Wprowadzenie
Opis
Niniejszy dokument zawiera podstawowe pojęcia i metody pracy wymagane podczas tworzenia aplikacji dialogowych w Comarch ERP Enterprise.
Grupa docelowa
Grupą docelową są programiści ze znajomością języka Java, którzy chcą zapoznać się z procesem tworzenia aplikacji dialogowych i poznać założenia Comarch ERP Enterprise.
Skróty
API Application Programming Interface
BO Business Object
BOD Business Object Definition
DB Baza danych
DHTML Dynamic HTML
GUI Graphical User Interface
GUID Global Unique IDentifier
HTML Hyper Text Markup Language
JDK Java Development Kit
JVM Java Virtual Machine
IDE Integrated Development Environment
MM Message Manager
NLS National Language Support
LDT Logiczny typ danych
OLTP Online Transaction Processing
OLAP Online Analytical Processing
OM Object Manager
OQL Object Query Language
SAS ERP System Application Server
SDK ERP System Development Kit
SOM ERP System Output Manager
SQL Structured Query Language
TM Transaction Manager
UI User Interface
URI Uniform Resource Identifier
URL Uniform Resource Locator
VE Visual Element
VEC Visual Element Container
Wymagania wstępne
Na potrzeby prezentacji wymagany jest system Comarch ERP Enterprise i skonfigurowane środowisko programistyczne (Eclipse).
Architektura klienta/serwera
System ERP został opracowany zgodnie z 3-warstwową architekturą i zasadniczo składa się z następujących trzech warstw. W nawiasach podano realizujący komponent oprogramowania:
- graficzny interfejs użytkownika (przeglądarka)
- logika aplikacji (serwer aplikacji systemu ERP)
- przechowywanie danych (system zarządzania bazą danych)
Taki podział zapewnia optymalne opcje konfigurowania i skalowania, ponieważ warstwy są od siebie niezależne. Graficzny interfejs użytkownika definiuje interfejsy dla interakcji użytkownika. Logika aplikacji stanowi połączenie graficznego interfejsu użytkownika z przechowywaniem danych. Platformą wykonawczą jest serwer aplikacji systemu ERP (SAS), który wymaga wirtualnej maszyny Java (JVM). Dzięki oddzieleniu warstw, różne zrealizowane interfejsy użytkownika mogą korzystać z tej samej logiki aplikacji dla tych samych funkcji aplikacji.
Interfejs użytkownika
System ERP posiada graficzny interfejs użytkownika (Graphical User Interface, w skrócie GUI), który może być wyświetlany po stronie klienta w przeglądarce Internet Explorer. Użytkownik może poruszać się zarówno po intranecie, jak i Internecie, ponieważ uzyskuje dostęp do systemu ERP za pomocą swojego klienta poprzez połączenie TCP/IP.
Logika aplikacji
Logika aplikacji tworzy warstwę środkową w architekturze 3-warstwowej. To tutaj znajdują się wszelkie aplikacje biznesowe. Serwer aplikacji systemu ERP (SAS) korzysta z różnych usług systemowych silnika systemu, takich jak:
- Zarządzanie pamięcią podręczną
- Obsługa transakcji
- Obsługa ciągłości
- Obsługa zdarzeń
- Usługa licencyjna
- Przetwarzanie w tle
- Dziennik zmian
- Usługa blokowania
- Zlecenia wydania
- Web Server
Klienci komunikują się z SAS za pomocą protokołu HTTP/HTTP za pośrednictwem serwera WWW dostosowanego do wymagań systemu ERP. Liczba SAS w ramach systemu ERP zależy od struktury organizacyjnej firmy i liczby użytkowników.
Każdy użytkownik wymaga określonej przestrzeni dyskowej w SAS, np. dla danych aplikacji itp. Zasoby dostępne dla każdego SAS są ograniczone, co skutkuje odpowiednim górnym limitem liczby użytkowników na SAS. Procesy wymagające dużej mocy obliczeniowej, np. ODBC, serwer logistyki magazynowej, również powinny być obsługiwane w oddzielnym SAS.
Każdy użytkownik wymaga określonej przestrzeni dyskowej w SAS, np. dla danych aplikacji itp. Zasoby dostępne dla każdego SAS są ograniczone, co skutkuje odpowiednim górnym limitem liczby użytkowników na SAS. Procesy wymagające dużej mocy obliczeniowej, np. ODBC, serwer logistyki magazynowej, również powinny być obsługiwane w oddzielnym SAS.
Innym powodem podziału na kilka SAS jest garbage collector dla JVM. Każdy SAS ma własne JVM. W określonych odstępach czasu garbage collector usuwa niepotrzebne obiekty. Dzięki temu zwalnia się pamięć na potrzeby innych procesów. Nowoczesne garbage collectory wykonują to zadanie równolegle z innymi uruchomionymi procesami. W pewnych sytuacjach, np. gdy kończy się miejsce w pamięci, inne procesy są zatrzymywane, aby garbage collector miał wystarczająco dużo czasu na zwolnienie miejsca w pamięci. Zamiast jednego dużego SAS, lepiej jest pracować na kilku mniejszych SAS. Ponieważ pamięć każdego SAS jest mniejsza, garbage collector potrzebuje również mniej czasu na każdy SAS. Logika aplikacji działa w określonym środowisku. Ważnymi terminami w tym kontekście są session, thread i transaction.
Session (sesja)
Sesje to oddzielne obszary robocze, z których każdy zawiera zestaw obiektów. Sesja reprezentuje korzeń grafu obiektów i definiuje kontekst wszystkich działań w systemie ERP. Rozróżnia się sesje interaktywne i sesje nieinteraktywne. Sesje interaktywne zawierają informacje o aktywnych aplikacjach w przeglądarce, uwierzytelnianiu użytkownika i wszystkich powiązanych zasobach. Zasadniczo sesja może pomieścić dowolną liczbę instancji aplikacji. Sesje nieinteraktywne rozpoczynają się wraz z uruchomieniem usługi lub zlecenia przetwarzania. Sesje kończą się wylogowaniem użytkownika lub w wyniku błędu połączenia po przekroczeniu limitu czasu. Wszystkie zajęte zasoby, takie jak pamięć i blokady, są ponownie zwalniane najpóźniej w momencie zakończenia sesji.
Thread (wątek)
Wątek jest wymagany do opracowania działań lub zgłoszeń uruchamianych w ramach sesji. Wątki są równoległymi jednostkami wykonawczymi, które są przypisane do sesji na czas opracowania zgłoszenia. Sesja przekazuje do wątku to, co ma zostać opracowane. Wątek przejmuje opracowanie i zwraca wynik. Oznacza to, że wątek jest wymagany dla sesji tylko podczas aktywnego opracowania. Aby skutecznie rozdzielać ograniczone zasoby, stopniowo budowana jest pula wątków. W razie potrzeby z tej puli można przypisać do jednej sesji kilka wątków.
Z perspektywy dewelopera aplikacji zawsze tylko jeden wątek jest aktywny. Oznacza to, że deweloper nie musi się zajmować synchronizacją wątków. Wątki mają przypisane priorytety realizacji, np. można ustawić wyższy priorytet dla przetwarzania dialogu i niższy priorytet dla przetwarzania w tle. Wątek wraz z przyporządkowaną sesją stanowią
środowisko pracy, w którym np. uruchamiane są transakcje i zgłaszane blokady.
Wątki są udostępniane przez maszynę wirtualną JAVA™, która w razie potrzeby rozdziela wątki do wielu procesorów.
Transaction (transakcja)
Sesja może zawierać kilka tzw. transakcji Toplevel. Transakcja zazwyczaj zawiera sekwencję operacji na instancjach obiektów biznesowych. Transakcja jest używana do utworzenia jednostki. Jednostka ta jest realizowana w całości lub unieważniania, w celu przywrócenia zmienionych danych do spójnego stanu. System ERP posiada
własny mechanizm zarządzania transakcjami, który obsługuje zagnieżdżone transakcje.
Po rozpoczęciu sesji w bazie danych OLTP automatycznie otwierana jest transakcja (transakcja dummy), aby umożliwić deweloperowi aplikacji dostęp do odczytu instancji obiektów biznesowych. Modyfikacja instancji musi odbywać się w ramach nowej transakcji, która jest otwierana za pomocą menedżera transakcji. Aby uzyskać dostęp do instancji obiektów biznesowych w transakcji, deweloper aplikacji może użyć Object Manager lub Object Query Language (OQL).
Podczas modyfikacji instancji obiektu biznesowego system ERP blokuje automatycznie ten obiekt. Dzięki temu nie jest możliwa modyfikacja tego samego obiektu biznesowego przez inne transakcje.
Do komunikacji z bazą danych wykorzystywana jest pula połączeń z bazą danych. W celu przesłania danych wymagane jest uzyskanie połączenia z tej puli połączeń i otwarcie transakcji bazy danych. Dopiero po pomyślnym potwierdzeniu transakcji bazy danych przez commit lub po anulowaniu przez rollback transakcja Toplevel będzie rzeczywiście zakończona w systemie ERP. Oznacza to, że blokady na obiektach biznesowych są zwalniane dopiero wtedy, gdy transakcja Toplevel będzie ponownie zwolniona.
Obsługa zasobów
Skalowalność i wydajność systemu klient-serwer zależą od tego, w jaki sposób obsługiwane są ograniczone lub kosztowne zasoby. Podstawowe zasady są dwie:
- wspólne, naprzemienne korzystanie z ograniczonych zasobów
- pooling kosztownych zasobów
Serwer sieci web używa puli wątków do przetwarzania przychodzących zgłoszeń ze stałą liczbą wątków. Umożliwia to
równomierne rozłożenie obciążenia na serwerze aplikacji systemu ERP i uniknięcie generowania kosztownego zasobu. Na tej samej zasadzie zapytania sesji do bazy danych rozdzielane są na stałą liczbę połączeń z bazą danych. Oznacza to redukcję kosztów (overhead) związanych z żądaniem połączenia z bazą danych.
Przechowywanie danych
Trzecia warstwa obejmuje przechowywanie danych w relacyjnych bazach danych. Obsługiwane są systemy zarządzania bazami danych (DBMS) Oracle®, MS-SQL-Server i DB2/AS400®.
W celu wydajnego przechowywania danych stosowany jest następujący sposób partycjonowania:
- Baza danych konfiguracji systemu
- Baza danych repozytorium
- Baza danych Online Transaction Profession (OLTP)
- Baza danych Online Analytical Processing (OLAP)
Ten układ bazy danych daje możliwość rozdzielenia określonych zestawów danych do różnych systemów zarządzania bazami, co zapewnia odpowiednią elastyczność i skalowalność.
Zwiększenie wydajności wynika z zarządzania podobnymi zestawami danych w poszczególnych bazach danych. Widać to już po podobnym przebiegu zmian w poszczególnych bazach danych: zestawy danych w bazie danych repozytorium prawie nigdy nie są zmieniane w czasie działania systemu, podczas gdy te w bazie danych OLTP są zmieniane na bieżąco.
Podczas rozwoju systemu ERP skupiono się na szybkim dostępie do danych z baz danych w celu uzyskania krótkich czasów reakcji. Dlatego system ERP wykorzystuje tylko niezbędne mechanizmy relacyjnych systemów zarządzania bazami danych. Obejmują one wydajne trwałe przechowywanie danych i zoptymalizowane wykonywanie zapytań.
Świadomie zrezygnowano z trigerrów producenta, referencyjnej i semantycznej integralności
czy „stored procedures“, również z uwagi na kompatybilność. Szybki dostęp jest realizowany głównie poprzez oddzielny system zarządzania pamięcią podręczną, któremu podlegają wszystkie bazy danych. Minimalizuje to liczbę dostępów do bazy danych i zwiększa ogólną przepustowość danych.
Komunikacja z bazą danych
Producenci używają różnych interfejsów lub różnych dialektów SQL do komunikacji z bazami danych. Aby ustandaryzować tę komunikację, zaimplementowano Object Query Language (OQL) oparty na koncepcjach obiektowych i relacyjnych. OQL bazuje na standardzie SQL. Przy porównywalnym zakresie funkcji jak w SQL, OQL jest obsługiwany przez wszystkie wymienione systemy zarządzania bazami danych. Z perspektywy programisty aplikacji dialekty SQL nie maja znaczenia.
Język zapytań OQL jest zintegrowany z systemem ERP. Podczas tłumaczenia
specyficzne nazwy systemu ERP są konwertowane na techniczne nazwy baz danych zgodnie z nazewnictwem obszaru nazw (namespace). Pozwala to na tworzenie unikalnych odniesień do obiektów i eliminuje występowanie konfliktów nazw w systemie.
Object Manager zapewnia deweloperowi aplikacji prosty sposób dostępu do danych. Umożliwia on wykonywanie na obiektach biznesowych poszczególnych operacji odczytu, wstawiania, zmiany i usuwania danych. W tym kontekście programista może również używać instrukcji OQL, w celu jednoczesnego przetwarzania wielu instancji obiektów biznesowych.
OQL i Object Manager tworzą dla programisty aplikacji interfejs do baz danych. Stosują niezależny od platformy protokół JDBC™3. Różne sterowniki JDBC™ są zwykle dostarczane z dodatkowymi parametrami specyficznymi dla producenta, które są używane przez system ERP w celu wykorzystania specjalnych funkcji systemów zarządzania bazami danych i wykorzystania ich potencjału wydajności.
Baza danych konfiguracji systemu
System ERP może być rozmieszczony na różnych komputerach. Dlatego centralnie, w bazie danych konfiguracji systemu przechowywane są obiekty niezbędne do konfiguracji systemu. Obiekty konfiguracyjne wpływają na środowisko wykonawcze i obejmują wszystkie dane zintegrowanych zasobów, a także dane uwierzytelniające użytkowników. W odpowiednich aplikacjach dialogowych można konfigurować zarówno poszczególne systemy, jak i rodziny systemów.
Baza danych repozytorium
Wszystkie obiekty deweloperskie są przechowywane w bazie danych repozytorium. Opisują one lub definiują system ERP. W środowisku produkcyjnym dostęp do obiektów deweloperskich jest możliwy tylko w trybie odczytu.
Dane te są zmieniane tylko w fazie rozwoju i poprzez instalację aktualizacji oprogramowania. Wszystkie obiekty deweloperskie podlegają ciągłemu wersjonowaniu i są zarządzane w obszarach nazw systemu ERP, które mają taką samą strukturę jak obszary nazw JAVA™.
Data Dictionary systemu ERP jest również przechowywany w bazie danych repozytorium. Opisuje on schemat bazy danych systemu ERP przy użyciu systemu typów odniesień do obiektów. System typów jest niezależny od platform baz danych. Data Dictionary stanowi podstawę mapowania statycznego, które odwzorowuje zawartość relacyjnych baz w obiektowym środowisku wykonawczym.
Baza danych Online Transaction Processing (OLTP)
W bazie danych Online Transaction Processing (OLTP) administrowane są dane podstawowe i transakcyjne dla
aplikacji biznesowych. Baza danych OLTP jest najbardziej wykorzystywana przez użytkowników w systemie produkcyjnym. Dane mogą być również utrzymywane oddzielnie przez wiele baz danych OLTP
(mandant), co może być konieczne w przypadku oddzielnych prawnych podmiotów biznesowych.
Baza danych Online Analytical Processing (OLAP)
Baza danych Online Analytical Processing (OLAP) służy do analizy danych biznesowych podobnie jak w innych rozwiązaniach hurtowni danych. Do celów statystycznych odpowiednie dane podstawowe i transakcyjne są pobierane z bazy danych OLTP i zapisywane w bazie danych OLAP zgodnie z „star schema”. Umożliwia to zapytania obejmujące wybór, podsumowanie lub agregację i grupowanie dużych ilości danych.
Programowanie w Comarch ERP Enterprise
Do rozwoju aplikacji w systemie ERP dostępne są: ERP System Development Kit ( SDK) oraz Application Development
Kit (ADK). Obok odpowiedniej wiedzy technicznej wymagane jest środowisko IDE Java™ z Compiler, Editor i Debugger. Jako IDE zalecane jest Eclipse w wersji 3.7 lub wyższej. IDE musi obsługiwać Javę co najmniej w wersji 7 jako środowisko deweloperskie JDK. Sposób przygotowania środowiska programistycznego opisano w dokumentacji Utworzenie środowisk programistycznych.
Klasy są uporządkowane w pakietach, których podział jest oparty na obszarach (frameworks) systemu ERP. Development Kits zawierają dodatkowe narzędzia zintegrowane z systemem. Należą do nich:
- narzędzia administracyjne do realizacji i obsługi zleceń i zadań deweloperskich
- aplikacja Obiekty deweloperskie do definiowania i rozszerzania obiektów deweloperskich, takich jak obiekty biznesowe, wyszukiwania QOL, widoki OQL, komunikaty itp.
