W ramach rozwoju lub adaptacji może zaistnieć potrzeba poprawy czasu wykonywania programu aplikacyjnego. Niniejszy artykuł opisuje w szczególności możliwości optymalizacji w programach aplikacyjnych przy dostępie do usługi persystencji.
Grupa docelowa
Grupą docelową niniejszego artykułu są deweloperzy aplikacji.
Definicje terminów
- Notacja O — aby poprawić wydajność systemu, konieczna jest wiedza, ile czasu zajmują poszczególne operacje. Czas wykonania operacji jest jednak często zależny od zakresu przetwarzanych danych. Z tego powodu stosuje się notację O w celu oszacowania złożoności operacji. Pełną, matematycznie poprawną definicję można znaleźć w odpowiedniej literaturze podstawowej.
Zbiór O(f(n)) obejmuje wszystkie funkcje g(n), dla których istnieją stałe c oraz n₀ takie, że dla wszystkich m > n₀ zachodzi:
0 ≤ g(m) < c · f(m).
W praktyce stosowane są głównie następujące zbiory:
- O(c) dla wszystkich funkcji stałych
- O(log(n))
- O(n)
- O(n · log(n))
Przyjmuje się następujące założenia:
- Dostęp do tablicy haszującej ma stały koszt czasowy, czyli należy do O(c). Chociaż w ogólnym przypadku koszt wynosi O(n), to przy założeniu dobrej funkcji haszującej oraz ograniczeniu stopnia wypełnienia tabeli do 75% takie oszacowanie jest uzasadnione.
- Dostęp do indeksu bazy danych ma koszt czasowy rzędu O(log(n)).
- Odczyt wszystkich rekordów tabeli ma koszt czasowy rzędu O(n).
Podstawy
Jeżeli program lub funkcja programu wymaga więcej czasu, niż jest to akceptowalne, problem ten musi zostać rozwiązany. W pierwszej kolejności należy sprawdzić konfigurację systemu:
- sprawdzenie, czy baza danych oraz serwer aplikacyjny dysponują wystarczającą ilością fizycznej pamięci operacyjnej,
- sprawdzenie, czy bufory (cache) bazy danych i serwera aplikacyjnego mają odpowiedni rozmiar,
- sprawdzenie, czy wykorzystywany sprzęt spełnia wymagania,
- itd.
Jeżeli wszystkie możliwości przyspieszenia systemu poprzez zmiany konfiguracji zostały wyczerpane, przyczyna problemu może leżeć w używanych aplikacjach.
W dalszej części podawane wartości czasów i rozmiarów służą wyłącznie zobrazowaniu zależności i nie odnoszą się bezpośrednio do rzeczywistego systemu. Dodatkowo, należy zapoznać się z artykułem Lista kontrolna systemu.
Wytyczne
Aplikacje w Comarch ERP Enterprise muszą być przystosowane do przetwarzania dużych wolumenów danych oraz charakteryzować się wysoką wydajnością. Oznacza to, że program musi być w stanie przetwarzać duże ilości danych w czasie akceptowalnym dla użytkownika, bez nadmiernego zużycia pamięci operacyjnej lub innych kluczowych zasobów.
Podstawowe zasady, które należy uwzględniać przy tworzeniu wydajnych programów, zostały opisane poniżej. Bardziej złożonych zagadnień nie da się jednak ująć w postaci prostych reguł. Z tego powodu po zakończeniu implementacji programu konieczne jest zmierzenie jego zapotrzebowania na zasoby. W razie potrzeby należy następnie skorygować słabe punkty programu.
Cele optymalizacji
Wszystkie serwery aplikacji Comarch ERP Enterprise (SAS) korzystają ze wspólnego systemu bazodanowego (DBS). DBS ma ograniczoną maksymalną wydajność. Jeżeli DBS wykonuje jedno lub kilka złożonych zapytań, to również wykonywanie prostych zapytań trwa znacznie dłużej niż w przypadku nieobciążonego systemu.
Jednym z celów optymalizacji wydajności jest to, aby złożone zapytania bazodanowe o czasie wykonania powyżej 2–3 sekund w normalnej eksploatacji Comarch ERP Enterprise nie występowały lub pojawiały się jedynie sporadycznie.
Podobnie jak złożone zapytania, również proste zapytania bazodanowe mogą prowadzić do problemów, jeżeli są wykonywane zbyt często. Wielokrotne wykonywanie prostego zapytania ma taki sam efekt jak wykonanie jednego złożonego zapytania.
Kolejnym celem jest zatem ograniczenie liczby wykonywanych prostych zapytań bazodanowych.
Jeżeli DBS jest przeciążony, wszystkie operacje w całym systemie Comarch ERP Enterprise ulegają spowolnieniu. Oznacza to, że przy obciążonym DBS również operacje, które same w sobie są wystarczająco szybkie, stają się dla użytkowników nieakceptowalnie wolne. W konsekwencji operacja, która jest postrzegana jako wolna, nie zawsze jest rzeczywistą przyczyną problemów wydajnościowych. W szczególności, jeżeli obserwowane jest silnie zmienne zachowanie systemu (raz szybkie, raz wolne), można przypuszczać, że przyczyna nie leży w bezpośrednio obserwowanej operacji.
Podobnie jak obciążenie DBS spowalnia cały system, tak samo obciążenie CPU na jednym SAS spowalnia wszystkich użytkowników zalogowanych do tego serwera. Z tego powodu obliczenia intensywnie wykorzystujące CPU powinny być unikane w aplikacjach dialogowych.
Pamięć operacyjna w każdym SAS jest ograniczona, dlatego aplikacja dialogowa może wykorzystywać jedynie ograniczoną jej ilość.
Systemy operacyjne oraz systemy zarządzania bazami danych reagują na obciążenie w bardzo różny sposób. Niektóre systemy lepiej radzą sobie z okresami wysokiego obciążenia niż inne. W związku z tym nie można formułować ogólnych, uniwersalnych stwierdzeń dotyczących wpływu wysokiego obciążenia na czas odpowiedzi systemu.
Najpierw pomiar i weryfikacja, a później zmiana
Aby poprawić wydajność programu, którego rozwój przebiegał zgodnie z podstawowymi zasadami, zasadniczo należy najpierw przeprowadzić pomiary, a dopiero potem wprowadzać zmiany w programie. Dopóki nie jest wiadomo, gdzie zużywana jest zasób krytyczny (pamięć operacyjna lub czas wykonania), optymalizacja nie ma uzasadnienia.
