Wprowadzenie
W artykule opisano zakres funkcjonalny i funkcjonalność Persistence service w systemie.
Persistence service jest interfejsem do otwierania i zapisywania danych. Jest częścią silnika systemu i zapewnia podstawowe funkcje. Persistence service może uzyskiwać dostęp do różnych systemów zarządzania bazami danych (DBMS). Gwarantowany jest jednolity dostęp do baz danych w różnych systemach DBMS. Czasami różne zachowanie DBMS jest ukryte przed aplikacją i programami systemowymi przez Persistence service. Funkcjonalność programu aplikacji jest zatem niezależna od używanego systemu DBMS.
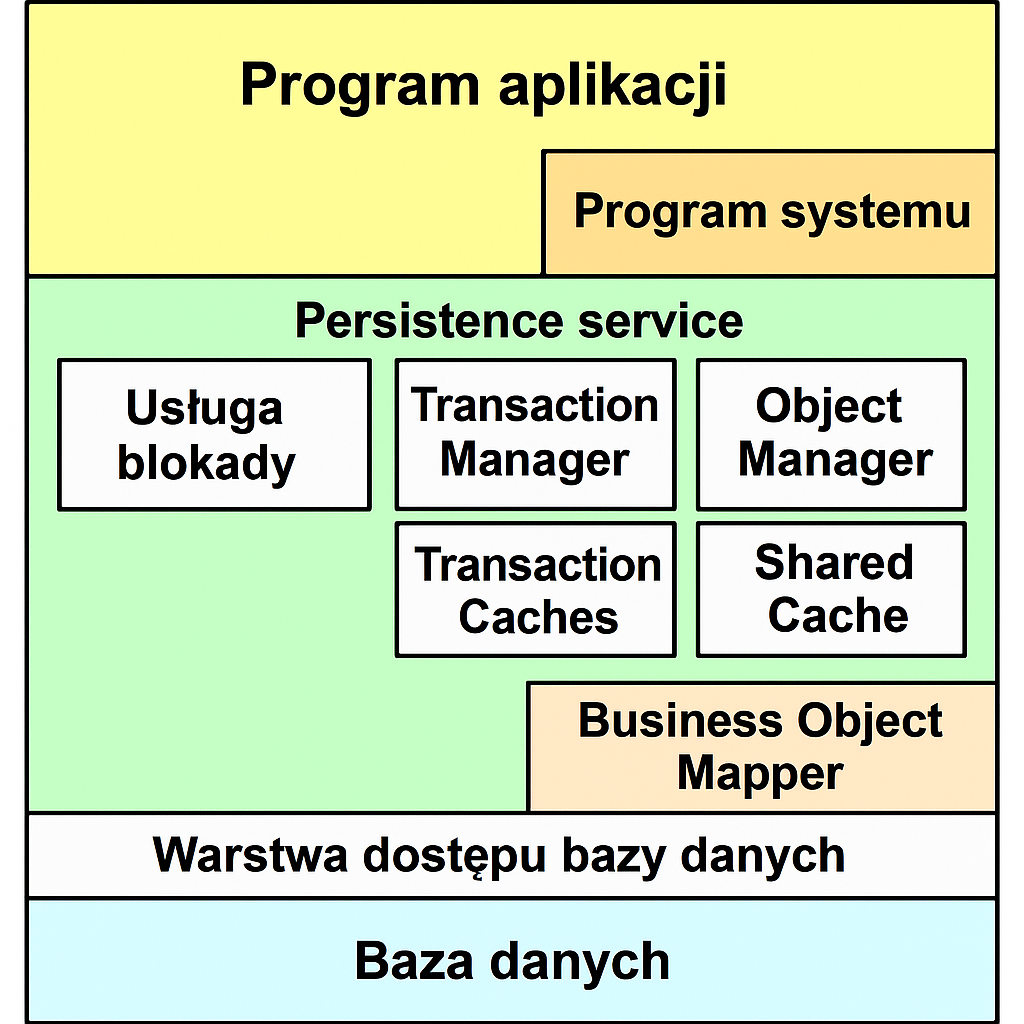
Program aplikacji (w tym programy systemowe) zawsze uzyskuje dostęp do bazy danych za pośrednictwem Persistence service. Składa się ona z kilku komponentów i ma strukturę warstwową. Program zawsze używa manager transakcji lub manager obiektów do odczytu lub zapisywania danych. Korzystają one z usługi blokady, aby zsynchronizować dostęp do obiektów biznesowych. Manager uzyskuje dostęp do pamięci podręcznej transakcji (Transaction Cache) i współdzielonej pamięci podręcznej (Shared Cache). Aby otworzyć lub zapisać obiekt biznesowy, Persistence service korzysta z klasy mappera wygenerowanej dla każdego obiektu biznesowego, która konwertuje dane między modelem obiektowym a relacyjnym modelem bazy danych. Warstwa dostępu do bazy danych (sterownik JDBC) zapewnia interfejsy do bezpośredniej komunikacji z bazą danych. Wykonuje dostęp do bazy danych i hermetyzuje funkcje specyficzne dla bazy danych. Baza danych przechowuje dane instancji obiektów biznesowych w tabelach i wykonuje na nich zapytania SQL.
Grupa docelowa
- Zaawansowani deweloperzy
Wymagania wstępne
Podstawy Persistence service są niezbędne do zrozumienia tego dokumentu. Dokumentacja Podręcznik programowania stanowi wprowadzenie do podstaw.
Skróty
| Skrót | Pełna nazwa / Opis |
| API | Interfejs programowania aplikacji |
| BO | Obiekt biznesowy |
| BOD | Definicja obiektu biznesowego |
| DB | Baza danych |
| DHTML | Dynamiczny HTML |
| GUI | Graficzny interfejs użytkownika |
| GUID | Globalny unikalny identyfikator |
| HTML | Język znaczników hipertekstowych |
| JDK | Java Development Kit |
| JVM | Wirtualna maszyna Java |
| IDE | Zintegrowane środowisko deweloperskie |
| MM | Manager wiadomości |
| NLS | Krajowe wsparcie językowe |
| LDT | Logiczny typ danych |
| OLTP | Przetwarzanie transakcji online |
| OLAP | Przetwarzanie analityczne online |
| OM | Object Manager |
| OQL | Obiektowy język zapytań |
| SAS | Serwer aplikacji systemu ERP |
| SDK | Zestaw do tworzenia systemów ERP |
| SOM | Manager raportów systemu ERP |
| SQL | Strukturalny język zapytań |
| SVM | Maszyna wirtualna systemu ERP, synonim SAS |
| TM | Manager transakcji |
| UI | Interfejs użytkownika |
| URI | Uniform Resource Identifier |
| URL | Uniform Resource Locator |
| VE | Element wizualny |
| VEC | Visual Element Container |
Istotne obiekty deweloperskie
W kolejnych rozdziałach opisano obiekty deweloperskie, z którymi współpracuje Persistence service.
Obiekt biznesowy
Obiekt biznesowy jest kontenerem danych bez wyspecjalizowanej logiki. Dla obiektu biznesowego generowana jest tabela główna i tabele pomocnicze ze strukturami dostępu z definicji indeksów przechowywanych w bazie danych. Obiekt biznesowy jest zmienną techniczną, którą Persistence service może odczytywać, zapisywać i usuwać. Konwersja odbywa się między obiektowym modelem danych używanym w aplikacji a relacyjnym modelem danych bazy danych. Obiekty biznesowe to jedyny sposób na trwałe przechowywanie danych.
Każdy obiekt biznesowy jest opisany w aplikacji Obiekty deweloperskie. Ten opis obiektu obejmuje definicje atrybutów, kluczy i relacji. Typ obiektu deweloperskiego Business Object jest używany do opisu obiektu w aplikacji Obiekty deweloperskie.
Poniższa ilustracja przedstawia przykład opisu obiektu biznesowego Item:

Klasy Java
Po wywołaniu narzędzia crtbo z opisu obiektu generowane są trzy klasy Java:
- klasa główna (main class)
- klasa stanu (state class)
- klasa mappera (mapper class)
Klasy Java są przechowywane w pakiecie Java odpowiadającym przestrzeni nazw pod nazwą obiektu biznesowego (ewentualnie z przyrostkiem _State lub _Mapper). Wygenerowane klasy Java hermetyzują między innymi dostęp do bazy danych i zapewniają programowi aplikacyjnemu dostęp do danych instancji obiektu biznesowego.
Klasa główna, która ma taką samą nazwę jak obiekt biznesowy, zapewnia dostęp do właściwości instancji obiektu biznesowego. Klasa główna zawiera metody get…(), set…() i is…() (dla Boolean) dla dostępu do atrybutów obiektu biznesowego. Odpowiednie metody build…Key() są generowane dla unikalnych indeksów, które są używane do odczytu instancji przy użyciu unikalnych wartości klucza z Persistence service. Metody retrieve…(), które można wykorzystać do określenia przypisanych obiektów biznesowych, są generowane dla określonych relacji. Metody publiczne są określane wyłącznie przez opis obiektu. Klasa obiektu biznesowego nie może zostać zmieniona. W szczególności oznacza to, że do klasy głównej nie można dodawać żadnych funkcji logicznych. Muszą one zostać zaimplementowane w oddzielnych klasach logicznych (w przestrzeni nazw z przyrostkieme.log).
Następujące metody dostępu do atrybutów są generowane dla obiektu biznesowego Item (przykład) w powiązanej klasie głównej:
public byte[] getGuid() ; public void setGuid(byte[]newValue); public String getNumber() ; public void setNumber(String newValue); public String getDescription() ; public void setDescription(String newValue); public CisDecimal[] getSize() ; public setSize(CisDecimal[] newValue); public DomesticAmount getValue() ; public DomesticAmountMutable getMutableValue() ; public void setValue (DomesticAmountMutable newValue);
Następujące metody są generowane w celu utworzenia kluczy Persistence service ze zdefiniowanych kluczy obiektów biznesowych:
public byte[] buildPrimaryKey(byte[] guid); public byte[] buildByNumberKey(String number);
Dla relacji generowane są następujące metody:
public InventoryItem retrieveInventoryItem(); public OriginalItem retrieveOriginalItem(); public CisObjectIterator<AlternativeItem> retrieveAlternativeItems();
Rozszerzenie klasy głównej
Klasa główna może zostać rozszerzona przez pochodną w celu nadpisania niektórych metod. Ta klasa implementacji podlega ograniczeniom. Tylko funkcjonalności opisane w tym rozdziale mogą być zaimplementowane w tej klasie.
Klasa implementacji podlega następującej konwencji nazewnictwa: przestrzeń nazw jest pobierana z klasy nadrzędnej, nazwa klasy jest rozszerzana o przyrostek Impl. Relacja dziedziczenia musi być zapisana w metadanych obiektu biznesowego. Nazwę nowej klasy wprowadza się w aplikacji Obiekty deweloperskie, typ Business object -> zakładka Edytor -> podzakładka Ustawienia -> sekcja Inne ustawienia -> pole Klasa Java.
Nowo wygenerowane źródła wykorzystują następnie wewnętrznie klasę pochodną. Nowa klasa (np. BookImpl) nie może być używana bezpośrednio w aplikacji. W tym celu zawsze używana jest klasa główna (np. Book).
metoda get_instanceString():
W klasie implementacji domyślną implementację można zastąpić implementacją niestandardową.
Persistence service nie może być używana z wyjątkiem metody resolveForeignKey() klasy com.cisag.pgm.datatype.CisObjectUtility. Można jej użyć do otwarcia instancji obiektu biznesowego dla klucza obcego. Metoda zwraca przejściową kopię instancji obiektu biznesowego dla przekazanego klucza technicznego i typu bazy danych w języku bazy danych odwołującej się instancji obiektu biznesowego. Metoda zwraca null dla nieistniejącej instancji. Sygnatura to:
public static CisObject resolveForeignKey( CisObject Source, String targetDatabaseAlias, byte[] targetPrimaryKey);
Implementacja klasy XYZImpl wywodzącej się z klasy XYZ jest pokazana poniżej jako przykład, w którym opisowy InstanceString jest tworzony z klucza biznesowego przywoływanego obiektu biznesowego i własnego klucza biznesowego użytkownika.
W przypadku zamówienia klucz biznesowy składa się z typu (GUID typu (klucz obcy)) i numeru zamówienia. Wyświetlany InstanceString powinien składać się z identyfikacji typu zamówienia i numeru zamówienia.
public class XYZImpl {
...
public String get_instanceString() {
String result = getNumber();
byte[] typeGuid = getTypeGuid();
if (!Guid.isInvalidGuid(typeGuid)) {
// Pomiń nieistniejące obiekty
XYZType t = (XYZType) CisObjectUtility.
resolveForeignKey(this, CisTransactionManager.OLTP,
XYZType.buildPrimaryKey(typeGuid));
if (t != null) {
result = t.getCode() + " " + getNumber();
}
}
return result;
}
...
}
get_permission():
Ta metoda służy do implementacji sprawdzania uprawnień związanych z treścią.
Klucz
Opis obiektu biznesowego zawiera również opis indeksów obiektu biznesowego. Indeks zasadniczo składa się z nazwy, typu i sekwencji atrybutów obiektu biznesowego. Niektóre z tych indeksów są unikalne w zależności od typu i są używane do identyfikacji instancji obiektu biznesowego. Te unikalne indeksy są również określane poniżej jako klucze. Każdy obiekt biznesowy posiada klucz główny (typ Primary Index), opcjonalnie klucz biznesowy (typ Secondary (Business Key)) i opcjonalnie dowolną liczbę kluczy dodatkowych (typ Secondary (unique)).
Klucz podstawowy obiektu biznesowego jest zawsze kluczem technicznym, który jest tak kompaktowy, jak to możliwe i nie zmienia się podczas istnienia instancji. Klucz podstawowy powinien zawierać co najmniej jeden atrybut typu GUID.
Korzystanie z identyfikatorów GUID oferuje następujące korzyści:
- Identyfikatory GUID mogą być efektywnie obliczane lokalnie, tj. nie ma potrzeby korzystania z usługi przypisywania numerów itp.
- Identyfikatory GUID zapewniają wysoką selektywność w drzewach B* (indeksach DB)
- Identyfikatory GUID dobrze nadają się do procedur skrótu
- Identyfikatory GUID są globalnie unikalne, co ułatwia na przykład wdrażanie scenariuszy replikacji
- Identyfikatory GUID są stosunkowo niewielki (16 bajtów)
Stała wartość elementu zestawu wartości jest identyfikatorem technicznym i może być używana w kluczu podstawowym obiektu biznesowego. Klucz podstawowy instancji obiektu biznesowego nie może już zostać zmieniony po pierwszym zapisaniu go w bazie danych. Długie klucze podstawowe (np. zawierające więcej niż 2 identyfikatory GUID) oznaczają więcej przetwarzania dla Persistence service. W związku z tym zaleca się, aby klucz podstawowy był jak najkrótszy.
Identyfikator GUID w kluczu podstawowym powinien być używany tylko dla jednej instancji. W szczególnych przypadkach dopuszczalny jest identyfikator kilku instancji obiektów biznesowych przy użyciu tej samej wartości GUID. Powinno to jednak mieć miejsce tylko wtedy, gdy dane obiekty biznesowe odnoszą się do tej samej zmiennej biznesowej (np. Item, SalesItem, InventoryItem, …).
Niektóre obiekty mają identyfikację funkcjonalną, taką jak numer artykułu lub kombinacja typu zamówienia i numeru zamówienia. Ta identyfikacja biznesowa jest mapowana w kluczu biznesowym i powinna reprezentować czytelne dla człowieka odniesienie do instancji obiektu biznesowego. Klucz biznesowy powinien zawierać atrybuty o najprostszym możliwym typie, takie jak ciąg znaków dla liczb. Klucz biznesowy może również zawierać techniczne klucze obce, takie jak identyfikator GUID typu zamówienia. Definicja klucza biznesowego jest również wykorzystywana w sterowniku ODBC w celu zapewnienia użytkownikowi lepszych opcji dostępu poprzez dodatkowe atrybuty wirtualne.
Dalsze techniczne lub specjalistyczne identyfikatory mogą być rejestrowane jako klucze dodatkowe. Klucze dodatkowe mogą zawierać atrybuty z dowolnymi prymitywnymi typami danych.
Relacje między obiektami biznesowymi są definiowane wyłącznie za pomocą klucza głównego. Ma to następujące przyczyny:
- Klucz podstawowy jest krótki
- Klucz główny ma wysoką selektywność
- Klucz podstawowy obiektu biznesowego nie może już zostać zmieniony w późniejszym terminie
Wartości zerowe
Wartości zerowe dla atrybutów klucza są niedozwolone. Deweloper musi upewnić się, że atrybuty są wypełnione odpowiednimi wartościami. Przykładowo, dla atrybutu typu GUID może to być ZEROGUID.
Generowanie kluczy Persistence service
Persistence service identyfikuje instancję obiektu biznesowego poprzez techniczną reprezentację klucza instancji obiektu biznesowego. Ten klucz Persistence service jest tablicą bajtów, w której przechowywane są atrybuty klucza, powiązana baza danych i klasa obiektu biznesowego. Zawiera również informacje takie jak typ klucza i długości atrybutów.
Klasa obiektu biznesowego ma metody generowania klucza usługi trwałości dla klucza. Metoda tworzenia reprezentacji technicznej jest generowana dla każdego zdefiniowanego klucza obiektu biznesowego. Nazwa metody jest tworzona z przedrostka build, nazwy klucza obiektu biznesowego i przyrostka Key. Wartości atrybutów klucza są przekazywane do metody jako parametry, np. metoda dla klucza podstawowego nosi nazwę buildPrimaryKey(). Klucze Persistence service nie są unikatowe dla instancji obiektu biznesowego i mogą następnie ulec zmianie, gdy są używane w Persistence service. Z tego powodu nie wolno używać kluczy usługi trwałości jako kluczy na przykład w CisHashMaps.
Referencje obiektów
Jeśli referencje obiektów są nadal używane, należy je jak najszybciej usunąć. Alternatywnie można użyć tablicy bajtów o wystarczającej długości (np. 256 bajtów), w której przechowywany jest klucz podstawowy obiektu, do którego się odwołano, zbudowany za pomocą buildPrimaryKey.
Referencja obiektu to tablica bajtów o ograniczonej długości, która identyfikuje dokładnie jedną instancję obiektu biznesowego. Może być używany do odwoływania się do innej nieznanej instancji obiektu biznesowego z instancji obiektu biznesowego. Referencja obiektu jest niezależna od długości klucza głównego obiektu biznesowego, do którego się odwołuje. Reprezentuje pośrednictwo, które przypisuje klucz o określonej maksymalnej długości do klucza podstawowego instancji obiektu biznesowego. Jeśli klucz podstawowy jest krótszy niż maksymalna długość, odniesienie do obiektu jest obliczane na tej podstawie w czasie wykonywania. Jeśli klucz główny jest dłuższy, przypisanie między kluczami jest zapisywane w obiekcie biznesowym com.cisag.sys.kernel.obj.ObjectReference, ponieważ w tym przypadku klucz nie może zostać obliczony. Ze względu na ograniczoną długość odniesienia do obiektu, możliwe jest zapisanie go w binarnym typie danych bez użycia BLOB. Referencja obiektu może być używana w taki sam sposób jak klucz Persistence service w celu uzyskania dostępu do instancji obiektu biznesowego (np. poprzez getObject()).
Referencję obiektu instancji obiektu biznesowego, który nie jest przejściowy, można uzyskać za pomocą metody get_objectReference() klasy obiektu biznesowego. W tym celu należy najpierw otworzyć transakcję. W zależności od długości klucza głównego, przypisanie klucza jest zapisywane, jeśli nie utworzono jeszcze odniesienia do obiektu dla instancji. Odbywa się to w sposób przejrzysty dla dewelopera. Transakcja musi być zawsze potwierdzona przez commit, aby wygenerować prawidłowe odniesienie do obiektu. W przeciwnym razie zwrócone odniesienie do obiektu jest nieprawidłowe. Żadne odniesienie do obiektu nie może być zapytane o przejściową instancję obiektu biznesowego.
Podczas odpytywania odniesienia do obiektu dla instancji obiektu biznesowego zależnego od czasu, zawsze wskazuje to na bieżącą wersję.
Odniesienia do obiektów powinny być używane tylko w wyjątkowych przypadkach z następujących powodów:
- W języku OQL nie można zdefiniować sprzężenia z obiektem, do którego istnieje odwołanie, poprzez odwołanie do obiektu.
- Sterownik ODBC i inne narzędzia pracujące z bazą danych ERP nie potrafią rozpoznawać referencji do obiektów.
- Zapytanie o referencję do obiektu wymaga transakcji, która musi zostać zakończona poleceniem commit. Nieprawidłowe użycie może w pewnych okolicznościach prowadzić do niewykrywalnych błędów.
