporcje szerokości poszczególnych elementów. W przypadku kodów dwuszerokościowych (np. Code 39) wąskie elementy muszą być jednoznacznie rozpoznawalne jako wąskie, a szerokie elementy jako szerokie. Dla zapewnienia optymalnej czytelności wszystkie wąskie elementy (paski i przerwy) powinny mieć identyczną szerokość; analogicznie dotyczy to wszystkich szerokich elementów. W przypadku kodów wieloszerokościowych (np. Code 128) zasady te obowiązują oddzielnie dla każdej szerokości elementu.
Ponieważ drukarki dysponują ograniczoną rozdzielczością, szerokość modułu X nie może być dowolnie mała. Dla uzyskania optymalnych rezultatów szerokość modułu X powinna być dobrana w taki sposób, aby dla wszystkich występujących szerokości elementów była ona całkowitą wielokrotnością szerokości pojedynczego punktu drukarki. Poniższa tabela przedstawia kilka przykładowych wartości dla najczęściej spotykanych rozdzielczości drukarek:
| 203 dpi | 300 dpi | 600 dpi |
| 0,125 mm (4,92 mil) | 0,085 mm (3,33 mil) | 0,043 mm (1,67 mil) |
| 0,250 mm (9,85 mil) | 0,169 mm (6,67 mil) | 0,085 mm (3,33 mil) |
| 0,375 mm (14,8 mil) | 0,254 mm (10,0 mil) | 0,127 mm (5,00 mil) |
| 0,500 mm (19,7 mil) | 0,339 mm (13,3 mil) | 0,169 mm (6,67 mil) |
| 0,625 mm (24,6 mil) | 0,423 mm (16,7 mil) | 0,212 mm (8,33 mil) |
| 0,750 mm (29,6 mil) | 0,508 mm (20,0 mil) | 0,254 mm (10,0 mil) |
| 0,875 mm (34,5 mil) | 0,593 mm (23,3 mil) | 0,296 mm (11,7 mil) |
| 1,000 mm (39,4 mil) | 0,677 mm (26,7 mil) | 0,339 mm (13,3 mil) |
W przypadku zastosowania wartości innych od całkowitych mogą pojawić się błędy zaokrągleń, prowadzące do zniekształcenia proporcji szerokości poszczególnych elementów. Przy odpowiednio dużej szerokości modułu lub wystarczająco wysokiej rozdzielczości drukarki powstające odchylenia mogą jednak zostać pominięte, ponieważ mieszczą się w dopuszczalnym zakresie tolerancji danego kodu kreskowego.
Jeżeli jednak przy niskiej rozdzielczości drukarki zachodzi potrzeba drukowania kodów kreskowych o małej szerokości modułu, rozmiar czcionki musi zostać dobrany w taki sposób, aby proporcje szerokości elementów mieściły się w granicach tolerancji określonych w specyfikacji kodu kreskowego. Poniższa tabela przedstawia rozmiary czcionek zalecane przez firmę IDAutomation.com, Inc..
| Kod | Zalecana czcionka (dla 600 dpi) | 203 dpi | 300 dpi |
| Code 39 | 12 pt | 4 pt, 8 pt | 2,8 pt, 5,5 pt, ≥ 8 pt |
| Code 128 | 12 pt | 7,4 pt, 14,5 pt | 5 pt, 9,8 pt, 14,5 pt |
| Codabar | 12 pt | 5 pt, 10 pt | 3,6 pt, 6,9 pt, 10 pt |
| EAN/UPC | 20 pt | 5 pt, 10 pt | 3,6 pt, 6,9 pt, 10 pt |
| Interleaved 2 of 5 | 12 pt | 12,5 pt | 8,5 pt |
| MSI | 12 pt | 6 pt, 11,5 pt | 4 pt, 7,8 pt |
Definicje
Element – kod kreskowy składa się z ciemnych i jasnych elementów, czyli pasków oraz przerw.
Przerwa – jasny element znajdujący się pomiędzy dwoma paskami kodu kreskowego.
Moduł – najwęższy element w kodzie kreskowym określany jest jako moduł. Szerokość pozostałych elementów wyrażana jest jako wielokrotność szerokości modułu.
Szerokość modułu (X) – szerokość najwęższego elementu (modułu) określana jest również symbolem „X”.
OCR – (Optical Character Recognition) – znaki przeznaczone do odczytu maszynowego, które są jednocześnie czytelne dla człowieka. Istnieje wiele czcionek OCR, jednak najszersze zastosowanie mają OCR-A oraz OCR-B. Czcionka OCR-A została zaprojektowana przede wszystkim z myślą o łatwości odczytu maszynowego i charakteryzuje się technicznym, nienaturalnym wyglądem. Czcionka OCR-B jest natomiast łatwa do odczytania także dla człowieka.
Pasek – ciemny element kodu kreskowego.
Symbol – definiuje specyficzną strukturę symboli danego kodu kreskowego.
Strefa ciszy – jasny obszar przed i za kodem kreskowym. Strefa ciszy (R) jest niezbędna, aby urządzenie odczytujące (skaner) mogło prawidłowo rozpoznać kod (np. ustawić ostrość). Szerokość strefy ciszy powinna wynosić co najmniej 10X (dziesięciokrotność szerokości modułu) lub 2,5 mm — w zależności od tego, która z wartości jest większa.
Przerwa rozdzielająca – przerwa pomiędzy ostatnim paskiem jednego znaku a pierwszym paskiem kolejnego znaku.
Znane problemy
Używanie czcionek rozpoczynających się od znaku „@”
Czcionki kodów kreskowych mogą w niektórych przypadkach pojawiać się na liście czcionek w Crystal Reports podwójnie, na przykład jako „IDAutomationC128L” oraz „@IDAutomationC128L”. Zastosowanie wariantów czcionek rozpoczynających się od znaku „@” może prowadzić do nieprawidłowego generowania kodów kreskowych (np. pojawienia się dodatkowych pasków lub przerw).
Z tego względu należy bezwzględnie używać wyłącznie czcionek bez poprzedzającego znaku „@”.
Eksportowanie w formacie PDF
Jeśli raporty (Crystal Reports) są eksportowane do formatu PDF, mogą wystąpić odchylenia w rozmiarze czcionki. Szczególnie dotyczy to niektórych czcionek kodów kreskowych.