Optymalizacja polegająca na skróceniu czasu działania danej części o połowę ma następujące efekty: Z powyższego przykładu wynika, że jeżeli całkowity czas wykonania funkcji f jest zbyt długi, największy efekt przynosi optymalizacja części gromadzenie danych. Natomiast optymalizacja części obliczanie danych będzie dla użytkownika praktycznie niezauważalna. Przykład ten pokazuje, jak istotne jest najpierw zidentyfikowanie tej części programu, która generuje największe zużycie zasobów. Od tego elementu należy rozpocząć optymalizację. Im dokładniej zostanie zawężona funkcja o najwyższym zapotrzebowaniu na zasoby, tym bardziej ukierunkowana i skuteczna może być optymalizacja.
Weryfikacja dostępu do bazy danych
W przypadku złożonych programów do przeprowadzenia miarodajnych pomiarów konieczne są reprezentatywne dane testowe. Oznacza to, że dane testowe muszą pod względem zakresu i struktury odpowiadać przypadkowi użycia, który ma zostać zoptymalizowany.
Tworzenie danych testowych może być stosunkowo pracochłonne. Jeżeli jest to możliwe, zaleca się korzystanie z danych rzeczywistych. W przypadku występowania problemu wydajnościowego u klienta do systemu deweloperskiego partnera powinna zostać, o ile to możliwe, dołączona kopia bazy danych OLTP zawierająca rzeczywiste dane. Zbyt małe lub zbyt prosto ustrukturyzowane dane testowe zniekształcają wyniki pomiarów i mogą prowadzić do optymalizacji niewłaściwych części programu.
Podczas wykonywania pomiarów w systemie deweloperskim należy pamiętać, że baza danych OLTP w tym systemie zazwyczaj nie ma takiego rozmiaru jak baza OLTP w systemie produkcyjnym. W związku z tym zapytania bazodanowe mogą wykazywać inne czasy wykonania niż w środowisku produkcyjnym. Ponadto obciążenie bazy danych i serwerów aplikacyjnych w systemie deweloperskim jest znacznie mniejsze niż w systemie produkcyjnym. W środowisku deweloperskim jednocześnie pracuje zwykle niewielu deweloperów, natomiast w systemie produkcyjnym wielu użytkowników wykonuje równolegle różne operacje. W efekcie bufory (cache) serwera aplikacyjnego i bazy danych w systemie deweloperskim są niemal wyłącznie dostępne dla jednej operacji, podczas gdy w systemie produkcyjnym muszą być współdzielone przez wiele aktywnych sesji. Z tego powodu pomiary czasu wykonane w systemie deweloperskim należy zawsze interpretować z ostrożnością.
Systemy zarządzania bazami danych (DBMS) tworzą dla każdego polecenia SQL plan dostępu. Plan dostępu opisuje sposób, w jaki DBMS uzyskuje dostęp do tabel i indeksów podczas wykonywania polecenia SQL. Wszystkie DBMS udostępniają możliwość graficznego wyświetlenia planu dostępu. W szczególności w przypadku poleceń SQL o długim czasie wykonania konieczna jest analiza planu dostępu. W tym celu należy korzystać z dokumentacji danego DBMS, aby pobierać i interpretować plany dostępu.
Optymalizator DBMS działa zazwyczaj w oparciu o koszty. Oznacza to, że na podstawie informacji statystycznych próbuje on oszacować koszt wykonania polecenia SQL. Jeżeli dostępnych jest kilka alternatywnych planów dostępu, wybierany jest plan o najniższym koszcie. Może się zatem zdarzyć, że mimo istnienia odpowiednich indeksów nie zostaną one użyte, ponieważ koszt dostępu z wykorzystaniem indeksu jest wyższy niż koszt dostępu bez indeksu.
Niemal każdy DBMS oferuje funkcję monitorowania, która umożliwia rejestrowanie zużycia zasobów przez polecenia SQL wykonywane w określonym przedziale czasu. Funkcja ta powinna być wykorzystywana podczas testów obciążeniowych. W przypadku problemów wydajnościowych w systemie produkcyjnym również można z niej korzystać, przy czym należy bezwzględnie upewnić się, że pomiary nie powodują nadmiernego obciążenia systemu produkcyjnego.
Comarch ERP Enterprise może za pomocą monitorów wydajności rejestrować szczegółowe informacje wydajnościowe dotyczące aplikacji i raportów. Informacje te mogą obejmować statystyki dotyczące dostępu aplikacji lub raportu do bazy danych. Dane te należy wykorzystywać w procesie optymalizacji.
Protokoły profilowania dostarczają szczegółowej analizy pojedynczych aplikacji lub akcji związanych z aplikacjami. Dalsze informacje znajdują się w rozdziale Pomiary wydajności.
Zużycie pamięci
Java wykorzystuje dynamiczne zarządzanie pamięcią z mechanizmem garbage collector, który w tle regularnie usuwa obiekty, do których nie istnieją już referencje. Mechanizm ten może prowadzić do znacznego obciążenia CPU, jeżeli w krótkim czasie tworzona jest bardzo duża liczba obiektów. Z tego względu należy unikać niepotrzebnego tworzenia nowych obiektów Java.
Za pomocą profilerów pamięci, takich jak np. Optimize-It, możliwa jest analiza liczby tworzonych obiektów poszczególnych klas. Narzędzia te należy wykorzystywać do optymalizacji aplikacji.
Na ten temat istnieje wiele opracowań dostępnych w Internecie oraz w literaturze specjalistycznej. Z tego powodu zagadnienia związane z optymalizacją zużycia pamięci nie są dalej omawiane.
Należy zwrócić uwagę, że większość problemów wydajnościowych w aplikacjach biznesowych jest spowodowana niekorzystnym lub zbyt częstym dostępem do bazy danych. Problemy wynikające z nadmiernego zużycia pamięci lub zbyt dużej liczby tymczasowo tworzonych obiektów występują stosunkowo rzadko.
Pomiary wydajności
Do pomiarów wydajności dostępne są między innymi narzędzia przedstawione w niniejszym rozdziale. Wynikiem pomiaru wydajności może być zestaw instrukcji bazodanowych, które odpowiadają za czas odpowiedzi aplikacji lub raportu. W rozdziale Wyszukiwanie instrukcji bazodanowych w aplikacjach opisano, w jaki sposób lokalizować problematyczne instrukcje bazodanowe w aplikacjach.
Monitory wydajności
Monitory wydajności w Comarch ERP Enterprise rejestrują wybrane operacje przez dłuższy czas. Rejestrowanie można – w zależności od poziomu szczegółowości – włączyć również w systemach produkcyjnych. W ramach monitorów wydajności mierzony jest także czas wykonania poszczególnych operacji.
Za pomocą monitorów wydajności bazy danych każdy deweloper aplikacji może kontrolować operacje opracowane przez siebie pod kątem dostępu do usługi persystencji. W wielu przypadkach sprawdza się następujące postępowanie:
- Uruchomienie aplikacji Monitory wydajności.