Atrybuty Part
W klasie obiektu biznesowego generowanych jest kilka metod dostępu do atrybutu części:
- Metoda get<AttributName>() zwraca niezmienną instancję klasy Imutable Part, z której można uzyskać wartości atrybutów części za pomocą odpowiednich metod ..()
- Metoda getMutable<nazwa atrybutu>() zwraca mutowalną instancję mutowalnej klasy Part, na której wartości atrybutów można wyszukiwać za pomocą odpowiednich metod ..() lub ustawiać za pomocą metod set…(). Nie zmienia to obiektu stanu instancji obiektu biznesowego, a jedynie instancję części. Zmieniona instancja części musi zostać ponownie jawnie przeniesiona do instancji obiektu biznesowego.
- Metoda set() dla atrybutu części zapisuje zmienną instancję Part w obiekcie stanu instancji obiektu biznesowego. Oznacza to, że wszelkie zmiany wprowadzone w instancji części są przenoszone do instancji obiektu biznesowego.
W OQL prymitywne atrybuty części, ale nie kompletna część, mogą być odpytywane z atrybutów części. Nazwa atrybutu części może być używana z OQL jako wartość logiczna do zapytania, czy atrybut części w instancji obiektu biznesowego ma wartość null. Jeśli atrybut części nie ma wartości null, wartość logiczna to TRUE. Prymitywne atrybuty części mają prawidłowe wartości tylko wtedy, gdy atrybut części w instancji obiektu biznesowego nie jest null.
Zależność od czasu
Zależność czasowa dla obiektu biznesowego jest konfigurowana w aplikacji Obiekty deweloperskie w zakładce Ustawienia. Następujące typy są obsługiwane w ten sam sposób przez Persistence service:
- Bez
- Dodawaj zawsze nowy rekord danych
- Pisz zawsze w aktualnym rekordzie danych
- Sterowany przez aplikację
- Data ze strefą czasową przez aplikację
- Czas ze strefą czasową przez aplikację
Jeśli jeden z tych typów zależności od czasu został ustawiony dla obiektu biznesowego, wówczas obiekt biznesowy jest zależny od czasu dla Persistence service. To, czy konkretna instancja obiektu biznesowego jest zależna od czasu, można sprawdzić za pomocą metody is_timeDependent() klasy obiektu biznesowego.
Obiekt biznesowy i wszystkie obiekty zależne muszą mieć ten sam typ zależności od czasu. Zabronione jest, aby obiekt zależny miał inny typ zależności czasowej niż obiekt biznesowy.
Okres obowiązywania
Obiekty biznesowe zależne od czasu mają przedział obowiązywania. Jest on zapisywany w specjalnych atrybutach validFrom i validUntil obiektu biznesowego zależnego od daty. Data zapisana w atrybucie validFrom wskazuje początek okresu obowiązywania, a data zapisana w atrybucie validUntil wskazuje koniec okresu obowiązywania. Czas validFrom należy do okresu obowiązywania, ale czas określony przez validUntil już nie.
Okres obowiązywania wszystkich instancji obiektów zależnych i instancji obiektu biznesowego musi być identyczny. Zabronione jest, aby instancja zależna miała inny okres obowiązywania niż instancja jednostki biznesowej.
Rozszerzenie unikalnych kluczy
Wszystkie zdefiniowane unikalne klucze są niejawnie rozszerzane o atrybut validFrom dla obiektu biznesowego zależnego od czasu. Oznacza to, że unikalność wartości klucza nie jest już gwarantowana przez Persistence service lub bazę danych. Kilka instancji może teraz istnieć dla określonej wartości klucza, które są ważne od różnych punktów w czasie. W związku z tym mówi się również o wersjach instancji obiektu biznesowego. Ich przedziały obowiązywania nie mogą się pokrywać i nie mogą występować luki. Wersja jest ważna dla dokładnie jednego punktu w czasie, jeśli mieści się on w jej przedziale obowiązywania. Aktualnie obowiązującą wersją instancji obiektu biznesowego zależnego od czasu jest wersja, w której przedziale obowiązywania znajduje się bieżący punkt w czasie.
Zmiany wartości klucza nie są dozwolone w przypadku instancji obiektów biznesowych zależnych od czasu, ponieważ usługa trwałości nie uwzględnia automatycznie wszystkich powiązanych wersji.
Generowanie kluczy Persistence service dla określonych wersji
Metoda buildTimeDependentKey() klasy obiektu biznesowego służy do generowania klucza Persistence service w celu otwarcia określonej wersji. Wartość klucza głównego i znacznik czasu z atrybutu validFrom są przekazywane do tej metody jako parametry. Klucz Persistence service zależny od czasu instancji obiektu biznesowego można sprawdzić za pomocą metody get_timeDependentKey().
Bieżąca wersja jest otwierana za pomocą konwencjonalnie wygenerowanych kluczy Persistence service.
Dostęp do sąsiednich wersji
W przypadku wersji zależnej od czasu, bezpośrednia następna wersja może być odpytywana przy użyciu metody retrieve_nextVersion() lub bezpośrednia poprzednia wersja przy użyciu metody retrieve_previousVersion().
Atrybuty NLS
NLS to skrót od National Language Support. Atrybut NLS jest atrybutem wielojęzycznym opartym na typie pierwotnym String, dla którego ustawiono funkcję Możliwych wiele języków. Jeśli atrybut ma przypisany lokalny logiczny typ danych, wartość może być dostępna w kilku tłumaczeniach. Tłumaczenia atrybutu są zapisywane w oddzielnym obiekcie biznesowym NLS. Baza danych ma zawsze przypisany język główny i ewentualnie kilka języków dodatkowych. Wartość w głównym języku atrybutu jest zapisywana w tabeli powiązanego obiektu biznesowego i dlatego może być szybko odpytywana. Wartości języków drugorzędnych (tłumaczeń) atrybutu są przechowywane w oddzielnej tabeli obiektu NLS. Z punktu widzenia twórcy aplikacji dostęp do atrybutu NLS jest w dużej mierze przejrzysty.
Typ danych ustawiony dla obiektu biznesowego w bazie danych OLTP wpływa na to, które języki dodatkowe są używane. Obiekty biznesowe z typem danych Konfiguracyjne dane podstawowe mogą również mieć języki pomocnicze bazy danych repozytorium w atrybutach NLS oprócz języków pomocniczych bazy danych OLTP.
Obiekt biznesowy NLS
Obiekty biznesowe NLS mają typ Dependent. Są one zarządzane automatycznie przez system. Obiekt biznesowy NLS odpowiada atrybutowi wielojęzycznemu. Nazwa składa się z nazwy obiektu biznesowego zawierającego atrybut wielojęzyczny i nazwy kolumny tabeli bazy danych atrybutu wielojęzycznego. Podczas generowania powiązanego obiektu biznesowego obiekt biznesowy NLS jest automatycznie tworzony w przestrzeni nazw NLS, która różni się od oryginalnej przestrzeni nazw tym, że ciąg znaków nls jest wstawiany po prefiksie rozwoju, np. com.cisag.nls. Usunięcie atrybutu wielojęzyczności lub obiektu biznesowego powoduje również usunięcie powiązanego obiektu biznesowego NLS.
Obiekt biznesowy NLS ma następujące atrybuty:
- Prefiks X_ + nazwa atrybutu Primary key powiązanego obiektu biznesowego — obiekt biznesowy NLS zawiera wszystkie atrybuty klucza głównego powiązanego obiektu biznesowego. Aby zapewnić unikalną nazwę atrybutu w obiekcie biznesowym NLS, nazwa atrybutu jest poprzedzona prefiksem X_. Klucz podstawowy jest wymagany tylko przez Persistence service dla zapytań i widoków OQL. Jeśli powiązany obiekt biznesowy ma typ jednostki biznesowej, relacja _entity zależności NLS jest zdefiniowana na tych atrybutach.
- validFrom — jeśli powiązany obiekt biznesowy jest zależny od czasu, obiekt biznesowy NLS zawiera również atrybut validFrom
- objectReference — ten atrybut zawiera odniesienie do obiektu powiązanego obiektu biznesowego. W przypadku dostępu do Persistence service, za pośrednictwem kluczy Persistence service (np. getObject()) jądro systemu operacyjnego ustanawia połączenie z obiektu biznesowego do obiektu biznesowego NLS za pośrednictwem referencji obiektu biznesowego.
- language — ten atrybut zawiera język, w którym dostępne jest tłumaczenie
- value — ten atrybut zawiera tłumaczenie
- Prefiks X_ + nazwa atrybutu Primary key powiązanego obiektu biznesowego jednostki — jeśli powiązany obiekt biznesowy ma typ Dependent, dołączane są również atrybuty Primary key powiązanej jednostki biznesowego. W tym przypadku relacja _entity do jednostki biznesowej jest zdefiniowana na podstawie tych atrybutów.
Każdy obiekt NLS posiada klucz podstawowy i drugorzędny klucz unikalny. Klucz podstawowy jest tworzony z atrybutów objectReference, language i validFrom (tylko z zależnością od czasu).
Klucz drugorzędny jest tworzony z atrybutów klucza głównego language obiektu biznesowego oraz, w przypadku zależności od czasu, z atrybutu validFrom.
Zmiana informacji/usunięcie techniczne
Jeśli opcja Zapisuj użytkownika i czas została aktywowana dla obiektu biznesowego, złożony atrybut UpdateInformation jest dodawany do obiektu biznesowego, który odnotowuje czas i użytkownika, który utworzył, ostatnio zmienił lub profesjonalnie usunął instancję. Specjalistyczny znacznik usuwania nie jest oceniany przez Persistence service; jest zarezerwowany dla aplikacji.
Metoda is_updateInfoRequired() klasy obiektu biznesowego może być użyta do zapytania, czy informacje o aktualizacji powinny być przechowywane dla obiektu biznesowego. Poniższe metody są generowane tylko dla obiektów biznesowych z aktywnym logowaniem:
- Metoda getUpdateInfo() zwraca niemodyfikowalną instancję części UpdateInformation, z której dane mogą być odpytywane za pomocą odpowiednich metod ..()
- Metoda getUpdateInfoMutable() zwraca modyfikowalną instancję części UpdateInformation, z której dane mogą być odpytywane za pomocą odpowiednich metod ..() lub zmieniane za pomocą metod set…()
- Modyfikowalna instancja części może zostać przekazana do metody setUpdateInfo() w celu zapisania w instancji obiektu biznesowego
Metoda set_deleted() służy do zmiany funkcjonalnego znacznika usuwania. Znacznik usuwania można sprawdzić za pomocą metody is_deleted(). Te dwie metody są również zaimplementowane dla klas obiektów biznesowych, których obiekty biznesowe nie mają informacji o aktualizacji. W tym przypadku mogą one być używane tylko dla instancji przejściowych.
Trwałe i przejściowe instancje obiektu biznesowego
Instancja obiektu biznesowego ma dwa stany w odniesieniu do bazy danych i przynależności do transakcji. Stany te można sprawdzić za pomocą metod is_persistent(), is_newObject() i is_transient().
Metoda is_persistent() służy do określenia, czy instancja obiektu biznesowego jest przechowywana w bazie danych. Jeśli wyświetlone zostanie true, instancja istnieje w bazie danych; jeśli jednak wyświetlone zostanie false, wówczas ona nie istnieje.
Metoda is transient() może być użyta do określenia, czy instancja obiektu biznesowego ma kontekst transakcji, tj. czy instancja jest przechowywana w pamięci podręcznej transakcji bieżącej transakcji, czy nie. Jeśli wyświetlona zostanie false, wówczas instancja obiektu biznesowego ma kontekst transakcji i jest ważna tylko w bieżącej transakcji. Jeśli wyświetlone zostanie true, wówczas instancja nie jest powiązana z transakcją.
W przypadku nowych obiektów, które zostały zarejestrowane do zapisu za pomocą funkcji putObject(), ale nie zostały jeszcze zapisane w bazie danych (transakcja Top Level nie została jeszcze zatwierdzona), metoda is_persistent() wyświetla wartość false. To, czy obiekt został już zarejestrowany do zapisania, można określić za pomocą metody is_newObject(). Metoda ta wyświetla false, jeśli obiekt nie jest trwały ani nie został zarejestrowany za pomocą putObject().
Podczas pracy z obiektami biznesowymi należy przestrzegać tych znaczników, aby tworzyć aplikacje zgodne z Comarch ERP Enterprise. Nietrwała instancja obiektu biznesowego, która została otwarta za pośrednictwem Persistence service, jest zawsze powiązana z bieżącą transakcją i jest nieważna po zakończeniu transakcji. Jeśli instancja obiektu biznesowego zostanie otwarta w podtransakcji, instancja ta może być używana tylko tak długo, jak długo otwarta jest podtransakcja. Dalsze korzystanie z instancji poza transakcją może prowadzić do błędów programu i dlatego jest niedozwolone.
Stany instancji obiektu biznesowego są zatem określane w następujący sposób:
- Instancja, która została odczytana przy użyciu metody getObject() w trybie dostępu READ, READ_UPDATE lub READ_WRITE (instancja istnieje w bazie danych) jest trwała i nieprzechodnia. Instancja, która została odczytana przy użyciu metody getObject() w trybie dostępu READ_WRITE (instancja nie istnieje w bazie danych) nie jest trwała i nie jest przejściowa. Jeśli instancja nie została jeszcze zarejestrowana w pamięci podręcznej transakcji, znacznik is_newObject() ma wartość true.
- Kopię przejściową można utworzyć za pomocą metody getTransientCopy(). Znacznik trwałości jest przenoszona do nowo utworzonej kopii przejściowej.
- Instancja utworzona przy użyciu metody newTransientInstance() nie jest trwała ani przejściowa
- Wartości atrybutów mogą być kopiowane między instancjami przejściowymi i nieprzechodnimi za pomocą metody copyTo()
- Metoda getObject() jest reprezentatywna dla metod getObjectArray() i getObjectIterator(), które wewnętrznie odwołują się do metody getObject()
Metoda getTransientCopy()
Jeśli instancja obiektu biznesowego została otwarta przez bazę danych za pomocą Manager obiektów, nie jest ona przejściowa i jest powiązana z transakcją ładowania. Aby użyć instancji między transakcjami, należy utworzyć nową przejściową kopię za pomocą metody getTransientCopy() klasy obiektu biznesowego. Oprócz wartości atrybutów kopiowana jest również znacznik persistent, a znacznik transient ustawiany jest na true. Utworzona przejściowa instancja obiektu biznesowego nie należy do żadnej transakcji i może być używana między transakcjami. Ta metoda jest bardzo przydatna, jeśli użytkownik chciałby zapamiętać zawartość instancji obiektu biznesowego po zakończeniu transakcji, np. do wyświetlania GUI.
Metoda newTransientInstance()
Metoda newTransientInstance() klasy obiektu biznesowego tworzy pustą, przejściową, nietrwałą instancję obiektu biznesowego (is_persistent() wyświetla false, is_transient() wyświetls true).
Metoda copyTo()
Metoda copyTo() klasy obiektu biznesowego może być używana do kopiowania wartości atrybutów instancji do innej instancji tego samego obiektu biznesowego. Źródłem lub celem mogą być trwałe lub przejściowe instancje. W każdym przypadku copyTo() zawsze przenosi wartości atrybutów i klucz biznesowy źródła do celu. Specjalne traktowanie jest stosowane w następujących przypadkach:
- Jeśli obiekt docelowy jest instancją przejściową, znacznik trwałości i klucz podstawowy są również kopiowane ze źródła
- Jeśli obiekt docelowy jest instancją nietrwałą, kopiowany jest klucz główny źródła
- Jeśli obiekt docelowy jest przejściowy, a informacje o aktualizacji są wymagane dla klasy obiektu biznesowego, cała informacja o aktualizacji jest kopiowana ze źródła. Funkcjonalna znacznika usuwania źródła (znacznik usuwania) jest zawsze kopiowana do celu.
- Jeśli cel jest przejściowy i zależny od czasu, kopiowane są atrybuty validFrom i validUntil źródła
Metoda set_persistent()
Znacznik persistent może zostać zmieniona dla obiektów przejściowych za pomocą metody set_persistent(); dla obiektów nieprzechodnich metoda ta prowadzi do błędu wykonania.
Specjalne metody klasy obiektów biznesowych
Wygenerowana klasa obiektów biznesowych posiada specjalne metody dostępu do danych:
| Nazwa metody | Funkcja |
| retrieve_instances() | Ta metoda zapewnia iterator obiektów, który może być używany do iteracji po wszystkich instancjach obiektu biznesowego. |
| get_type() | Ta metoda zwraca stałą typu obiektu biznesowego. |
| get_contentLanguage() | Ta metoda zwraca język treści, w którym została otwarta instancja obiektu biznesowego. |
| retrieve_entity() | Ta metoda jest implementowana dla klasy obiektu biznesowego obiektu biznesowego typu Dependent. Zwraca ona instancję obiektu biznesowego jednostki biznesowej, do której należy instancja zależna. |
| retrieve_dependents() | Metoda ta jest zaimplementowana w klasie obiektu biznesowego typu Jednostka biznesowa. Zwraca ona iterator obiektu, który może być użyty do iteracji po wszystkich instancjach powiązanych zależności. |
Part
Part są używane do realizacji złożonych atrybutów obiektów biznesowych. Definiują one strukturę danych, która podsumowuje grupę atrybutów pod znaczącą nazwą. Złożone atrybuty nie mają własnego klucza, ale są częścią obiektu biznesowego, stąd nazwa Part.
Part umożliwiają ponowne wykorzystanie struktur danych, które zostały raz zamodelowane dla różnych obiektów biznesowych. Część nie ma własnej tabeli w bazie danych. Atrybuty części są zapisywane w tabeli obiektu biznesowego. Relacje z innymi obiektami biznesowymi mogą być również określone w definicji części, chociaż część nigdy nie może być celem relacji. Generowanych jest kilka klas Java, które są używane do uzyskiwania dostępu do instancji części w aplikacji:
- Atrybuty części mogą być dostępne tylko do odczytu poprzez klasę Imutable. Posiada ona tylko odpowiednie metody ..() do odczytu wartości atrybutów. Odpowiednia metoda retrieve…() jest generowana dla relacji.
- Klasa mutable może być używana do odczytu i zapisu atrybutów części, a także posiada niezbędne metody ..()
- Klasa mappera jest generowana, jeśli relacje są przypisane do części, która jest używana wewnętrznie przez Persistence service w celu uzyskania dostępu do obiektu biznesowego relacji
Widok OQL
Obiekt biznesowy z dodatkowymi danymi z innych obiektów biznesowych, do których istnieją odniesienia, jest często używany wielokrotnie w aplikacjach. Zamiast otwierać obiekt biznesowy, otwierać powiązane obiekty biznesowe za pośrednictwem relacji i wybierać interesujące atrybuty lub zawsze używać tego samego polecenia OQL, łatwiej jest utworzyć widok żądanych informacji. Widok ten może być używany w aplikacji jak normalny obiekt biznesowy, z zastrzeżeniem, że dane mogą być tylko odczytywane. Zmiany można wprowadzać w centralnej lokalizacji. Widok danych jest określony w postaci instrukcji OQL SELECT. Nie ma ograniczeń co do stosowania złączeń i klauzul WHERE, więc możliwe są złożone zapytania.
System (narzędzie crtbo) generuje trzy klasy Java z definicji widoku OQL: klasę główną, klasę stanu i klasę mappera. Klasy Java są zapisywane w pakiecie Java odpowiadającym przestrzeni nazw pod nazwą widoku OQL (ewentualnie z przyrostkiem _State lub _Mapper). Deweloper używa klasy głównej w aplikacji, aby uzyskać dostęp do instancji widoku OQL, podczas gdy klasy stanu i mappera są wymagane przez usługę trwałości w celu realizacji dostępu do bazy danych. Klasa główna zawiera metody get…() lub is…() (dla Boolean) do uzyskiwania dostępu do atrybutów widoku oraz metodę buildPrimaryKey() do otwierania instancji za pomocą klucza głównego. W aplikacji widok zachowuje się podobnie do obiektu biznesowego, ale możliwy jest tylko dostęp do odczytu.
Powiązany widok bazy danych jest tworzony w bazie danych, przy czym instrukcja OQL jest konwertowana przez system na instrukcję SQL, której widok bazy danych używa do utworzenia wirtualnej tabeli bazy danych.
Systemy DBMS nie zawsze mogą w pełni zoptymalizować instrukcje bazy danych zawierające widoki. Szczególnie w wyszukiwaniach, raportach i listach, korzystanie z widoków OQL pogarsza czasy odpowiedzi bazy danych.
W związku z tym nie zaleca się używania widoków OQL do tych celów; zamiast tego należy używać OQL, wyszukiwań OQL lub wirtualnych tabel i funkcji do raportów.
Struktura Persistence service
Persistence service składa się z kilku komponentów. Niektóre z tych komponentów, takie jak Współdzielona pamięć podręczna (Shared Cache) lub Pamięć podręcznej transakcji (Transaction Cache), mogą być dostępne dla dewelopera tylko za pośrednictwem interfejsów Manager obiektów lub Managerze transakcji. Zadania wszystkich głównych komponentów Persistence service zostały opisane poniżej.