- narzędzia do zarządzania bazą danych (tworzenie, kopiowanie i obsługa)
administrowanie) - narzędzia do importu i eksportu danych
- narzędzia do zarządzania aktualizacjami oprogramowania
Aby móc programować z Comarch ERP Enterprise deweloper musi musi wiedzieć, czym jest zlecenie deweloperskie, zadanie deweloperskie i obiekt deweloperski oraz w jaki sposób te trzy elementy są ze sobą powiązane.

Zlecenie deweloperskie zawiera opis tego, co należy wykonać. Może to być nowe opracowanie, albo też korekta błędu.
Opracowanie zlecenia deweloperskiego odbywa się w jednym lub kilku zadaniach deweloperskich.
Obiekty deweloperskie są podstawową jednostką w programowaniu aplikacji. Obiekty deweloperskie to metadane, które klasyfikują określone wartości i opisują ich właściwości. Stanowią one wartości funkcjonalne i techniczne w systemie ERP. Istnieją różne typy obiektów deweloperskich.
Obiekty deweloperskie podlegają wersjonowaniu, tzn. po zmianie jednego obiektu powstaje nowa wersja, a wcześniejsze wersje są archiwizowane.
W ramach jednego zadania deweloperskiego można opracowywać wiele obiektów deweloperskich jako jednostkę.
Zlecenie deweloperskie
Zlecenie deweloperskie jest narzędziem wspierającym dewelopera podczas programowania w systemie ERP. Zlecenie dokumentuje postęp w trakcie całego procesu opracowania. Zazwyczaj w zlecenie deweloperskie zaangażowanych jest czterech użytkowników: Creator, Coordinator, Programmer oraz Tester.
Użytkownik tworzy zlecenie deweloperskie. Może to być np. pracownik działu wsparcie klienta. Podczas rejestracji zlecenia deweloperskiego określana jest osoba, która ma zająć się realizacją danego zlecenia, czyli koordynacją dalszych działań. Koordynator decyduje, kto będzie programistą oraz kto przeprowadzi oba testy.
Zlecenie deweloperskie zawsze posiada aktualnego użytkownika obsługującego Editor. Jest on określany na podstawie statusu zlecenia. Poniższa tabela zawiera listę dostępnych statusów i wynikających z nich Editors.
| Status | Editor |
| Created | Coordinator |
| Classified | Programmer |
| In progress | Programmer |
| Implemented | Tester |
| Initial test | Tester |
| Initial test completed | Tester |
| In second test | Tester |
| Completed | Coordinator |
| Closed | Coordinator |
| Completed without changes | Coordinator |
| Consultation | Dowolny użytkownik |
| Postponed | Coordinator |
Opracowywanie przebiega zwykle od statusu Created do Closed w podanej powyżej kolejności.
Status Completed without changes ustawia się, jeśli zlecenie nie zostało opracowane lub nie były konieczne żadne zmiany.
Jeśli wymagane są szczegółowe informacje, można ustawić status Consultation. W tym miejscu można wprowadzić dowolnego użytkownika odpowiedzialnego za dostarczenie wymaganych informacji.
Jeśli opracowanie zostanie przerwane na dłuższy czas, można ustawić status Postponed.
Wszystkie informacje, etapy pracy itp. mogą być udokumentowane w zleceniu poprzez
teksty i załączniki. Teksty są ustandaryzowane i zależne od statusu i użytkownika, np. tester może utworzyć w zleceniu ze statusem Initial test tekst typu Comment, który opisuje przebieg testu.
Ważnym tekstem jest tekst do paczek instalacyjnych – Support Delivery Text. Opisuje, jaki problem został usunięty lub jakie przeprowadzono modyfikacje. Ten tekst może być opublikowany później i powinien być odpowiednio napisany.
Zlecenie deweloperskie podczas tworzenia otrzymuje unikalny kod. Składa się on z typu zlecenia, np. SUP, oraz sześciocyfrowego numeru. Informacje o typach zleceń dostępnych w systemie można uzyskać od administratora.
Zlecenie deweloperskie posiada ponadto następujące cechy: priorytet, kategorię, hierarchię i wersję (release).
Priorytet może być użyty do określenia stopnia pilności opracowania zlecenia. Przyjmuje wartości od Priority 1 (bardzo ważne) do Priority 9 (nieistotne).
Kategoria służy do określenia obszaru, którego dotyczą prace rozwojowe. Dostępne są następujące kategorie:
- rozwój (dodanie nowego elementu)
- dokumentacja
- korekta (bugfix)
- informacja
- ergonomia
W przypadku hierarchii zlecenie można przypisać do danego obszaru funkcjonalnego.
Release określa wersją oprogramowania, w której ma nastąpić opracowanie zlecenia.
Zlecenia deweloperskie zawiera jedno lub wiele zadań deweloperskich, w ramach których odbywa się właściwa implementacja.
Obsługa zleceń deweloperskich wymaga aktywacji usługi zleceń deweloperskich dla systemu deweloperskiego.
Zadanie deweloperskie
Przetwarzanie obiektów deweloperskich może odbywać się wyłącznie w ramach
zadania deweloperskiego. Zadanie deweloperskie musi być przypisane do zlecenia deweloperskiego. Zadanie deweloperskie tworzy powiazanie pomiędzy opracowującymi użytkownikami, obiektami deweloperskimi i i treścią.
Nowe zadanie deweloperskie otrzymuje automatycznie unikalny numer. Zadanie musi być przypisane do zlecenia deweloperskiego, które w momencie przyporządkowania musi mieć status W opracowaniu.
W przypadku systemu bez bez usługi zleceń deweloperskich w zleceniu można wprowadzić dowolny tekst.
Statusy zadań deweloperskich:
- otwarte
- w kolejce do zwolnienia
- w trakcie zwalniania
- zwolnione
- zwolnienie z ostrzeżeniami nie powiodło się
- w kolejce do aktywowania
- w trakcie aktywowania
- aktywowane
- aktywowane bez aktualizacji oprogramowania
Podczas dodawania obiektu deweloperskiego do zadania deweloperskiego obiekt ten jest blokowany w systemie. Blokada ta nazywana jest blokadą globalną. Ustawienie blokady globalnej gwarantuje, że
że obiekt deweloperski nie będzie modyfikowany równolegle w innym zadaniu deweloperskim.
Usuniecie globalnej blokady następuje w momencie, gdy obiekt deweloperski jest usuwany z zadania deweloperskiego lub gdy zadanie deweloperskie zostanie aktywowane.
Zadanie deweloperskie może być opracowywane przez wielu użytkowników, jeśli są oni dodani do zadania jako
użytkownicy opracowujący. Podczas modyfikacji obiektu deweloperskiego przyporządkowanego do zadania deweloperskiego następuje dodatkowo blokada lokalna, oprócz wspomnianej blokady globalnej.
Zapobiega to jednoczesnej modyfikacji danego obiektu przez wielu użytkowników.
Użytkownik opracowujący musi ręcznie zwolnić obiekt po zakończeniu edycji i w ten sposób usunąć blokadę lokalną.
Opracowanie zadania deweloperskiego kończy się zwolnieniem i aktywacją zadania.
Efektem zakończonego zadania deweloperskiego jest aktualizacja oprogramowania. Zwykle rezultaty zadań deweloperskich z jednego zlecenia deweloperskiego są zebrane w aktualizacji oprogramowania. Zadania są łączone do momentu wydania utworzonej aktualizacji oprogramowania. Kolejne zadania deweloperskie z tego samego zlecenia deweloperskiego są zebrane w nowej aktualizacji oprogramowania. Utworzona aktualizacja
aktualizacja przenosi modyfikacje do systemu pochodnego np. systemu produkcyjnego klienta.
Podstawowy proces deweloperski
Przed omówieniem poszczególnych typów obiektów deweloperskich, przyjrzyjmy się typowemu procesowi deweloperskiemu oraz niektórym specyficznym właściwościom aplikacji Zadania deweloperskie.
Krok 1: Utworzenie zlecenia deweloperskiego i rozpoczęcie opracowania
Proces rozwoju rozpoczyna się utworzeniem zlecenia deweloperskiego za pomocą aplikacji Zlecenia deweloperskie. W tym celu użytkownik musi określić Description, Release, Full task desription i Coordinator.
Po zapisaniu zlecenia Coordinator jest automatycznie wprowadzony jako Editor. Zamówienie przyjmuje teraz status Created.
Coordinator sprawdza utworzone zlecenie i dodaje lub koryguje wymagane dane, tj. priorytet, kategorię, hierarchię, release i czas przetwarzania. Konieczne jest wprowadzenie programistów i testerów. W razie potrzeby koordynator może wprowadzić dodatkowe teksty. Następnie ustawia status zlecenia na Classified.
Krok 2: Opracowanie
Programista rozpoczyna opracowanie zlecenia deweloperskiego ustawiając jego status na In Progress. Następnie w aplikacji Zadania deweloperskie w obszarze Rozwój oprogramowania dodaje nowe zadanie deweloperskie do zlecenia.
Programista rozpoczyna opracowanie obiektów lub tworzy nowe w aplikacji Obiekty deweloperskie.
Są one automatycznie dodawane do zadania i blokowane globalnie (również lokalnie podczas ich modyfikacji). Wiąże się to z tzw. check-out. Korzystając z narzędzi SAS (crtbo, crtvs, …) należy w razie potrzeby wygenerować na nowo źródła dla zmienionych obiektów deweloperskich i utworzyć tymczasowe tabele bazy danych dla zmienionych obiektów biznesowych. Wygenerowane źródła są przechowywane w katalogu roboczym zadania, podczas dodawania do zadania następuje check-out klas Java i zapisanie do opracowania w tym samym miejscu. Od tego momentu rozpoczyna się właściwe programowanie.
Jeśli testy przeprowadzone przez dewelopera zakończą się pomyślnie, następuje implementacja źródeł. Proces ten nazywany jest check-in i wykonywany jest za pomocą przycisków na standardowym pasku narzędzi aplikacji Zadania deweloperskie. Wygenerowane i zaprogramowane źródła są przenoszone do repozytorium i kompilowane ze stanem klasy systemu. Jeśli wystąpią błędy, należy je usunąć i powtórzyć check-in.
Krok 3: Zwolnienie zadania deweloperskiego
Następnym krokiem jest zwolnienie zadania deweloperskiego. Po jego wykonaniu nie jest już możliwa modyfikacja obiektów deweloperskich zawartych w zadaniu. Jeśli w ramach zadania wprowadzono zmiany w obiektach biznesowych, wprowadzone zmiany w schemacie muszą zostać aktywowane na bazie danych za pomocą komendy „actjob“. Aktywacja odbywa się poprzez zastąpienie starych, wciąż aktywnych tabel nowymi tabelami tymczasowymi. System automatycznie przenosi dane dane ze starych tabel do nowych.
Jeśli konieczna jest konwersja danych lub określenie specjalnych wartości początkowych dla nowo dodanych atrybutów, deweloper musi dostosować odpowiednie programy aktualizacji.
Krok 4: Aktywacja zadania deweloperskiego
Aktywacja zadania deweloperskiego jest ostatnim krokiem opracowania. Wszystkie globalne blokady nałożone przez zadanie deweloperskie zostają anulowane. Dla zadania deweloperskiego tworzona jest aktualizacja oprogramowania ze zmianami lub zmiany są dodawane do istniejącej otwartej aktualizacji oprogramowania z innego aktywowanego zadania w tym samym zleceniu deweloperskim. Źródła Java, klasy Java, pliki, ikony i pliki pomocy online zastępują starsze wersje w systemie plików serwera systemu ERP. Po ponownym uruchomieniu serwera będą stosowane nowe pliki klas.
Etap implementacji jest zakończony, gdy wszystkie zadania deweloperskie należące do zlecenia deweloperskiego zostaną aktywowane. Użytkownik opracowujący nadaje zleceniu status Implemented. Użytkownik opracowujący (editor) zmienia się na testera (tester).
Krok 5: Testy zlecenia deweloperskiego
Testy zlecenia deweloperskiego odbywa się w dwóch etapach. Pierwszy test jest przeprowadzany w systemie deweloperskim. Jeśli przebiegnie pomyślnie, aktualizacja oprogramowania jest implementowana w systemie testowym i na tym systemie przeprowadzany jest drugi test.
Przed rozpoczęciem testowania należy zmienić status zlecenia deweloperskiego na Initial test. Tester sprawdza, czy zadania zostały zrealizowane bez błędów. Jeśli implementacja żądanych modyfikacji jest niekompletna lub nieprawidłowa, programista musi ponownie opracować zlecenie deweloperskie. Status zlecenia zmienia wówczas z powrotem na Classified.
Jeśli pierwszy test zakończył się pomyślnie, status zlecenia należy zmienić na Initial test completed. Następnie, jak
jak opisano powyżej, aktualizacja oprogramowania jest importowana do systemu testowego. W tym momencie rozpoczyna się drugi test. Tester ustawia status zlecenia na In second test. W przypadku wystąpienia błędów zlecenie musi zostać ponownie opracowane przez programistę.
Jeśli drugi tekst zakończył się pomyślnie, zlecenie otrzymuje status Completed. Oznacza to zakończenie fazy testów.
Obiekty deweloperskie
Rozwój w systemie ERP opiera się na łączeniu różnych obiektów. Mogą to być na przykład klasy Java, ikony, logiczne typy danych, zestawy wartości, obiekty pomocy itp. Wszystkie obiekty używane podczas programowania są określane ogólnym terminem: obiekt deweloperski. System ERP obsługuje predefiniowany zestaw różnych typów obiektów. Są one określane jako typy obiektów deweloperskich. Każdy obiekt deweloperski posiada nazwę i obszar nazw. Na podstawie
kombinacji obszaru nazw i nazwy można jednoznacznie zidentyfikować obiekt deweloperski. Obiekt musi być unikalny w ramach swojego typu. Oznacza to, że nie mogą na przykład istnieć klasy Java, które mają ten sam obszar nazw i nazwę.
Z drugiej strony możliwe jest istnienie logicznego typu danych i klasy Java z tą samą kombinacją obszaru nazw i nazwy. W niektórych przypadkach przyjmuje się nawet, że istnieją obiekty deweloperskie różnych typów z tym samym obszarem nazw i nazwą. Dobrym tego przykładem są zestawy wartości (value sets). W momencie tworzenia nowego zestawu wartości jest zwykle generowana klasa Java o tej samej nazwie.
Wszystkie stosowane obiekty deweloperskie są wersjonowane i zapisywane w repozytorium.
Poniżej opisane są obszary nazw, a w dalszej części dokumentu poszczególne typy obiektów deweloperskich i wersjonowanie.
Obszary nazw
Wszystkie obiekty deweloperskie systemu ERP są uporządkowane w obszarach nazw. Ten składa się z jednego lub więcej słów oddzielonych kropką, np. com.cisag.app lub com.cisag.pgm. Obszary nazw mają strukturę hierarchiczną w formie drzewa, którego podstawą jest obszar nazw com. Dla obszaru nazw
com.cisag.app.sales.ui struktura jest następująca:
com com.cisag com.cisag.app com.cisag.app.sales com.cisag.app.sales.ui
Podczas tworzenia obszaru nazw można zdefiniować dla niego specjalne zachowanie. Obszar może być oznaczony jako testowy lub jako wewnętrzny. Obszar nazw oznaczony jako testowy nie może zostać wydany z aktualizacją. Dotyczy to również wszystkich zawartych w nim obiektów deweloperskich. W przypadku wewnętrznego obszaru nazw można dla każdego zadania deweloperskiego indywidulanie zdecydować, czy obiekty deweloperskie zostaną wydane z aktualizacją.
Po wybraniu dla obszaru nazw jednego z tych dwóch oznaczeń, nie będzie już możliwości jego zmiany. Wszystkie obszary, które zostaną utworzone w ramach tego obszaru, otrzymają automatycznie to oznaczenie, bez możliwości zmiany.
Dla obiektów uporządkowanych w strukturach obszarów nazw stosowane są następujące reguły:
- Wszystkie obiekty deweloperskie danego typu znajdujące się w jednym obszarze nazw musza się różnić nazwą, bez rozróżniania pisowni wielką i małą literą.
- Obiekty z dwóch różnych obszarów nazw są zawsze różnymi obiektami, nawet jeśli ich nazwy są takie same.
- W przypadku obiektu Klasa Java obszar nazw odpowiada również nazwie pakietu Java.
Reguły dotyczące obszarów nazw zapobiegają nakładaniu się na siebie nazw obiektów deweloperskich.
Obiekty rozwojowe pochodzące ze standardu mogą zatem istnieć obok obiektów deweloperskich programowanych przez partnerów, bez ryzyka wystąpienia konfliktów w nazewnictwie.