- Utworzenie nowego monitora wydajności.
- Użycie pliku szablonu DatabaseMonitor-FullAnalysis.xml.
- Ograniczenie monitora wydajności do używanego serwera aplikacyjnego.
- Ewentualne ograniczenie monitora wydajności do własnego użytkownika.
- Zapisanie monitora wydajności.
- Aktywacja monitora wydajności.
- Wykonanie odpowiednich funkcji.
- Zakończenie monitora wydajności.
- Analiza wyników monitora wydajności.
Dalsze informacje znajdują się w artykułach Monitory wydajności oraz Wykorzystywanie informacji wydajnościowych.
Protokoły profilowania
Protokoły profilowania zliczają, jak często wybrane operacje usługi persystencji są wywoływane oraz w jakim kontekście (aplikacji).
Dalsze informacje na ten temat znajdują się w artykule Odczytywanie protokołów profilowania.
Profilery pamięci
Profilery pamięci w środowiskach deweloperskich Java (np. profiler pamięci narzędzia Optimize-It) często nie mogą być wykorzystywane w systemach produkcyjnych, ale stanowią jedyną możliwość analizy problemów pamięciowych w Comarch ERP Enterprise.
Profilery CPU
Profilery CPU w środowiskach deweloperskich Java (np. profiler CPU narzędzia Optimize-It) często nie mogą być wykorzystywane w systemach produkcyjnych, a w systemach wielowątkowych/wielosesyjnych, takich jak Comarch ERP Enterprise, często mają problem z przypisaniem pomiarów do właściwego kontekstu użytkownika. Ponadto niektóre profilery Java zniekształcają w szczególności pomiary czasu, ponieważ albo HotSpot nie działa w pełnym zakresie, albo zbyt wiele niepotrzebnych punktów pomiarowych wydłuża czas wykonania.
W związku z tym profilery Java w wielu przypadkach nie są odpowiednie do pomiarów w Comarch ERP Enterprise. Monitory wydajności oraz protokoły profilowania zwykle dostarczają lepszych danych niż profilery Java.
Wyprowadzanie zapytań bazodanowych
W trakcie rozwoju wykonywane zapytania bazodanowe można wyprowadzać za pomocą następującego polecenia.
dbgcls -class:com.cisag.sys.kernel.sql.CisPreparedStatement
Za pomocą opcjonalnego parametru -level można ustawić próg dotyczący czasu wykonania, od którego następuje wyprowadzanie instrukcji bazodanowej.
| Parametr | Wartość progowa |
| brak podanego poziomu lub level:100 | brak wartości progowej |
| -level:2 | 250 ms |
| -level:5 | 1000 ms |
Indeksy
Indeks jest strukturą dostępu, która może przyspieszyć dostęp do pojedynczych wierszy tabeli. Indeks jest definiowany przez uporządkowaną sekwencję atrybutów tabeli. Atrybuty te nazywane są atrybutami indeksu. Szczegółowe informacje dotyczące wewnętrznego działania indeksów można znaleźć w literaturze podstawowej dotyczącej baz danych.
Indeks zawiera (w uproszczeniu) wpis dla każdego wiersza tabeli, dla której został zdefiniowany. Wpis składa się z wartości oraz odwołania do przypisanego wiersza w tabeli. Indeks posiada strukturę dostępu, która umożliwia efektywne wyszukiwanie na podstawie wartości wpisów indeksu. Na podstawie wpisu indeksu system zarządzania bazą danych (DBMS) może w sposób wydajny uzyskać dostęp do odpowiedniego wiersza tabeli.
Wartość wpisu indeksu wynika z wartości atrybutów indeksu danego wiersza tabeli, na który wskazuje odwołanie. Indeksy stosowane w Comarch ERP Enterprise są posortowane, tzn. wpisy indeksu są uporządkowane według wartości. Oprócz optymalizacji dostępu DBMS może również wykorzystywać indeks do sortowania wyników zapytania.
Przykład tabeli z dwoma indeksami Tabela 1 w tym przykładzie posiada dwa indeksy. Indeks BK (Business Key) jest zdefiniowany na atrybutach Type oraz Code, natomiast indeks PK (Primary Key) na atrybucie Guid. Każdy wpis indeksu wskazuje na jeden wiersz tabeli.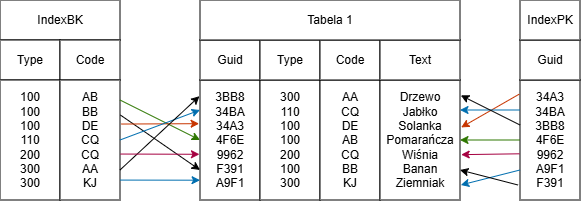
Odczyt z wykorzystaniem indeksu
Za pomocą indeksu można wybierać określone wiersze tabeli. Czas wyszukiwania wpisu w indeksie mieści się w O(log(n)), co oznacza, że wyszukiwanie zazwyczaj wymaga czasu logarytmicznego (index scan).
W przeciwieństwie do tego, czas wyszukiwania wpisu bezpośrednio w tabeli mieści się w O(n), czyli jest liniowy (full table scan).
Im więcej wierszy zawiera tabela, tym większa jest przewaga czasowa dostępu z użyciem indeksu. Przykład ten pokazuje, że dostęp do dużej ilości danych bez wykorzystania indeksu (full table scan) jest nieakceptowalny.
Liczba rekordów
Czas full table scan
Czas index scan
100
0,1 s
0,01 s
10.000
1 s
0,02 s
1.000.000
10 s
0,03 s
100.000.000
100 s
0,04 s
Liczba atrybutów indeksu (oraz ich rozmiar) ma wpływ na czas trwania index scan. Dostęp do indeksu z pięcioma atrybutami jest wolniejszy niż do indeksu z jednym atrybutem. Z tego powodu indeksy nie powinny obejmować zbyt wielu atrybutów.
Indeks może zostać wykorzystany w zapytaniu tylko wtedy, gdy pierwsze n atrybutów indeksu jest w zapytaniu ograniczonych operatorem =. Porównania atrybutów indeksu powinny być połączone operatorem AND oraz występować w tej samej kolejności, co w definicji indeksu. Złożone zagnieżdżenia oraz kombinacje AND i OR utrudniają optymalizatorowi rozpoznanie możliwości użycia indeksu.
SELECT * FROM Tabelle1 WHERE guid=’3BB8’
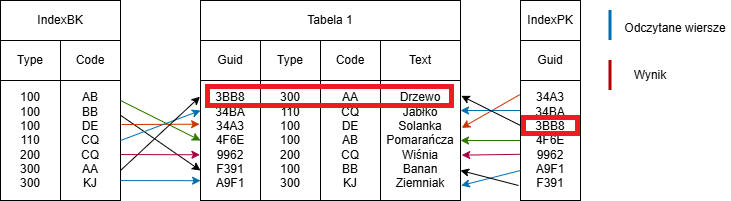
Przykład dostępu z wykorzystaniem wszystkich atrybutów indeksu
Zapytanie może wykorzystać indeks IndexPK, dlatego jego złożoność czasowa wynosi O(log(n)).