Współdzielona pamięć podręczna
Współdzielona pamięć podręczna służy do tymczasowego przechowywania otwartych instancji obiektów biznesowych w pamięci głównej w celu zminimalizowania liczby dostępów do bazy danych. Przyczynia się zatem znacząco do wydajności całego systemu. Dostęp do instancji obiektu biznesowego we współdzielonej pamięci podręcznej jest znacznie szybszy niż dostęp do niego w bazie danych. Współdzielona pamięć podręczna działa zgodnie ze strategią LRU (least recently used) i zawiera instancje obiektów biznesowych ostatnio używane przez serwer aplikacji. Jeśli aplikacja chce odczytać obiekt biznesowy z bazy danych, najpierw sprawdza, czy obiekt biznesowy jest dostępny we współdzielonej pamięci podręcznej, w przeciwnym razie jest odczytywany z bazy danych.
Współdzielona pamięć podręczna istnieje dokładnie raz w każdym serwerze aplikacji, który wykonuje dostęp do bazy danych (singleton). W systemie z więcej niż jednym serwerem aplikacji wysiłek komunikacyjny między serwerami aplikacji byłby bardzo wysoki, gdyby obiekty we wszystkich współdzielonych pamięciach podręcznych miały przez cały czas taki sam stan jak w bazie danych. Wystarczy, że obiekty we współdzielonej pamięci podręcznej będą aktualizowane w określonych odstępach czasu (30 sekund).
Pamięć główna serwera aplikacji jest ograniczona, więc nie wszystkie obiekty mogą być przechowywane we współdzielonej pamięci podręcznej w tym samym czasie. Rozmiar współdzielonej pamięci podręcznej jest ustawiany podczas konfiguracji serwera aplikacji. Współdzielona pamięć podręczna może być podzielona na różne partycje o ograniczonym rozmiarze. Obiekty biznesowe są przechowywane w jednej z partycji w zależności od typu danych i bazy danych.
Pamięć podręczna transakcji
Pamięć podręczna transakcji służy do tworzenia lokalnego kontekstu transakcji. Każda transakcja Top Level ma własną pamięć podręczną transakcji. Dopóki transakcja nie zostanie potwierdzona przez commit, instancje obiektów biznesowych, które są zarejestrowane do modyfikacji w ramach tej transakcji, są przechowywane tylko w ich pamięci podręcznej transakcji. Managerze obiektów najpierw wyszukuje obiekty do otwarcia w odpowiedniej pamięci podręcznej transakcji. Zmiany w transakcji są widoczne tylko dla dostępu w ramach tej transakcji. Zmiana staje się widoczna dla wszystkich innych transakcji dopiero po przeniesieniu danych z pamięci podręcznej transakcji do współdzielonej pamięci podręcznej i bazy danych. Dzieje się tak, gdy zmieniająca się transakcja jest finalizowana przez commit.
Manager transakcji
Manager transakcji zarządza i kontroluje transakcje. Może rozpocząć nową transakcję Top Level lub transakcję podrzędną oraz potwierdzić (zatwierdzić) lub anulować (wycofać) transakcję.
Obiekty stanu obiektów biznesowych i pamięci podręczne transakcji są używane do izolowania lokalnych kontekstów transakcji.
Transakcje
Transakcja jest nawiasem dla operacji zapisu funkcjonalnej bazy danych. Składa się z jednego lub więcej działań na bazie danych, z których wszystkie lub żadne nie są wykonywane (atomowość). Są one jawnie otwierane, zamykane lub anulowane. Zmiany są widoczne dla świata zewnętrznego dopiero po pomyślnym zakończeniu transakcji. Anulowanie przywraca wszystkie poprzednie zmiany. Transakcja ERP odpowiada rozumieniu transakcji w systemach relacyjnych baz danych i dlatego spełnia właściwości ACID.
Persistence service obsługuje zamknięte, zagnieżdżone transakcje. Oznacza to, że transakcja może zasadniczo mieć dowolną liczbę podtransakcji o dowolnej głębokości zagnieżdżenia. Transakcje zagnieżdżone lub podrzędne to transakcje, które są rozpoczynane i kończone w ramach istniejącej transakcji, transakcji nadrzędnej. Podtransakcje są tutaj nieistotne, tzn. anulowanie podtransakcji nie wymusza anulowania transakcji nadrzędnej. Zmiany w ramach podtransakcji będą widoczne tylko w odpowiedniej transakcji nadrzędnej po pomyślnym zatwierdzeniu i są zapisywane w bazie danych, a zatem stają się trwałe, gdy transakcja Top Level zostanie zatwierdzona.
Z reguły komponenty oprogramowania są projektowane w celu zapewnienia określonej, ukończonej usługi. Często musi się to odbywać w sposób bezpieczny dla transakcji. Komponent może dostarczyć usługę w całości lub nie. Komponent użyje transakcji do wykonania swoich operacji w ramach tej transakcji. Zagnieżdżone wywołania komponentów automatycznie skutkują zagnieżdżonymi transakcjami.
Transakcja Top Level i wszystkie jej podtransakcje mogą mieć dostęp do odczytu i zapisu tylko do jednej bazy danych. Transakcje między bazami danych nie są możliwe.
Manager transakcji zawsze ma dokładnie jedną bieżącą transakcję w danym momencie. Chociaż w sesji można otworzyć kilka transakcji Top Level, tylko ostatnia z nich jest bieżącą transakcją Top Level. Jeśli transakcja nie została jawnie uruchomiona, transakcja fikcyjna jest niejawnie otwierana w domyślnej bazie danych OLTP. W tym przypadku możliwy jest tylko dostęp do bazy danych tylko do odczytu; nie może mieć żadnych podtransakcji i nie może zapisywać do baz danych.
Jeśli instancje obiektów biznesowych są zmieniane w ramach transakcji, wymagane są dla nich blokady. Blokady te są powiązane z odpowiednią transakcją Top Level i są zwalniane dopiero po zakończeniu transakcji Top Level. Oznacza to, że blokady żądane w podtransakcjach są również utrzymywane do momentu zakończenia transakcji Top Level, niezależnie od tego, czy podtransakcja została potwierdzona, czy anulowana.
Zarządzanie transakcjami
Instancja Managera transakcji może być wyszukiwana w aplikacji w środowisku bieżącej sesji. Manager transakcji oferuje następujące funkcje dla transakcji:
- Otwarcie nowej transakcji Top Level (beginNew)
- Otwarcie nowej transakcji tylko do odczytu (beginReadOnly)
- Otwieranie transakcji (begin)
- Potwierdzenie transakcji (commit)
- Anulowanie transakcji (rollback)
- Utworzenie nowego obiektu transakcji Top Level (createNew)
- Utworzenie nowego obiektu transakcji tylko do odczytu (createReadOnly)
- Utworzenie obiektu transakcji (create).
Obiekt transakcji utworzony za pomocą funkcji create reprezentuje transakcję. Obiekt transakcji posiada następujące metody:
- Potwierdzenie transakcji (commit)
- Potwierdzenie transakcji i otwarcie nowej transakcji (commitBlock)
- Potwierdzenie transakcji, jeśli maksymalny rozmiar transakcji został przekroczony i otwórz nową transakcję (commitIfSizeLimitExceeded)
- Sprawdzenie, czy transakcja jest nadal otwarta (isOpen)
- Zamknięcie transakcji (close)
Transakcje można otwierać za pomocą polecenia begin… lub create…. Otwarcie transakcji za pomocą create… tworzy obiekt transakcji, który implementuje interfejs AutoCloseable. Podczas tworzenia nowych aplikacji i funkcji należy używać create… zamiast begin…. Wiele starszych aplikacji używa begin….
Alias bazy danych
Aliasy baz danych są zdefiniowane jako stałe w Managerze transakcji. Można ich użyć do otwarcia transakcji dla odpowiedniej bazy danych.
| Nazwa aliasu | Znaczenie |
| OLTP | Ten alias oznacza bieżącą bazę danych OLTP sesji. |
| OLAP | Ten alias oznacza bieżącą bazę danych OLAP sesji. |
| CONFIGURATION | Ten alias oznacza bieżącą bazę danych konfiguracji sesji. |
| REPOSITORY | Ten alias oznacza bazę danych repozytorium. |
| Konkretna nazwa bazy danych | Można również określić nazwę bazy danych podłączonej do SAS, ale jest to przydatne tylko w wyjątkowych przypadkach, ponieważ w rezultacie kod programu nie może zostać przeniesiony do innego systemu ERP. |
Tworzenie transakcji Top Level
Metoda beginNew() lub createNew() służy do tworzenia nowej transakcji Top Level dla określonej bazy danych. Można przenieść alias bazy danych lub identyfikator GUID bazy danych. Jeśli żadna baza danych nie zostanie przeniesiona, wówczas używana jest bieżąca baza danych OLTP sesji.
Tworzenie transakcji tylko do odczytu
Metoda beginReadOnly() lub createReadOnly() tworzy nową transakcję tylko do odczytu dla określonej bazy danych. Możliwe jest przeniesienie aliasu bazy danych lub identyfikatora GUID bazy danych. Jeśli żadna baza danych nie zostanie przekazana, używana jest bieżąca baza danych OLTP sesji. Otwarcie transakcji tylko do odczytu powoduje mniejsze obciążenie systemu niż otwarcie normalnej transakcji Top Level. Korzystanie z transakcji tylko do odczytu może być opłacalne, zwłaszcza jeśli duża liczba transakcji jest otwierana w krótkim czasie.
Następujące działania są zabronione w ramach transakcji tylko do odczytu:
- Modyfikowanie obiektu biznesowego
- Żądanie blokad obiektów biznesowych
- Otwieranie podtransakcji
- Zakończenie transakcji za pomocą funkcji commit()
Tworzenie podtransakcji
Wywołanie metody begin() lub create() bez parametrów tworzy nową transakcję. Jeśli żadna baza danych nie zostanie przesłana, wówczas bieżąca baza danych OLTP sesji jest używana w taki sam sposób, jak w przypadku beginNew().
Jeśli metoda begin() zostanie wywołana na poziomie transakcji fikcyjnej lub w ramach transakcji Top Level, a używana baza danych nie jest taka sama jak baza danych transakcji nadrzędnej, wystąpi błąd wykonania. Jeśli bazy danych są zgodne, otwierana jest nowa transakcja Top Level, jeśli transakcja nadrzędna jest transakcją fikcyjną, w przeciwnym razie otwierana jest transakcja podrzędna.
Potwierdzenie transakcji
Bieżąca transakcja jest potwierdzana przy użyciu metody commit() na managerze transakcji lub obiekcie transakcji. Jeśli zaangażowana jest transakcja Top Level, zarejestrowane obiekty są zapisywane w bazie danych lub usuwane. W przypadku transakcji podrzędnej zarejestrowane obiekty nie są jeszcze zapisywane w bazie danych, ale są dziedziczone przez transakcję nadrzędną, tj. wstawiane do jej lokalnego kontekstu transakcji, a zatem są widoczne dla tej transakcji. Dopiero gdy powiązana transakcja Top Level zostanie potwierdzona za pomocą funkcji commit(), obiekty te stają się trwałe w bazie danych.
Tylko wtedy, gdy transakcja Top Level jest zatwierdzona, numery są losowane z automatycznym przypisaniem numeru lub aktualizowane są informacje o aktualizacji zmienionych instancji obiektów biznesowych.
Jeśli zależna instancja zostanie zmieniona, czas zmiany i bieżący użytkownik są wprowadzane do informacji o aktualizacji instancji jednostki biznesowej. Jeśli sama zmieniona instancja ma informacje o aktualizacji, są one również aktualizowane.
Anulowanie transakcji
Bieżąca transakcja jest anulowana za pomocą metody rollback(). Oznacza to, że wszystkie zmiany, które zostały przekazane do Persistence service podczas tej transakcji lub jednej z jej podtransakcji, są odrzucane. Dotyczy to zarówno anulowanej transakcji Top Level, jak i podtransakcji.
Jeśli anulowana transakcja ma transakcję nadrzędną, jej kontekst lokalny transakcji pozostaje niezmieniony, tj. w tym samym stanie, w którym rozpoczęto transakcję podrzędną. Transakcja nadrzędna staje się bieżącą transakcją.
Jeśli transakcja Top Level zostanie anulowana, wówczas transakcja dummy staje się transakcją bieżącą.
Metoda close() na obiekcie transakcji anuluje otwartą transakcję w taki sam sposób jak rollback(). Jeśli transakcja została już potwierdzona przez commit(), wówczas close() musi być nadal wywoływane. W tym przypadku jednak close() nie ma wpływu na wynik transakcji.
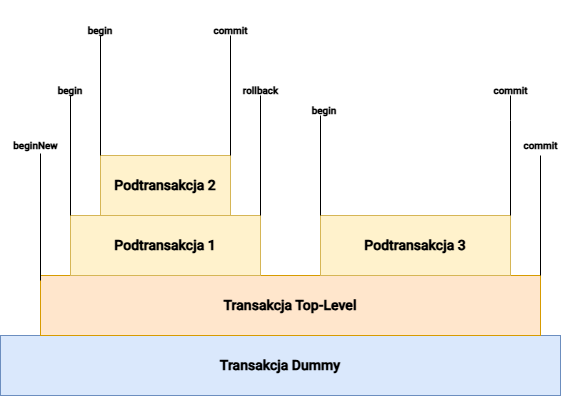
Przykład łączenia transakcji nadrzędnych i podrzędnych
Poniższa ilustracja przedstawia transakcję Top Level z trzema podtransakcjami. Zmiany w Podtransakcja 2 są przenoszone do pamięci podręcznej transakcji Podtrasakcja 1, ponieważ Podtransakcja 2 jest zakończona przez commit. Jednak zmiany w Podtransakcja 1 nie są przenoszone do transakcji Top Level, ponieważ Podtransakcja 1 jest anulowana za pomocą rollback. Oznacza to, że zmiany w Podtransakcja 2 są również odrzucane. Zmiany w Podtransakcja 3 są stosowane do transakcji Top Level za pomocą zatwierdzenia. Oznacza to, że gdy transakcja Top Level zostanie zatwierdzona, zmiany zostaną utrwalone bezpośrednio w transakcji Top Level, a zmiany w Podtransakcja 3 zostaną utrwalone w bazie danych.
Zależność transakcyjna obiektów biznesowych instancje
Instancje obiektów biznesowych utworzone przez Managera obiektów należą dokładnie do tej transakcji lub podtransakcji, w której zostały otwarte lub utworzone. Mogą być używane tylko w tej transakcji. Jeśli transakcja, w której zostały otwarte, zostanie zamknięta, instancja jest nieważna.
Obiekty niezależne od transakcji mogą być tworzone przy użyciu metody getTransientCopy(). Metoda ta tworzy kopię instancji obiektu biznesowego, która nie należy do żadnej transakcji i dlatego może być używana w różnych transakcjach. Wszystkie obiekty biznesowe mają tę metodę.
Metoda newTransientInstance() może być użyta do utworzenia pustej, niezależnej od transakcji instancji obiektu biznesowego.
Widoczność zmian w transakcjach zagnieżdżonych
Widoczność zmian w instancjach obiektów biznesowych (tj. właściwość izolacji transakcji) jest kontrolowana na trzech poziomach.
Bieżąca transakcja z podtransakcjami
Na poziomie bieżącej transakcji i jej podtransakcji zmiany atrybutów są znane tylko w odpowiedniej instancji obiektu biznesowego. Dopiero po putObject() stają się one widoczne dla bieżącej transakcji i dla wszystkich kolejnych podtransakcji, tj. kolejne getObject() zwraca zmienioną instancję obiektu biznesowego. Instancje zmienionego obiektu biznesowego, które zostały już otwarte, nadal mają starą wartość, dopóki nie zostaną ponownie odczytane za pomocą getObject().
Transakcja nadrzędna transakcji modyfikującej
Zmiany atrybutów są widoczne tylko w transakcji nadrzędnej zmieniającej się transakcji, jeśli instancja obiektu biznesowego została zapisana w zmieniającej się transakcji za pomocą putObject(), transakcja ta została pomyślnie zakończona za pomocą commit(), a instancja obiektu biznesowego została ponownie odczytana za pomocą getObject(). Dotyczy to również głębszych poziomów zagnieżdżenia.
Zmiana zawartości bazy danych
Zawartość bazy danych odzwierciedla zmiany (INSERT/UPDATE/DELETE) dopiero po pomyślnym zakończeniu transakcji Top Level za pomocą commit. Dopiero w tym momencie wszystkie zmiany w transakcji Top Level i jej pomyślnie zakończonych podtransakcjach są zapisywane w bazie danych. Są one wtedy widoczne globalnie. Ponowny odczyt jest konieczny, ponieważ instancje obiektów biznesowych odczytane przed zatwierdzeniem zmieniającej się transakcji nadal zawierają stare wartości. Instrukcje OQL zawsze działają na rzeczywistych trwałych danych, tj. zmiany wprowadzone w instancjach obiektów biznesowych w tej samej transakcji nie są jeszcze widoczne dla zapytań OQL.
Obsługa błędów dla transakcji
Należy upewnić się, że otwarta transakcja jest zawsze anulowana przez wycofanie lub zakończona zatwierdzeniem. Obsługa błędów zależy od tego, czy transakcja została otwarta za pomocą begin… czy create… .
Jeśli transakcja została otwarta za pomocą create… , obsługa błędów jest prosta, a deweloper nie może popełnić żadnych błędów. Najlepiej otwierać transakcje za pomocą create… , w szczególności ze względu na prostszą obsługę błędów.
Jeśli transakcja została otwarta za pomocą begin… , należy przestrzegać poniższych wzorców programowania. Podczas korzystania z funkcji begin… konieczne jest obsługiwanie wyjątków występujących w bloku transakcji. Ponadto należy unikać ewentualnego wystąpienia wyjątków w określonych punktach programu. W przypadku transakcji zagnieżdżonych należy zadbać o to, aby stos transakcji nie został pomieszany, np. jeśli transakcja wyższego poziomu zostanie również zamknięta z powodu nieostrożności.
Aby zwiększyć pewność, że rollback lub commit odnosi się do właściwej transakcji dla begin… , można użyć identyfikatora GUID transakcji. beginNew()/begin() zwraca identyfikator GUID bieżącej transakcji, który można przekazać jako parametr dla rollback() i commit(). Jeśli nie pasuje on do bieżącej transakcji dla commit(), zostanie zgłoszony wyjątek, a nieprawidłowa transakcja nie zostanie utrwalona.
W przypadku funkcji rollback() wyświetlane jest tylko ostrzeżenie, że identyfikatory GUID transakcji nie są zgodne. Każda transakcja Top Level ma swój własny identyfikator GUID transakcji, podczas gdy transakcje niższego poziomu dostarczają identyfikator GUID transakcji Top Level. Użycie identyfikatora GUID transakcji chroni przed niezamierzonym zamknięciem niewłaściwej transakcji Top Level; takie błędy są nadal możliwe w przypadku transakcji podrzędnych. W późniejszej wersji ten mechanizm ochrony można również rozszerzyć na podtransakcje, tak aby każda podtransakcja miała swój własny identyfikator GUID transakcji. W związku z tym identyfikator GUID transakcji powinien być również używany dla podtransakcji.
Transakcja odczytu z begin…
Transakcja odczytu z begin… musi zawsze odpowiadać następującemu szablonowi. Żaden wyjątek nie może zostać rzucony w miejscach oznaczonych /*xx*/. Oznacza to, że najlepiej byłoby, gdyby w tych miejscach nie było żadnego kodu lub tylko instrukcje, które nie mogą wywołać wyjątku. Transakcja tylko do odczytu powinna być zawsze resetowana za pomocą rollback(), ponieważ żadne zmiany nie są wprowadzane do bazy danych. Blok try-finally zapewnia, że rollback() jest zawsze wykonywany, niezależnie od tego, czy wyjątek wystąpi w bloku transakcji, czy nie.
Szablon dla transakcji odczytu:
byte[] transGuid= tm.begin...(..);
/*xx*/
try {
...
} finally {
/*xx*/
tm.rollback(transGuid);
...
}
Wyjątek w zaznaczonych punktach spowodowałby, że transakcja nie zostałaby wycofana przez rollback(). Transakcja byłaby otwarta i zostanie zamknięta dopiero przy następnym wystąpieniu commit() lub rollback() dla innej transakcji. Stos transakcji nie byłby już spójny, co spowodowałoby utratę danych.
W przypadku transakcji odczytu należy sprawdzić, czy możesz użyć funkcji beginReadOnly(), aby otworzyć transakcję tylko do odczytu.
Transakcja odczytu z create…
Transakcja odczytu z create… musi zawsze odpowiadać następującemu szablonowi. Wynik „create…” musi zostać przypisany do zmiennej w „try” w następujący sposób, w przeciwnym razie transakcja nie zostanie zamknięta.
Szablon dla transakcji odczytu:
try (CisTransaction txn=tm.create...(...)) {
...