Struktura obszaru nazw
Obszar nazw składa się z jednego lub więcej słów oddzielonych kropkami i ma strukturę hierarchiczną. Słowa mogą składać się z liter a – z i muszą być pisane małymi literami. Podstawą wszystkich obszarów nazw w systemie ERP jest obszar com. Kolejny poziom tworzy prefiks deweloperski składający się z 3-5 znaków. Jest on definiowany w momencie przyznania licencji i nie podlega modyfikacji. Prefiks deweloperski standardowego rozwoju to cisag. Następny poziom jest również ściśle określony. Są to trzy obszary nazw:
| Obszar nazw | Opis |
| com.<präfix>.app | Wszystkie obiekty deweloperskie zawierające się w tym obszarze są używane w aplikacjach biznesowych. |
| com.<präfix>.dbu | Dla każdego obiektu deweloperskiego istnieją wygenerowane klasy Java i program aktualizacji dla każdej wersji. Program aktualizacji definiuje, w jaki sposób należy zmienić dane, aby móc przejść do kolejnej wersji. |
| com.<präfix>.nls | W tym obszarze nazw znajdują się specjalne wygenerowane klasy Java dla atrybutów obiektów biznesowych specyficznych dla danego języka, które umożliwiają dostęp dostęp do bazy danych. |
Struktura obszaru nazw zawarta w com.<prefix>.app jest uzasadniona technicznie i opiera się na obszarach (frameworks) zdefiniowanych w systemie ERP. Istnieje możliwość dalszych gradacji.
Najniższy poziom obszaru nazw tworzy zazwyczaj połączenie maksymalnie sześciu obszarów nazw:
com.<präfix>.app.<klasyfikacja techniczna> com.<präfix>.app.<klasyfikacja techniczna>.obj com.<präfix>.app.<klasyfikacja techniczna>.log com.<präfix>.app.<klasyfikacja techniczna>.ui com.<präfix>.app.<klasyfikacja techniczna>.gui com.<präfix>.app.<klasyfikacja techniczna>.res2d com.<präfix>.app.<klasyfikacja techniczna>.hook com.<präfix>.app.<klasyfikacja techniczna>.model com.<präfix>.app.<klasyfikacja techniczna>.rest
Każdy z obszarów nazw ma określone znaczenie. Typy obiektów deweloperskich, opisane w rozdziale Typy obiektów deweloperskich, są rozdzielane do tych obszarów nazw według określonych reguł lub kryteriów. Niektóre typy obiektów deweloperskich podlegają pewnej zasadzie: muszą znajdować się dokładnie w jednej określonej przestrzeni nazw. Dotyczy to na przykład obiektów biznesowych, które zawsze muszą znajdować się w obszarze nazw zakończonym na .obj. Inne typy są przypisywane do obszarów nazw raczej według rodzaju ich zastosowania.
Szczególne obszary nazw rozwoju standardu
Obszar nazw com.cisag obejmuje trzy specjalne obszary:
| Obszar nazw | Opis |
| com.cisag.pgm | Ten obszar nazw zawiera Application Programming Interface (API), w którym programowane są aplikacje w systemie ERP. Są to zazwyczaj klasy wrapper lub interfejsy, które są implementowane przez klasy w obszarze nazw com.cisag.sys. |
| com.cisag.sys | Ten obszar nazw zawiera silnik systemu, inne komponenty systemu oraz data dictionary. |
| com.cisag.archive | Ten obszar nazw zawiera data dictionary, w którym zapisywane są metadane wersji wszystkich obiektów deweloperskich. |
Typy obiektów deweloperskich
System ERP opiera się na zdefiniowanym zestawie typów obiektów deweloperskich. Każdy typ obiektu ma specjalne znaczenie i zastosowanie. Poniżej wymienione zostały niektóre typy. Szczegółowe informacje o każdym z typów znajdują się w odpowiednich podrozdziałach, jak również w dokumencie Obiekty deweloperskie.
Akcja
Akcje są używane w systemie ERP do programowania interfejsów. Są one niezbędne w procesie tworzenia przycisków, zakładek, menu i menu kontekstowych. Dla akcji można wprowadzić etykietę, tooltip, kombinację klawiszy, małą ikonę i dużą ikonę. Akcje mogą dziedziczyć po innych akcjach, tzn. można wprowadzić akcję, z której pobierana jest dana etykieta lub tooltip. Które atrybuty zostaną przejęte, można określić za pomocą listy wyboru dla każdego atrybutu, dostępne opcje to: Z dziedziczenia i Niestandardowe (zdefiniowane przez użytkownika).
Akcje mogą być tworzone tylko w obszarach nazw kończących się na „.gui” lub „.ui”. Akcje są używane w innych akcjach do dziedziczenia lub w klasach Java. Stosowany obszar nazw „.ui” lub „.gui” powinien zależeć od klasy Java. Zwykle akcja znajduje się w tym samym obszarze nazw co używana klasa Java.
Nazwa akcji powinna być wybrana w taki sposób, aby można było po niej rozpoznać przynależność do aplikacji, dialogu lub komponentu UI. Na przykład nazwa akcji może zaczynać się od nazwy danej aplikacji.
Ponadto nazwa akcji powinna wskazywać na to, dla jakich elementów UI jest wykorzystywana, np. przycisku, przełącznika, zakładki czy menu podręcznego.
Akcje dla przycisków
Szablon akcji stosowanych dla przycisków to:
<Nazwa klasy><Nazwa akcji>[Button]
Nazwa klasy jest nazwą klasy aplikacji, okna dialogowego lub komponentu. Przyrostek Button jest opcjonalny i dodawany tylko w celu doprecyzowania.
Obszar nazw: com.cisag.app.internal.ui
Nazwa: LicenceDefinitionMaintenanceAddEntry
Nazwa alternatywna: LicenceDefinitionMaintenanceAddEntryButton
Akcje dla przełączników
Szablon akcji stosowanych dla przełączników to:
<Nazwa klasy>Toggle<Nazwa akcji>
Nazwa klasy jest nazwą klasy aplikacji, okna dialogowego lub komponentu. Następnie słowo Toggle, a po nim nazwa akcji.
Obszar nazw: com.cisag.app.internal.ui
Nazwa: LicenceDefinitionMaintenanceToogleDetails
Akcja dla zakładek
Szablon akcji stosowanych dla zakładek to:
<Nazwa klasy><Nazwa akcji>Tab
Nazwa klasy jest nazwą klasy aplikacji, okna dialogowego lub komponentu. Następnie nazwa akcji, a po niej słowo Tab.
Obszar nazw: com.cisag.app.internal.ui
Nazwa: LicenceDefinitionMaintenanceExtensionTab
Akcja dla menu kontekstowego
Szablon akcji stosowanych dla menu kontekstowego to:
<Nazwa klasy>Popup<Nazwa akcji>
Nazwa klasy jest nazwą klasy aplikacji, okna dialogowego lub komponentu. Następnie słowo Popup, a po nim nazwa akcji.
Obszar nazw: com.cisag.app.internal.ui
Nazwa: LicenceDefinitionMaintenanceExtensionTab
Szablony
W com.cisag.pgm istnieje kilka akcji, które w przypadku takiego samego zastosowania powinny być używane jako szablon dla akcji własnych. Nie mogą one być stosowane bezpośrednio, ale akcje własne mogą dziedziczyć po nich i przybierać formę Shortcuts i Icons.
Dla zastosowania w standardowym pasku narzędzi:
com.cisag.pgm.gui.coolbar.Execute
com.cisag.pgm.gui.coolbar.ExecuteList
com.cisag.pgm.gui.coolbar.ExecuteMenu
Dla zastosowania w paskach narzędzi:
com.cisag.pgm.gui.coolbar.Add („Nowe/Dodaj”)
com.cisag.pgm.gui.coolbar.AddDuplicate („Duplikuj”)
com.cisag.pgm.gui.coolbar.AddFromSearch („Wyszukaj i dodaj”)
com.cisag.pgm.gui.coolbar.Remove („Wstaw/Usuń znacznik usuwania”)
com.cisag.pgm.gui.coolbar.ToggleDetails(„Szczegóły”)
com.cisag.pgm.gui.coolbar.FilterEntries („Filtruj pozycje/wpisy”)
com.cisag.pgm.gui.coolbar.Find („Wyszukaj”)
com.cisag.pgm.gui.coolbar.ShowDetailsDialog
(„Cechy”)
Do obsługi klawiatury:
com.cisag.pgm.gui.Enter
Aplikacja
Aplikacje mają szerokie zastosowanie w systemie ERP i dzielą się na aplikacje dialogowe, aplikacje działające w tle, aktualizacje danych dialogowych, automatyczne aktualizacje danych w tle, ręczne aktualizacje danych w tle, usługi, reorganizacje i narzędzia.
Aplikacja dialogowa
Aplikacje dialogowe to aplikacje, na których najczęściej pracuje się w systemie ERP. Są to
aplikacje jak np. Zamówienia sprzedaży lub aplikacje typu Lista.
Aplikacje dialogowe muszą być tworzone w obszarze nazw, który kończy się na „.ui”. Nazwa aplikacji dialogowej nie podlega żadnym regułom. Należy jednak pamiętać, że: normalne aplikacje zarządzania kończą się na „Maintenance”, aplikacje zapytań i aplikacje typu Lista kończą się na „Inquiry” lub „Cockpit”.
Aplikacja dialogowa posiada nazwę, która jest wyświetlana w panelu nawigacji i na pasku głównym aplikacji. Nazwa aplikacji jest wyświetlana w panelu nawigacji użytkownika, jeśli spełnione są następujące warunki: opcja wyświetlania i serwisu jest ustawiona na „Wyświetlanie, obsługa”, użytkownik posiada niezbędne uprawnienia do korzystania z aplikacji, funkcja (o ile istnieje) jest aktywowana w Konfiguracji.
Aplikacja musi być typu „Dialog”. Specjalne zastosowanie musi pozostać puste. W panelu nawigacji aplikacja jest przypisana do podanego obszaru (framework). Klasa Java zawiera program, który ma zostać uruchomiony po wywołaniu aplikacji. Zazwyczaj obszar nazw i nazwa klasy Java są takie same jak obszar nazw i nazwa aplikacji.
Jeśli aplikacja ma być wyświetlana w menu kontekstowym jednostki biznesowej, to minimalnym wymaganiem jest to, że akcja „Load” musi zostać utworzona z parametrem typu Business Object. Żądana jednostka biznesowa musi być wprowadzona jako obiekt biznesowy.
Jedna z aplikacji w menu kontekstowym jednostki biznesowej jest wyróżniona jako aplikacja domyślna. Ta aplikacja jest określana według określonych reguł. Oprócz wspomnianych minimalnych wymagań dla wyświetlania w menu kontekstowym, można wprowadzić inne specyfikacje, dzięki którym aplikacja będzie miała „wyższą rangę”.
Po pierwsze, nazwa parametru akcji „Load” może odpowiadać nazwie jednostki biznesowej. Przykładowo, dla jednostki biznesowej com.cisag.app.general.obj.Partner można użyć nazwy parametru „Partner”.
Po drugie, można wprowadzić główną jednostkę biznesową, która odpowiada obiektowi biznesowemu parametru.
Dla ustalenia preferowanej aplikacji w menu kontekstowym przyjmuje się następującą narastającą kolejność pod względem istotności:
– Akcja
– Akcja i nazwa parametru
– Akcja i główna jednostka biznesowa
– Akcja, główna jednostka biznesowa i nazwa parametru
Jeśli na najwyższym poziomie istotności znajduje się kilka aplikacji, wybierana jest ta aplikacja, która znajduje się na pierwszym miejscu w kolejności alfabetycznej.
Aktywną bazą danych wymaganą dla aplikacji dialogowej jest Baza danych OLTP, a w rzadkich przypadkach Baza danych OLAP. Baza danych repozytorium i Baza danych konfiguracji są wymagane tylko dla aplikacji dialogowych do rozwoju systemu ERP.
Aplikacja w tle
Aplikacje działające w tle są używane w zadaniach przetwarzania lub uruchamiane za pośrednictwem dialogu batch submit. Aplikacje w tle są używane do wykonywania czasochłonnych akcji i przetwarzania danych w tle. Do przetwarzania nie jest wymagana dodatkowa interakcja użytkownika, a podczas przetwarzania użytkownik może
normalnie kontynuować swoją pracę z systemem ERP.
Aplikacje w tle muszą być tworzone w obszarze nazw, który kończy się na „.log” lub „.print”. Aplikacja musi posiadać typ Tło. Szczególne zastosowanie musi pozostać nieuzupełnione. Klasa Java zawiera program, który ma zostać uruchomiony po wywołaniu aplikacji. Obszar nazw i nazwa klasy Java są zazwyczaj takie same jak obszar nazw i nazwa aplikacji.
Aktualizacja danych dialogu
Aktualizacje danych dialogu są wykonywane w celu aktualizacji danych, dla której użytkownik musi podać dodatkowe informacje. Aktualizację danych można uruchomić z poziomu aplikacji Zapytania o aktualizacje danych. Wyświetlana jest pomoc kontekstowa aplikacji oraz maska wprowadzania danych (jeśli istnieje), w której użytkownik może wprowadzić dodatkowe dane wymagane przez aktualizację.
Aktualizacje danych dialogu muszą być tworzone w obszarze nazw, która kończy się na „.ui”. Nazwa aplikacji dialogowej nie podlega żadnym regułom. Jednak nazwa często składa się z „UPD” i zlecenia deweloperskiego, np. UPDSUP12345.
Aplikacja musi być typu Dialog. Szczególne zastosowanie musi być ustawione na Aktualizacja danych. Aktualizacje danych dialogu są zwykle przyporządkowane do obszaru (framework) com.cisag.pgm.Update.
Automatyczna aktualizacja danych w tle
Automatyczna aktualizacja danych w tle jest wykonywana podczas instalacji aktualizacji oprogramowania, które zawiera daną aktualizację danych. Ta aktualizacja danych jest wymagana np. w przypadku, gdy zmieniono obiekt biznesowy i konieczne jest dostosowanie zasobu danych. Automatyczne aktualizacje danych w tle powinny być tworzone w
obszarze nazw com.<prefix>.app.update.log. Nazwa aplikacji dialogowej nie podlega żadnym regułom. Często
nazwa składa się z „UPD” i zlecenia deweloperskiego, np. UPDSUP12345.
Aplikacja musi być typu Tło. Szczególne zastosowanie musi być ustawione na Aktualizacja danych. Aktualizacje danych są zazwyczaj przyporządkowane do obszaru (framework) com.cisag.pgm.Update. Obszar nazw i nazwa klasy Java są zwykle takie same obszar nazw i nazwa aplikacji. Klasa Java dla aktualizacji danych w tle musi implementować abstrakcyjną klasę com.cisag.pgm.base.CisUpdateBatchApplication.
Ręczna aktualizacja danych w tle
Ręczna aktualizacja danych w tle różni się od aktualizacji automatycznej tym, że nie jest wykonywana podczas instalacji aktualizacji oprogramowania. Ręczna aktualizacja danych w tle może być wykonana w dowolnym momencie poprzez zlecenie przetwarzania. Aplikacja musi być typu Tło. Szczególne zastosowanie musi być ustawione na Aktualizacja danych w tle.
Narzędzie
Narzędzia są uruchamiane w systemie ERP w Toolshell poprzez określenie klasy
Java. Klasa Java musi zawierać mainMethode.
public static void main(String[] argv) {
….
}
}
Narzędzia są tworzone w obszarze nazw kończącym się na „.tools”.
Typ musi być ustawiony na Tool. Szczególne zastosowanie musi pozostać nieuzupełnione.
Raport
Raporty służą do tworzenia dokumentów raportów lub dokumentów końcowych (do wydruku)
za pomocą ERP System Output Manager. Układ i parametry raportu i parametry raportu są opracowywane z zastosowaniem Crystal Reports.
Gotowe pliki raportów można zaimportować do systemu ERP i uzupełnić o dodatkowe dane. Dane te obejmują m.in. etykiety parametrów i stałe tekstowe w raporcie.
Grupa jednostek biznesowych
Grupy jednostek biznesowych są stosowane do zdefiniowania uprawnień.
Obiekt biznesowy
Obiekt biznesowy jest techniczną definicją zmiennej funkcjonalnej, dla której określone specyfikacje (instancje) są zapisywane w bazie danych w oddzielnej tabeli. Obiekt biznesowy (BO) stanowi przede wszystkim kontener danych bez logiki funkcjonalnej. Posiada obszar nazw i konkretną nazwę. Dane, które maja być przechowywane, są opisywane za pomocą jednej lub kilku definicji atrybutów (w skrócie atrybuty). Obiekt biznesowy może dziedziczyć atrybuty z definicji częściowej.