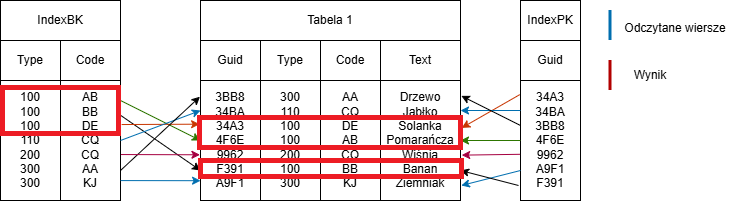
Przykład dostępu z wykorzystaniem pierwszych atrybutów indeksu
Natomiast w poniższym zapytaniu konieczne jest wykonanie full table scan, ponieważ indeks IndexBK nie rozpoczyna się od atrybutu code:
SELECT * FROM Tabelle1 WHERE code=’AB’
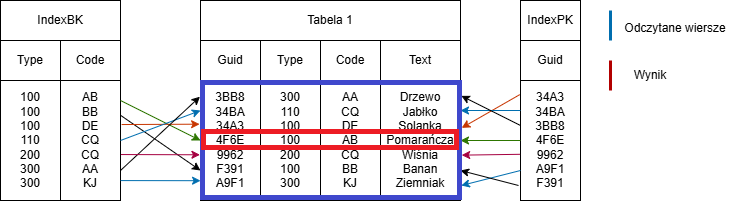
Przykład full table scan
W poniższym zapytaniu może zostać użyty indeks IndexBK, ponieważ do selekcji wykorzystywany jest pierwszy atrybut indeksu (type), a wszystkie atrybuty indeksu zostały podane w klauzuli ORDER BY w poprawnej kolejności:
SELECT * FROM Tabelle1 WHERE type=’100’ ORDER BY type, code
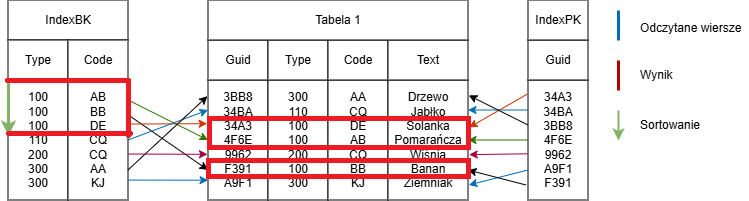
Przykład sortowania z wykorzystaniem indeksu
Natomiast w poniższym zapytaniu indeks IndexBK może zostać użyty wyłącznie do selekcji, a nie do sortowania, ponieważ sortowanie nie obejmuje pierwszych n atrybutów indeksu.
SELECT * FROM Tabelle1 WHERE type=’100’ OR type=’200’ ORDER BY code
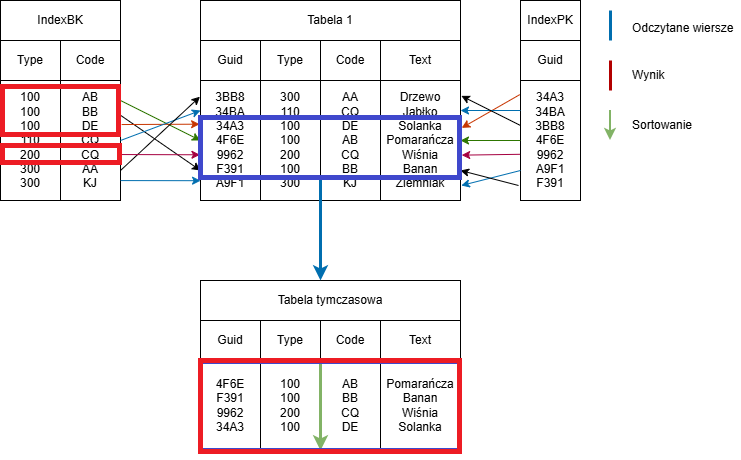
Przykład sortowania w tabeli tymczasowej
Wybór atrybutów indeksu
Indeks może być sensownie wykorzystywany przez DBMS do selekcji tylko wtedy, gdy w istotny sposób ogranicza liczbę możliwych wierszy wynikowych. Jeżeli na przykład indeks ogranicza liczbę potencjalnych wierszy tabeli jedynie o 50%, DBMS najprawdopodobniej nie będzie go używać, ponieważ w takim przypadku full table scan jest korzystniejszy niż index scan.
Indeksy należy zawsze definiować w taki sposób, aby pojedynczy wpis indeksu odnosił się do jak najmniejszej liczby wierszy tabeli. Im większa jest różnica pomiędzy liczbą wpisów indeksu a liczbą wierszy tabeli, tym bardziej wątpliwa jest przydatność takiego indeksu.
Wyjątkiem od powyższej reguły jest sytuacja, w której wykorzystanie wartości atrybutu indeksu nie jest równomiernie rozłożone.
Baza danych zazwyczaj wykorzystuje w zapytaniu tylko jeden indeks na tabelę do selekcji. Tworzenie osobnego indeksu (o niskiej selektywności) dla każdego atrybutu nie ma sensu. Należy zidentyfikować kombinacje atrybutów o wysokiej selektywności, które są wykorzystywane w jak największej liczbie istotnych zapytań, i dla nich definiować indeksy. W tym celu należy korzystać z funkcji monitorowania DBMS.
Zapis z wykorzystaniem indeksu
Podczas wstawiania, modyfikowania i usuwania wierszy tabeli wszystkie indeksy zdefiniowane dla danej tabeli muszą zostać zaktualizowane. Czas potrzebny na aktualizację jednego indeksu mieści się w O(log(n)). W związku z tym czas wstawiania, modyfikowania i usuwania wierszy tabeli rośnie liniowo wraz z liczbą indeksów.
Liczba rekordów
Zmiana przy 1 indeksie
Zmiana przy 2 indeksach
Zmiana przy 4 indeksach
Zmiana przy 8 indeksach
100
5 ms
10 ms
20 ms
40 ms
10 000
10 ms
20 ms
40 ms
80 ms
1 000 000
15 ms
30 ms
60 ms
160 ms
100 000 000
20 ms
40 ms
80 ms
320 ms
W przypadku modyfikacji danych aktualizacja indeksów jest relatywnie czasochłonna. Dlatego dla danych często zmienianych (np. danych ruchowych) nie należy definiować zbyt wielu indeksów dla jednej tabeli. Natomiast w przypadku tabel, których dane zmieniają się rzadko (np. dane podstawowe), zwiększony nakład czasowy związany z aktualizacją indeksów nie ma istotnego negatywnego wpływu.