}
Transakcja zapisu z begin…
Transakcja zapisu z begin… musi zawsze odpowiadać następującemu szablonowi. Żaden wyjątek nie może zostać rzucony w miejscach oznaczonych /*xx*/. Oznacza to, że w tych miejscach nie ma kodu lub są tylko instrukcje, które nie mogą wywołać wyjątku. Transakcja zapisu musi zostać anulowana za pomocą funkcji rollback() lub pomyślnie zakończona za pomocą funkcji commit(). Jeśli transakcja zostanie anulowana, wszystkie zmiany wprowadzone w transakcji lub w podtransakcjach zostaną odrzucone. Dostęp do odczytu i modyfikacji za pośrednictwem usługi trwałości jest dozwolony. Blok try-catch zapewnia, że transakcja zostanie jawnie anulowana za pomocą funkcji rollback() w przypadku wystąpienia wyjątku w bloku transakcji. W przeciwnym razie transakcja zostanie pomyślnie zakończona za pomocą funkcji commit().
Szablon dla transakcji zapisu:
byte[] transGuid= tm.begin...(..);
/*xx*1/
try {
...
tm.commit(transGuid);
/*xx*2/
} catch (RuntimeException ex) {
/*xx*3/
tm.rollback(transGuid);
...
}
Wyjątek w pozycji /*xx*1/ spowodowałby, że otwarta transakcja nie zostałaby zamknięta za pomocą instrukcji należącej do bloku. Wyjątek w pozycji /*xx*2/ spowodowałby wykonanie rollback() w bloku catch, co anulowałoby transakcję wyższego poziomu. Bieżąca transakcja została już zamknięta przez commit(). Wyjątek w pozycji /*xx*3/ oznacza, że funkcja rollback() nie zostanie wykonana, a transakcja pozostanie otwarta.
Transakcja zapisu z create…
Transakcja zapisu, która została otwarta za pomocą create… musi zawsze odpowiadać następującemu szablonowi. Manager obiektów nie może być dostępny w punktach oznaczonych /*xx*/. W związku z tym, po commit() nie powinno być żadnego kodu. Wynik create… musi zostać przypisany do zmiennej w try w następujący sposób, w przeciwnym razie transakcja nie zostanie zamknięta.
Szablon dla transakcji zapisu:
try (CisTransaction txn=tm.create...(..)) {
...
txn.commit();
/*xx*/
}
Transakcja otwarta za pomocą create… jest już zamknięta w pozycji /*xx*/. Manager obiektów nie używa transakcji otwartej w try w pozycji /*xx*/.
Blokowa transakcja zapisu z create…
Transakcja powinna zawsze mieć ograniczony rozmiar. Jeśli ma zostać zapisana nieograniczona ilość danych, dane te powinny być zapisywane w blokach o ograniczonym rozmiarze. Rozmiar bloku może być określony jako stała (np. 100 rekordów danych na transakcję) lub obliczany dynamicznie przez managera transakcji. Manager obiektów nie może być dostępny w punktach oznaczonych /*xx*/. Dlatego najlepiej jest, jeśli po zatwierdzeniu nie ma żadnego kodu.
Szablon dla transakcji ze stałymi rozmiarami bloków z funkcją commitBlock():
try (CisTransaction txn=tm.create...(..)) {
int i=0;
while (...) {
...
om.putObject(o);
if (++i%100=0) {
txn.commitBlock();
}
}
txn.commit();
/*xx*/
}
Szablon dla transakcji z dynamicznym rozmiarem bloku z funkcją commitIfSizeLimitExceeded():
try (CisTransaction txn=tm.create...(..)) {
int i=0;
while (...) {
...
om.putObject(o);
txn.commitIfSizeLimitExceeded();
}
txn.commit();
/*xx*/
}
Transakcja otwarta za pomocą create… jest już zamknięta w pozycji /*xx*/. Manager obiektów nie używa transakcji otwartej w try w pozycji /*xx*/.
Inne metody
Metoda GetComparator()
Metoda getComparator() zwraca komparator do porównywania ciągów znaków. Używa tego samego sortowania, co określona baza danych. Pozwala to na replikację sortowania bazy danych podczas sortowania ciągów w pamięci głównej. Metodzie można przekazać alias bazy danych lub identyfikator GUID bazy danych, dla której ma zostać dostarczony pasujący komparator. Jeśli nie określono bazy danych, zwracany jest komparator dla bieżącej bazy danych OLTP sesji.
Tabela sortowania znaków musi zostać określona, aby komparator mógł replikować sortowanie bazy danych. Do tego celu służy narzędzie Sprawdź collation (chkcol).
Metoda buildDatabaseLock()
Metoda buildDatabaseLock() powoduje, że łańcuch blokady przekazywany jako parametr jest specyficzny dla bazy danych poprzez dołączenie identyfikatora GUID określonej bazy danych. Dzięki temu ustawiana blokada logiczna jest ważna tylko dla określonej bazy danych. Jest to konieczne, jeśli np. instancja obiektu biznesowego, która istnieje w kilku bazach danych OLTP, ma zostać zmieniona, a klucz obiektu biznesowego jest używany jako ciąg blokady dla blokady logicznej. Zostanie on następnie zablokowany we wszystkich bazach danych, chociaż blokada jest konieczna tylko na poziomie bazy danych. Do metody można przekazać alias bazy danych lub identyfikator GUID bazy danych. Jeśli nie określono bazy danych, używana jest bieżąca baza danych OLTP sesji.
Wsparcie dla masowego przetwarzania danych
Transakcje zapisu w Persistence service mają ograniczony rozmiar. Maksymalny rozmiar transakcji zależy od pamięci serwera aplikacji i ograniczeń systemu zarządzania bazą danych. W związku z tym, nie ma sensu kodowanie rozmiarów transakcji w aplikacji, ponieważ rozmiary transakcji zależą od parametrów technicznych i nie są wyspecjalizowane.
Użytkownik może zastosować commitBlock() lub commitIfSizeLimitExceeded(), aby zagwarantować ograniczone rozmiary transakcji. Więcej informacji można znaleźć w rozdziale Blokowa transakcja zapisu z create… .
Manager obiektów
Maanager obiektów Persistence service oferuje aplikacji dwie opcje dostępu do bazy danych. Po pierwsze, zapewnia metody odczytu, tworzenia, zmiany i usuwania na poziomie obiektu biznesowego, a po drugie, aplikacja może korzystać z Persistence service w celu wykonania dowolnej instrukcji OQL systemu ERP w celu otwarcia lub zmiany danych. Manager obiektów mapuje obiektowy model danych używany w aplikacji na relacyjny model bazy danych. Wymagane zapytania SQL są generowane na podstawie instrukcji OQL. Wszystko to odbywa się w sposób przejrzysty dla aplikacji. Wszystkie dostępy do bazy danych w aplikacjach odbywają się w ramach transakcji zarządzanych przez Managera transakcji.
Instancję managera obiektów ważną dla bieżącej sesji można sprawdzić w środowisku sesji za pomocą metody getObjectManager().
Manager obiektów jest interfejsem dla aplikacji, za pomocą którego:
- Obiekty biznesowe mogą być otwierane lub tworzone
(metoda getObject() , getObjectArray()), - Iteratory obiektów biznesowych mogą być generowane do odczytu
(metoda getObjectIterator()), - można wykonać dowolne odczytane instrukcje OQL systemu ERP (SELECT)
(metoda getResultSet()), - Obiekty biznesowe mogą być rejestrowane w celu zapisania w bieżącej transakcji
(metoda putObject()), - Obiekty biznesowe mogą być zarejestrowane do usunięcia w bieżącej transakcji
(metoda deleteObject()), - można wykonywać dowolne instrukcje OQL systemu ERP (UPDATE/INSERT/ DELETE)
(metoda getUpdateStatement()).
Wszystkie używane obiekty biznesowe są otwierane, tworzone, zapisywane lub usuwane za pomocą Managera obiektów. Można ustawić różne tryby dostępu i określić język treści dla atrybutów wielojęzycznych.
Język treści (Content language)
Język treści służy do kontrolowania języka, w którym wielojęzyczne atrybuty instancji obiektu biznesowego powinny być dostępne, tj. wartość atrybutu wielojęzycznego ma zastosowanie tylko do określonego języka treści. Jeśli nie określono języka treści, wówczas używany jest aktualnie ustawiony język treści użytkownika. Określony język treści musi istnieć w bazie danych zgodnie z jej ustawieniami konfiguracyjnymi.
Język treści, w którym została otwarta instancja obiektu biznesowego, można sprawdzić za pomocą metody get_contentLanguage() klasy obiektu biznesowego.
Metoda GetObject()
Instancję obiektu biznesowego można otworzyć za pomocą funkcji getObject(). Uwzględniany jest lokalny kontekst transakcji. Odczytywana jest zawsze cała instancja ze wszystkimi atrybutami. Klucz Persistence service wygenerowany z klucza obiektu biznesowego i opcjonalnie tryb dostępu są oczekiwane jako parametry. Klucz Persistence service wymagany do identyfikacji otwieranej instancji jest generowany przy użyciu odpowiedniej metody statycznej klasy obiektu biznesowego. Przykładowo, metoda buildPrimaryKey() służy do generowania klucza Persistence service z klucza podstawowego obiektu biznesowego.
Metoda ta ma następujące sygnatury:
extends CisObject getObject(byte[] key); extends CisObject getObject(byte[] key, int flags); extends CisObject getObject(byte[] key, int flags, String language);
Tryb działania
Manager obiektów najpierw próbuje odczytać instancję obiektu biznesowego z pamięci podręcznej transakcji bieżącej transakcji. Jeśli nie zostanie tam znaleziony, przeszukiwana jest współdzielona pamięć podręczna. Jeśli i tam nie zostanie znaleziony, uzyskiwany jest dostęp do bazy danych. Wykonywane jest następujące zapytanie SQL, które wyświetla jeden wiersz lub brak wierszy jako wynik:
SELECT * FROM table WHERE keyAttributes='?'
Manager obiektów tworzy instancję klasy obiektu biznesowego, mapuje wynik zapytania na atrybuty i zwraca instancję do aplikacji jako CisObject. Tam musi nastąpić rzutowanie typu z ogólnej klasy CisObject do konkretnej klasy odczytanego obiektu biznesowego. Jeśli baza danych nie zwróciła żadnego wyniku, zwracana jest wartość null.
W zależności od przekazanych flag (np. READ_WRITE, INSERT, …), nowe instancje obiektów biznesowych mogą być również tworzone za pomocą funkcji getObject(). Wartości atrybutów są przenoszone z przekazanego klucza do instancji. Jeśli instancja jest tworzona z kluczem biznesowym lub kluczem drugorzędnym, atrybuty GUID z klucza podstawowego są inicjowane nowym identyfikatorem GUID.
Poniższy fragment kodu źródłowego otwiera instancję obiektu biznesowego Item poprzez klucz
podstawowy:byte[] guid = ...; byte[] primKey = Item.buildPrimaryKey( guid ); Item item = om.getObject(primKey, CisObjectManager.READ);
Następny fragment kodu źródłowego otwiera instancję obiektu biznesowego Item poprzez klucz funkcjonalny number:
String number = ...; byte[] busKey = Item.buildByNumberKey( number ); Item item = om.getObject(busKey, CisObjectManager.READ);
Zależność od czasu
Obiekty zależne od czasu są zawsze otwierane z aktualnie aktywną wersją. Jeśli ma zostać otwarta wersja inna niż aktywna, musi zostać przekazany klucz zależny od czasu, który jest generowany przy użyciu metody buildTimeDependentKey(). Atrybuty klucza głównego i atrybut validFrom są przekazywane jako parametry:
byte[] guid = ...; Date validFrom = ...; byte[] primKey = Item.buildTimeDependentKey(guid, validFrom); Item item = om.getObject(primKey, CisObjectManager.READ);
Aby otworzyć wersję instancji obiektu biznesowego, która jest ważna w dowolnym momencie, należy wykonać odpowiednie zapytanie OQL za pomocą metody getObjectIterator(). Nie jest to możliwe przy użyciu metody getObject().
Jeśli zależna od czasu instancja obiektu biznesowego jest tworzona przy użyciu funkcji getObject(), atrybut validFrom jest ustawiany na stałą MIN_DATE, a atrybut validUntil jest ustawiany na MAX_DATE.
Obsługa NLS
Każdy wielojęzyczny atrybut instancji obiektu biznesowego jest wypełniany wartością określonego języka treści, jeśli jest dostępny. Jeśli język treści odpowiada głównemu językowi bazy danych, wartość jest odczytywana bezpośrednio z tabeli odpowiadającej obiektowi biznesowemu. Jeśli język treści jest drugorzędnym językiem bazy danych, wartość jest odczytywana z tabeli odpowiadającej obiektowi NLS. Jeśli nie ma tłumaczenia dla języka, zwracana jest wartość dla języka głównego.
Jeśli null zostanie przekazane jako język dla getObject, instancja zostanie otwarta w języku bazy danych.
Aby otworzyć obiekt z dodatkowym językiem, konieczne jest kilka dostępów do bazy danych, ponieważ tłumaczenia atrybutów lokalizowalnych pochodzą z oddzielnych obiektów NLS. Jeśli wartość atrybutów NLS nie jest wymagana, obiekt można otworzyć z wartością null jako językiem.
Metoda GetObjectArray()
Metoda getObjectArray() otwiera wiele instancji obiektu biznesowego. Pozostałe parametry metody odpowiadają parametrom metody getObject(). Metoda getObjectArray ma zawsze krótszy czas odpowiedzi niż wielokrotne wywołanie getObject. Dlatego, jeśli to możliwe, należy używać getObjectArray zamiast getObject.
Sygnatury metody są następujące:
CisObject[] getObjectArray(byte[][] primaryKeys, int flags) CisObject[] getObjectArray(byte[][] primaryKeys, int flags, String language) CisObject[] getObjectArray(java.util.List primaryKeys, int flags) CisObject[] getObjectArray(java.util.List primaryKeys, int flags, String language)
Tryb działania
Manager obiektów próbuje odczytać instancje obiektów biznesowych z pamięci podręcznej transakcji. Instancje, które nie zostały znalezione, są wyszukiwane we współdzielonej pamięci podręcznej. Dostęp do bazy danych jest uzyskiwany dla pozostałych instancji, które również nie zostały tam znalezione. Wykonywane jest następujące zapytanie SQL:
SELECT * FROM table WHERE primaryKeyAttribute1=? OR ... OR primaryKeyAttributeN=?
Manager obiektów tworzy instancje klasy obiektów biznesowych, mapuje wynik zapytania na atrybuty i zwraca instancje do aplikacji jako CisObject-Array. Tam musi nastąpić rzutowanie typu z ogólnej klasy CisObject do konkretnej klasy odczytanych obiektów biznesowych. Jeśli nie zostanie znaleziony żaden wynik, zwracana jest pusta tablica CisObject.
Poniższy fragment kodu źródłowego otwiera instancje obiektu biznesowego Item poprzez klucze podstawowe:
byte[] primKey1 = Item.buildPrimaryKey( guid1 );
... byte
[]
primKeyN
= Item.buildPrimaryKey( guidN );
byte[][] primaryKeys = new byte[][]{primKey1, ...., primKeyN};
CisObject[] objects = om.getObjectArray(
primaryKeys, CisTransactionManager.READ);
for (int i=0; i< objects.length;i++) {
// Pozycja w obiektach odpowiada pozycji w primaryKeys
Item item = (Item) objects[i];
...
}
Zależność od czasu
Zachowanie odpowiada zachowaniu metody getObject(). Więcej informacji można znaleźć w sekcji Zależność od czasu w rozdziale Metoda getObject().
Obsługa NLS
Zachowanie odpowiada zachowaniu metody getObject(). Więcej informacji można znaleźć w sekcji Zależność od czasu w rozdziale Metoda getObject().
Metoda GetObjectList()
Metoda getObjectList() odczytuje kilka instancji obiektu biznesowego dla podanych kluczy w taki sam sposób jak getObjectArray(). Funkcje getObjectList() i getObjectArray() są identyczne, ale getObjectList() wyświetla listę z obiektami biznesowymi, podczas gdy getObjectArray() wyświetla tablicę. Rozmiar listy odpowiada liczbie przekazanych kluczy.
Sygnatura metody to:
<T extends CisObject> List<T> getObjectList(CisList keys, int flags)
Typ danych List jako wartość zwrotna umożliwia prostą konwersję typu na listę z obiektami biznesowymi, które są faktycznie otwarte.
Poniższy fragment kodu źródłowego otwiera instancje obiektu biznesowego Item poprzez klucze podstawowe:
CisList primaryKeys = new CisArrayList();
primaryKeys.add(Item.buildPrimaryKey( guid1 ));
...
primaryKeys.add(Item.buildPrimaryKey( guidN ));
List<Item> items = om.getObjectArray(
primaryKeys, CisTransactionManager.READ);
for (Item item : items) {
// Pozycja w items odpowiada pozycji w primaryKeys
...
}
Metoda putObject ()
Ta metoda rejestruje instancję obiektu biznesowego do zapisania w pamięci podręcznej transakcji bieżącej transakcji i sprawia, że jej zmienione atrybuty są widoczne w całej transakcji (= transakcje podrzędne lub podczas zatwierdzania transakcji nadrzędnej, a tym samym wszystkich transakcji podrzędnych). Dzięki temu obiekt jest widoczny w bieżącym kontekście lokalnym transakcji.
Sygnatura metody to:
void putObject(CisObject obj)
Tryb działania
Aby utworzyć lub zmienić instancję obiektu biznesowego, należy najpierw otworzyć transakcję najwyższego poziomu. Instancja jest następnie otwierana za pomocą getObject()/getObjectArray(), określając żądany tryb dostępu.
Tryb dostępu READ_UPDATE zapewnia instancje, które mogą być zmieniane lub usuwane zgodnie z wymaganiami. Tryb dostępu READ_WRITE tworzy nową instancję obiektu biznesowego, jeśli obiekt jeszcze nie istnieje. W takim przypadku READ_UPDATE zwraca wartość null.
Odczytana instancja obiektu biznesowego jest blokowana dla innych transakcji przez Persistence service. Jeśli inna transakcja chce odczytać tę samą instancję obiektu biznesowego, wyjątek limitu czasu pojawia się po określonym czasie oczekiwania.
Zmiany atrybutów są wprowadzane przy użyciu metod set…() klasy obiektu biznesowego. Wywołanie putObject() z instancją obiektu biznesowego jako parametrem przenosi zmiany do bieżącej pamięci podręcznej transakcji.
Instancja obiektu biznesowego, która została przekazana do putObject jest nieważna po wywołaniu putObject() i nie może być już używana. Nowa funkcja getObject() w ramach transakcji zwraca zmienioną instancję obiektu biznesowego.
Tylko zarejestrowane zmiany są brane pod uwagę podczas commit() transakcji. Operacja bazy danych mająca na celu utrwalenie zarejestrowanych zmian w bazie danych nie jest wykonywana do momentu commit() transakcji najwyższego poziomu.
Jeśli obiekt biznesowy zawiera informacje o aktualizacji (atrybut UpdateInformation), czas i osoba, która dokonała ostatniej zmiany, są aktualizowane podczas tego wywołania.
Poniższy fragment kodu źródłowego otwiera instancję obiektu biznesowego UnitOfMeasure z bazy danych lub tworzy nową instancję:
try (CisTransaction txn = tm.createNew()) {
byte[] key = UnitOfMeasure.buildByCodeKey(code);
// Załaduj instancję do zmiany/utworzenia
UnitOfMeasure unitOfMeasure = om.getObject(key,
CisObjectManager.READ_WRITE);
if (unitOfMeasure.is_newObject() ) {
// utworzyć
} else {
// aktualizacja
}
// Ustaw atrybuty
unitOfMeasure.setDescription(description);
...
// Zarejestruj zmiany w pamięci podręcznej transakcji
om.putObject(unitOfMeasure);
// Zakończenie transakcji, zapisanie zmian
txn.commit() ;
}
Obiekt stanu
Każda zmieniona instancja obiektu biznesowego ma jeden lub więcej obiektów stanu, które zawierają rzeczywiste wartości atrybutów. W przypadku zmian atrybutów, nowy obiekt stanu jest tworzony w kontekście lokalnym transakcji – jeśli jeszcze nie istnieje – który zawiera atrybuty obowiązujące w tym kontekście. Obiekty stanu są specyficzne dla transakcji i są przenoszone do transakcji nadrzędnej tylko podczas zatwierdzenia.
Zależność od czasu
Instancje zależne od czasu są obsługiwane w zależności od wartości atrybutów validFrom i validUntil:
- Jeśli validFrom ma wartość null, wówczas validFrom jest ustawiane na bieżący czas.
- Jeśli atrybut validUntil jest ustawiony na null, atrybut ten jest ustawiany na validFrom kolejnej wersji podczas putObject. Jeśli nie istnieje kolejna wersja, validUntil jest ustawiane na MAX_DATE.
Atrybut validUntil poprzedniej wersji jest ustawiany na validFrom zmodyfikowanego obiektu.
Więcej informacji można znaleźć w rozdziale Zależność od czasu.