Obiekt biznesowy to wielkość techniczna, która może być odczytana, zapisana i usuwana przez usługę trwałości danych (persystencja) systemu ERP. Dokonuje się przy tym konwertowanie pomiędzy obiektowym modelem danych używanym w aplikacji a relacyjnym modelem danych. Inne właściwości, które należy określić to rodzaj danych, oczekiwany rozmiar danych i strategia pamięci podręcznej (cache). Służy to przede wszystkim systemowi do optymalizacji wydajności i minimalizacji dostępów do baz danych.
Obiekt biznesowy, zwany również definicją obiektu biznesowego, jest podstawą generowania klas i tabel. Wygenerowane klasy Java enkapsulują wykorzystanie bazy danych i zapewniają aplikacji dostęp do danych instancji obiekty biznesowego. Dla obiektu biznesowego generowana jest tabela główna i tabele pomocnicze ze strukturami dostępu z przechowywanych definicji indeksów.
Atrybuty
Atrybut nie jest niezależnym typem obiektu deweloperskiego, ale częścią definicji obiektu biznesowego, cząstki part lub rozszerzenia. Atrybut ma nazwę, która jest unikalna w obiekcie deweloperskim (np. obiekcie biznesowym). Posiada typ określony przez przyporządkowany logiczny typ danych. Atrybut może być również zdefiniowany jako array określonego typu. W klasie Java wygenerowanej dla obiektu biznesowego atrybuty stają się zmiennymi, które zawierają wartości funkcjonalne. Jak jak zwykle w przypadku klas Java, można wykonać zapytanie o wartości za pomocą metody get
(dla boolowskiej metody is) i zmieniać je za pomocą metody set.
Atrybuty NSL
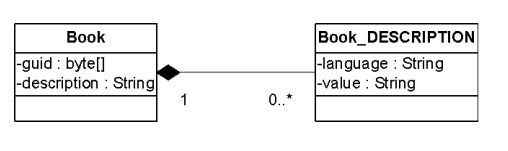
NLS to skrót od National Language Support. Atrybut NLS jest atrybutem wielojęzycznym opartym na typie pierwotnym string, dla którego ustawiono cechę multilingual capable. Jeśli atrybutowi przypisano identyfikowalny logiczny typ danych, wówczas wartość może być dostępna w kilku językach. Tłumaczenia atrybutu są zapisywane w oddzielnym obiekcie biznesowym NLS. Jego nazwa składa się z nazwy obiektu biznesowego, który zawiera identyfikowalny atrybut oraz nazwy kolumny tabeli bazy danych identyfikowalnego atrybutu. Obiekt biznesowy NLS jest automatycznie tworzony w paczce NLS, która różni się od pierwotnej paczki tym, że po skrócie systemu w obszarze nazw dodany jest string „nls”, np. com.cisag.nls. Baza danych (mandant) zawsze ma przyporządkowany język główny i ewentualnie kilka języków dodatkowych. Wartość w głównym języku atrybutu jest zapisywana w tabeli powiązanego obiektu biznesowego i dlatego może być skutecznie wyszukiwana w zapytaniach. Wartości języków dodatkowych dla atrybutu, czyli tłumaczenia, są przechowywane w oddzielnej tabeli obiektu NLS. Z punktu widzenia programisty aplikacji dostęp do atrybutu NLS jest maksymalnie transparentny.
Poniższy rysunek przedstawia obiekt biznesowy com.cisag.app.edu.obj.Book z wielojęzycznym atrybutem description. Obiekt biznesowy NLS com.cisag.nls.app.edu.obj.Book_DESCRIPTION, utworzony przez system, zawiera wszelkie języki dodatkowe dla atrybutu.
Indeksy
Indeks jest strukturą dostępu do zapisanych instancji obiektu biznesowego. Instancja jest identyfikowana poprzez
wartości specjalnie oznaczonych atrybutów, tzw. atrybutów kluczowych.
Rozróżnia się następujące indeksy:
- Primary key
- Business key
- Secondary key
- Non unique index
Obiekt biznesowy z reguły zawsze posiada Primary key i Business key, które są unikalnymi indeksami. W ramach danego obiektu biznesowego indeks posiada unikalną nazwę. W klasie obiektów biznesowych dla każdego zdefiniowanego indeksu jest generowana metoda w postaci buildIndexnameKey(…). Metoda ta dostarcza klucz techniczny dla usługi trwałości do wartości klucza podstawowego danej instancji obiektu biznesowego. W ten sposób usługa usługi trwałości może pobierać instację z bazy danych.
Zasadniczo indeksy przyspieszają dostępy odczytu, ale spowalniają dostępy zapisu (create, update, delete), ponieważ zarządzanie indeksami wymaga dodatkowego nakładu pracy.
Primary key
Primary key o stałej nazwie Primary opiera się na unikalnych wartościach klucza podstawowego. Klucz podstawowy obiektu biznesowego zazwyczaj składa się tylko z atrybutu opartego na logicznym typie danych typu prymitywnego guid. Jest to sztucznie wprowadzony klucz i może być również określany jako tożsamość obiektu. Umożliwia identyfikację instancji obiektu biznesowego i skuteczny dostęp ze względu na jego niewielką długość. Identyfikuje instancję obiektu biznesowego również wtedy, gdy zmieni się klucz funkcjonalny. Wszystkie atrybuty w kluczu podstawowym są polami obowiązkowymi. Ten Indeks ten jest używany jako podstawowy indeks tabeli w bazie danych.
Business key
Business key stanowi unikalny klucz funkcjonalny i jest zazwyczaj odczytywalny, np. numer artykułu, kod kraju. Jest zwykle używany w aplikacjach biznesowych do identyfikacji instancji obiektu biznesowego. Nazwa klucza
biznesowego powinna zaczynać się od przedrostka „By”. Jeśli na przykład
kluczem funkcjonalnym obiektu biznesowego jest atrybut „code”, indeks powinien nazywać się „ByCode”. Jeśli klucz funkcjonalny składa się z kilku atrybutów, należy wybrać odpowiednią nazwę. Dla tabeli bazy danych tworzony jest unikalny indeks przy użyciu atrybutów klucza.
Secondary key
Istnieje możliwość zdefiniowania dodatkowego indeksu pomocniczego, który jest oparty na innym unikalnym kluczu.
Unikalny indeks jest tworzony dla tabeli bazy danych przy użyciu atrybutów klucza. Nazwy
powinny być przypisywane w taki sam sposób jak nazwy kluczy biznesowych.
Non unique index
Indeks nieunikalny opiera się na atrybutach, których wartości mogą być wieloznaczne. Indeks jest tworzony na tabeli dla znajdujących się w niej atrybutów (duplikaty są zatem dozwolone), przy czym w jednym dostępie może być dostarczone wiele instancji. Przykładem jest obiekt biznesowy com.cisag.app.general.obj.Item.

W tym przykładzie w klasie „com.cisag.app.general.obj.Item” generowane są następujące metody do indeksów z zastosowaniem nazw indeksów:
Dla Non unique index nie jest generowana żadna metoda.
Relacje
Relacja jest funkcjonalnym połączeniem pomiędzy dwoma obiektami biznesowymi.
Aby odzwierciedlić połączenie funkcjonalne, dla obiektu biznesowego określa się definicję relacji (w skrócie: relacja). W systemie ERP relacje są zawsze unidirektional, tzn. prowadzą tylko od źródła do celu. Jeśli potrzebne są oba kierunki, należy osobno utworzyć drugą relację. Relacja może posiadać kardynalność „1-1” lub „1-n”. Relacje opcjonalne nie są modelowane oddzielnie i są uwzględnione w kardynalności. Relacja jest częścią definicji obiektu biznesowego. Ma unikalną nazwę i określa przyporządkowanie atrybutów źródłowych do atrybutów docelowych. W klasie Java należącej do obiektu biznesowego generowana jest metoda retrieveRelationshipName dla każdej podanej relacji.
(…).
Relacja 1-1
Relacja o kardynalności „1-1” przypisuje do instancji obiektu biznesowego maksymalnie jedną inną instancję obiektu biznesowego. Na podstawie wartości atrybutów źródłowych wyszukiwane są te same wartości w atrybutach docelowych, aby zidentyfikować cel relacji. Dla zapewnienia unikalności relacji, w atrybutach docelowych musi być zdefiniowany unikalny indeks, tj. primary key, business key lub secondary key. Integralność referencyjna nie jest sprawdzana przez system.
Relacja 1-n
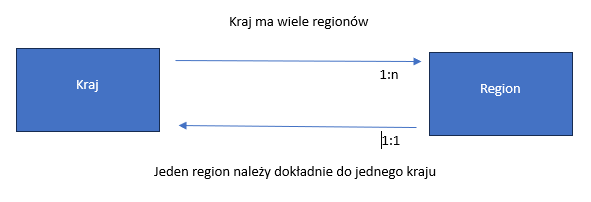
Relacja o kardynalności „1-n” przypisuje do instancji obiekty biznesowego jedną lub wiele instancji tego samego obiektu biznesowego, ale może również nie przypisywać żadnej instancji. Na podstawie wartości atrybutów źródłowych wyszukiwane są te same wartości w atrybutach docelowych. Nazwa takiej relacji powinna być podana w liczbie mnogiej, aby zaznaczyć kardynalność.
W systemie ERP można w następujący sposób modelować te relacje:
Jeden kraj ma wiele regionów:
| Nazwa relacji | Regiony |
| Obiekt źródłowy | com.cisag.app.general.obj.Country |
| Obiekt docelowy | com.cisag.app.general.obj.Region |
| Kardynalność | 1-n |
| Mapping atrybutu | Country.guid auf Region.country |
W klasie obiektu biznesowego com.cisag.app.general.obj.Country generowana jest następująca metoda dla relacji:
public CisObjectIterator retrieveRegions()
Jeden region należy dokładnie do jednego kraju:
| Nazwa relacji | Regiony |
| Obiekt źródłowy | com.cisag.app.general.obj.Region |
| Obiekt docelowy | com.cisag.app.general.obj.Country |
| Kardynalność | 1-n |
| Mapping celu | Primary |
| Mapping atrybutu | Region.country auf Country.guid |
W klasie obiektu biznesowego com.cisag.app.general.obj.Regions generowana jest następująca metoda dla relacji:
public Country retrieveCountry()
Zależności pomiędzy obiektami biznesowymi
Obiekty biznesowe i modelowane przez nie zmienne funkcjonalne są zazwyczaj niezależne, tzn. istnienie jednego obiektu biznesowego nie jest powiązane z istnieniem innego. Niektóre zmienne funkcjonalne nie istnieją samodzielnie, ale są zależne od innych. Jeśli pozycja zlecenia należy dokładnie do jednego nagłówka zlecenia, to nie może istnieć bez przypisanego jej nagłówka zlecenia. Te obie zmienne funkcjonalne, nagłówek zlecenia i pozycja zlecenia, razem tworzą logiczną jednostkę – zlecenie. Nagłówek zlecenia jest niejako reprezentantem zlecenia, a jego właściwości są danymi istotnymi dla przedmiotowego zlecenia. Do modelowania takich zależności służy typ obiektów biznesowych.
Typy obiektów biznesowych
Obiekty biznesowe istnieją zazwyczaj w znormalizowanej formie. Zdarza się, że rzeczywista zmienna funkcjonalna jest opisana przez więcej niż jeden obiekt biznesowy. Niemniej jednak, zawsze istnieje jeden główny obiekt biznesowy, nagłówek jednostki biznesowej. Wszystkie inne obiekty biznesowe w tej grupie, Supplements i Dependents, są zależne od głównego obiektu biznesowego. Cała grupa tworzy jednostkę biznesową. Nagłówek jednostki biznesowej, Supplements i Dependents tworzą hierarchiczną strukturę z jednoznaczną przynależnością.
W definicji obiektu biznesowego określa się, czy jest on suplementem (przypisany typ: Supplement), elementem zależnym (przypisany typ: Dependent), czy głównym obiektem biznesowym (przypisany typ: Business Entity).
Jednostka biznesowa (Business Entity)
Obiekt biznesowy typu Business Entity jest szczególnym przykładem grupy obiektów biznesowych, od której zależą inne obiekty biznesowe (Supplements i Dependents). Cała grupa opisuje modelowaną jednostkę biznesową (wielkość funkcjonalna). Często zdarza się, że jednostka biznesowa jest modelowana tylko przez jeden obiekt biznesowy.
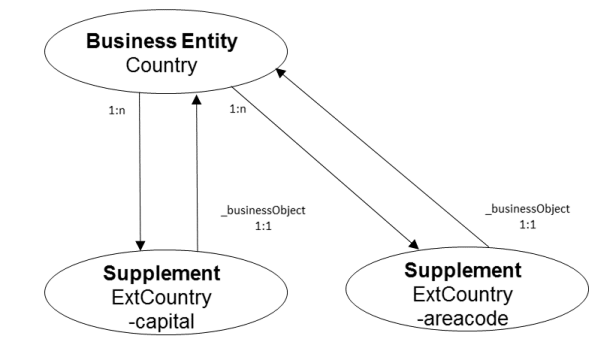
Supplement
Obiekt biznesowy typu Supplement stanowi uzupełnienie nagłówka jednostki biznesowej. Supplement posiada specjalną relację o nazwie „_businessObject”, która wskazuje na powiązanie z nagłówkiem jednostki biznesowej (kardynalność „1-1”). Usługa trwałości systemu ERP wymaga tej (technicznej) relacji, aby zapewnić obsługę dziennika modyfikacji i informacji o zmianach. W przypadku zmiany suplementu, dane te są wprowadzane do nagłówka jednostki biznesowej i suplementu.
Suplementy pełnią tę samą funkcję co rozszerzenia. Mogą być używane do uzupełniania obiektów biznesowych o atrybuty, jednak bez uzupełniania tabeli głównego obiektu biznesowego. Dlatego zalecane jest używanie suplementów zamiast rozszerzeń.
Poniższa ilustracja przedstawia przykład jednostki biznesowej „Country” z dwoma suplementami „ExtCountry”, z których każdy rozszerza główny obiekt BusinessObject o jeden atrybut.
Dependent
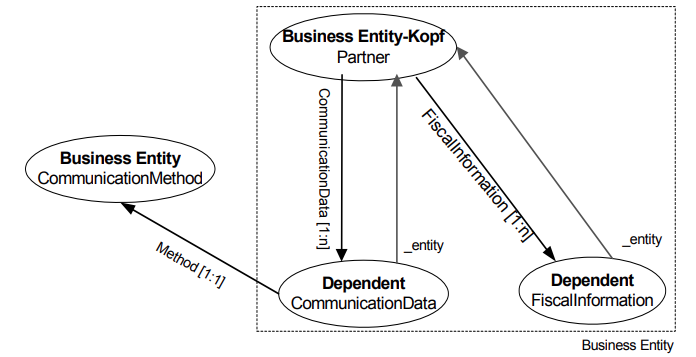
Obiekt biznesowy typu Dependent stanowi uzupełnienie nagłówka jednostki biznesowej. Dependent posiada specjalną relację o nazwie „_entity“, która wskazuje na powiązanie z nagłówkiem jednostki biznesowej (kardynalność „1-1”). Usługa trwałości systemu ERP wymaga tej (technicznej) relacji, aby zapewnić obsługę dziennika modyfikacji i informacji o zmianach. W przypadku zmiany Dependent, dane te są wprowadzane do nagłówka jednostki biznesowej i do Dependent.
Poniższy rysunek przedstawia przykład jednostki biznesowej Partner z wybranymi elementami Dependent „CommunicationData” i „FiscalInformation”. Dodatkowo pokazana jest relacja elementu Dependent „CommunicationData” do jednostki biznesowej „CommunicationMethod”, która nie posiada żadnych elementów Dependent.
Funkcjonalności systemu ERP dla obiektów biznesowych
Jednostka biznesowa jest centralnym elementem wielu rozwiązań funkcjonalnych. Do zarządzania każdą jednostką biznesową służy zazwyczaj dokładnie jedna aplikacja. System automatycznie obsługuje specjalne atrybuty, takie jak
twórca i czas utworzenia, ostatni edytor, czas ostatniej zmiany i system oryginalny. Na poziomie obiektu biznesowego
odbywa się wersjonowanie instancji i definicje obowiązywania zależne od czasu. Dzięki dziennikowi modyfikacji system zapewnia przechowywanie historii zmian obiektu biznesowego. Uprawnienia są również definiowane na podstawie jednostek biznesowych.