Relacje
Relacje w Comarch ERP Enterprise są niemal zawsze definiowane za pomocą klucza podstawowego.
W relacjach typu 1:1 klucz podstawowy instancji docelowego obiektu biznesowego jest zapisywany w instancji źródłowego obiektu biznesowego. Podczas odpytywania relacji do instancji docelowej przy dostępie do bazy danych może zostać użyty indeks podstawowy obiektu docelowego.
W relacjach typu 1:n klucz podstawowy instancji źródłowego obiektu biznesowego jest zapisywany w instancji docelowego obiektu biznesowego. W modelu danych należy bezwzględnie utworzyć indeks w docelowym obiekcie biznesowym, który w pełni obejmuje kopie atrybutów klucza podstawowego źródłowego obiektu biznesowego lub przynajmniej od nich się rozpoczyna.
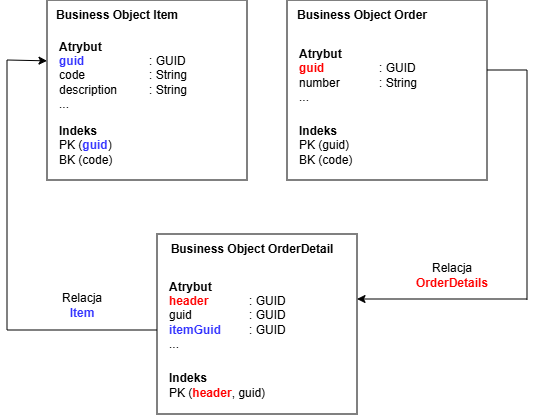
Przykładowe tworzenie indeksów dla relacji 1:1 oraz 1:n
Indeks PK w obiekcie biznesowym OrderDetail rozpoczyna się od atrybutu header, który zawiera wartość atrybutu guid powiązanego obiektu Order. Dzięki temu podczas rozwiązywania relacji OrderDetail może zostać użyty indeks PK obiektu biznesowego OrderDetail w celu ustalenia powiązanych instancji.
W szczególności w przypadku obiektów zależnych (Dependents) zasadne może być wykorzystanie klucza podstawowego encji (tj. jej GUID) jako pierwszej części klucza podstawowego obiektu zależnego.
Klucz podstawowy ma w niektórych bazach danych szczególne znaczenie. W części systemów bazodanowych wiersze tabeli są fizycznie przechowywane zgodnie z kolejnością sortowania w indeksie (klaster). Ma to tę zaletę, że podczas index scan dostęp do wierszy tabeli odbywa się sekwencyjnie, dzięki czemu DBMS musi załadować znacznie mniej danych w celu obliczenia wyniku zapytania.
Dane ruchowe
Dane ruchowe często dzielą się na dane aktywne oraz dane historyczne. Przykładowo wszystkie zamówienia, które mają status inny niż zrealizowany, należą do danych aktywnych, natomiast zamówienia zrealizowane stanowią raczej dane historyczne. Pomiędzy danymi aktywnymi a historycznymi występują następujące różnice:
- wolumen danych aktywnych jest wyraźnie mniejszy niż wolumen danych historycznych,
- na danych aktywnych w bieżącej eksploatacji często wykonywane są operacje odczytu i zapisu,
- na danych historycznych wykonywane są już tylko operacje odczytu, natomiast operacje zapisu występują rzadko.
Rozdzielenie danych ruchowych na aktywne i historyczne jest często realizowane za pomocą atrybutu statusu w nagłówku encji. Jeżeli tworzone są indeksy w celu poprawy wydajności, atrybut statusu powinien – o ile to możliwe – znajdować się na pierwszej pozycji indeksu.
Dane podstawowe
W przypadku danych podstawowych występuje bardzo dużo operacji odczytu, natomiast stosunkowo niewiele operacji zapisu. Wolumen danych podstawowych w dużym stopniu zależy od konkretnego przypadku użycia.
ORDER BY
Jeżeli do sortowania wyniku zapytania nie może zostać użyty żaden indeks, zapotrzebowanie czasowe sortowania wyniku wynosi O(n·log(n)). W praktyce sortowanie małych zbiorów danych jest zwykle nieproporcjonalnie szybsze niż sortowanie dużych zbiorów danych. Małe zbiory danych (np. < 1 MB) DBMS może sortować w pamięci operacyjnej. W przypadku dużych zbiorów danych może być konieczne tymczasowe zapisywanie wyników sortowania na dysku.
DBMS musi obliczyć pełny wynik zapytania, zanim będzie mógł zwrócić pierwszy rekord posortowanego zbioru wyników. Oznacza to w szczególności, że wynik zapytania musi zostać tymczasowo buforowany w bazie danych. Również z tego powodu sortowanie dużych zbiorów wyników jest bardzo czasochłonne.
Jeżeli do sortowania może zostać użyty indeks, zapotrzebowanie czasowe sortowania wynosi O(n). Oznacza to, że czas rośnie liniowo wraz z liczbą rekordów w wyniku.
Liczba rekordów
Czas sortowania bez indeksu
Czas sortowania z indeksem
100
0,2 s
0,2 s
10 000
10 s
2 s
1 000 000
150 s
20 s
100 000 000
2000 s
200 s
Jeżeli sortowanie jest konieczne, należy zatem albo utrzymywać zbiór wyników na tyle mały, aby sortowanie nie było nadmiernie kosztowne, albo utworzyć indeks, który może zostać wykorzystany do sortowania.
GROUP BY
Zapotrzebowanie czasowe przy pobieraniu pełnego zbioru wyników zapytania z klauzulą GROUP BY wynosi – podobnie jak w przypadku sortowania – O(n·log(n)). Tak jak przy sortowaniu, również dla GROUP BY może zostać użyty indeks, jeżeli klauzula GROUP BY składa się z sekwencji pierwszych n atrybutów indeksu.
DISTINCT
Zapotrzebowanie czasowe przy pobieraniu pełnego zbioru wyników zapytania z klauzulą DISTINCT wynosi – podobnie jak w przypadku sortowania – O(n·log(n)). W przypadku DISTINCT nie zawsze jest jednak konieczne obliczenie pełnego wyniku zapytania przed zwróceniem pierwszego wiersza wynikowego.
Optymalizacje
Dostęp do bazy danych
Prawie wszystkie aplikacje zawierają niektóre lub wszystkie z następujących części funkcjonalnych:
- odczyt danych z bazy danych,
- przetwarzanie danych,
- zapis danych do bazy danych,
- wyświetlanie danych.