Obsługa NLS
Gdy tworzona jest instancja obiektu biznesowego, wszystkie wpisy języków drugorzędnych są tworzone w tabeli NLS powiązanej z atrybutem wielojęzyczności, niezależnie od określonego języka treści. Wartość atrybutu jest przenoszona zarówno do języka głównego, jak i języków dodatkowych.
Gdy instancja obiektu biznesowego zostanie zmieniona, wartość ustawiona dla atrybutu wielojęzycznego zostanie zapisana w określonym języku treści w bazie danych. Jeśli język treści jest głównym językiem bazy danych, wartość jest zapisywana bezpośrednio w tabeli odpowiadającej obiektowi biznesowemu. Jeśli jest to język drugorzędny, wartość jest zapisywana w tabeli odpowiadającej tabeli NLS.
Metoda deleteObject()
Metoda deleteObject() rejestruje instancję obiektu biznesowego do usunięcia w pamięci podręcznej transakcji bieżącej transakcji. Powoduje to usunięcie go z bieżącego kontekstu lokalnego transakcji. Sygnatura metody to:
void deleteObject(CisObject obj)
Tryb działania
Aby usunąć instancję, należy najpierw otworzyć transakcję najwyższego poziomu. Obiekt biznesowy, który ma zostać zmieniony, jest następnie otwierany za pomocą funkcji getObject(), określając tryb dostępu READ_UPDATE. Wywołanie deleteObject() z instancją obiektu biznesowego oznaczoną jako parametr ustawia instancję w pamięci podręcznej bieżącej transakcji do usunięcia. Gdy transakcja najwyższego poziomu zostanie zatwierdzona, instancja obiektu biznesowego zarejestrowana do usunięcia zostanie usunięta z bazy danych.
Po usunięciu instancji obiektu biznesowego za pomocą funkcji deleteObject(), otwarta instancja jest nieważna i nie może być już używana. Ponowny odczyt tej samej instancji obiektu biznesowego w trybie dostępu READ-UPDATE zwraca teraz wartość null. Jeśli usunięta instancja zostanie ponownie odczytana w trybie READ_WRITE w tej samej transakcji (lub jej podtransakcjach), w której instancja została usunięta, usługa trwałości nie utworzy nowego obiektu, ale zwróci zawartość poprzednio usuniętej instancji.
Poniższy fragment kodu źródłowego otwiera instancję obiektu biznesowego UnitOfMeasure z bazy danych. Znaleziona instancja jest oznaczona do usunięcia. Instancja jest usuwana w momencie commit.
try (CisTransaction txn = tm.beginNew()) {
byte[] key = UnitOfMeasure.buildByCodeKey(code);
// Załaduj instancję do zmiany/utworzenia
UnitOfMeasure unitOfMeasure = (UnitOfMeasure) om.getObject(key,
CisObjectManager.READ_UPDATE);
if (unitOfMeasure==null) {
// Nie znaleziono
...
} else {
// Wybierz, aby usunąć
om.deleteObject(unitOfMeasure);
}
// Zakończenie transakcji, zapisanie zmian
txn.commit();
}
Zależność od czasu
Gdy zależna od czasu wersja instancji obiektu biznesowego zostanie usunięta, wartość atrybutu validUntil kontroluje, czy powstała luka w łańcuchu wersji zostanie zamknięta.
Jeśli wartość wynosi null, okres ważności poprzedniej wersji jest przedłużany o okres ważności usuniętej wersji. Poprzednia wersja jest zatem ważna tak długo, jak usunięta wersja (przeniesienie wartości z validUntil usuniętej wersji do poprzedniej wersji).
Jeśli wartość nie wynosi null, określona wersja zostanie usunięta, a w łańcuchu wersji może pozostać luka.
Więcej informacji można znaleźć w rozdziale Zależność od czasu.
Obsługa NLS
Po usunięciu instancji obiektu biznesowego z atrybutami wielojęzycznymi, powiązane wpisy dla języków dodatkowych są również usuwane z tabel NLS.
Metoda getObjectIterator()
Metoda getObjectIterator() może być użyta do otwarcia zestawu instancji obiektów biznesowych. W tym celu metoda zwraca iterator poprzez zestaw wyników określonego zapytania OQL. Instrukcja OQL SELECT i opcjonalnie tryb dostępu są oczekiwane jako parametry. Podobnie jak w przypadku getObject(), można również określić język treści dla otwieranych instancji.
Metoda ta ma następujące sygnatury:
CisObjectIterator getObjectIterator (String oqlString) CisObjectIterator getObjectIterator (String oqlString, int flags) CisObjectIterator getObjectIterator (String oqlString, int flags, String language)
Użycie sub-selekcji w klauzuli WHERE jest dozwolone w instrukcji OQL. Połączenia nie są obsługiwane.
Tryb działania
Metoda getObjectIterator() zwraca iterator, który jest używany w aplikacji do otwierania instancji obiektów biznesowych. Następnie ustawiane są wartości parametrów wyboru, które zostały określone w instrukcji OQL za pomocą symbolu zastępczego ?. Pierwsze wywołanie hasNext() lub next() na iteratorze wyzwala dostęp do bazy danych. Metoda hasNext() sprawdza, czy instancje mogą być nadal dostarczane. Metoda next() dostarcza następną instancję do aplikacji. Jeśli obiekt biznesowy jest buforowany we współdzielonej pamięci podręcznej, wartości klucza podstawowego są otwierane jako pierwsze:
SELECT primkeyAttr FROM table [WHERE ...]
Instancje obiektów biznesowych są tworzone przy użyciu wewnętrznie wywoływanej metody getObjectArray(), która otwiera instancje w blokach za pośrednictwem kluczy głównych. Domyślny rozmiar bloku to 16. Jeśli instancja obiektu biznesowego jest oznaczona jako usunięta w pamięci podręcznej bieżącej transakcji, jest filtrowana i nie jest zwracana. Iterator obiektów nigdy nie zwraca wartości null. W aplikacji należy wykonać rzutowanie typu z ogólnej klasy CisObject do określonej klasy odczytywanych obiektów biznesowych.
Jeśli obiekt biznesowy nie jest buforowany we współdzielonej pamięci podręcznej, wszystkie atrybuty są odczytywane bezpośrednio z bazy danych i tworzone są instancje obiektu biznesowego. Jeśli znacznik BYPASS_CACHE jest określona dla getObjectIterator(), instancje są również całkowicie otwierane przez bazę danych, tak jakby obiekt biznesowy nie był buforowany.
Jeśli używany jest iterator obiektów z znacznikami READ_UPDATE lub READ_WRITE, wówczas tylko klucze podstawowe są odczytywane z bazy danych, a obiekty są otwierane za pomocą funkcji getObjectArray().
Poniższy fragment kodu źródłowego otwiera instancje obiektu biznesowego Item, do którego przypisana jest określona jednostka miary (obiekt biznesowy UnitOfMeasure). Ich klucz główny typu GUID jest ustawiany jako parametr w iteratorze za pomocą metody setGuid(), która przekazuje pozycję w instrukcji OQL i wartość jako parametry.
Przykład z parametrem OQL:
byte[] uomGuid = ... ; try (CisObjectIterator<Item> iter = ... ;
try (CisObjectIterator<Item> iter = om.getObjectIterator(
"SELECT FROM com.cisag.app.general.obj.Item i WHERE i:uom=?")
) {
iter.setGuid(1, uomGuid);
while (iter.hasNext() ) {
Item item = (Item) iter.next() ;
...
}
}
Nota wyjaśniająca
Wynik wyrażenia OQL jest obliczany bezpośrednio na danych w bazie danych; pamięć podręczna transakcji nie jest brana pod uwagę. Obiekty zmienione w tym samym kontekście transakcji nie są zatem brane pod uwagę, ponieważ zmiany te nie zostały jeszcze zapisane w bazie danych. Stają się one trwałe dopiero po zakończeniu transakcji najwyższego poziomu. Oznacza to, że iterator obiektów może dostarczać nieprawidłowe dane, jeśli jego instrukcja OQL wpływa również na zmienione obiekty. Nowo utworzone obiekty nie mogą być brane pod uwagę ze względu na zasadę funkcjonalną, usunięte obiekty można odfiltrować za pomocą klucza podstawowego.
To zachowanie należy wziąć pod uwagę podczas korzystania z funkcji getObjectIterator() w zmieniających się transakcjach.
Zależność od czasu
Jeśli ani validFrom, ani validUntil nie są używane w instrukcji OQL dla obiektów biznesowych zależnych od czasu, zwracane są tylko aktualnie ważne instancje. Jeśli validFrom lub validUntil jest używane w dowolnej części instrukcji OQL, wówczas zwracane są wszystkie dostępne wersje, do których odnosi się warunek instrukcji OQL.
Obsługa NLS
Zachowanie odpowiada zachowaniu metody getObject(), patrz sekcja Zależność od czasu w rozdziale Metoda getObject().
Metoda getResultSet()
Metoda getResultSet() może być używana do odczytywania atrybutów z obiektów biznesowych za pomocą instrukcji SELECT języka OQL. Atrybuty wyników mogą być łączone zgodnie z wymaganiami za pomocą instrukcji SELECT w OQL. Żadne kompletne instancje obiektów biznesowych nie są odczytywane z bazy danych. Zestaw wyników jest powiązany z bieżącą transakcją. Połączenia i podselekcje są dozwolone w łańcuchu OQL.
Dopóki zestaw wyników nie zostanie zamknięty, połączenie z bazą danych jest używane wyłącznie. Połączenie z bazą danych jest ponownie zwalniane dopiero po zamknięciu zestawu wyników. Polecenie rollback() lub commit() domyślnie zamyka wszystkie zestawy wyników powiązanej transakcji. Jeśli zestaw wyników jest używany w ramach fikcyjnej transakcji, deweloper musi upewnić się, że został on zamknięty. Zestaw wyników powinien być zawsze używany w bloku try/catch. W bloku finally zestaw wyników jest jawnie zamykany za pomocą metody close().
Ważne jest, aby zminimalizować czas otwarcia zestawu wyników, ponieważ liczba dostępnych połączeń z bazą danych jest ograniczona. Złożone lub długie operacje powinny być wykonywane dopiero po zamknięciu zestawu wyników. Ważne jest również, aby zagnieżdżone zestawy wyników korzystały z własnego połączenia z bazą danych. Oznacza to, że liczba dostępnych połączeń z bazą danych ogranicza głębokość zagnieżdżenia. Z tego powodu głębokość zagnieżdżenia powinna być niewielka.
Sygnatury metody są następujące:
CisResultSet getResultSet(String oqlString) CisResultSet getResultSet(String oqlString, int flags) CisResultSet getResultSet(String oqlString, int flags, String language)
Tryb działania
Metoda getResultSet() zwraca zestaw wyników, który może być użyty do zapytania zestawu wyników rekord po rekordzie. Instrukcja OQL przekazana jako parametr może zawierać symbole zastępcze (?) dla wartości, którym należy przypisać odpowiednie wartości wyboru przed wykonaniem zapytania. Odbywa się to za pomocą metody set…() odpowiadającej typowi danych parametru wyboru, do której wartość wyboru i numer parametru wyboru są przekazywane jako parametry. Numeracja parametrów wyboru jest niejawnie określona przez ich pozycję (od lewej) w instrukcji OQL. Zapytanie jest oceniane przez bazę danych, gdy pierwszy rekord wyniku jest odpytywany przy użyciu metody next().
Wartości atrybutów dla tego zestawu mogą być następnie odpytywane przy użyciu metody get…() odpowiadającej typowi danych. Numer atrybutu jest przekazywany do metody get…() jako parametr. Jest on określony przez kolejność atrybutów wyniku w klauzuli SELECT (od lewej). Istnienie następnego rekordu wyniku można sprawdzić za pomocą metody hasNext(). Jeśli istnieją kolejne rekordy, ponowne wywołanie metody next() zwraca następny rekord. Aplikacja musi pobrać atrybuty odczytanego rekordu ze zbioru wyników za pomocą odpowiedniej metody (w zależności od typu danych). Po odczytaniu danych należy upewnić się, że zestaw wyników został zamknięty.
Poniższy fragment kodu źródłowego otwiera tylko atrybuty guid (klucz podstawowy) i number (klucz funkcjonalny) instancji obiektu biznesowego Item, do którego przypisana jest określona jednostka miary (obiekt biznesowy UnitOfMeasure). Ich klucz główny typu GUID jest ustawiany jako parametr w zestawie wyników za pomocą metody setGuid() (pasującej do typu), do której pozycja w instrukcji OQL i wartość są przekazywane jako parametry. Blok try-catch-finally zapewnia, że zestaw wyników zostanie zamknięty, nawet jeśli wystąpi wyjątek.
byte[] uomGuid = ... ;
try (CisResultSet rs = om.getResultSet("SELECT i:guid, i:number
FROM com.cisag.app.general.obj.Item i
WHERE i:uom=?")) {
rs.setGuid(1, uomGuid);
while (rs.next() ) {
// czytaj dalej
byte[] guid = rs.getGuid(1);
String number = rs.getString(2);
...
}
}
[/alert]
Nota wyjaśniająca
Zestaw wyników jest zawsze oceniany w bazie danych, pamięć podręczna transakcji nie jest brana pod uwagę. Podobnie jak w przypadku getObjectIterator(), zmiany w pamięci podręcznej transakcji nie mają wpływu na wybór zwracanych wartości. Należy to wziąć pod uwagę podczas korzystania z funkcji getResultSet() w zmieniających się transakcjach.
Zależność od czasu
Jeśli ani atrybut validFrom, ani validUntil obiektu biznesowego zależnego od czasu nie jest używany w instrukcji OQL, wówczas tylko aktualnie ważne wersje są brane pod uwagę podczas oceny instrukcji OQL. Jeśli atrybut validFrom lub validUntil obiektu biznesowego jest używany w dowolnej części instrukcji OQL, wówczas wszystkie dostępne wersje są uwzględniane w zapytaniu.
Obsługa NLS
Zestaw wyników oferuje obsługę NLS dla atrybutów wielojęzycznych. Jeśli określony język treści jest głównym językiem bazy danych, wartości atrybutów są odczytywane z tabel powiązanych obiektów biznesowych. Jeśli zaangażowany jest język dodatkowy, instrukcja OQL jest rozszerzana o odpowiednie sprzężenia wewnętrzne do obiektów NLS atrybutów wielojęzycznych. Wartość atrybutu wielojęzycznego jest odczytywana z tabeli NLS dla określonego języka treści.
Metoda getUpdateStatement ()
OQL może być używany do wykonywania instrukcji UPDATE, INSERT lub DELETE. Pozwala to na zmianę, wstawienie lub usunięcie wielu instancji obiektów biznesowych za pomocą jednego polecenia.
Instrukcja aktualizacji jest wykonywana tylko wtedy, gdy transakcja najwyższego poziomu jest zatwierdzona. Wcześniej instrukcja UPDATE nie ma wpływu na dane, które mają zostać otwarte w transakcji. Jeśli użytkownik chciałby zmienić, wprowadzić lub usunąć obiekt biznesowy za pomocą instrukcji UPDATE, a także zmodyfikujesz go w tej samej transakcji za pomocą metod putObject lub deleteObject, spowoduje to błąd. Instrukcja UPDATE blokuje całą tabelę, na której działa instrukcja; żadna inna transakcja nie może otworzyć instancji obiektu biznesowego tego typu. Jeśli obiekt biznesowy zostanie zmieniony za pomocą instrukcji UPDATE, wszystkie inne sesje, które chcą zmienić instancje tego samego obiektu biznesowego, muszą poczekać na zakończenie transakcji z instrukcją UPDATE. Użycie instrukcji UPDATE może zatem uniemożliwić skalowanie aplikacji.
Instrukcja UPDATE nie może zmieniać żadnych atrybutów klucza podstawowego.
Wydajność, np. podczas usuwania wielu rekordów danych, jest znacznie wyższa w przypadku usuwania OQL niż za pośrednictwem Persistence service. Użycie instrukcji UPDATE ma jednak poważny wpływ na ogólną wydajność systemu. Po użyciu instrukcji aktualizacji wszystkie instancje tego obiektu biznesowego w tej bazie danych są usuwane ze wszystkich współdzielonych pamięci podręcznych w całym systemie. Jeśli inne aplikacje zależą od instancji tego obiektu biznesowego przechowywanych w pamięci podręcznej, wydajność jest znacznie zmniejszona.
Ani Workflow management, ani dziennik zmian nie są powiadamiane, jeśli instancje obiektów biznesowych są zmieniane, usuwane lub tworzone przez instrukcje aktualizacji. Informacje o aktualizacji nie są aktualizowane dla instancji obiektów biznesowych utworzonych i zmienionych przez instrukcje aktualizacji.
Instrukcje aktualizacji są przede wszystkim odpowiednie dla następujących przypadków użycia:
- Usuwanie danych tymczasowych
- Reorganizacje
try (CisTransaction txn=tm.create()) {
CisUpdateStatement s = om.getUpdateStatement("DELETE FROM com.cisag.sys.tools.testsuite.obj.SimpleMasterData a WHERE a:code like ?");
s.setString(1,'001%');
om.putUpdateStatement(s);
txn.commit() ;
}
Obsługa NLS
Instrukcje aktualizacji nie obsługują atrybutów wielojęzycznych. Jeśli są one używane w instrukcji update, główny język bazy danych jest zawsze używany jako język treści. Tabele NLS nie są brane pod uwagę, dlatego nie można wstawiać danych do tabel obiektów biznesowych z atrybutami wielojęzycznymi w instrukcjach INSERT. W przeciwnym razie w tabelach NLS atrybutów brakowałoby wpisów dla języków dodatkowych.
Zależność od czasu
Instrukcje aktualizacji nie obsługują zależności od czasu. Jeśli obiekty biznesowe zależne od czasu są używane w instrukcjach aktualizacji, wszystkie wersje są zawsze obsługiwane niezależnie od użycia validFrom i validUntil, a nie tylko aktualnie ważna wersja. Jeśli ma być wybrana tylko aktualnie ważna wersja, wybór musi być odpowiednio ograniczony.
Zalety i wady metod dostępu
Ta sekcja zawiera kilka wskazówek dotyczących korzystania z przedstawionych metod w celu osiągnięcia dobrej wydajności.
Metoda getObjectArray() (ArrayFetch) nigdy nie jest wolniejsza niż wykonanie metody getObject() n-razy, ale często jest szybsza. Wymaga maksymalnie jednego żądania bazy danych w przeciwieństwie do maksymalnie n-żądań bazy danych.
Kolejną zaletą jest to, że mapowanie atrybutów między atrybutami OQL, SQL i Java musi być określone tylko raz.
Jeśli dla otwieranego obiektu biznesowego ustawiona jest strategia pamięci podręcznej, metody getObject(), getObjectArray() i getObjectIterator() zawsze najpierw odczytują współdzieloną pamięć podręczną. Wstawiają one również instancje otwarte przez bazę danych do pamięci podręcznej. Metody te są przydatne w przypadku często używanych obiektów biznesowych (np. danych podstawowych), ponieważ uwzględniają pamięć podręczną podczas dostępu.
Z drugiej strony, są one słabo przystosowane do masowych operacji na danych transakcyjnych (np. zapytania o dostępność artykułów), ponieważ mogą one wyprzeć inne często używane dane ze współdzielonej pamięci podręcznej, nawet jeśli nowo przechowywane dane prawie nigdy nie będą ponownie potrzebne. Inną wadą jest to, że metody te generują wiele obiektów Java, które są potrzebne tylko tymczasowo, co wymaga czasu i miejsca w pamięci głównej.
Dzięki metodzie getResultSet() możliwe jest otwarcie tylko tych atrybutów, które są wymagane, a nie całej instancji obiektu biznesowego z być może dziesiątkami atrybutów. Zmniejsza to ilość danych do przesłania, a zatem w Javie tworzonych jest mniej obiektów. W przypadku korzystania z funkcji getResultSet(), na deweloperze spoczywa większa odpowiedzialność, ponieważ otwarty zestaw wyników zajmuje wyłącznie połączenie z bazą danych. Ponadto trzeba samodzielnie zadbać o mapowanie wyników zestawu wyników na atrybuty Java.