W polach jednostek numerów GUI, które reprezentują jednostkę biznesową w interfejsie aplikacji, dostępne są funkcje specjalne. Korzystając z opcji Drag&Drop można zapisać konkretną instancję obiektu biznesowego w ulubionych lub poprzez przeciągnięcie jej na ikonę symbolizującą daną funkcję uruchomić tę funkcję za pomocą tej jednostki jako parametru przeniesienia. Z menu kontekstowego pola jednostki użytkownik przejść do odpowiednich aplikacji i uzyskać dostęp do dalszych właściwości jednostki biznesowej.
Generowane klasy Java
System generuje co najmniej trzy klasy Java na podstawie definicji obiektu biznesowego
trzy klasy Java: klasa główna, klasa state i klasa mapper.
Klasy Java są przechowywane w pakiecie Java odpowiadającym obszarowi nazw pod nazwą obiektu biznesowego (lub z przyrostkiem „_State” lub „_Mapper”).
Deweloper używa głównej klasy w aplikacji do uzyskania dostępu do instancji obiektu biznesowego, podczas gdy klasy state i mapper są wymagane przez usługę trwałości, w celu realizacji dostępu do bazy danych. Klasa główna zawiera metody get…()-, set…()- lub is…()-metody (dla Boolean) umożliwiające dostęp do atrybutów obiektu biznesowego. Odpowiednie metody build..Key() są generowane dla zdefiniowanych indeksów, które są używane do odczytu instancji za pomocą unikalnych wartości klucza z usługą trwałości. Dla wskazanych relacji są generowane metody retrieve…(), które można wykorzystać do wyszukiwania przyporządkowanych obiektów biznesowych.
Atrybuty daty i znacznika czasu
Daty i godziny przechowywane w systemie ERP,tak zwane CisDates, zawsze odnoszą się do danej strefy czasowej.
Strefa czasowa jest określana przez aplikację w momencie wprowadzania. Nie można już zmienić strefy czasowej wprowadzenia daty i godziny. Składnik daty lub godziny jest zawsze przechowywany w bazie danych w odniesieniu do strefy czasowej GMT.
Określenie daty jest zawsze zapisywane w postaci ustandaryzowanej do godziny 0:00. Standaryzacja jest realizowana poprzez pole GUI (CisDateField), a nie automatycznie przez usługę trwałości. W przeciwnym razie jest to zadaniem dewelopera. Istnieją typy dat: CisObjectDate, CisAttributeDate, CisObjectDateUntil i CisAttributeDateUntil (zob.
obszar nazw com.cisag.pgm.datatype).
Określenie znaczników czasowych to specyfikacja daty i godziny. Dostępne typy znaczników czasowych to: CisObjectTimeStamp i CisAttributeTimeStamp.
Wizualizacja zawsze odbywa się w odniesieniu do strefy czasowej poprzez odpowiednie pole GUI (CisDateField). Tylko jeśli strefa czasowa wprowadzenia różni się od strefy czasowej kontekstu czasu wykonywania (runtime),
wyświetlana jest strefa czasowa wprowadzenia.
Typy CisDate: CisObjectDate, CisObjectTimeStamp
Atrybut typu CisObjectDate zapisuje datę znormalizowaną do godziny 0:00 w odniesieniu do strefy czasowej obowiązującej w momencie wpisu. Logiczny typ danych atrybutu musi zawsze pochodzić od logicznego typu danych
com.cisag.pgm.datatype.CisObjectDate.
Atrybut typu CisObjectTimeStamp zapisuje czas w odniesieniu do strefy czasowej obowiązującej w momencie wpisu. Logiczny typ danych atrybutu musi zawsze pochodzić od logicznego typu danych com.cisag.pgm.datatype.CisObjectTimeStamp.
Jeśli obiekt biznesowy zawiera atrybut tego typu, atrybut _timeZoneGuid jest automatycznie dodawany do obiektu biznesowego.
Przechowuje on identyfikator GUID strefy czasowej wprowadzania dla wszystkich atrybutów typu
typu CisObjectDate i CisObjectTimeStamp. Oznacza to, że wszystkie te atrybuty muszą odnosić się do tej samej strefy czasowej. Atrybut _timeZoneGuid jest uzupełniany odpowiednią wartością przez aplikację. Po pierwszym zapisaniu instancji obiektu biznesowego wartość tego atrybutu nie może być już zmieniona.
Typy CisDate: CisAttributeDate, CisAttributeTimeStamp
Atrybut typu CisAttributeDate zapisuje datę znormalizowaną do godziny 0:00 w odniesieniu do danej strefy czasowej. Logiczny typ danych atrybutu musi zawsze pochodzić od logicznego typu danych
com.cisag.pgm.datatype.CisAttributeDate.
Atrybut typu CisAttributeTimeStamp zapisuje czas w odniesieniu do danej strefy czasowej. Logiczny typ danych atrybutu musi zawsze pochodzić od logicznego typu danych com.cisag.pgm.datatype.CisAttributeTimeStamp.
Logiczne typy danych są oparte na specjalnej cząstce com.cisag.sys.kernel.obj.CisDate, która oprócz informacji o czasie zawiera również identyfikator GUID właściwej strefy czasowej. Oznacza to, że te atrybuty obiektu biznesowego mogą odnosić się do różnych stref czasowych, ponieważ każdy z nich zapisał własną strefę czasową wprowadzenia/wpisu.
Typy CisDate: CisObjectDateUntil, CisAttributeDateUntil
Atrybut typu CisObjectDateUntil jest specjalnym atrybutem CisObjectDate. Logiczny typ danych atrybutu musi zawsze pochodzić od logicznego typu danych com.cisag.pgm.datatype.CisObjectDateUntil.
Atrybut typu CisAttributeDateUntil jest specjalnym atrybutem CisAttributeDate. Logiczny typ danych atrybutu musi zawsze pochodzić od logicznego typu danych com.cisag.pgm.datatype.CisAttributeDateUntil.
Te typy są używane do określania „daty do” w przedziale czasu. Do wskazanej daty jest automatycznie dodawany jeden dzień, a wartość ta jest zapisywana w bazie danych. Natomiast na potrzeby wizualizacji od zapisanej daty odejmowany jest jeden dzień, przez co użytkownik nie dostrzega się różnicy.
Java-Klasse CisDate
Atrybut typu CisObjectDate, CisObjectTimeStamp, CisAttributeDate lub CisAttributeTimeStamp w wygenerowanych klasach Java obiektu biznesowego posiada typ com.cisag.pgm.datatype.CisDate . Instancja CisDate reprezentuje konkretną wartość atrybutu. Za pomocą metod getTimeZoneGuid() można uzyskać dostęp do
GUID strefy czasowej wprowadzania, a za pomocą metody getDate() do wartości TimeStamp.
Dla rozwoju aplikacji dostępne są specjalne pola GUI (com.cisag.pgm.gui.CisDateField itd.), które mogą bezpośrednio obsługiwać instancje CisDate. Klasa pomocnicza com.cisag.pgm.util.CisDateUtility udostępnia metody do tworzenia instancji CisDate i wykonywania operacji takich jak zaokrąglanie i przenoszenie na CisDates.
Primitiver Datentyp TimeStamp
Techniczne lub bezwzględne specyfikacje czasu nie wymagają definicji strefy czasowej, np. granice przedziałów obowiązywania lub techniczne punkty w czasie (data i godzina), np. czas zmiany jednostki. Takie atrybuty są oparte na prymitywnym typie danych systemu ERP TimeStamp i nie zawierają informacji o strefie czasowej. Określenie czasu jest konwertowane bezpośrednio na strefę czasową kontekstu czasu wykonywania i wizualizowane bez określania strefy czasowej.
Zatem w generowanych klasach Java obiektu biznesowego atrybut posiada typ java.util.Date.
Zależność czasowa
Atrybuty validFrom i validUntil obiektu biznesowego zależnego od czasu mogą być oparte na specyfikacji daty lub punktu w czasie (data i godzina) z uwzględnieniem strefy czasowej. W punkcie „Zależny od czasu” obiektu biznesowego można określić, który typ daty będzie używany dla tych atrybutów:
- Data ze strefą czasową przez aplikację: atrybuty mają typ CisObjectDate
- Punkt w czasie (data i godzina) ze strefą czasową przez aplikację: atrybuty mają typ CisObjectTimeStamp
Ustawienia te należy wybrać odpowiednio dla obiektu biznesowego, jeśli strefa czasowa ma być uwzględniana w prezentowanym okresie obowiazywania. Atrybuty validFrom i validUntil są generowane w klasach Java jako java.util.Date.
Data-Description-LDT i Data-Description-Column
Dla Data Description istnieją dwa typy obiektów deweloperskich:
- Data Description LDT
- Data Description Column
Chociaż mają one te same właściwości, różnią się poziomami odniesienia. Data Description LDT tworzy jednostkę z
logicznym typem danych (identyczny obszar nazw i identyczna nazwa obiektu deweloperskiego). Opisuje ona zachowanie logicznych typów danych w interfejsie użytkownika. Poprzez zastosowanie logicznych typów danych typu „logiczny”, hierarchia dziedziczenia jest niejawnie mapowana na powiązane Data Descriptions.
W tym celu dla logicznych typów danych musi być zdefiniowany Data Description LDT. Następnie jest on wykorzystywany do określenia, czy wartości mają pochodzić z dziedziczenia, czy też mają być jawnie podane.
Data Description Column jest przyporządkowana dokładnie jednej ścieżce atrybutu obiektu biznesowego, cząstki (part) lub rozszerzenia, przy czym również opisuje zachowanie w interfejsie użytkownika. Może dziedziczyć od Data Description LDT należącego do logicznego typu danych atrybutu. Ścieżka do atrybutu może zostać przeniesiona do elementów wizualnych. W ten sposób Data Description Column jest realizowana i prezentowana. Jeśli dla atrybutu nie zdefiniowano Data Description Column, stosuje się Data Description LDT logicznego typu danych atrybutu.
Nazwa obiektu deweloperskiego dla Data Description Column ma następującą budowę:
<obszar nazw obiektu biznesowych>.<nazwa obiektu biznesowego
>:<nazwa atrybutu>
Jeśli dla atrybutu obiektu biznesowego istnieją oba typy DataDescription, wówczas priorytet posiada Data Description Column.
Plik
Obiekt deweloperski „File” może być używany do przechowywania różnych plików w bazie danych repozytorium. Te obiekty w formie plików mogą być np. szablonami dokumentów. Dostęp do nich można uzyskać za pośrednictwem interfejsu PGM com.cisag.pgm.util.FileLogic.
Zdarzenie
Obiekt deweloperski „Zdarzenie” jest stosowany w przepływie pracy, aby definicje aktywności tworzone dla
poszczególnych zdarzeń, mogły wygenerować aktywności, gdy wystąpią poszczególne zdarzenia. Obiekt deweloperski „Zdarzenie” może realizować zdarzenie wynikające z określonego stanu aplikacji, które jest przetwarzane przez przepływ pracy. Zdarzenia są rejestrowane w repozytorium i definiowane podczas programowania aplikacji. Zdarzenia mogą być wyzwalane za pośrednictwem interfejsu programistycznego. W interfejsie
com.cisag.pgm.appserver.CisSystem-Manager dostępne są metody o nazwie fireEvent z różnymi parametrami, za pomocą których są realizowane zdarzenia. Zdarzenia zawsze mają odniesienie do bazy danych.
Rozszerzenie
do tego samego co rozszerzenia, ale nie rozbudowują tabeli obiektu biznesowego ze standardu.
Rozszerzenie jest używane do wprowadzania przez partnerów modyfikacji obiektów biznesowych lub
cząstek (parts) ze standardu (tj. z obszaru nazw com.cisag). Poprzez rozszerzenia można uzupełniać o dodatkowe atrybuty definicje cząstki lub definicje obiektu biznesowego, któe zostały utworzone przez Comarch
Software und Beratung AG. Dzięki temu wygenerowane JavaSources zawierają nie tylko atrybuty zdefiniowane przez Comarch Software und Beratung AG, ale także atrybuty pochodzące ze wszystkich powiązanych rozszerzeń. Źródła
rozszerzonego obiektu biznesowego są zastępowane nowymi źródłami, tzn. zmiany są dokonywane w katalogu źródłowym w ścieżce „com.cisag”. Podczas dodawania atrybutów przestrzegana jest konwencja nazewnictwa, tak aby uniknąć konfliktów spowodowanych zduplikowanymi nazwami atrybutów z różnych rozszerzeń. Nazwa nowego atrybutu jest poprzedzona prefiksem deweloperskim, np. w poniższym przykładzie jest to skrót „ABC_”. Rozszerzenia
są zorganizowane w obszarach nazw, gdzie posiadają unikalną nazwę. Obszar nazw rozszerzenia
mieści się poza „com.cisag…” w obszarze nazw prefiksu deweloperskiego.
Software und Beratung AG atrybuty a i b, ale ma zostać rozszerzona dla firmy
„ABC” o atrybut c. W tym celu zostaje utworzone rozszerzenie „com.abc.app.general.obj. ExtensionPart1” oparte na cząstce „com.cisag.app.general.obj.Part1“, która ma zostać rozszerzona. Do rozszerzenia dodany zostaje atrybut o nazwie „abc_c”. W wygenerowanych klasach cząstki wygląda to tak, jakby Comarch Software und Beratung AG już zdefiniował atrybut abc_c. Rozszerzona cząstka jest w pełni kompatybilna z cząstką podstawową. Wszystkie miejsca w aplikacji, które używają atrybutów a i b, nadal działają. Partner musi jedynie zająć się miejscami, dla których
istotny jest atrybut c. Miejsca te znajdują się poza paczkami „com.cisag…”. Aplikacja, która ma zostać dostosowana przez partnera, znajduje się w obszarze nazw z prefiksem „abc”. Gdy rozszerzenie jest tworzone lub usuwane, numer wersji podstawowego obiektu biznesowego lub cząstki przyjmuję wyższą wartość i jest uwzględniany w zadaniu deweloperskim nowego generowania źródeł Java.
Obszar (Framework)
Obszary są wykorzystywane do tematycznego grupowania aplikacji. Wszystkie licencjonowane obszary są widoczne w panelu nawigacji. Aplikacje znajdują się w odpowiednich obszarach.
Zdolność
Zdolność jest kompetencją przydzielaną w systemie ERP na poziomie programowania do obsługi określonych działań, widoków itp.
Zdolność usuwania działań w przepływie pracy.
CisSystemManager sm = CisEnvironment.getInstance()
.getSystemManager();
if (!sm.isAuthorized("com.cisag.sys.workflow.DeleteActivities.cap")){
mm.sendMessage("WFL", 250);
return;
}
Funkcja
W celu dostosowania procesów w systemie ERP bez konieczności zmian w aplikacjach, istnieje możliwość definiowania funkcji. W aplikacji Konfiguracja funkcje mogą być aktywowane i parametryzowane dla każdego systemu, każdej bazy danych OLTP lub każdej jednostki organizacyjnej. Aplikacje używają następnie tych ustawień jako ustawień domyślnych lub nie wyświetlają niepotrzebnych elementów, jeśli funkcja jest dezaktywowana.
Obiekt pomocy
Pliki pomocy, które są wyświetlane w pomocy online systemu ERP. Ten obiekt deweloperski obejmuje zarówno pliki źródłowe i docelowe.
Ikona (symbol)
Definicja właściwości ikon używanych w elemencie graficznym lub akcji. Nowe ikony powinny być tworzone w obszarze nazw .res lub .res2d, ta reguła nie jest sprawdzana. W przeciwieństwie do wszystkich innych obiektów deweloperskich nazwa tego obiektu deweloperskiego zaczyna się od małej litery i zawiera specyfikację rozmiaru ikony (np. -16×16). System nie sprawdza obszaru nazw, ani nazwy obiektu deweloperskiego pod kątem wspomnianych ograniczeń. Są one opcjonalne i służą zachowaniu czytelności.
Klasa Java
Obiekt Klasa Java obsługuje źródła i klasy Java.
Klucz licencyjne
Klucze licencyjne służą do dezaktywacji funkcji lub zestawu funkcji. Jeśli dla funkcji zostanie wprowadzony klucz licencyjny, który nie jest licencjonowany, wówczas funkcja nie jest widoczna w aplikacji Konfiguracja i nie można z niej korzystać.
Logiczny typ danych
Struktura typów w systemie ERP opiera się na logicznych typach danych. Logiczny typ danych odpowiada (w przybliżeniu) typedef w języku C lub domenie w obszarze bazy danych. Logiczne typy danych są zorganizowane w
obszarach nazw, gdzie posiadają unikalną nazwę. Logiczny typ danych zawsze posiada znaczenie techniczne, które powinno być również wyrażone w nazwie. Logiczne typy danych są dostępne jako typy prymitywne, złożone i logiczne. Typ danych każdego atrybutu obiektu biznesowego jest zdefiniowany poprzez logiczny typ danych.