W większości aplikacji odczytywanych jest więcej danych niż zapisywanych. Odczyt i zapis danych z bazy danych często zajmują najwięcej czasu w aplikacji.
O ile nie są wykonywane zbędne operacje zapisu, a rozmiar transakcji nie jest ani zbyt mały, ani zbyt duży, potencjał optymalizacji operacji zapisu jest niewielki.
Znaczenie współdzielonego cache
Operacje odczytu bardzo często wymagają najwięcej czasu. Dostęp do bazy danych jest w porównaniu z dostępem do danych znajdujących się w serwerze aplikacyjnym znacznie wolniejszy. Z tego powodu Comarch ERP Enterprise posiada współdzielony cache (shared cache), który umożliwia ponowne wykorzystywanie często odczytywanych instancji obiektów biznesowych.
Współdzielony cache ma ograniczony rozmiar i może przechowywać w pamięci określoną liczbę instancji obiektów biznesowych.
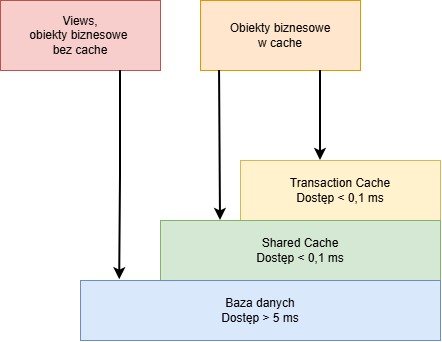
Czas dostępu do obiektu biznesowego
Dostęp do bazy danych może być ponad 50-krotnie wolniejszy niż dostęp do współdzielonego cache. Współczynnik cache hit rate określa, przy jakim procencie odwołań żądana instancja obiektu biznesowego została znaleziona w shared cache.
Ze względu na dużą różnicę pomiędzy czasem dostępu do szybkiego shared cache a wolnej bazy danych, nawet przy pozornie wysokim cache hit rate przekraczającym 90% to faktycznie wykonywane dostępy do bazy danych stanowią decydujący czynnik wpływający na średni czas przetwarzania.
Shared cache przechowuje wyłącznie istniejące obiekty i zasadniczo nie zapamiętuje, które obiekty zostały usunięte lub nie istnieją. Oznacza to, że gdy metoda getObject zostanie wywołana z kluczem, dla którego nie istnieje żadna instancja obiektu biznesowego, usługa persystencji nie może obsłużyć takiego żądania z shared cache i musi wykonać zapytanie do bazy danych.
W szczególności podczas projektowania lub rozszerzania obiektów biznesowych należy zadbać o to, aby w relacjach typu 1:1 istnienie obiektu docelowego mogło zostać wywnioskowane ze stanu obiektu źródłowego.
Wykorzystanie getObjectArray
Dostęp odczytowy do instancji obiektu biznesowego w bazie danych z Comarch ERP Enterprise przebiega przez następujące warstwy:
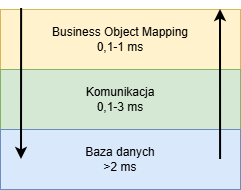
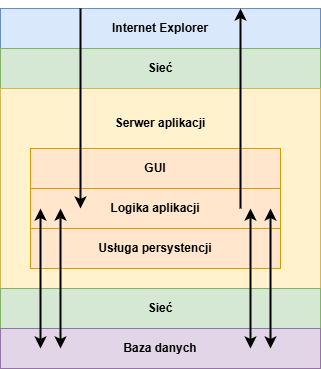
Różne warstwy podczas dostępu do bazy danych
W pierwszym kroku dla operacji odczytu tworzona jest instrukcja SQL, która następnie jest przesyłana do bazy danych, tam wykonywana, a na podstawie wyniku zapytania tworzona jest instancja obiektu biznesowego:
- nakład czasowy potrzebny na zbudowanie zapytania oraz na utworzenie instancji obiektu biznesowego na podstawie wyniku zapytania zależy od liczby atrybutów, jakie obejmuje obiekt biznesowy. Im wyższa jest wydajność CPU komputera, na którym działa serwer aplikacyjny, tym mniejszy jest czas potrzebny na mapowanie obiektu biznesowego.
- nakład czasowy związany z komunikacją również zależy od złożoności obiektu biznesowego. W przypadku komunikacji decydującym czynnikiem wpływającym na czas jest rodzaj połączenia sieciowego pomiędzy serwerem aplikacyjnym a serwerem bazy danych. Jeżeli serwer aplikacyjny i serwer bazy danych działają na tym samym komputerze, narzut komunikacyjny jest minimalny.
- czas przetwarzania po stronie bazy danych zależy od wielu czynników. Jeżeli zapytanie zostanie obsłużone z wewnętrznego cache bazy danych, czas odpowiedzi może wynosić zaledwie kilka milisekund. Jeżeli konieczny jest dostęp do dysków, wykonanie zapytania zajmuje zwykle nieco ponad 10 ms.
Jeżeli metodą getObject odczytywanych jest n instancji obiektów biznesowych, które nie znajdują się w shared cache, wówczas n-krotnie ponoszony jest koszt mapowania obiektu biznesowego, komunikacji oraz wykonania zapytania do bazy danych.
Metoda getObjectArray umożliwia odczyt wielu instancji obiektów biznesowych w ramach jednego zapytania do bazy danych. Dzięki temu zmniejsza się narzut komunikacyjny, ponieważ zapytanie jest przesyłane do serwera bazy danych tylko raz, a wynik zapytania jest przekazywany jako jeden blok z serwera bazy danych do serwera aplikacyjnego.
Jeżeli serwer bazy danych i serwer aplikacyjny nie działają na tym samym komputerze, zastosowanie metody getObjectArray może przyspieszyć odczyt danych w programie nawet do trzykrotności.
Wykorzystanie INSERT
Przy użyciu flagi CisObjectManager.INSERT usługa persystencji nie sprawdza, czy obiekt już istnieje w bazie danych. Podczas odczytu obiektu z użyciem INSERT usługa persystencji nie wykonuje dostępu do bazy danych. Jeżeli jednak obiekt faktycznie istnieje w bazie danych, zastosowanie INSERT prowadzi do błędu wykonania.
Jeżeli nowe obiekty są tworzone z użyciem flagi READ_WRITE, dla każdego nowego obiektu konieczny jest odczyt z bazy danych w celu sprawdzenia, czy obiekt już istnieje. Jeżeli możliwe jest użycie INSERT, operacja odczytu zostaje pominięta, co prowadzi do istotnej oszczędności czasu.