Tryby dostępu
Typ dostępu do obiektów biznesowych jest kontrolowany przez tryb dostępu. Jeśli nie określono trybu dostępu, wówczas używany jest standardowy tryb dostępu READ.
| Tryb dostępu | Znaczenie |
| READ | Instancja obiektu biznesowego jest odczytywana, ale nie może zostać zmieniona. Jeśli instancja nie została znaleziona, wyświetlana jest wartość null. |
| READ_UPDATE | Instancja obiektu biznesowego jest odczytywana w celu modyfikacji i może zostać zmieniona lub usunięta zgodnie z wymaganiami. Jeśli instancja nie została znaleziona, wyświetlana jest wartość null. |
| READ_WRITE | Podobnie jak tryb dostępu READ_UPDATE. Ale: jeśli instancja, do której ma zostać uzyskany dostęp, nie istnieje, wyświetlana jest nowa instancja. Jeśli nowa instancja zawiera atrybut UpdateInformation, czas utworzenia i użytkownik są wprowadzane do UpdateInformation. Jeśli instancja jest nowo utworzona za pomocą klucza pomocniczego, wszystkie atrybuty klucza głównego typu GUID są inicjowane nowym identyfikatorem GUID. |
| READ_REPEATABLE | Tryb dostępu jawnie ustawia blokadę odczytu na instancję obiektu biznesowego i zapewnia, że nie może ona zostać zmieniona przez inne transakcje. Gwarantuje to, że instancja w pamięci podręcznej pasuje do danych w bazie danych. Oznacza to, że tryb dostępu gwarantuje dostarczanie spójnych danych, nawet jeśli kilka serwerów aplikacji pracuje na bazie danych OLTP. Inaczej jest w przypadku zwykłego READ, ponieważ synchronizacja cache pomiędzy serwerami odbywa się co 30 sekund, a instancja obiektu biznesowego z nieaktualnymi wartościami atrybutów może znajdować się w cache. |
| READ_PARALLEL | Ten tryb dostępu jest przydatny, jeśli użytkownik chciałby użyć fikcyjnej transakcji do odczytu z innej transakcji. Umożliwia to powiązanie ważności iteratorów obiektów i zestawów wyników z fikcyjną transakcją, a nie z bieżącą transakcją. Transakcja fikcyjna musi być otwarta w bazie danych. Opcja ta działa zatem tylko w bazie danych OLTP przypisanej do użytkownika. |
| INSERT | Jeśli ma zostać utworzona nowa instancja obiektu biznesowego, a z logiki programu wiadomo, że instancja jeszcze nie istnieje, wówczas usługa trwałości nie musi sprawdzać jej istnienia w bazie danych. Ten tryb dostępu wyłącza sprawdzanie istnienia i tworzy nową, nietrwałą instancję obiektu biznesowego niezależnie od zawartości bazy danych. Jeśli, wbrew założeniu, instancja nadal istnieje, wystąpi błąd podczas zatwierdzania transakcji najwyższego poziomu. |
| INSERT_DIRTY | Ten tryb dostępu zachowuje się jak INSERT, ale blokowanie jest wyłączone. Oznacza to, że nie są powiadamiani słuchacze pamięci podręcznej ani nie są wyzwalane zdarzenia przepływu pracy. Ten tryb nie powinien być używany w przypadku obiektów biznesowych zależnych od czasu i obiektów biznesowych ze strategią pamięci podręcznej Otwórz wszystkie instancje przy pierwszym dostępie. INSERT_DIRTY jest zatem użyteczny tylko dla danych tymczasowych. |
| NEW_VERSION | W tym trybie dostępu nowa pusta wersja instancji obiektu biznesowego jest zawsze tworzona bez uwzględniania pamięci podręcznej lub bazy danych. Ta opcja jest przydatna tylko w trybie tylko do wstawiania dla obiektów zależnych od czasu. |
Wymienione tryby dostępu można modyfikować za pomocą dodatkowych znaczników. Aby to zrobić, odpowiednie stałe muszą być połączone za pomocą operacji binarnej AND.
| Znacznik | Znaczenie |
| DISABLE_LOCKING | Blokowanie jest wyłączone w tym trybie dostępu. Znacznik ten zasadniczo nie powinien być używany, ponieważ w przeciwnym razie dane mogą stać się niespójne z powodu brakujących blokad. |
| NO_PUT_SHARED_CACHE | Wystąpienie obiektu biznesowego nie jest przechowywane we współdzielonej pamięci podręcznej. |
| CACHE_ONLY | Instancja obiektu biznesowego jest wyszukiwana tylko we współdzielonej pamięci podręcznej. Jeśli go tam nie ma, zwracana jest wartość null, nawet jeśli jest on obecny w bazie danych. Ten tryb dostępu nie powinien być używany, ponieważ wynik nie jest deterministyczny. |
| BYPASS_CACHE | Instancja obiektu biznesowego jest odczytywana bezpośrednio z bazy danych. Zarówno współdzielona pamięć podręczna, jak i lokalna pamięć podręczna transakcji są ignorowane. Jeśli dla obiektu biznesowego ustawiona jest strategia pamięci podręcznej, instancja jest dołączana do pamięci podręcznej. Ten tryb dostępu zwiększa wydajność iteratorów obiektów, jeśli większość instancji do otwarcia nie znajduje się we współdzielonej pamięci podręcznej. |
| IGNORE_SHARED_CACHE | Tryb dostępu ma taki sam efekt jak BYPASS_CACHE, tylko instancja obiektu biznesowego nie jest przechowywana we współdzielonej pamięci podręcznej po odczycie. Zapobiega to wypieraniu ważniejszych obiektów w pamięci podręcznej przez odczytywany obiekt. |
Jak działa dostęp do obiektów biznesowych
Poniżej wyjaśniono, w jaki sposób Persistence service działa podczas otwierania i zapisywania instancji obiektów biznesowych w transakcjach.
Dostęp do odczytu
Gdy odczytywana jest instancja obiektu biznesowego, jest ona najpierw wyszukiwana w pamięci podręcznej transakcji. W pierwszej kolejności brane są pod uwagę zmiany w ostatnio otwartej podtransakcji. Jeśli obiekt nie zostanie znaleziony w pamięci podręcznej transakcji, wówczas jest wyszukiwany we współdzielonej pamięci podręcznej. Jeśli obiekt nie znajduje się również we współdzielonej pamięci podręcznej, jest wyszukiwany w bazie danych.
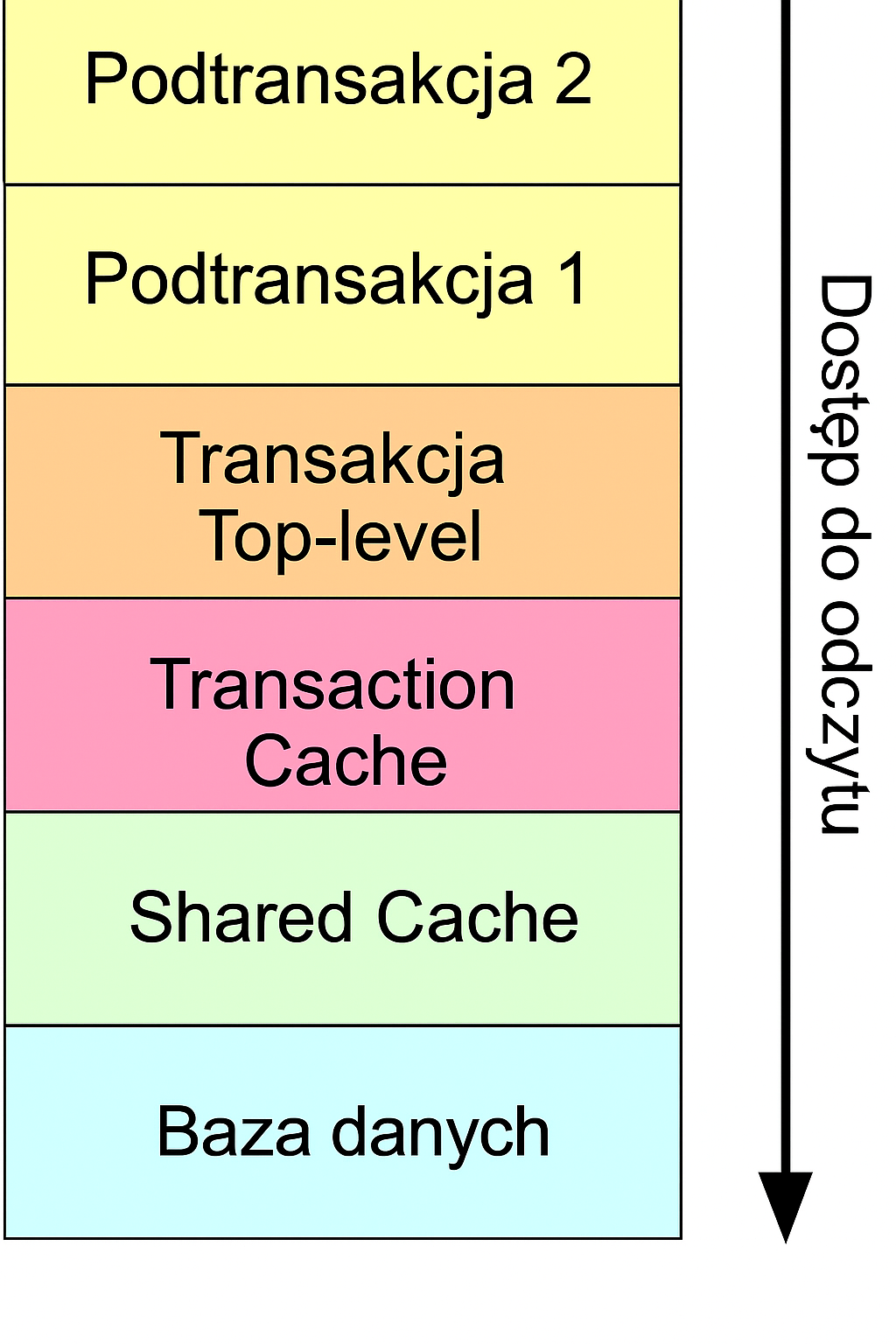
Dostęp do zapisu
W przypadku dostępu do zapisu dane są zapisywane z pamięci podręcznej transakcji do współdzielonej pamięci podręcznej i do bazy danych w tym samym czasie podczas zatwierdzenia.
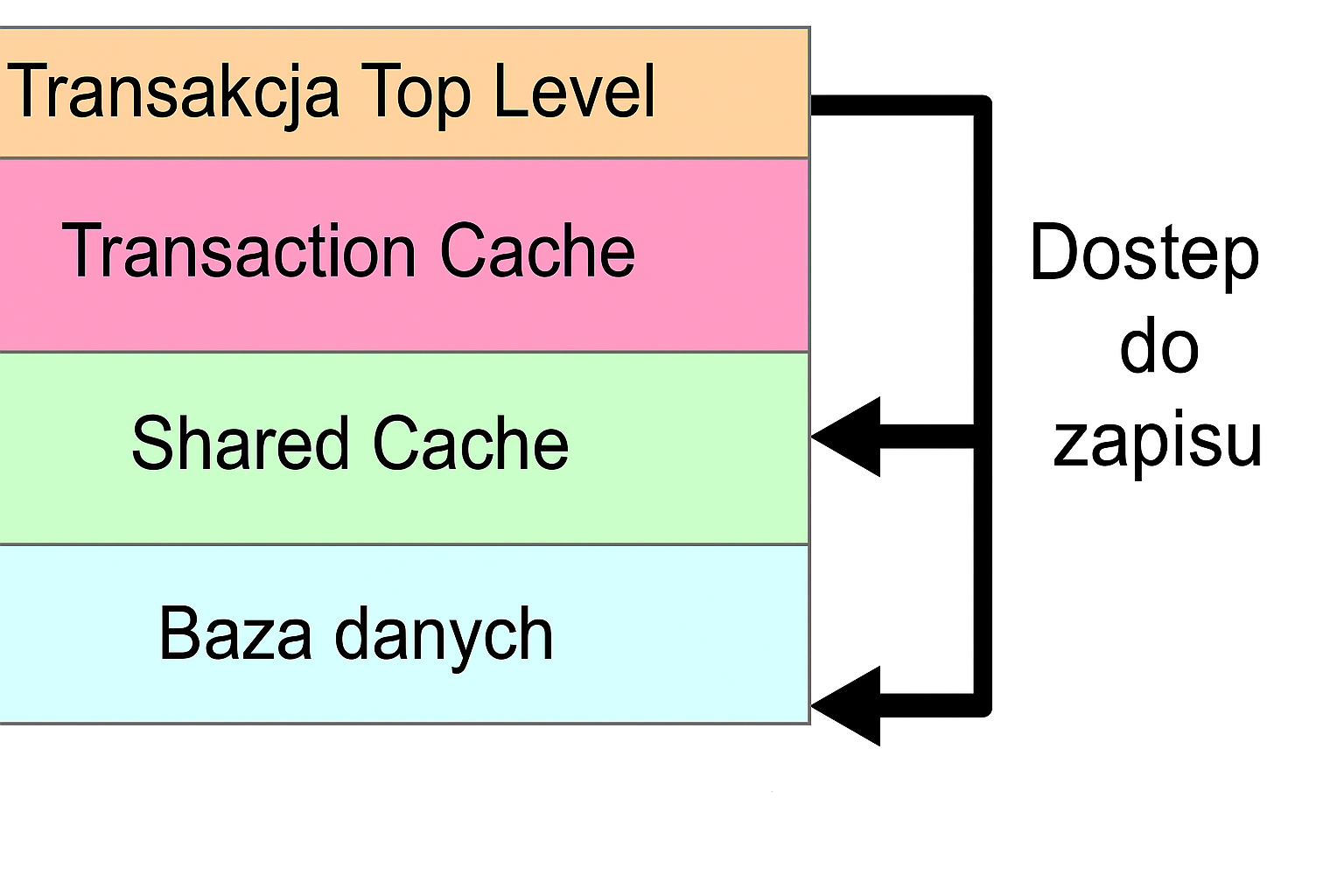
Procedura zatwierdzania transakcji najwyższego poziomu
Obiekty stanu
Obiekty stanu przechowują atrybuty instancji obiektu biznesowego. Klasa główna jest opakowaniem, które hermetyzuje dostęp do obiektów stanu. Obiekty stanu tworzą łańcuch zgodnie z głębokością zagnieżdżenia podtransakcji. Ostatni obiekt stanu zawiera status instancji obiektu biznesowego. Wszystkie metody set() i get() klasy obiektu biznesowego wywołują odpowiednie metody obiektu stanu.
Dla niezmienionej instancji obiektu biznesowego nowy obiekt stanu jest tworzony przy pierwszej zmianie atrybutu. Nowy obiekt stanu jest kopią poprzedniego obiektu stanu ze zmienionym atrybutem.
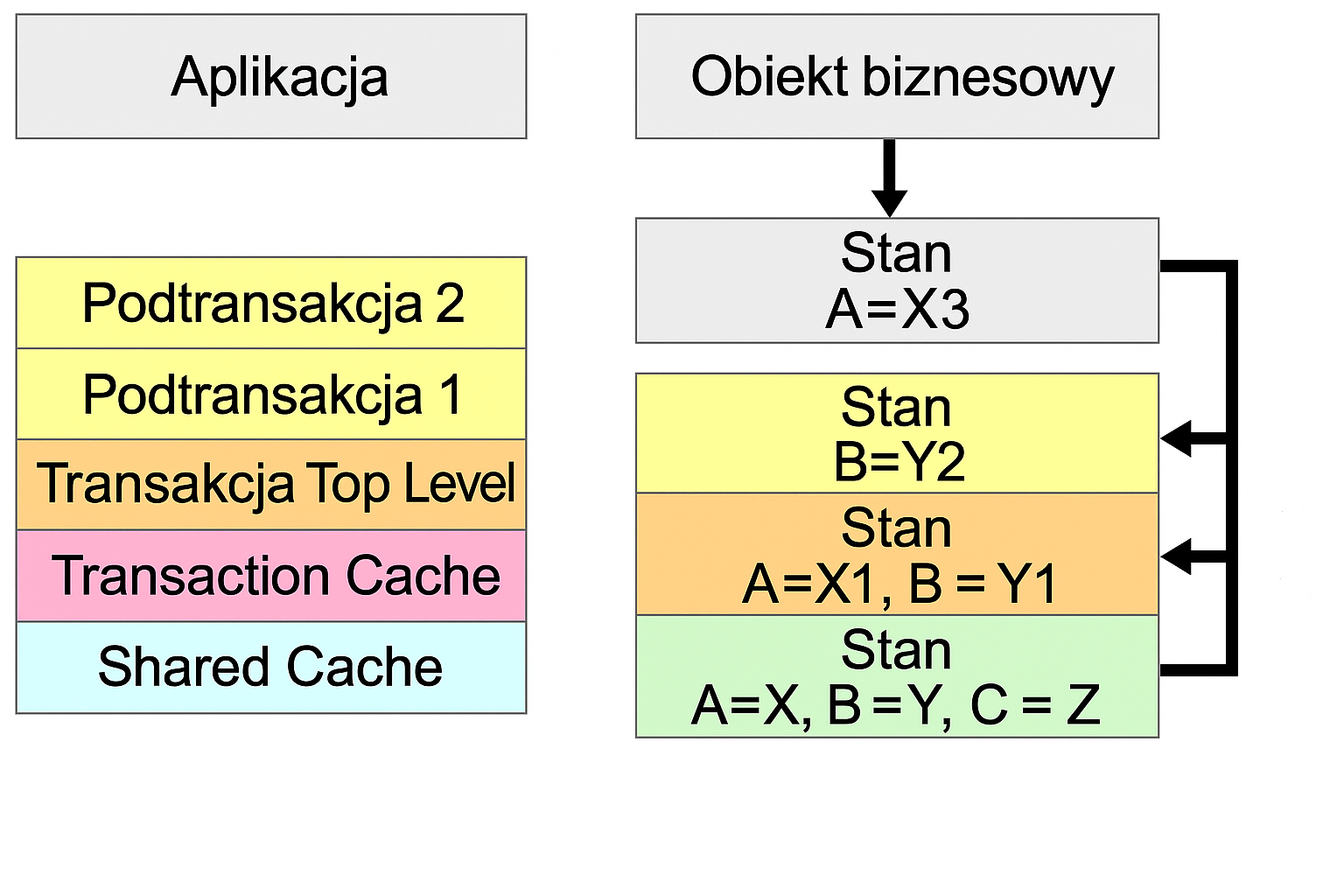
W powyższym przykładzie aplikacja otworzyła instancję obiektu biznesowego w Podtransakcji 2, zmieniła atrybut A, a tym samym utworzyła nowy obiekt stanu, który zawiera nowy stan instancji obiektu biznesowego z wartością X3 A. Instancja obiektu biznesowego nie została jeszcze zarejestrowana do zapisu, a obiekt stanu nie został jeszcze zapisany w pamięci podręcznej transakcji. Obiekt stanu odwołuje się do obiektu stanu w nadrzędnej Podtransakcji 1. W tym przypadku atrybut B instancji obiektu biznesowego został zmieniony, a zmieniony stan został zapisany w obiekcie stanu. Instancja obiektu biznesowego została zarejestrowana do zapisania w Podtransakcja 1. W rezultacie powiązany obiekt stanu jest przechowywany w pamięci podręcznej transakcji. Obiekt stanu odwołuje się do obiektu stanu w transakcji Top Level. W tej transakcji atrybuty A i B instancji obiektu biznesowego zostały zmienione, a zmieniony stan został zapisany w obiekcie stanu. Instancja obiektu biznesowego została zarejestrowana do zapisania w transakcji najwyższego poziomu. W rezultacie powiązany obiekt stanu jest przechowywany w pamięci podręcznej transakcji. Obiekt stanu odwołuje się do obiektu stanu we współdzielonej pamięci podręcznej, w której otwarte instancje obiektów biznesowych są globalnie buforowane. Gdyby obiekt został ponownie otwarty w Podtransakcji 2, zawierałby wartości A=X1, B=Y2 i C=Z, ponieważ wartość B w obiekcie stanu została zmieniona w Podtransakcji 1.
Obiekty stanu w transakcjach
Każdy obiekt biznesowy należy do transakcji, w której został odczytany lub utworzony. Można go używać tylko w tym kontekście transakcji. Obiekty stanu są również specyficzne dla transakcji. Odpowiedni obiekt stanu jest tworzony w każdej transakcji, w której obiekt biznesowy jest zmieniany. Zawiera on wszystkie atrybuty zmienione w tej transakcji.
Otwieranie instancji obiektu biznesowego (getObject())
Instancja obiektu biznesowego jest otwierana z bazy danych za pomocą funkcji getObject() i jest przechowywana we współdzielonej pamięci podręcznej. Jest on nadal w tym samym stanie, co w bazie danych. W związku z tym, wystarczy utworzyć pojedynczy obiekt stanu, który jest dostępny do odczytu ze wszystkich sesji.
Ilustracja przedstawia transakcję najwyższego poziomu, która otworzyła obiekt biznesowy za pomocą funkcji getObject(). Ponieważ nie wprowadzono żadnych zmian, odwołuje się do obiektu stanu we współdzielonej pamięci podręcznej, która zawiera wartości atrybutów.
Ustawianie wartości atrybutów (set …() i get …())
Odwoływanie się do obiektu stanu we współdzielonej pamięci podręcznej nie jest już możliwe, jeśli atrybut instancji obiektu biznesowego zostanie zmieniony w ramach transakcji (set…()). Następnie tworzony jest nowy obiekt stanu dla instancji obiektu biznesowego, którego atrybut został zmieniony, w którym zapisywane są zmienione wartości atrybutów.
W transakcji najwyższego poziomu instancja obiektu biznesowego została otwarta do modyfikacji, a atrybut A został zmieniony na wartość X3 przy użyciu odpowiedniej metody set…(). Tworzony jest nowy obiekt stanu, który zawiera stan instancji obiektu biznesowego ze zmienioną wartością atrybutu. Poprzedni obiekt stanu jest przywoływany w obiekcie stanu.