Logiczny typ danych typu prymitywny
Logiczny typ danych typu prymitywnego opiera się na prymitywnych typach systemu ERP, z których każdy może przybrać tylko jedną wartość elementarną. W wygenerowanych klasach Java te typy danych są zastępowane odpowiednimi typami danych Java. Jeśli logiczny typ danych o typie „prymitywny” jest używany bezpośrednio w definicji atrybutu, wówczas atrybut odpowiada dokładnie jednej kolumnie tabeli w bazie danych.
w tabeli bazy danych obiektu biznesowego na przykład w DBMS Oracle miałaby typ „NVARCHAR2”.
Logiczny typ danych typu logiczny
Logiczny typ danych typu logiczny jest funkcjonalnym doprecyzowaniem (specjalizacją) innego logicznego typu danych. Może być być oparty na wszystkich typach (prymitywny, złożony, logicznych); przy czym relacja dziedziczenia nie może być cykliczna. Ten logiczny typ danych przyjmuje właściwości wyjściowego logicznego typu danych. Relacja dziedziczenia jest ponadto używana do definiowania właściwości GUI poprzez przyporządkowanie Data Description.
Logiczny typ danych typu złożony
Logiczny typ danych typu złożony opiera się na definicji PartDefinition, która opisuje strukturę danych. W ten sposób realizowane są złożone atrybuty obiektu biznesowego.
Komunikat
Komunikat jest wiadomością dla użytkownika. Informuje o wyniku działania lub o określonym statusie aplikacji.
stanu aplikacji. Nazwa obiektu deweloperskiego to numer komunikatu, który jest przypisywany automatycznie lub przez użytkownika podczas tworzenia nowego komunikatu. Numer komunikatu musi być unikalny w klasie komunikatów.
W kodzie źródłowym komunikaty są wywoływane przez MessageManager. Komunikaty są ustalane i wyświetlane w systemie za pomocą klasy i numeru komunikatu.
CisEnvironment env = CisEnvironment.getInstance(); CisMessageManager mm = env.getMessageManager(); mm.sendMessage(„APP“, 100, „Parameter1“, „Parameter2“);
Klasa komunikatu
Komunikat jest przyporządkowany do klasy komunikatów, która wskazuje na jej przynależność. Klasa komunikatów posiada obszar nazw. Na przykład, istnieje klasa komunikatów APP (Application), do której należą
ogólne komunikaty dla aplikacji, klasa komunikatów SYS (System) dla komunikatów systemowych oraz klasa komunikatów EDU (Education) dla aplikacji szkoleniowych.
Klasa komunikatów jest identyfikowana poprzez obszar nazw i nazwę. Nazwa zazwyczaj składa się z trzech wielkich liter. Możliwe jest również dodanie opisu kontekstu. Klasa komunikatów może być traktowana jako alias dla obszaru nazw. Dlatego nazwa może być przypisana tylko raz.
Obszar nazw
Typ obiektu deweloperskiego Obszar nazw został szczegółowo opisany w rozdziale Obszary nazw.
Wyszukiwanie OQL
Wyszukiwania OQL są stosowane głównie jako pomoc wyszukiwania wartości dla pól wprowadzania danych. W przypadku małych ilości danych zwykle wyświetlana jest lista wyboru, a w przypadku dużych ilości danych – okno dialogowe.
Oprócz tego wyszukiwania OQL mogą być używane dla aplikacji zapytań np. bezpośrednio w programach, w celu odczytu danych z bazy na podstawie zdefiniowanych kryteriów.
Podobnie jak wszystkie inne typy obiektów deweloperskich, również wyszukiwanie OQL jest identyfikowane za pomocą kombinacji obszaru nazw i nazwy.
Wyszukiwanie OQL definiuje tylko metadane dla wyszukiwania. Dopiero w czasie wykonywania procesu z metadanych jest tworzone OQL dla wyszukiwania.
Metadane wyszukiwania OQL obejmują stosowane obiekty biznesowe, definicję relacji między obiektami biznesowymi, stosowane atrybuty obiektów biznesowych oraz kryteria wyszukiwania. Dla poszczególnych atrybutów
wyszukiwania można zdefiniować, czy mają one być używane jako kryterium wyszukiwania, do wyświetlania, do zwracania czy do sortowania. Atrybuty są sortowane dla każdej właściwości według numeracji. Jeśli atrybut nie ma numeru dla właściwości, wówczas ten atrybut nie będzie używany dla właściwości. Do zastosowania jako kryterium wyszukiwania i atrybut wyświetlania można wskazać każdy logiczny typ danych, który jest używany dla poszczególnych wizualizacji.
Z uwagi na wydajność wyszukiwanie OQL może być podzielone na fragment podstawowy i
dowolną liczbę fragmentów dodatkowych. Fragmenty dodatkowe są uwzględniane tylko w OQL, jeśli co najmniej jeden zawarty w nim atrybut używany jest jako kryterium wyszukiwania lub służy do sortowania.
Wyszukiwaniem można manipulować programowo-technicznie za pomocą klasy Java Hook. Można sterować interfejsami z obszaru nazw com.cisag.pgm.objsearch. Po zaimplementowaniu tych interfejsów możliwe jest na przykład wyświetlenie wyników wyszukiwania w postaci listy zamiast zamiast zwykłej tabeli.
Jeśli wyszukiwanie jest wykonywane w programie, logiczne typy danych, Hook itp. mogą nie być używane.
Widok OQL
Często zdarza się, że wielokrotnie wymagany jest obiekt biznesowy zawierający dodatkowe dane, pochodzące z innych referencyjnych obiektów biznesowych w aplikacjach. Zamiast pobierać obiekt biznesowy i referencyjne obiekty poprzez relacje i wybierać odpowiednie atrybuty lub stosować zawsze tę samą instrukcję OQL, można zastosować łatwiejsze rozwiązanie: utworzyć widok (view) żądanych informacji. Widok ten można stosować w aplikacji jak normalny obiekt biznesowy, z tym ograniczeniem, że dane są tylko do odczytu. Zmiany można więc wprowadzać w centralnej lokalizacji. Widok danych jest określany w postaci instrukcji OQL. Nie ma żadnych ograniczeń dotyczących stosowania joins i klauzul WHERE, dzięki czemu możliwe jest tworzenie złożonych instrukcji zapytań.
Definicja widoku OQL zawiera obszar nazw i nazwę, które służą do jednoznacznej identyfikacji widoku. Opis żądanego wyniku tworzony jest za pomocą instrukcji SELECT w zapisie OQL, którą musi sformułować programista. Instrukcję OQL można przetestować interaktywnie za pomocą aplikacji Polecenia OQL w obszarze Rozwój Oprogramowania.
System (narzędzie crtbo) generuje trzy klasy Java z definicji widoku OQL: trzy klasy Java: klasa główna, klasa state i klasa mapper. Klasy te są przechowywane w pakiecie Java odpowiadającym obszarowi nazw pod nazwą widoku OQL (lub z przyrostkiem „_State” lub „_Mapper”). Deweloper używa głównej klasy w aplikacji, aby uzyskać dostęp do instancji widoku OQL, podczas gdy klasy state i mapper są wymagane przez usługę trwałości danych do uzyskania dostępu do baz danych.
Klasa główna zawiera metody get…() lub is…() (boolean) do uzyskania dostępu do atrybutów widoku oraz metodę buildPrimaryKey() do ładowania instancji za pomocą klucza podstawowego. Widok zachowuje się w aplikacji podobnie jak obiekt biznesowy, ma jednak tylko możliwość odczytu.
Widok bazy danych jest tworzony w bazie danych, przy czym instrukcja OQL jest konwertowana przez system na instrukcję SQL, która używa tego widoku bazy do utworzenia wirtualnej tabeli bazy danych.
Poniższy rysunek przedstawia przykładowy widok OQL. Dostarcza on dla JobDescription klucz biznesowy jednostki organizacyjnej (klucz obcy dla obiektu biznesowego Partner). Atrybutom zdarzeń przypisywana jest unikalna nazwa poprzez skrót as lub askey. Atrybuty tworzące klucz podstawowy widoku OQL są oznaczone skrótem askey.
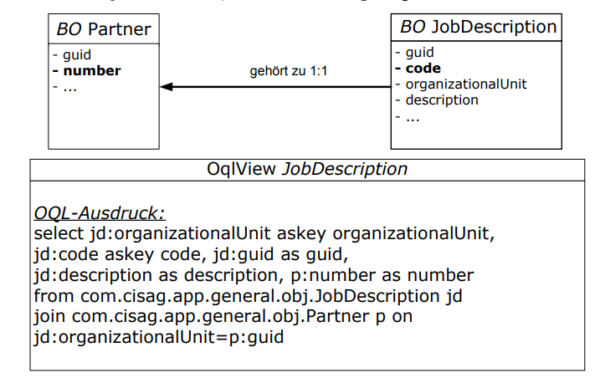
Część (Part)
Definicja części (w skrócie: część) służy do realizacji złożonych atrybutów obiektów biznesowych. Cząstka definiuje strukturę danych, która skupia grupę atrybutów pod jedną określoną nazwą. Złożone atrybuty nie mają własnego klucza, ale są częścią obiektu biznesowego. Części umożliwiają ponowne wykorzystanie raz zamodelowanych struktur danych dla różnych obiektów biznesowych. Definicja części może również określać relacje z innymi obiektami biznesowymi. Część nie może być jednak obiektem docelowym relacji. Podczas modelowania części można również określić inną część, z której mają być dziedziczone atrybuty. Definicja obiektu biznesowego również może dziedziczyć atrybuty z
części.
Część jest określona poprzez obszar nazw i nazwę. Może posiadać jeden lub więcej przypisanych atrybutów. Nie posiada własnej tabeli w bazie danych. Atrybuty części są zapisywane w tabeli obiektu biznesowego.
Dla definicji części jest generowane wiele klas Java, które służą do uzyskania dostępu do instancji części w aplikacji:
- klasa immutable do odczytu atrybutów części
- klasa mutable do odczytu i zapisu atrybutów części
Definicja części com.cisag.app.general.obj.BankInfo opisuje strukturę informacji bankowej. Zdefiniowano następujące atrybuty:
| Atrybut | Logiczny typ danych | Prymitywny typ danych |
| bankCountry | ..BankInfoBankCountry | guid |
| bankCode | ..BankInfoBankCode | guid |
| bankBranch | ..BankInfoBankBranch | guid |
| bankAccount | ..BankInfoBankAccount | str(30) |
| iban | ..BankInfoIban | str(40) |
| swift | ..BankInfoSwift | str(11) |
| accountHolder | ..BankInfoAccountHolder | str(80) |
Dodatkowo definicja części posiada następujące relacje:
| Relacja | Docelowy obiekt biznesowy | Kardynalność |
| Bank bankCode |
com.cisag.app.general.obj. Bank guid |
1-1 |
| BankBranch bankBranch |
com.cisag.app.general.obj. BankBranch guid |
1-1 |
| BankCountry bankCountry |
com.cisag.app.general.obj. Country guid |
1-1 |
Wygenerowana jest klasa immutable com.cisag.app.general.obj.BankInfo, która posiada jedynie metody odczytu atrybutów, np. getBankCountry(), getBankCode() itp. Nie ma metod do zmiany wartości atrybutów. Dzięki relacjom tej części istnieją również metody dla relacji, np. metoda retrieveBank(). Istnieje również klasa mutable com.cisag.app.
general.obj.BankInfoMutable, która dodatkowo posiada metody do zmiany atrybutów, np. setBankCountry(), setBankCode() itp.
Stringtable
Tabela ciągów jest specjalnym obiektem deweloperskim, który służy do odłączania
tekstów i kodu źródłowego. Nie zaleca się wpisywania tekstów bezpośrednio do kodu źródłowego, ponieważ trudno jest przetłumaczyć teksty wprowadzone w ten sposób lub zmienić bez konieczności ponownej kompilacji źródeł. Tabela ciągów obsługuje teksty używane przez aplikację.
Tabele ciągów stanowią jeden ze sposobów realizacji tego zadania w systemie ERP. Jeśli to możliwe, należy korzystać z dedykowanych obiektów deweloperskich, takich jak logiczne typy danych, akcje i zestawy wartości. Tabele ciągów powinny być używane tylko wtedy, gdy wszystkie inne opcje nie są nieodpowiednie.
Do każdej stałej są przyporządkowywane teksty. Tekst jest wprowadzany dla stałej w aktualnie ustawionym języku programowania, tzn. w jednej stałej można wprowadzić po jednym tekście w każdym języku. Aby wprowadzić tekst w innym języku programowania, należy najpierw zmienić język w ustawieniach użytkownika. Z reguły istnieje jeden predefiniowany język programowania. W kodzie źródłowym, zamiast konkretnego tekstu, określana jest odpowiednia stała tabeli ciągów. Tekst jest pobierany z zapisanych wpisów zgodnie z aktualnie ustawionym językiem wyświetlania w czasie działania programu.
Tabela ciągów posiada obszar nazw i nazwę. Jeśli tabela ciągów jest używana dla jednego określonego obszaru tematycznego, to stosowany jest główny obszar tematyczny (zapisywane są teksty dla danego obszaru tematycznego).
Nazwa często pochodzi od obsługiwanej jednostki biznesowej, np. Stringtable com.cisag.app.sales.BonusAgreement.
W podrzędnym obszarze nazw jest tworzona tabela ciągów, która służy jako uzupełnienie do jednej lub więcej określonych powiązanych ze sobą klas Java, np. z jednej aplikacji.
Stringtable com.cisag.app.crm.ui.OpportunityMaintenance
Poniżej przedstawiono tabelę ciągów com.cisag.app.general.partner.ui.PartnerIdentArea. Zawiera ona kilka stałych, dla których zapisane są teksty w językach programowania
(niemiecki, angielski, …).
Aby wykonać zapytanie o tekst dla stałej w aktualnie ustawionym języku wyświetlania, należy użyć metody getText() klasy com.cisag.pgm.util.RepositoryInfo z następującymi sygnaturami:
public static String getText(String absPath); public static String getText(String path, String constant);
getText()
Zapytanie o tekst przez ścieżkę absolutną:
RepositoryInfo.getText("com.cisag.app.general.partner.ui.PartnerIdentArea:PRIVATEADDRESS.txt");
Zapytanie o tekst przez ścieżkę względną:
RepositoryInfo.getText("com.cisag.app.general.partner.ui.PartnerIdentArea", "PRIVATEADDRESS");
Do elementów GUI przekazywany jest zazwyczaj nie tekst, ale ścieżka tabeli ciągów. Np. GroupBox jest generowane w następujący sposób:
GroupBox box = new GroupBox("0060...8010","absoluteStringTablePath");
A nie w ten sposób:
GroupBox box = new GroupBox(("0060...8010",getText(" absoluteStringTablePath "));
Termin
Obiekt deweloperski Termin umożliwia przenoszenie i korzystanie z terminów obsługiwanych w Trados Multiterm. Terminy są importowane do repozytorium za pomocą aplikacji Import terminów. Ten obiekt deweloperski można edytować tylko za pomocą aplikacji TradosMultiterm. Terminy są zawsze przechowywane w obszarze nazw
com.cisag.app.terminus. Nazwa obiektu deweloperskiego jest numerowana (00001 …).
Przebieg testowy (Test Run)
Przebieg testowy to definicja powtarzalnego scenariusza testowania aplikacji. Istnieją dwie różne możliwe definicje przebiegów testowych:
- Definicja ogólna – w tej definicji można wskazać obszar nazw. Przebieg testowy uwzględnia wszystkie aplikacje zdefiniowane w tym obszarze nazw. Ten typ definicji jest używany do testowania ogólnej funkcjonalności aplikacji.
- Definicja konkretna – zawiera wszystkie aplikacje i testy. Oznacza to, że zestaw aplikacji
i testów jest taki sam podczas rejestracji, jak i podczas wykonywania. Ta definicja może również zawierać specjalne testy, które można zdefiniować dla jednej aplikacji.
Tekst
Dla każdego obiektu deweloperskiego zawierającego tekst, który można przetłumaczyć, istnieje dokładnie jeden dodatkowy obiekt deweloperski typu Tekst.
Obiekt tekstowy zawiera wszystkie wprowadzone teksty w poszczególnych językach. Obszar nazw jest taki sam jak obszar nazw powiązanego obiektu deweloperskiego. Nazwa obiektu deweloperskiego zawiera typ tekstu
i nazwę powiązanego obiektu deweloperskiego (<typ tekstu>_<nazwa obiektu deweloperskiego>). Obiekt tekstowy
jest tworzony automatycznie podczas tworzenia powiązanego obiektu deweloperskiego. Jeśli w obiekcie deweloperski, zostanie zmieniony tekst, to automatycznie następuje zmiana obiektu tekstowego i blokada w bieżącym zadaniu deweloperskim. Teksty mogą być również zmieniane za pomocą Panelu Redakcja poza repozytorium.