Flaga CisObjectManager.INSERT powinna być stosowana zawsze wtedy, gdy na podstawie przebiegu programu wiadomo, że tworzony obiekt nie istnieje jeszcze w bazie danych. W przypadku tworzenia nowych encji wystarczające jest – o ile w ogóle jest to konieczne – utworzenie głównego obiektu biznesowego encji z użyciem READ_WRITE. Wszystkie obiekty zależne (dependents) encji mogą być tworzone z użyciem INSERT, o ile główny obiekt biznesowy nie jest jeszcze trwały (nie jest zapisany w bazie danych).
Stałe w OQL
Nigdy nie należy używać stałych tekstowych jako parametrów zapytań w OQL, lecz zamiast tego stosować symbol zastępczy ?. Każda instrukcja OQL jest tłumaczona na SQL. W tym celu instrukcja OQL jest parsowana, a następnie – z wykorzystaniem opisów obiektów biznesowych – generowana jest instrukcja SQL. Ponieważ takie tłumaczenie może być stosunkowo kosztowne, wygenerowane w ten sposób instrukcje SQL są przechowywane w pamięci podręcznej.
Każda instrukcja OQL, dla której w cache nie istnieje jeszcze odpowiadająca jej instrukcja SQL, musi zostać przetłumaczona od nowa. W praktyce wartości parametrów zapytań nie są stałe. Jeżeli zamiast symboli zastępczych ? w instrukcji OQL używane są bezpośrednio stałe tekstowe jako parametry zapytania, za każdym razem powstaje nowa instrukcja OQL, która musi być ponownie tłumaczona na SQL. Dodatkowo każda nowa instrukcja bazodanowa może powodować kolejne dostępy do bazy danych związane z monitorowaniem wydajności. Z tych powodów używanie stałych tekstowych jako parametrów zapytań w OQL jest niedozwolone.
Podczas komunikacji z bazą danych instrukcje SQL są wielokrotnie wykorzystywane (prepared statements). Jeżeli parametry zapytania są przekazywane jako stałe tekstowe, wzrasta również obciążenie bazy danych, ponieważ prepared statements nie mogą być ponownie użyte.
CisObjectIterator i=om.getObjectIterator( “SELECT FROM com.cisag.app.general.obj.Item i WHERE “+ “i:guid=TOGUID(‘”+Guid.toHexString(itemGuid)+”’)”);
ObjectIterator i=om.getObjectIterator(
“SELECT FROM com.cisag.app.general.obj.Item i WHERE “+
“i:guid=?”);
i.setGuid(1,itemGuid);
Wykorzystanie getObjectIterator
Metoda getObjectIterator selekcjonuje zbiór instancji obiektów biznesowych danego obiektu biznesowego. Jeżeli obiekt biznesowy ma ustawienie cache LRU lub jest odczytywany z użyciem flag READ_UPDATE albo READ_WRITE, instrukcja SQL wygenerowana z OQL selekcjonuje atrybuty klucza podstawowego obiektu biznesowego.
SELECT FROM com.cisag.app.sales.obj.SalesOrder o dla obiektu biznesowego przechowywanego w cache typu LRU generowane jest następujące zapytanie SQL: SELECT O.GUID FROM SALESORDER O WHERE O.NUMBER>?
WHERE o:number>?
Na podstawie atrybutów klucza podstawowego instancje obiektów biznesowych są ładowane metodą getObjectArray.
Jeżeli obiekt biznesowy nie jest odczytywany z cache lub jest odczytywany z użyciem flagi BYPASS_CACHE, instrukcja SQL wygenerowana z OQL selekcjonuje wszystkie atrybuty obiektu biznesowego.
SELECT FROM com.cisag.app.sales.obj.SalesOrder o dla obiektu biznesowego, który nie jest przechowywany w cache, generowane jest następujące zapytanie SQL: SELECT * FROM SALESORDER O WHERE O.NUMBER>?
WHERE o:number>?
Selekcja atrybutów klucza podstawowego jest przy cache hit rate na poziomie około 70% szybsza niż selekcja wszystkich atrybutów. Zazwyczaj jednak aplikacja nie jest w stanie jednoznacznie określić, który sposób dostępu jest korzystniejszy. W przypadku przetwarzania dużych wolumenów danych może być jednak korzystne stosowanie flagi BYPASS_CACHE również dla obiektów przechowywanych w cache.
Przy cache hit rate równym 0% selekcja przez klucz podstawowy jest wyraźnie wolniejsza niż selekcja pełnego obiektu. Natomiast przy cache hit rate równym 100% selekcja przez klucz podstawowy jest zdecydowanie szybsza niż selekcja pełnego obiektu.
Wykorzystanie getResultSet
Metoda getResultSet umożliwia – podobnie jak zapytanie SQL – selekcję zbioru wartości z dowolnych obiektów biznesowych.
Jeżeli z obiektu biznesowego potrzebnych jest jedynie stosunkowo niewiele atrybutów, a cache hit rate tego obiektu nie jest szczególnie wysoki (< 95%), bardziej opłacalne może być odczytanie atrybutów za pomocą getResultSet niż budowanie pełnych obiektów przy użyciu getObjectIterator.
SELECT FROM com.cisag.app.sales.obj.SalesOrder o działa wolniej niż zapytanie OQL dla getResultSet SELECT o:guid, o:pickingStatus
WHERE o:number>?
FROM com.cisag.app.sales.obj.SalesOrder o
WHERE o:number>?
Wykorzystanie getUpdateStatement()
Metoda getUpdateStatement() umożliwia wykonywanie instrukcji UPDATE oraz DELETE bezpośrednio na bazie danych. Czas wykonania takich instrukcji jest zazwyczaj znacznie krótszy niż czas realizacji równoważnej logiki opartej na instancjach obiektów biznesowych.
Po użyciu instrukcji aktualizacji wszystkie instancje danego obiektu biznesowego są usuwane ze wszystkich cache wszystkich serwerów aplikacyjnych w systemie. Zapewnia to spójność shared cache z zawartością bazy danych.
Częste stosowanie getUpdateStatement() znacząco obniża efektywność shared cache. Z tego powodu instrukcje UPDATE powinny być wykorzystywane głównie w reorganizacjach oraz w przetwarzaniu masowych danych.
Przetwarzanie blokowe w klasach logiki
Każdy etap przetwarzania musi operować na danych w jednostkach o odpowiedniej wielkości. Jednostki te nie mogą być ani zbyt duże, ani zbyt małe.
Jeżeli przetwarzanie odbywa się w zbyt dużych jednostkach, zapotrzebowanie na zasoby (pamięć operacyjną oraz częściowo CPU) po stronie serwera aplikacyjnego jest zbyt wysokie.