Zarejestruj się do zapisu (putObject())
Aby dokonać zmiany w instancji obiektu biznesowego znanej w ramach transakcji, należy ją zarejestrować w celu zapisania za pomocą funkcji putObject(). Spowoduje to dodanie obiektu stanu do pamięci podręcznej transakcji najwyższego poziomu.
Transakcja najwyższego poziomu otworzyła instancję obiektu biznesowego do modyfikacji i zmieniła atrybut A na wartość X1, a atrybut B na wartość Y1. Utworzony obiekt stanu jest rejestrowany w celu zapisania przy użyciu funkcji putObject(). Powoduje to wstawienie go do pamięci podręcznej transakcji. Zmiany są następnie widoczne w całej transakcji
Kolejna podtransakcja również otwiera ten sam obiekt biznesowy. Ponieważ obiekt stanu istnieje dla obiektu biznesowego w pamięci podręcznej transakcji, otwarty obiekt biznesowy odnosi się do obiektu stanu w pamięci podręcznej transakcji, a zatem również do nowej zawartości atrybutów. Zmieniając atrybut C na Z1, tworzony jest nowy obiekt stanu, który jest wstawiany do obszaru pamięci podręcznej transakcji za pomocą funkcji putObject(), która rejestruje zmiany w podtransakcji. Gdy podtransakcja zostanie zatwierdzona, zarejestrowane zmiany są przenoszone do pamięci podręcznej transakcji wyższego poziomu, w tym przypadku transakcji najwyższego poziomu. Po wycofaniu są one odrzucane.
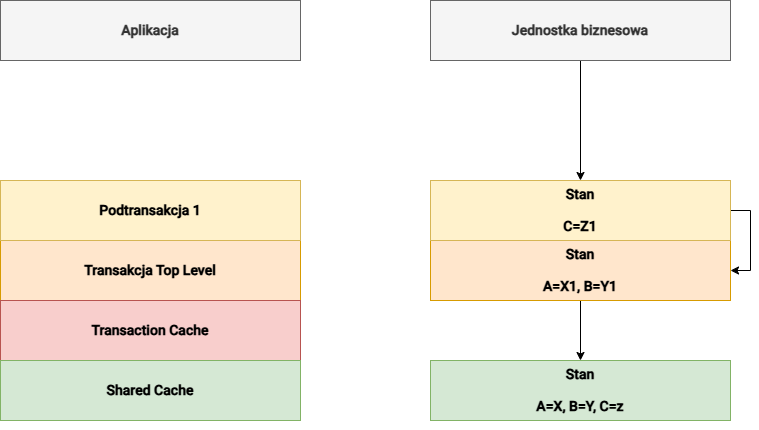
Stan po kolejnym „putObject()” tej samej instancji obiektu biznesowego
Gdy transakcja najwyższego poziomu zostanie zatwierdzona, zarejestrowane zmiany są utrwalane w pamięci podręcznej transakcji, a współdzielona pamięć podręczna jest aktualizowana.
Zależność od czasu
Wszystkie operacje odczytu Managera obiektów działają na aktualnie ważnej wersji instancji obiektu biznesowego. Persistence service zakłada, że interwały ważności wszystkich zapisanych wersji dla instancji obiektu biznesowego z tym samym kluczem podstawowym są płynne i nie nakładają się na siebie.
Persistence service rozpoznaje tryby tylko wstawiania i aktualizacji do przetwarzania obiektów biznesowych zależnych od czasu. Jeśli te dwa tryby są zawsze używane, usługa trwałości gwarantuje, że wygenerowane wersje instancji obiektu biznesowego są płynne i wolne od nakładania się. Instancje obiektów biznesowych zależnych od czasu można zapisywać lub usuwać w taki sam sposób, jak wszystkie inne obiekty biznesowe przy użyciu metod putObject() i deleteObject(). Przypisanie atrybutów validFrom i validUntil kontroluje, w którym z tych trybów obsługiwana jest zależność od czasu.
Tryb Insert-Only
Ten tryb służy do tworzenia nowej wersji instancji obiektu biznesowego. W tym celu należy utworzyć nową wersję za pośrednictwem usługi trwałości przy użyciu trybu dostępu NEW_VERSION. Atrybuty validFrom i validUntil muszą być ustawione na null przed zapisaniem wersji za pomocą funkcji putObject(), ponieważ atrybuty te są obliczane przez same Persistence service. Wygenerowana wersja jest ważna od bieżącego czasu (validFrom) do maksymalnej daty. Data validUntil poprzedniej wersji jest ustawiana na datę validFrom nowej wersji.
Przykład dołączenia nowej wersji
Tryb Update
Tryb Update służy do wstawiania nowej wersji między istniejącymi wersjami instancji obiektu biznesowego. Określany jest początek okresu ważności (validFrom) wersji, która ma zostać wstawiona; w tym przypadku jądro automatycznie ogranicza maksymalny czas ważności (validUntil) wersji ważnej w tym czasie.
Podczas korzystania z trybu aktualizacji instancja powinna zostać otwarta z trybem dostępu READ_WRITE i kluczem zależnym od czasu do utworzenia, aby uwzględnić każdą istniejącą wersję instancji obiektu biznesowego. W trybie Update atrybut validUntil musi być ustawiony na null, ponieważ jest ustawiany przez usługę trwałości.
Przykład wstawiania nowej wersji
Przetwarzanie przez aplikację
Jeśli validFrom i validUntil są ustawione dla obiektu biznesowego, tj. nie są null, wówczas Persistence service nie wykonuje żadnych dalszych operacji w celu utrzymania spójności interwałów ważności. W takim przypadku zapisywane są dokładnie określone wartości atrybutów. Persistence service nie wykonuje żadnych dalszych działań w celu zapewnienia, że nie ma nakładania się lub luk w pełnych przystankach ważności.
Schematy numeracji
Usługa trwałości obsługuje automatyczne przypisywanie numerów dla zakresów numerów. Jest to bardzo przydatne, jeśli ma zostać osiągnięte pełne przypisanie numeru. Numery są generowane tylko podczas tworzenia obiektów. Żadne nowe numery nie są przypisywane podczas aktualizacji.
Rysowanie liczb bez przerw
Przypisywanie numerów bez luk wykorzystuje funkcjonalność Persistence service, aby zapobiec występowaniu luk. Numery nie są przypisywane, dopóki powiązana transakcja najwyższego poziomu nie zostanie pomyślnie zakończona za pomocą funkcji commit(). Oznacza to, że przypisany numer nie jest wcześniej znany i nie może być jeszcze wyświetlany, np. podczas wprowadzania danych dla obiektu biznesowego. Aby Persistence service rozpoznało, że podczas tworzenia instancji obiektu biznesowego konieczna jest specjalna obsługa, definicja obiektu biznesowego musi spełniać następujące warunki:
- Logiczny typ danych dla atrybutu zakresu liczbowego musi pochodzić od logicznego typu danych com.cisag.pgm.base.numberrange.GaplessNumberRange
- Logiczny typ danych dla atrybutu schematu numeracji musi pochodzić od logicznego typu danych com.cisag.pgm.base.numberrange.GaplessNumber10 lub com.cisag.pgm.base.numberrange.GaplessNumber50
- Te dwa atrybuty razem tworzą indeks obiektu biznesowego
Podczas tworzenia instancji obiektu biznesowego deweloper musi ustawić wartość tablicy bajtów w atrybucie schematu numeracji, który jest określany przez wywołanie metody getAutoNumberRangeValue() w managerze schematu numeracji. Identyfikator GUID zakresu liczb, który ma zostać użyty, oraz informacje kontekstowe są przekazywane do tej metody jako parametry. Aby wymusić automatyczne rysowanie liczby, atrybut number jest albo ustawiony na null, albo ma przypisany identyfikator schematu. Jeśli atrybut number jest pusty, wówczas zawsze rysowana jest nowa liczba. Czasami konieczne jest przypisanie kilku instancjom obiektu biznesowego tego samego numeru dla tego samego zakresu liczb. W atrybucie number można zatem ustawić dowolny ciąg znaków, który będzie służył jako identyfikator. Persistence service używa tego samego wylosowanego numeru dla schematu numeracji dla instancji obiektów biznesowych, w których wprowadzono ten sam identyfikator. Identyfikator jest zawsze ważny dla każdej transakcji najwyższego poziomu. Po wstawieniu instancji do pamięci podręcznej transakcji za pomocą funkcji putObject() transakcja jest kończona za pomocą funkcji commit(). Podczas tworzenia instancji obiektu biznesowego, Persistence service wyszukuje zdefiniowany indeks składający się z dwóch atrybutów z wyżej wymienionymi typami danych. Po znalezieniu indeksu automatycznie przypisuje numer do przeniesionego zakresu numerów w atrybucie zakresu numerów i zapisuje go w atrybucie numeru instancji oraz w centralnej tabeli NumbersRangeUse. Jeśli numer został już przypisany do identyfikatora numeru, numer ten jest używany. Dzieje się to w ramach transakcji. Gwarantuje to, że numery są przypisywane bez luk. Jeśli kilka instancji obiektów biznesowych jest zapisywanych w ramach transakcji, można użyć specjalnego znacznika ORDERED_COMMIT, aby określić, że kolejność przypisywania numerów musi odpowiadać kolejności putObject().
W przypadku ustawienia ZERO_GUID zamiast GUID schematu numeracji, wartość ustawiona w atrybucie number jest zapisywana jako liczba.
Jeśli liczby w zakresie numerów zostaną wyczerpane, generowany jest wyjątek CisApplicationServerException typu NUMBER_RANGE_OVERFLOW. Wyjątek ten generuje odpowiedni komunikat, jeśli zostanie zapisany w dzienniku komunikatów.
W poniższym przykładzie dwie instancje obiektów biznesowych są tworzone w transakcji i każda z nich jest automatycznie przypisywana do numeru przez usługę trwałości. Kolejność, w jakiej numery są przypisywane, jest określana przez kolejność putObject().
tm.beginNew(CisTransactionManager.ORDERED_COMMIT);
try {
...
CisNumberRangeManager nrm= CisEnvironment.getInstance().getNumberRangeManager();
obj=(InventoryTransaction) om.getObject(key, CisObjectManager.READ_WRITE);
byte[] autoNumberRangeValue= nrm.getAutoNumberRangeValue(numberRangeGuid, context);
obj.setNumberRange(autoNumberRangeValue); // Ustawienie zakresu liczb i informacji kontekstowych
obj.setNumber(null); // wymusza nową liczbę
obj2=(InventoryTransaction) om.getObject(key, CisObjectManager.READ_WRITE);
autoNumberRangeValue= nrm.getAutoNumberRangeValue(numberRangeGuid, context);
obj2.setNumberRange(autoNumberRangeValue); // Ustawienie zakresu liczb i informacji kontekstowych
obj2.setNumber("Number-ID"); // wymusza nowy numer lub użycie numeru wcześniej narysowanego pod określonym Number-ID
...
om.putObject(obj2);
om.putObject(obj);
...
tm.commit() ;
} catch (RuntimeException ex) {
tm.rollback() ;
rzucać np;
}
Wyszukiwanie OQL (getOqlSearchStatement())
Wyszukiwania OQL są rejestrowane jako obiekty deweloperskie w aplikacji Obiekty deweloperskie. Wyszukiwanie OQL składa się z kolekcji fragmentów, warunków i parametrów. CisOqlSearchStatement opiera się na wyszukiwaniu OQL. Instrukcja CisOqlSearchStatement jest tworzona w Managerze obiektów przy użyciu metody:
CisOqlSearchStatement getOqlSearchStatement(String searchName); CisOqlSearchStatement getOqlSearchStatement(String searchName, String language);
Instrukcja CisOqlSearchStatement zawiera metody ustawiania wartości parametrów. Rozróżnia się parametry, które są już zawarte w definicji wyszukiwania i parametry wolne.
Wykonywanie wyszukiwania
Instrukcja CisOqlSearchStatement ma dwie metody wykonywania wyszukiwania. W obu przypadkach wynik wyszukiwania można określić na podstawie CisResultSet. Metody różnią się tym, że do jednej z nich można przekazać dodatkowy ciąg znaków, który wpływa na strukturę klauzuli WHERE wyszukiwania (patrz rozdział Dowolne parametry).
public CisResultSet execute() ; public CisResultSet execute(String pattern);
Limit czasu wyszukiwania
Podczas wykonywania wyszukiwania OQL limit czasu wyszukiwania nie jest domyślnie aktywowany. Jednak limit czasu wyszukiwania można później aktywować za pomocą opcji
public void setUseSearchTimeout(boolean useSearchTimeout);
można aktywować. Jeśli limit czasu wyszukiwania jest aktywny, wykonanie zapytania do bazy danych wywołanego przez wyszukiwanie OQL jest anulowane po upływie limitu czasu wyszukiwania ustawionego dla bazy danych w panelu systemu, jeśli zapytanie do bazy danych nie wyświetliło wyniku w ciągu limitu czasu wyszukiwania. Gdy zapytanie do bazy danych jest anulowane, generowany jest wyjątek CisApplicationServerException typu SEARCH_TIMEOUT. Może on zostać zarejestrowany i specjalnie obsłużony przez aplikację.
Ustawianie parametrów
Wszystkie parametry wyszukiwania są zdefiniowane w definicji wyszukiwania. Każdy parametr ma unikalną nazwę w wyszukiwaniu. Poszczególne parametry są używane jako kryterium ograniczające w wyszukiwaniu i łączone za pomocą AND.
Każdemu parametrowi wyszukiwania można przypisać więcej niż jedną wartość. Poszczególne wartości parametru są połączone za pomocą OR. Parametr, któremu nie przypisano wartości, nie jest uwzględniany w wyszukiwaniu jako kryterium ograniczające.
Wyszukiwanie ma parametry a, b, c, d. Parametrowi a należy przypisać wartości 1, 2, 4, a parametrowi b wartości 10, 20. Parametrom c i d nie przypisuje się żadnych wartości. Przypisanie parametrów
prowadzi do następującego wyrażenia: (a = 1 OR a = 2 OR a = 4) AND (b = 10 OR b = 20)
Instrukcja CisOqlSearchStatement udostępnia metody dla różnych typów danych w celu ustawienia indywidualnych wartości dla parametru wyszukiwania.
Podpisy metod wybrane jako przykłady mogą być używane do ustawiania indywidualnych wartości long i int dla parametru:
public void setLongSelection(String name, long value); public void setIntSelection(String name, int value);
Jeśli dla parametru ma zostać ustawionych kilka wartości lub zakresów, należy utworzyć ciąg zapytania przy użyciu klasy com.cisag.pgm.objsearch.SelectionSupport i przekazać go do metody setSelection(…).
Dowolne parametry
Oprócz parametrów określonych w definicji wyszukiwania, można zdefiniować dalsze wolne parametry i przypisać je do CisOqlSearchStatement.
W przeciwieństwie do parametrów stałych, dla parametrów wolnych nie są używane ciągi zapytań. W związku z tym metody ustawiania wolnych parametrów nie kończą się na Selection.
public void setLong(String name, long value); public void setInt(String name, int value);
Dowolne parametry są zdefiniowane w łańcuchu znaków, który jest dołączany do klauzuli WHERE instrukcji CisOqlSearchStatement podczas wykonywania wyszukiwania. Ciąg znaków zawiera symbole zastępcze dla używanych parametrów. Nazwy symboli zastępczych odpowiadają nazwom parametrów.
Korzystanie z dodatkowego wzorca wyszukiwania
Instrukcja CisOqlSearchStatement oferuje dwie metody wykonywania wyszukiwania. Jednej z metod można przekazać ciąg znaków, który wpływa na klauzulę WHERE wyszukiwania OQL.
Ciąg zawiera wyrażenie OQL, które może być również używane w klauzuli WHERE. Parametry wyszukiwania, normalne i dowolne, mogą być osadzone w wyrażeniu. Aby to zrobić, należy umieścić nazwę parametru w nawiasach klamrowych jako symbol zastępczy w żądanych pozycjach.
Dowolne parametry są zawsze używane jako wartość, a normalne parametry jako wyrażenie logiczne.
Dowolny parametr number powinien mieć przypisaną wartość 0815 dla atrybutu ac:name.
stm.setString("numer", "0815");
stm.execute("ac:name={number});
Normalne parametry code i name nie powinny być łączone za pomocą AND, ale za pomocą OR.
stm.execute("({code} LUB {name})");
Jeśli w wyrażeniu OQL używane są normalne parametry, nie są one już uwzględniane w normalnym łączeniu parametrów.
Parametry A, B, C i D są zdefiniowane w wyszukiwaniu i mają przypisane wartości. Zazwyczaj parametry są połączone za pomocą AND: A AND B AND C AND D. Jeśli parametry C i D są używane w wyrażeniu OQL, np. ({C} OR {D}), tylko A i B są połączone, a wyrażenie OQL jest dołączane: A AND B AND (C OR D).
Restart
Z reguły wyszukiwanie nigdy nie zwraca wszystkich rekordów danych. Zamiast tego odczytywana jest tylko ograniczona liczba rekordów danych. W dostarczonych wizualizacjach wyszukiwania, np. wyszukiwanie dialogowe, pomoc wartości aplikacji itp. liczba ta jest ograniczona do 60 rekordów danych. W przypadku aplikacji zapytań liczba rekordów danych zależy od dostępnego miejsca w interfejsie. Jeśli wymagana jest większa liczba rekordów danych, wyszukiwanie musi zostać wznowione od starej pozycji i wczytać kolejne rekordy danych.
Aby możliwe było ponowne uruchomienie, każdy ze znalezionych rekordów danych musi być unikalny dla zastosowanego sortowania, tj. parametry użyte w sortowaniu, które muszą być również wartościami zwracanymi, tworzą unikalny klucz do określenia rekordu danych. Jeśli ten wymóg jest spełniony, można skonfigurować warunek przy użyciu parametrów sortowania i wartości zwracanych ostatniego znalezionego rekordu danych w celu określenia następnego rekordu danych do ponownego uruchomienia.
Więcej informacji na temat tworzenia warunku można znaleźć w dokumentacji Podręcznik referencji: Wyszukiwanie.
Instrukcja CisOqlSearchStatement zawiera dwie metody ponownego uruchamiania wyszukiwania. Metoda setContinuePosition(…) służy do ustawiania pozycji dla ponownego uruchomienia. Do metody można przekazać CisResultSet. Wartości parametrów istotnych dla sortowania są odczytywane i kompilowane do warunku zgodnie z opisaną procedurą. Następnie należy zamknąć CisResultSet.
Jeśli metoda continueExecute(…) zostanie wywołana później, wyszukiwanie będzie kontynuowane z warunkiem utworzonym dla ponownego uruchomienia. Jeśli metoda zostanie wywołana bez wcześniejszego określenia pozycji dla ponownego uruchomienia, zostanie zgłoszony wyjątek.
public void setContinuePosition(CisResultSet rs) throws SQLException; public CisResultSet continueExecute() ;
Dołączanie unikalnego klucza
Jeśli wybrane parametry sortowania nie są wystarczające do określenia unikalnej pozycji dla restartu, można sztucznie dodać dodatkowe parametry. Są to parametry oznaczone jako atrybuty kluczowe w definicji wyszukiwania. Parametry z tym wskaźnikiem byłyby wystarczające do jednoznacznego określenia rekordu danych.
Aby uwzględnić te parametry w warunku ponownego uruchomienia, należy przekazać wartość true do metody setAppendUnqiuekey(…).
public void setAppendUnqiueKey(boolean appendUniqueKey);
Fragmenty
Definicja wyszukiwania OQL składa się z co najmniej jednego głównego fragmentu i zestawu parametrów, które są zdefiniowane w tym głównym fragmencie.
W definicji wyszukiwania można zdefiniować dodatkowe fragmenty i powiązane z nimi parametry. Fragmenty te powinny być zawsze powiązane z głównym fragmentem za pomocą outer join.
Różnica w stosunku do głównego fragmentu polega na tym, że te fragmenty są dodawane do wyszukiwania tylko wtedy, gdy co najmniej jeden ze zdefiniowanych parametrów jest używany do wyszukiwania, np. do zapytania lub sortowania. Jeśli parametry nie są używane, cały fragment jest pomijany. Wynikowe wyrażenie OQL jest krótsze, a zatem mniej złożone. Zwiększa to wydajność zapytania.
Definicja wyszukiwania ma główny i dodatkowy fragment. Główny fragment jest zdefiniowany w następujący sposób:
{base = com.cisag.app.test.AEntity A}
Atrybuty A:a, A:b, A:c są używane pod nazwami parametrów a, b, c dla zapytania.
Drugi fragment jest zdefiniowany w następujący sposób:
{base} LEFT OUTER JOIN com.cisag.app.test.BEntity B
Atrybuty B:e, B:f są używane pod nazwami parametrów e, f dla zapytania.
Jeśli dla parametrów e lub f zapytania zapisane są wartości, otrzymamy następujący wynik OQL:
SELECT ... FROM com.cisag.app.test.AEntity A LEFT OUTER JOIN com.cisag.app.test.BEntity B ON A:bguid = B:guid WHERE B:e = ... ORDER BY ...