Zestaw wartości (Valueset)
Zestaw wartości jest określonym zbiorem wartości podobnym do konstrukcji type istniejącym np. w Pascalu. Uzupełnieniem są elementy ValueSet, które zawierają konkretne specyfikacje zestawu. Każdy element składa się z wartości short, nazwy i oznaczenia. Domyślnie dla każdego zestawu wartości generowana jest powiązana klasa Java, w której zdefiniowane są stałe (static final short). Nazwa elementu ValueSet jest stosowana jako nazwa stałej, a wartość short jako wartość stałej. Oznaczenie podlega tłumaczeniu i jest używane do prezentacji GUI elementu.
Numery stosowane w ID są zdefiniowane. System deweloperski partnera może stosować tylko numery z zakresu od 3001 do 3999, a system dostosowań klienta od 6001 do 6999, aby uniknąć nakładania się numerów podczas rozszerzania zestawu wartości.
Stałe nie powinny być używane do operacji bitowych, ponieważ partner nie ma wtedy możliwości rozszerzenia ValueSet.
Poniższa tabela prezentuje przykładowy zestaw wartości com.cisag.app.general.CommunicationMedia:
| ID | Stała | Oznaczenie |
| 1 | ||
| 2 | TELEFAX | faks |
| 3 | TELEPHONE | telefon |
| 4 | TELEX | teleks |
| 5 | URL | www |
Odpowiednia klasa Java musi zostać wygenerowana dla zestawu wartości. Odbywa się to za pomocą narzędzia crtvs, które jest wykonywane w wierszu poleceń
wiersza poleceń SAS. Określając parametr „-j:nummer”, generowane są wszystkie zestawy wartości zawarte w zadaniu programistycznym.
Generowane są wszystkie zestawy wartości zawarte w zadaniu programistycznym:
Do zestawu wartości musi zostać wygenerowana powiązana klasa Java. Służy do tego narzędzie crtvs, które jest uruchamiane w wierszu poleceń SAS. Poprzez określenie parametru „-j:nummer” generowane są wszystkie zestawy wartości zawarte w zadaniu deweloperskim:
crtvs –j:nummer
Wygenerowana klasa znajduje się w paczce odpowiadającej obszarowi nazw zestawu wartości, w katalogu roboczym zadania deweloperskiego i nosi nazwę zestawu wartości.
Wersje obiektów deweloperskich
Podczas przetwarzania obiektu deweloperskiego w ramach zadania deweloperskiego zawsze tworzona jest nowa wersja obiektu. Gdy tworzony jest nowy obiekt deweloperski, powstaje jego pierwsza wersja. Dopóki zadanie nie zostanie zakończone, wersja ta nie jest jeszcze aktywna w systemie, ale istnieje tylko w zadaniu deweloperskim. Taka wersja może zatem zostać usunięta bez konieczności jej archiwizowania. Po aktywacji zadania nowa wersja staje się aktywną wersją w systemie. Po usunięciu obiektu deweloperskiego tworzona jest nowa wersja, która jest oznaczona znakiem „+” na końcu numeru wersji jako usunięta.
Obiekt deweloperski posiada sześcioczęściowy numer wersji. Za nim, oddzielona dwukropkiem, znajduje się
nazwa systemu, w którym powstała ta wersja. Typ systemu ERP, w którym obiekt deweloperski został utworzony lub
lub zmodyfikowany, określa, która część numeru wersji będzie zwiększana. Do zapisu stosuje się zasadę pomijania zer po prawej stronie. W przypadku starszych wersji możliwe jest, że nazwa systemu nie jest częścią numeru wersji. Istnieją następujące typy systemu:
- Wewnętrzny system deweloperski (etap 1): System w Comarch Software und Beratung AG, w którym rozwijana jest kolejna wersja wydania. Podczas tworzenia nowych obiektów lub zmiany istniejących podnoszona jest pierwsza część numeru wersji.
- Wewnętrzny system korekt (etap 2): W wewnętrznym systemie korekt następuje włączenie korekt do wydawanego systemu. System korekt istnieje dla każdej wersji wydania tak długo, dopóki wersja wydania jest utrzymywana przez Comarch Software und Beratung AG. Podczas tworzenia nowych obiektów lub zmiany istniejących podnoszona jest druga część numeru wersji.
- Rozwiązanie dla branż partnera (etap 3): System rozwiązań dla branż partnera jest rozwinięciem systemu dla konkretnej branży. Podczas tworzenia nowych obiektów lub zmiany istniejących podnoszona jest trzecia część numeru wersji.
- System korekt dla branż partnera (etap 4): W tym systemie implementowane są poprawki do wersji wydania dla rozwiązań branżowych partnera. Podczas tworzenia nowych obiektów lub zmiany istniejących podnoszona jest czwarta część numeru wersji.
- System dostosowań klienta (etap 5 lub 6): System zawiera konkretne dostosowania rozwiązania dla branż partnera lub wersji wydania w Comarch Software und Beratung AG do specyficznych potrzeb klienta. Podczas tworzenia nowych obiektów lub zmiany istniejących podnoszona jest szósta część numeru wersji.
- System produkcyjny (etap 7): System używany przez klienta w jego lokalizacji. W systemie produkcyjnym nie można dodawać, ani zmieniać żadnych obiektów deweloperskich.
Poniższa tabela przedstawia strukturę numeracji wersji (bez określania systemu)
| Pozycja | Stosowane przez system typu | Wersja obiektu |
| 1 | System deweloperski Comarch Software und Beratung AG | Numer wersji głównej |
| 2 | System korekt Comarch Software und Beratung AG | Numer wersji korekt |
| 3 | System rozwiązania dla branż partnera | Numer wersji głównej |
| 4 | System rozwiązania dla branż partnera | Numer wersji korekt |
| 5 | System dostosowań klienta | Numer wersji dostosowań klienta |
| 6 | System dostosowań klienta | Numer wersji dostosowań klienta |
Przykład sposobu liczenia wersji dla obiektu biznesowego:
- Po utworzeniu obiektu biznesowego w systemie deweloperskim Comarch Software und Beratung AG obiekt ma numer wersji 1.0.0.0.0 (w skrócie 1) i zostaje wydany.
- Partner rozwija rozwiązanie branżowe oparte na tym wydaniu i dostosowuje obiekt biznesowy. Obiekt otrzymuje numer wersji 1.0.1.0.0.0 (w skrócie 1.0.1) w opracowanym rozwiązaniu branżowym partnera.
- Po dwóch korektach rozszerzenia przez partnera w systemie korekt rozwiązania branżowego do wydanego rozwiązania branżowego obiekt biznesowy otrzymuje numer wersji 1.0.1.2.0.0
(w skrócie 1.0.1.2). - W systemie dostosowań klienta opartym o rozwiązanie branżowe partnera, obiekt biznesowy zostaje ponownie zmieniony. W tym systemie otrzymuje numer wersji 1.0.1.2.0.1.
- W systemie dostosowań klienta opartym na standardowym wydaniu Comarch Software und Beratung AG obiekt biznesowy zostaje zmieniony. Oznacza to, że w tym systemie jego numer wersji to 1.0.0.0.0.1.
Usługa trwałości danych
Dla aplikacji systemu ERP usługa trwałości danych jest interfejsem służącym di wczytywania i zapisywania danych z bazy. Programista aplikacji korzysta głównie z menedżera transakcji i menedżera obiektów.
Usługa trwałości danych odpowiada za połączenie bazy danych z systemem. Realizuje dostępy do bazy danych wymagane przez aplikację i kapsułkują przy tym specyficzne cechy używanego DBMS. Menedżer obiektów usługi trwałości danych umożliwia aplikacji dwie opcje dostępu do bazy danych. Po pierwsze zapewnia metody odczytu,
tworzenia, zmiany i usuwania na poziomie obiektów biznesowych. Po drugie za pomocą usługi trwałości danych aplikacja może wykonać dowolną instrukcję OQL, w celu załadowania lub zmiany danych.
Usługa trwałości odwzorowuje obiektowy model danych używany w aplikacji na relacyjny model bazy danych. Wymagane komendy SQL są generowane na podstawie instrukcji OQL. Wszystko to odbywa się w sposób przejrzysty dla aplikacji. Wszystkie dostępy do bazy danych w aplikacjach odbywają się w ramach transakcji zarządzanych przez menedżera transakcji.
Pozostałe istotne zadania usługi trwałości danych:
- zarządzanie blokadami na obiektach biznesowych (Lock Service)
- zarządzanie pamięcią podręczną w celu ograniczenia dostępów do bazy danych (Caching)
- zarządzanie otwartymi połączeniami z bazą danych (Connection Pooling)
Manager transakcji
Menedżer transakcji zarządza transakcjami w sesji. Pozwala uruchomić nową transakcję Top Level lub transakcję podrzędną oraz potwierdzić lub anulować transakcję.
Transakcje systemu ERP
Transakcja stanowi klamrę dla operacji zapisu w bazie danych. Składa się z jednej lub więcej akcji w bazie danych, które są wykonywane w całości lub wcale (niepodzielność). Są one jawnie otwierane, zamykane lub anulowane. Zmiany są widoczne dopiero po pomyślnym zakończeniu transakcji. Przerwanie powoduje anulowanie wszystkich poprzednich zmian. Transakcja w systemie ERP odpowiada definicji transakcji w relacyjnych bazach danych, czyli wykazuje właściwości ACID. System ERP obsługuje zamknięte transakcje zagnieżdżone. Oznacza to, że dla transakcji może istnieć transakcja podrzędna o dowolnym stopniu głębokości zagnieżdżenia (głębokość zagnieżdżenia jest obecnie ograniczona do 20 poziomów). Najbardziej zewnętrzna transakcja nazywana jest transakcją Top Level. Zmiany w ramach transakcji podrzędnej będą widoczne po jej pomyślnym zakończeniu również w odpowiedniej transakcji nadrzędnej (parent). Zmiany te będą trwałe dopiero po pomyślnym zakończeniu transakcji Top Level.
Transakcje zagnieżdżone lub podrzędne są zatem transakcjami, które rozpoczynają się i kończą
w ramach istniejącej transakcji parent. Transakcje podrzędne są w tym przypadku nieistotne, tzn. anulowanie podrzędnej nie wymusza anulowania transakcji parent.
Zazwyczaj komponenty oprogramowania są skonstruowane w taki sposób, aby wykonać określoną, odrębną usługę. Z reguły musi to być bezpieczne dla transakcji; komponent może wykonać usługę w całości, albo wcale. Oznacza to, że komponent rozpocznie transakcję i wykona operacje w ramach tej transakcji. Zagnieżdżone wywoływanie komponentów automatycznie oznacza zagnieżdżone transakcje.
Transakcja Top Level i wszystkie jej transakcje podrzędne mieć dostęp do odczytu i zapisu tylko do jednej bazy danych.
Menedżer transakcji zawsze ma zawsze jedną bieżącą transakcję aplikacji w danym momencie. Jeśli transakcja nie została jawnie uruchomiona, wówczas w bazie danych OLTP otwierana jest transakcja dummy. Taka transakcja ma tylko dostęp do odczytu i nie posiada transakcji podrzędnych.
Zarządzanie transakcjami w aplikacji
Menedżer transakcji udostępnia aplikacji niezbędne funkcje do uruchamiania, anulowania i zakończenia transakcji.
Transakcje mogą być otwierane za pomocą „begin” lub „create”. Jeśli transakcja jest otwierana za pomocą „create”, wówczas tworzony jest obiekt transakcji, który implementuje interfejs „AutoCloseable”. W przypadku programowania nowych aplikacji i funkcji, należy zastosować opcję „create” zamiast „begin”. Wiele starszych aplikacji używa opcji „begin”.
beginNew() lub createNew()
beginNew() oraz createNew() służą do tworzenia nowych transakcji Top Level w aplikacji. Możliwe jest przekazanie aliasu bazy danych lub GUID bazy danych w formie parametru. Jeśli nie zostanie przekazana żadna baza danych, wówczas używana jest aktywna baza danych OLTP sesji użytkownika. Menedżer transakcji udostępnia dostępne aliasy baz danych jako stałe:
- CisTransactionManager.OLTP oznacza aktywną bazę danych OLTP sesji
- CisTransactionManager.OLAP oznacza aktywną bazę danych OLAP sesji
Jeśli transakcja została wygenerowana za pomocą funkcji createNew(), to nie wolno jej zamykać poprzez menedżera transakcji, ale zamiast tego należy użyć metod na transakcji.
begin() lub create()
Nowe transakcje są generowane za pomocą funkcji begin() i create(). Możliwe jest przekazanie aliasu bazy danych lub GUID bazy danych w formie parametru. Jeśli istnieje już kontekst transakcji dla otwartej transakcji, wówczas tworzona jest transakcja podrzędna. Jeśli podana baza danych nie odpowiada bazie danych otwartej transakcji, pojawia się wyjątek. Jeśli nie istnieje żadna otwarta transakcja, wówczas w podanej bazie danych lub w bazie OLTP sesji (jeśli nie przekazano aliasu bazy) generowana jest transakcja Top Level. Transakcja Top Level powinna być jednak zawsze tworzona jawnie za pomocą beginNew() lub createNew(), zamiast begin(), jeśli chcemy mieć pewność, że zmiany przez commit() zostaną również zapisane w bazie danych.
Jeśli istnieje już otwarty kontekst transakcji i zostanie użyta funkcja
begin() lub create(), to generowana jest transakcja podrzędna, która zostanie pomyślnie zakończona za pomocą funkcji commit(), ale wówczas transakcja parent może zostać przerwana, a zmiany transakcji podrzędnych zostaną utracone.
Jeśli transakcja została wygenerowana za pomocą funkcji create(), nie wolno zamykać tej transakcji za pomocą menedżera transakcji, ale należy użyć metod na transakcji.
Transakcje podrzędne nie zależą od tego, czy transakcja nadrzędna została otwarta za pomocą funkcji „create” czy „begin”. Oznacza to, że w ramach transakcji otwartej za pomocą begin() lub beginNew() można otwierać transakcje podrzędne za pomocą create(), jak również w ramach transakcji otwartej za pomocą create() lub createNew() można otwierać transakcje podrzędne za pomocą begin().
commit()
Funkcja commit() kończy aktualną transakcję. Jeśli jest to transakcja Top Level, zarejestrowane obiekty są zapisywane w bazie danych lub usuwane. W przypadku transakcji podrzędnych zarejestrowane obiekty nie są jeszcze zapisywane w bazie danych, ale są dziedziczone przez transakcję parent, tj. umieszczane w lokalnym kontekście transakcji, a zatem są widoczne dla transakcji równorzędnych. Tylko wtedy, gdy powiązana transakcja Top Level zostanie zakończona za pomocą commit(), obiekty te stają się trwałe w bazie danych. Utrzymywane blokady transakcji podrzędnej są dziedziczone przez transakcję parent, a blokady transakcji Top Level są usuwane.
Jeśli transakcja została wygenerowana za pomocą funkcji create() lub createNew(), należy zamknąć tę transakcję za pomocą commit() na transakcji. Nie używaj commit() na menedżerze transakcji. Po wykonaniu commit() należy koniecznie wywołać również metodę close() na transakcji.
rollback()
Funkcja rollback() powoduje przerwanie aktualnej transakcji. Oznacza to, że odrzucone zostaną wszystkie zmiany przekazane do usługi trwałości danych podczas tej transakcji lub jednej z jej transakcji podrzędnych (np. za pomocą putObject lub deleteObject). Przy czym nie ma znaczenia, czy przerwana transakcja jest transakcją Top Level, czy transakcją podrzędną. Jeśli anulowana jest transakcja podrzędna, to lokalny kontekst transakcji parent pozostaje niezmieniony, tzn. taki sam jak w momencie uruchomienia transakcję podrzędnej. Po anulowaniu transakcja parent
staje się ponownie aktualną transakcją. Jeśli anulowana jest transakcja Top Level, to transakcją aktualną staje się istniejąca transakcja dummy fikcyjna. Wszystkie blokady utrzymywane przez anulowaną transakcję zostają zniesione.
Poniższy rysunek przedstawia transakcję Top Level z transakcją podrzędną, która również posiada podrzędną transakcję.
![]()
Dopiero przy commit() transakcji Top Level zmiany będą trwałe w bazie danych. Obiekty state i pamięć podręczna transakcji służą do izolowania lokalnych kontekstów transakcji.
Wszystkie instancje obiektów biznesowych dostarczone przez menedżera obiektów należą do tej transakcji, w której zostały wczytane lub utworzone. Mogą być używane tylko w tej konkretnej transakcji. W przypadku zamknięcia transakcji, do której zostały wczytane, instancje obiektów biznesowych są nieprawidłowe.