Jeżeli natomiast przetwarzanie odbywa się w zbyt małych jednostkach, zapotrzebowanie na zasoby (obciążenie bazy danych oraz częściowo CPU) po stronie serwera aplikacyjnego również jest zbyt wysokie. Przy zbyt małych jednostkach dane są zapisywane w zbyt małych transakcjach, co prowadzi do dużego obciążenia bazy danych. Dodatkowo w takim przypadku operacje odczytu zazwyczaj nie są realizowane w sposób blokowy.
Przy projektowaniu klas logiki należy przestrzegać następujących zasad:
- jedna transakcja powinna obejmować maksymalnie 1000 obiektów biznesowych,
- wszystkie operacje odczytu powinny być realizowane blokowo za pomocą getObjectArray(),
- logika powinna wykorzystywać jedynie ograniczoną ilość pamięci operacyjnej,
- jedna instrukcja OQL nie powinna przekraczać 4000 znaków.
for (…) {
…
i=om.getObjectIterator(
“SELECT FROM com.cisag.app.sales.obj.SalesOrder so “+
“WHERE so:status=? AND ”
“so:totalValue.grossValue.amount>=? AND “+
“so:totalValue.grossValue.amount<?”;
i.setShort(1,x);
i.setDecimal(2,y);
i.setDecimal(3,z);
…
}
W powyższym programie dla każdego przebiegu pętli zewnętrznej wykonywany jest dostęp do tabeli SalesOrder. Ponieważ na atrybucie totalValue.grossValue.amount nie istnieje indeks, dostęp ten jest relatywnie kosztowny.
Poprawny przykład przetwarzania blokowego:
StringBuffer oql = new StringBuffer(“SELECT “+
”FROM com.cisag.app.sales.obj.SalesOrder so
“WHERE so:status=? AND (“);
ArrayList values = new ArrayList();
String separator = “”;
for (…) {
…
oql.append(separator);
oql.append(“(so:totalValue.grossValue.amount>=? AND “+
“so:totalValue.grossValue.amount<?)”
values.add(x);
values.add(y);
values.add(z);
separator=” OR “;
if (blockSize>10 || …) {
oql.append(“)”);
i=om.getObjectIterator(oql.toString());
int idx=1;
for (Iterator v=values.iterator(); v.hasNext();) {
i.setShort(idx++,((Short)v.next()).shortValue());
i.setDecimal(idx++,(CisDecimal)v.next());
i.setDecimal(idx++,(CisDecimal)v.next());
}
…
separator = “”;
oql = new StringBuffer(“SELECT “+
”FROM com.cisag.app.sales.obj.SalesOrder so
“WHERE so:status=? AND (“);
…
}
W powyższym programie dostęp do tabeli SalesOrder wykonywany jest tylko co dziesiąty przebieg pętli zewnętrznej. Dzięki temu obciążenie bazy danych zostaje w przybliżeniu zmniejszone dziesięciokrotnie.
Wyszukiwanie instrukcji bazodanowych w aplikacjach
Jeżeli na podstawie monitorów wydajności lub protokołów profilowania zidentyfikowano jedną lub kilka instrukcji bazodanowych odpowiedzialnych za zbyt długi czas odpowiedzi aplikacji, należy znaleźć metody klas, które wykonują te instrukcje bazodanowe:
- Uruchomienie serwera aplikacyjnego w debuggerze.
- Zalogowanie się do serwera aplikacji.
- Przygotowanie środowiska w taki sposób, aby możliwe było uruchomienie problematycznej funkcji aplikacji.
- Ustawienie w debuggerze breakpointu w aplikacji na pierwszej linii problematycznej funkcji.
- Włączenie wyprowadzania wszystkich wykonywanych instrukcji bazodanowych:
dbgcls -class:com.cisag.sys.kernel.sql.CisPreparedStatement. - Uruchomienie problematycznej funkcji.
- Debugowanie do momentu, aż poszukiwana instrukcja bazodanowa zostanie wyświetlona jako komunikat debug.
Przy długich czasach wykonania należy zoptymalizować instrukcję bazodanową, natomiast przy bardzo częstym wykonywaniu instrukcji o krótkim czasie wykonania należy ograniczyć częstotliwość jej uruchamiania.
Wyszukiwania i listy
W wyszukiwaniach i listach najczęściej generowane są złożone zapytania bazodanowe. Zapytania te są dynamicznie składane w zależności od użytych parametrów wyszukiwania. Każdy system może – w zależności od wykorzystywanej funkcjonalności – generować inne zapytania. Z tego powodu, szczególnie w przypadku list, nie zawsze jest łatwo dostarczyć w standardzie indeksy, które byłyby użyteczne dla wszystkich możliwych wymagań klientów.
Wybór wartości domyślnych dla pól wyszukiwania
W wyszukiwaniach i aplikacjach typu listy, w których wyświetlane są wyniki wyszukiwania, są zawsze sortowane. Sortowanie dużych zbiorów wyników jest bardzo czasochłonne. Tylko rzadko istnieje możliwość utworzenia sensownego indeksu na potrzeby sortowania w wyszukiwaniach.
Wielu użytkowników otwiera wyszukiwanie i uruchamia je bez zawężania wyników przy użyciu kryteriów wyszukiwania. Jeżeli wartości domyślne wyszukiwania nie zawężają wyników, wybierany jest cały zasób danych i prawdopodobnie musi on zostać jeszcze posortowany. Powoduje to na przykład w przypadku danych ruchowych ekstremalnie wysokie obciążenie bazy danych.
Jeżeli wartości domyślne pól wyszukiwania zostaną dobrane w taki sposób, aby zbiór wyników miał ograniczony rozmiar, uruchamianie wyszukiwania z wartościami domyślnymi nie będzie tak mocno obciążać systemu.
W szczególności dane ruchowe często dzielą się na dane aktywne i historyczne. Przykładowo wszystkie zamówienia o statusie innym niż zrealizowany należą do danych aktywnych, natomiast wszystkie zamówienia zrealizowane stanowią raczej dane historyczne. Wolumen danych aktywnych jest wyraźnie mniejszy niż wolumen danych historycznych. Pola wyszukiwania w wyszukiwaniach i listach powinny być zawsze wstępnie ustawione w taki sposób, aby wyszukiwanie obejmowało wyłącznie dane aktywne.
Dostosowanie specyficzne dla klienta
Wyszukiwania, a w szczególności listy, mogą zostać w przypadku problemów wydajnościowych dostosowane do potrzeb klienta. W takim przypadku należy ukryć wszystkie pola wyszukiwania i sortowania, których klient nie potrzebuje. Im mniej dostępnych jest możliwości wyszukiwania i sortowania, tym łatwiej jest tworzyć indeksy specyficzne dla danego klienta.
Jeżeli istnieje bardzo wiele możliwości wyszukiwania i sortowania oraz nie zostaną one ograniczone, mogą wystąpić kombinacje, które charakteryzują się bardzo niekorzystnym czasem wykonania.