Jeśli jednak nie są używane żadne parametry z drugiego fragmentu, OQL jest skracany do następującego wyrażenia:
SELECT ... FROM com.cisag.app.test.AEntity A WHERE A:a = ... ORDER BY ...
Ograniczenia
Poniżej wymieniono ograniczenia dotyczące korzystania z Persistence service.
Typ danych SBlob
Typ danych systemu ERP SBlob jest dostępny tylko do użytku wewnętrznego w Comarch ERP Enterprise. W przyszłości, ten typ danych nie będzie obsługiwany – jego stosowanie nie jest zalecane. Alternatywą jest korzystanie z plików za pośrednictwem Knowledge Store.
Typ danych systemu ERP SBlob (Streamable Blob) to specjalny typ danych do przechowywania dużych ilości danych binarnych. Zaletą jest to, że Persistence service nigdy nie przechowuje danych w całości w pamięci głównej. Ten typ danych jest używany, gdy dane binarne są tak duże, że zużycie pamięci głównej w celu pełnego załadowania zestawu danych na serwerze aplikacji nie jest już uzasadnione.
Klasa com.cisag.pgm.datatype.CisStreamableBlob może być używana do odpytywania zarówno InputStream do odczytu danych typu blob, jak i OutputStream do zapisu.
Następujące ograniczenia mają zastosowanie do korzystania ze strumieniowych obiektów blob:
- Streamable blobs mogą być zapisywane tylko raz na transakcję
- Streamable blobs mogą być zapisywane tylko na poziomie pierwszej transakcji, tj. nie w podtransakcjach
- Streamable blobs mogą być ponownie odczytane dopiero po potwierdzeniu transakcji przez commit
Usługa blokady
Usługa blokady zarządza blokadami logicznymi i blokadami obiektów biznesowych. Blokady wszystkich serwerów aplikacji w systemie są zarządzane centralnie na serwerze komunikatów.
W systemie z wieloma użytkownikami konieczne jest regulowanie korzystania ze współdzielonych zasobów. Blokada służy do synchronizacji dostępu do ograniczonego zasobu. Zasoby te to zazwyczaj jedna lub więcej instancji obiektów biznesowych. Każda blokada jest wymagana dla zasobu w określonym kontekście blokady.
Wszystkie blokady są wydawane przez centralną usługę blokady. Gdy blokada jest wymagana, żądanie jest wysyłane do usługi blokady. Usługa blokady albo przyznaje tę blokadę, albo odrzuca żądanie blokady. Blokada pozostaje na miejscu do momentu jej jawnego zwolnienia lub zwolnienia kontekstu blokady.
Konteksty blokady
Blokady są zawsze wymagane w kontekście blokady. Możliwe konteksty blokady to transakcje, instancje aplikacji i sesje. Istnienie blokady jest powiązane z odpowiednim kontekstem blokady. Jeśli blokada została zażądana w ramach transakcji, jest ona zwalniana po zakończeniu transakcji (z zatwierdzeniem lub wycofaniem). Konteksty blokady mają następujące zależności:
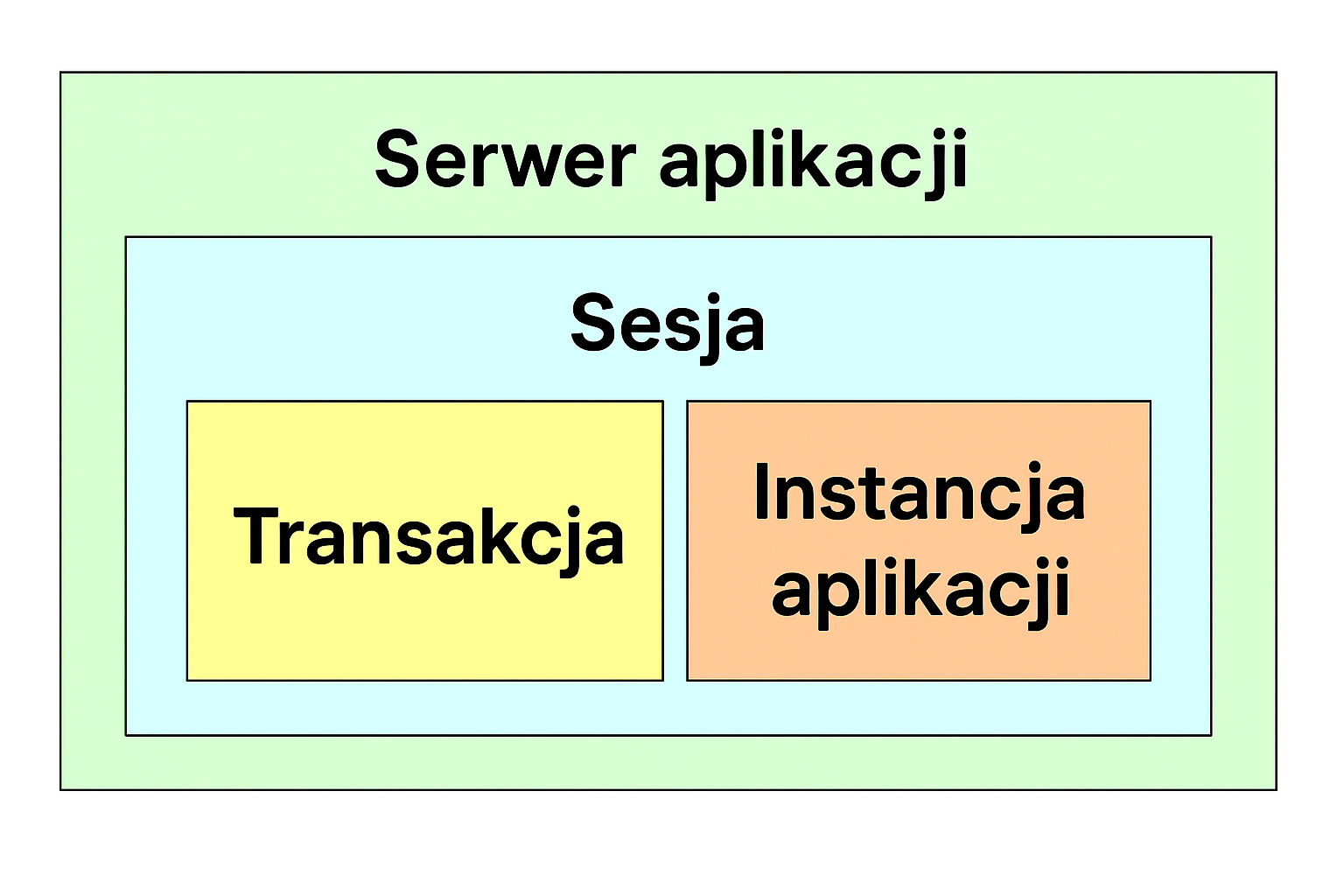
Na ilustracji wewnętrzne konteksty są egzystencjalnie powiązane z zewnętrznymi kontekstami blokad. Na przykład, jeśli sesja zostanie zakończona, wszystkie blokady na poziomie transakcji i instancji aplikacji , które zostały zażądane w tej sesji, zostaną również zwolnione. Jeśli serwer aplikacji zostanie zakończony, wszystkie blokady żądane przez serwer aplikacji zostaną zwolnione.
Rodzaje blokad
Następujące typy blokad są widoczne dla dewelopera aplikacji w Persistence service.
Blokady logiczne
Blokady logiczne są identyfikowane przez ciąg znaków. Nie blokują one żadnych zasobów, które są bezpośrednio rozpoznawalne dla Persistence service, ale mają znaczenie tylko dla aplikacji, która z nich korzysta. Blokady logiczne są
- wyłączne, tzn. tylko jeden kontekst może posiadać wyłączną blokadę logiczną w danym momencie,
lub
- niewyłączne, tj. dowolna liczba kontekstów może jednocześnie posiadać niewyłączne blokady logiczne.
Blokady logiczne są zawsze wyraźnie wymagane przez aplikację. Kontekstem blokady logicznej jest zazwyczaj instancja aplikacji.
Blokady instancji
Blokady instancji są niejawnie wymagane przez usługę trwałości dla poszczególnych instancji obiektów biznesowych w zależności od trybu dostępu. Wszystkie blokady instancji są wymagane w kontekście blokady transakcji najwyższego poziomu.
W trybie dostępu READ_REPEATABLE wymagana jest blokada instancji odczytu. Dowolna liczba transakcji najwyższego poziomu może posiadać blokadę instancji odczytu w tym samym czasie.
Blokada instancji zapisu jest wymagana dla trybu dostępu READ_UPDATE, READ_WRITE lub INSERT. Tylko transakcja Top Level może posiadać blokadę instancji zapisu w dowolnym momencie.
Tylko jedna blokada zapisu instancji lub dowolna liczba blokad odczytu instancji może zostać zażądana na instancji obiektu biznesowego. Blokady instancji są zwalniane dopiero po zakończeniu transakcji najwyższego poziomu. Oznacza to np. że jeśli transakcja zostanie zakończona za pomocą funkcji commit(), zmienione obiekty zostaną zapisane w bazie danych i dopiero wtedy blokady instancji zostaną zwolnione.
Blokady tablicy
Podczas korzystania z metody getUpdateStatement() blokada zapisu tabeli jest wymagana niejawnie. Obejmuje ona całą tabelę, tj. wszystkie instancje obiektów biznesowych danego typu w bazie danych. Tylko jedna transakcja najwyższego poziomu w danym momencie może posiadać blokadę zapisu tabeli. Blokady tabel są zwalniane dopiero po zakończeniu transakcji najwyższego poziomu. Oznacza to, że po zakończeniu transakcji za pomocą funkcji commit(), instrukcje aktualizacji są wykonywane w bazie danych i dopiero wtedy blokady tabel są zwalniane.
Blokady jednostek biznesowych
W przypadku gdy podmioty zależne jednostki biznesowej są odpowiednie dla blokad jednostki biznesowej, to jeśli wymagana jest blokada instancji dla podmiotu zależnego, zamiast tego wymagana jest blokada dla powiązanego podmiotu biznesowego. W szczególności, jeśli kilka blokad instancji jest żądanych dla podmiotów zależnych tej samej instancji jednostki biznesowej, tylko jedno żądanie blokady musi zostać przetworzone dla jednostki biznesowej. Blokady instancji podmiotów zależnych są przetwarzane w żądaniu blokady po zakończeniu transakcji.
Aby jednostka zależna obsługiwała blokady jednostek biznesowych, klucz podstawowy jednostki zależnej musi zaczynać się od klucza obcego dla klucza podstawowego jednostki biznesowej.
Jednostka biznesowa E posiada klucz podstawowy guid. Podmiot zależny D przechowuje klucz główny E w atrybucie header.
Jeśli klucz podstawowy D składa się z atrybutów header i detailGuid, wówczas D nadaje się do blokowania encji biznesowej.
Jeśli klucz podstawowy D składa się tylko z atrybutu detailGuid, wówczas D nie nadaje się do blokowania encji biznesowej.
Blokady jednostek biznesowych powinny być brane pod uwagę przy projektowaniu modelu danych, szczególnie w przypadku jednostek biznesowych z dużą liczbą podmiotów zależnych.
Synchronizacja współdzielonych pamięci podręcznych (Shared Caches)
Blokady obiektów biznesowych służą do synchronizacji pamięci podręcznej serwerów aplikacji w systemie. Za każdym razem, gdy dla instancji obiektu biznesowego zostanie zażądana blokada instancji zapisu, zakłada się, że instancja zostanie również zmieniona. W regularnych odstępach czasu (zazwyczaj co 5 sekund) wszystkie instancje obiektów biznesowych są usuwane ze współdzielonych pamięci podręcznych wszystkich serwerów aplikacji, których blokada instancji zapisu została zwolniona. W pamięci podręcznej serwera aplikacji, który wprowadził zmianę, instancje pozostają w pamięci podręcznej, ponieważ ten serwer aplikacji posiada aktualnie ważną wersję instancji.
Gdy blokady tabel zapisu są zwalniane, wszystkie instancje obiektów biznesowych są usuwane ze współdzielonej pamięci podręcznej wszystkich serwerów aplikacji w tych samych regularnych odstępach czasu w całym systemie.
Blokady logiczne
Blokady logiczne blokują dowolny zasób. Zasoby te są zazwyczaj zestawem instancji obiektów biznesowych, które nie mogą być zmieniane przez określony czas. Dzieje się tak, gdy złożona i rozległa operacja jest podzielona na kilka transakcji najwyższego poziomu. Odpowiednie transakcje najwyższego poziomu mogą czasami pozostawiać niespójne stany w bazie danych. Blokady instancji mają transakcję najwyższego poziomu jako kontekst blokady. Jeśli istnieje kilka kolejnych transakcji Top Level, możliwe jest, że inne sesje uzyskają dostęp do wcześniej zablokowanych i prawdopodobnie niespójnych obiektów między transakcjami. Tę złożoną operację można zabezpieczyć za pomocą blokady logicznej. Jednak aby to zadziałało, blokada logiczna musi być jawnie wymagana za każdym razem, gdy uzyskuje się dostęp do zablokowanych instancji obiektów biznesowych. Usługa trwałości nie zna relacji między blokadą a instancjami obiektów biznesowych i nie może sprawdzić blokady w sposób niejawny.
Blokady logiczne są zwykle wymagane w kontekście blokady instancji aplikacji. Te logiczne blokady mogą być tworzone przy użyciu funkcji
public acquireLock(String value); public acquireLock(String value, byte use);
managera aplikacji. Opcjonalny parametr use określa, czy należy zażądać blokady wyłącznej czy niewyłącznej. Tak długo, jak instancja aplikacji posiada wyłączną blokadę na ciągu znaków value, żadna inna wyłączna lub niewyłączna blokada nie jest przyznawana na tym samym ciągu znaków. Jeśli instancja aplikacji posiada blokadę niewyłączną na ciągu znaków value, wszelkie dalsze blokady niewyłączne żądane bezpośrednio po tym są przyznawane na tym samym ciągu znaków. Jeśli opcjonalny parametr use nie jest określony, żądana jest blokada wyłączna. Wartość zwrotna funkcji acquireLock() określa, czy blokada została przyznana, czy odrzucona. Jeśli blokada została odrzucona, można użyć funkcji
public String getLockInformation(String value);
Informacje o tym, który użytkownik posiada blokadę, można uzyskać za pomocą metody getLockInformation(). Metoda getLockInformation() nie może być wywoływana, jeśli blokada została pomyślnie przyznana, ponieważ metoda ta może zwolnić blokadę.
Instancja aplikacji jest odpowiedzialna za przywrócenie każdej blokady logicznej, której zażądała za pomocą
public void releaseLock( String value );
Jeśli instancja aplikacji nie zwolni żądanych blokad, inne instancje aplikacji nie mogą pomyślnie zażądać blokady, a zatem nie mogą uzyskać dostępu do zablokowanego zasobu.
Przełączanie awaryjne bazy danych
Większość systemów zarządzania bazami danych (DBMS) posiada mechanizmy przełączania awaryjnego. Oznacza to, że kilka instancji bazy danych działa równolegle w tej samej bazie danych lub w lustrzanej bazie danych. Jeśli instancja bazy danych nie jest już dostępna z powodu błędu, inna instancja bazy danych może przejąć zadania uszkodzonej instancji. Często istnieje kilka opcji konfiguracji przełączania awaryjnego dla systemu bazy danych w ramach systemu DBMS. Obsługiwane konfiguracje można znaleźć w dokumentacji instalacyjnej.
Persistence service utrzymuje wszystkie połączenia z jedną instancją bazy danych na bazę danych systemu ERP we wspólnej puli. Jeśli serwer aplikacji wymaga połączenia, wszystkie połączenia w puli są już używane, a maksymalna liczba połączeń w puli nie została jeszcze osiągnięta, nowe połączenie jest otwierane i rejestrowane w puli. Jeśli baza danych zgłosi błąd, dane połączenie zostanie zamknięte.
Jeśli Persistence service rozpozna na podstawie komunikatu o błędzie, że instancja bazy danych nie powiodła się, wszystkie otwarte nieaktywne połączenia z bazą danych są zamykane i ponownie otwierane po okresie oczekiwania. Operacja aktualnie wykonywana w aktywnym połączeniu z bazą danych jest anulowana z komunikatem o błędzie, jeśli instancja bazy danych ulegnie awarii. Persistence service rozpoznaje ten komunikat o błędzie i próbuje ponownie wykonać operację z nowym połączeniem z bazą danych. Następujące operacje nie mogą zostać wykonane ponownie:
- Zakończenie transakcji bazy danych przez commit
- Przeszukanie następnego zestawu danych w już otwartym ResultSet lub ObjectIterator
- Modyfikacje schematu danych, np. za pomocą crtbo lub upgaps
Jeśli połączenie z bazą danych zostanie przerwane podczas jednej z tych operacji, generowany jest wyjątek CisApplicationServerException typu DATABASE_CONNECTION_LOST. Wyjątek ten może być specjalnie obsługiwany przez aplikacje. Przykładowo, transakcje zapisu powinny zostać powtórzone, jeśli wystąpi ten wyjątek. Wyjątek ten jest również zgłaszany dla innych operacji, jeśli nie można ponownie nawiązać połączenia z bazą danych.
Dziennik zmian
Dziennik zmian jest funkcją dziennika dla historii zmiennych biznesowych i rejestruje zdarzenia w cyklu jednostek biznesowych. Dla każdej jednostki biznesowej i instancji bazy danych można określić, czy zmiany powinny być rejestrowane. Persistence service dba zatem nie tylko o informacje o zmianach dla podmiotów biznesowych, ale także o wpisy w dzienniku zmian. Rejestrowane są tylko pomyślnie zakończone transakcje Top Level.
Artykuł Dziennik zmian zawiera dalsze informacje.
Lista transferu
W przeciwieństwie do dziennika zmian, lista transferu rejestruje tylko, że instancja jednostki biznesowej została zmieniona od czasu ostatniego przetworzenia tej instancji. Lista transferu może być używana w szczególności podczas wymiany danych z systemami zewnętrznymi.
Artykuł Dziennik zmian zawiera dalsze informacje.
Update Listener
W szczególności podczas wymiany danych z systemami zewnętrznymi pomocna jest informacja, czy obiekt biznesowy został zmieniony w określonym czasie. Wymiana danych z systemem zewnętrznym musi zostać uruchomiona tylko wtedy, gdy nastąpiła zmiana. Update Listener może być teraz użyty do sprawdzenia dokładnie tego.
Update Listener jest tworzony w CisSystemManager przy użyciu metody createUpdateListener. Baza danych, która ma być monitorowana i obiekty biznesowe, które mają być monitorowane są zdefiniowane.
Metoda getUpdateTimeStamps może być używana w Update Listener w celu sprawdzenia, które obiekty biznesowe są monitorowane przez Update Listener i czy te obiekty biznesowe zostały zmienione od czasu ostatniego wywołania metod waitUpdate lub checkUpdate. Metoda isChanged zwraca wartość true, jeśli instancja obiektu biznesowego została zmieniona. Metoda etTimeStamp zwraca czas, w którym zmiana została przetworzona przez detektor aktualizacji. Czas ten zazwyczaj różni się od czasu podanego w UpdateInfo.
Update Listener mogą być używane razem z listą transferową. Słuchacz aktualizacji zgłasza, że instancja obiektu biznesowego została zmieniona, a lista transferów pokazuje, która instancja została zmieniona. Więcej informacji można znaleźć w rozdziale Lista transferu.
Należy pamiętać, że Update Listener monitoruje zmiany tylko po jego utworzeniu. Wszystkie zmiany w monitorowanych obiektach biznesowych, które miały miejsce przed utworzeniem słuchacza aktualizacji, nie powodują, że isChanged wyświetla wartość true.
Po utworzeniu Update Listener należy zatem założyć, że wszystkie obiekty biznesowe zostały zmienione przed utworzeniem Update Listener.
byte[] databaseGuid =
tm.getDatabaseGuid(CisTransactionManager.OLTP);
Class[] classes = new Class[] {
Partner.class, Item.class
};
CisUpdateListener updateListener = sm.createUpdateListener(
databaseGuid, classes );
try {
// Przetwarzanie wszystkich danych przed Update listener
// Zmienione obiekty
for (UpdateTimeStamp updateTimeStamp :
updateListener.getUpdateTimeStamps()) {
process(updateTimeStamp.getClassGuid());
}
while (! env.isToBeRemoved()) {
// Odczekaj co najmniej 30 sekund pomiędzy dwoma krokami przetwarzania.
// kroki
wait(30000);
// Oczekiwanie na zmianę przez nieskończenie długi czas
if (updateListener.waitUpdate(0)) {
// Przetwarzanie wszystkich zmienionych obiektów
for (UpdateTimeStamp updateTimeStamp :
updateListener.getUpdateTimeStamps()) {
if (updateTimeStamp.isChanged()) {
process(updateTimeStamp.getClassGuid());
}
}
}
}
} finally {
updateListener.deregister();
}