Aby móc stosować obiekty biznesowe lub ich atrybuty we wszystkich transakcjach, konieczne jest wygenerowanie z nich niezwiązanego z transakcją, przejściowego obiektu biznesowego (getTransientCopy). Zawartość przejściowego obiektu biznesowego można wtedy skopiować do innych obiektów biznesowych związanych z transakcją (copyTo).
Jeśli transakcja została wygenerowana za pomocą create() lub createNew(), należy zamknąć transakcję za pomocą funkcji close() na transakcji. Nie wolno zamykać jej za pomocą rollback() na menedżerze transakcji.
Widoczność zmian w zagnieżdżonych transakcjach
Widoczność zmian w instancjach obiektów biznesowych, tj. właściwość izolacji transakcji, jest zarządzana na trzech poziomach.
Aktualna transakcja zawierająca transakcje podrzędne
Na poziomie aktualnej transakcji i jej transakcji podrzędnych zmiany atrybutów są widoczne tylko w tej właściwej instancji obiektu biznesowego. Dopiero po putObject() stają się one widoczne dla bieżącej transakcji i wszystkich kolejnych transakcji podrzędnych. Oznacza to, że ponowne getObject() zwraca zmienioną instancją obiektu biznesowego. Załadowane instancje zmienionego obiektu biznesowego nadal będą miały starą wartość, dopóki nie zostaną ponownie odczytane za pomocą funkcji getObject().
Transakcja Parent dla transakcji modyfikującej
Zmiany atrybutów są widoczne w transakcji nadrzędnej dla transakcji modyfikującej tylko wtedy, gdy instancja obiektu biznesowego została zapisana w transakcji modyfikującej, transakcja ta została pomyślnie zakończona za pomocą commit(), a instancja obiektu biznesowego zostanie ponownie odczytana za pomocą getObject(). Dotyczy to również głębszych poziomów zagnieżdżenia.
Zmiana zawartości bazy danych
Zawartość bazy danych odzwierciedla zmiany (Insert, Update, Delete) tylko wtedy, gdy transakcja Top Level została pomyślnie zakończona za pomocą commit(). Dopiero w tym momencie zapisywane są w bazie danych wszystkie zmiany transakcji Top Level i pomyślnie zakończonych transakcji podrzędnych.
Wtedy widoczne są one globalnie. Należy je ponownie odczytać, ponieważ instancje obiektów biznesowych odczytane przed transakcją modyfikującą nadal zawierają stare wartości. Update Statements zawsze pracują na rzeczywistych trwałych danych, tj. zmiany wprowadzone w instancjach obiektów biznesowych w tej samej transakcji nie są jeszcze widoczne dla zapytań OQL.
Zarządzanie pamięcią podręczną (Cache)
Usługa trwałości danych używa dwóch pamięci podręcznych spełniających różne zadania.
Shared Cache
Współdzielona pamięć podręczna służy do tymczasowego przechowywania wcześniej wczytanych instancji obiektów biznesowych w pamięci głównej w celu uniknięcia dostępów do bazy danych.
Dzięki temu znaczącą zwiększa się wydajność systemu ERP. Jeśli aplikacja chce odczytać obiekt biznesowy z bazy danych, najpierw sprawdza, czy obiekt biznesowy jest dostępny w shared cache. Jeśli nie, obiekt jest odczytywany z bazy danych. Shared cache jest dostępna w każdym serwerze aplikacji, który wykonuje dostępy do bazy danych
(singleton), dokładnie jeden raz (singleton) i zazwyczaj odzwierciedla najważniejszą lub ostatnio używaną zawartość bazy danych.
W środowisku rozproszonym z więcej niż jednym serwerem aplikacji oznaczałoby to niepotrzebny nakład, gdyby obiekty we wszystkich współdzielonych pamięciach podręcznych były cały czas w tym samym stanie co w bazie danych. Zazwyczaj wystarczy, jeśli obiekty w shared cache są aktualizowane w określonym odstępie czasu (30 sekund). Ewentualnie zmiany danych podstawowych lub danych konfigurowanych mogą być skuteczne na innych serwerach aplikacji dopiero 30 sekund później.
Transaction Cache
Pamięć podręczna transakcji służy do tworzenia lokalnego kontekstu transakcji. Każda transakcja Top Level ma swoją
własną pamięć podręczną transakcji. Powstaje ona w momencie wygenerowania nowej transakcji Top Level i jest potrzebna do operacji zapisu (dodanie, zmiana, usunięcie).
Aby zmienić instancję obiektu biznesowego, należy ją najpierw wczytać do zmiany za pomocą getObject. Manager obiektów blokuje instancję, aby w tym czasie nie mogła zostać dołączona do żadnej innej pamięci podręcznej transakcji.
Jeśli nastąpi próba załadowania tej samej instancji obiektu biznesowego w ramach innej transakcji, system odczeka ze zwolnieniem, aż do wystąpienia limitu czasu. Dopóki transakcja nie zostanie zakończona przez commit, obiekty
zarejestrowane do zapisu w ramach tej transakcji za pomocą putObject lub deleteObject, będą przechowywane tylko w pamięci podręcznej transakcji.
Manager obiektów wyszukuje żądane obiekty w odpowiedniej pamięci podręcznej transakcji za pomocą getObject. Dzięki temu obiekty zarejestrowane wcześniej do zapisu są zwracane w takim stanie, w jakim zostały zarejestrowane, a nie w jakim znajdują się w shared cache lub w bazie danych (izolacja). Pamięć podręczna transakcji zostaje rozwiązana przez commit()/rollback() dla transakcji Top Level:
- w wyniku commit() zmiany są pobierane do bazy danych. Domyślnie są one również przesyłane do shared cache. Blokady zostają zniesione.
- w wyniku rollback() odrzucone zostają wszystkie zamiany, tzn. nie są one pobierana ani do bazy danych, ani do shared cache.
Poniższa ilustracja przedstawia współdziałanie pamięci podręcznej transakcji, pamięci współdzielonej i bazy danych.
![]()
Jeśli obiektu nie można znaleźć w transaction cache, wówczas dostęp do odczytu na bazie danych zazwyczaj odbywa się za pośrednictwem shared cache. Jeśli instancja obiektu biznesowego nie zostanie znaleziona w shared cache, jest pobierana z bazy danych, zapisywana w shared cache i w transaction cache. Transakcje podrzędne mają swój własny obszar w transaction cache, w którym przechowywane są wczytane i zarejestrowane do zapisu instancje obiektów biznesowych. Jeśli transakcja podrzędna zostanie zakończona przez commit, instancje obiektów biznesowych zarejestrowane do zapisu są przenoszone do transaction cache transakcji parent. W przypadku commit transakcji Top Level zarejestrowane do zapisu instancje obiektów biznesowych są zapisywane w bazie danych i aktualizowane w shared cache. Następnie transaction cache zakończonej transakcji jest anulowana.
Shared cache można całkowicie pominąć, używając odpowiedniego trybu dostępu (IGNORE_SHARED_CACHE, BYPASS_CACHE). Wówczas instancja obiektu biznesowego (jeśli jest dostępna) jest wczytywana bezpośrednio z bazy danych bez względu na zawartość pamięci podręcznej, ani bez jej aktualizowania. Jest to przydatne w testach sprawdzających zawartość bazy danych i jest używane podczas synchronizacji shared cache z zawartością bazy danych. O strony aplikacji może to być przydatne do poprawy wydajności, jeśli obiekty biznesowe do odczytu lub zapisu na pewno nie powinny być buforowane („cached”), np. w tabelach tymczasowych.
Ponieważ pamięć główna dostępna dla serwera aplikacji jest ograniczona, nie wszystkie obiekty mogą być jednocześnie przechowywane w pamięci podręcznej. Dlatego dla każdej definicji obiektu biznesowego przydzielany jest priorytet pamięci podręcznej. W przypadku konfliktów priorytet decyduje, który obiekt pozostanie w pamięci podręcznej, a który zostanie z niej usunięty. Priorytety obejmują zakres od „nie przechowuj w pamięci podręcznej” (np. dla dzienników) do
„zawsze przechowuj w pamięci podręcznej” (np. metadane). Podczas tworzenia nowego obiektu biznesowego należy pamiętać o prawidłowym ustawieniu przechowywania w pamięci podręcznej.
Manager obiektów
Manager obiektów jest interfejsem dla aplikacji, w których można wykonywać następujące akcje:
- wczytywanie lub generowanie obiektów biznesowych (metoda getObject())
- generowanie iteracji obiektów biznesowych (metoda getObjectIterator ())
- wykonywanie dowolnych instrukcji OQL odczytu (SELECT) (metoda getResultSet()),
- rejestracja do zapisu obiektów biznesowych na bieżącej transakcji (metoda putObject()),
- rejestracja do usunięcia obiektów biznesowych na bieżącej transakcji (metoda deleteObject()),
- wykonywanie dowolnych instrukcji OQL odczytu (SELECT) (metoda getResultSet())
Wszystkie obiekty biznesowe używane w systemie ERP są wczytywane, generowane, zapisywane lub usuwane za pomocą managera obiektów. Dostęp do instancji obiektu biznesowego uzyskuje się za pomocą klucza technicznego składającego się z GUID bazy danych, GUID klasy obiektu biznesowego i klucza identyfikacyjnego instancji (np. klucz podstawowy/business key). Klasa Java wygenerowana dla obiektu biznesowego posiada metody do generowania klucza (build…Key()) i wykonywania zapytań (get…Key()). Klucze techniczne są definiowane jako Byte Array (byte[]). Wygenerowana klasa Java dla obiektu biznesowego pochodzi z klasy „CisObject”, co zapewnia jednolite zachowanie.
W aplikacji jest zawsze niejawnie otwarta transakcja dummy dla aktywnego mandanta (firmy główej), przy czym dopuszcza ona tylko dostęp do odczytu. Dostęp do zapisu (np. zapisywanie, usuwanie) jest dozwolony tylko w ramach jawnie otwartej transakcji. Trwałe instancje obiektów biznesowych zawsze należą do transakcji, w której zostały załadowane lub zmienione, z końcem transakcji stają się nieaktualne. Obiekty niezależne od transakcji
(transient) mogą być generowane za pomocą metody getTransientCopy(), którą posiadają wszystkie klasy obiektów biznesowych.
Metoda getObject()
Instancję obiektu biznesowego można wczytać za pomocą funkcji getObject(), przy czym uwzględniany jest lokalny kontekst transakcji. Jako parametry przewidywane są: klucz techniczny i opcjonalnie tryb dostępu. Dodatkowo można predefiniować język treści dla wczytywanego obiektu, tzn. wszystkie możliwe do zlokalizowania atrybuty obiektu
biznesowego są wypełniane tekstami w języku treści. Jeśli atrybut nie posiada tłumaczenia, wówczas stosowany jest język bazy danych dla tego atrybutu.
Metoda getObjectIterator()
Za pomocą metody getObjectIterator() można wczytać zbiór instancji obiektów biznesowych. Metoda
zwraca iterator dla zbioru wyników dla określonego zapytania OQL. Podobnie jak w przypadku
getObject() można określić język treści dla wczytywanych instancji. Jeśli dla obiektów biznesowych zależnych czasowo nie zastosowano w instrukcji OQL ani validFrom ani validUntil, wówczas zwracane są tylko aktualnie obowiązujące instancje. Jeśli validFrom lub validUntil jest używane w dowolnej części instrukcji OQL, wówczas zwracane są wszystkie dostępne wersje, do których odnosi się warunek instrukcji OQL. Ponieważ iterator obiektu to „AutoClosable”, to – jeśli został przypisany w try – będzie on automatycznie zamykany podczas opuszczania bloków try bez konieczności wyboru „finally“.
Zastosowanie iteratora obiektów bez przypisania w try:
CisObjectIterator iter<Book>= om.getObjectIterator(„select from
com.cisag.app.edu.obj.Book o where o:title
like ?“);
om.setString(1, „%Ringe%“);
try {
while (om.hasNext()) {
Book book= iter.next();
...
}
} finally {
iter.close();
}
Iterator obiektu jest zamykany po odczytaniu ostatniego elementu iteratora lub gdy zostanie wywołana funkcja close().
Zastosowanie iteratora obiektów z create() i try:
try (CisObjectIterator<Book> iter= om.getObjectIterator("select from
com.cisag.app.edu.obj.Book o where o:title
like ?")) {
om.setString(1, "%Ringe%");
while (om.hasNext()) {
Book book= iter.next();
...
}
}
Klasa „CisObjectIterator” jest klasą „AutoClosable”, dlatego może być używana z try. Iterator jest automatycznie zamykany za pomocą funkcji close() na końcu bloku try.
Metoda getResultSet()
Zapytania o atrybuty obiektów biznesowych można wykonywać za pomocą metody getResultSet(). Metoda zwraca zestaw result zawierający wynik zapytania OQL. OQL w dużej mierze odpowiada standardowemu SQL. Różnice przedstawiono poniżej:
- jako nazwa tabeli używana jest pełna nazwa obiektu biznesowego (z obszarem nazw), dla której musi byc przypisana nazwa aliasu tabeli
- jako nazwy kolumny używane są pełne ścieżki atrybutów, np. „holdQuantity[0].amount”
- każda nazwa kolumny musi być kwalifikowana za pomocą aliasu tabeli. Alias tabeli jest oddzielony od nazwy kolumny znakiem „:”
Instrukcja OQL przekazana jako parametr może zawierać symbole zastępcze dla wartości, które są oznaczone symbolem „?”, tak jak w SQL. Nie jest uwzględniana ani zależność czasowa, ani atrybuty lokalne. Zapytanie jest przypięte do bieżącej transakcji.
Wynikiem zapytania jest zestaw result. W tym zestawie muszą zostać ustawione
wolne parametry określone w ciągu OQL. Analiza zapytania odbywa się podczas pierwszego wyszukiwania
wyniku za pomocą funkcji next(). Zestaw result może być ponownie użyty z nowymi parametrami po zastosowaniu metody close().
Dopóki zestaw result nie zostanie zamknięty, połączenie z bazą danych jest używane wyłącznie w tym celu. Dlatego ważne jest, aby zawsze zamykać też zestaw result. Zestaw result powinien być zawsze używany w bloku try/catch. W bloku finally, jeśli nadal jest otwarty, zestaw powinien zostać zamknięty za pomocą funkcji close(). Ponieważ zestaw result to „AutoClosable”, to – jeśli został przypisany w try – będzie automatycznie zamykany podczas opuszczania bloków try bez konieczności wyboru „finally“. Komenda rollback() lub commit() lub close() na transakcji zamyka niejawnie wszystkie zestawy result, które zostały otwarte w transakcji.
Zastosowanie zestawu result bez przypisania w try:
...
CisResultSet rs= om.getResultSet(„select
o:guid, o:number from
com.cisag.app.edu.obj.Book o where o:title
like ?“);
try {
rs.setString(1, „%Ringe%“);
while (rs.next()) {
byte[] guid= rs.getGuid(1);
String number= rs.getString(2);
...
}
}
finally {
if (rs != null && !rs.isClosed()) {
rs.close();
}
}
...
Zastosowanie zestawu result z przypisaniem w try:
try (CisResultSet rs= om.getResultSet(
"select o:guid, o:number from
com.cisag.app.edu.obj.Book o where
o:title like ?")) {
rs.setString(1, "%Ringe%");
while (rs.next()) {
byte[] guid= rs.getGuid(1);
String number= rs.getString(2);
...
}
}
...
Metoda putObject()
Metoda putObject() służy do rejestracji instancji obiektu biznesowego w transakcji do zapisu. Wprowadzone zmiany
są widoczne w bieżącym kontekście lokalnym transakcji. Po wykonaniu commit transakcji rejestracja jest przenoszona do kontekstu transakcji parent i tam jest również widoczna dla kolejnych transakcji podrzędnych. Jeśli obiekt biznesowy zawiera informacje o aktualizacji (atrybut UpdateInformation), wówczas podczas tego wywołania są aktualizowane czas i użytkownik ostatniej modyfikacji.
Metoda deleteObject()
Metoda deleteObject() służy do rejestracji instancji obiektu biznesowego w transakcji do usunięcia i finalnego usunięcia z bieżącego kontekstu lokalnego transakcji. Widoczność usunięcia jest takie jak w metodzie putObject().
Współdziałanie managera obiektów i pamięci podręcznej
Jeśli instancja obiektu biznesowego jest wczytywana w aplikacji za pomocą getObject(), menedżer obiektów najpierw wyszukuje instancję w transaction cache bieżącej transakcji. Jeśli tam nie zostanie znaleziona, druga próba polega na załadowaniu instancji z shared cache. Jeśli tam również nie można znaleźć instancji, następuje dostęp odczytu do bazy danych. Przy zapisie za pomocą putObject() instancja obiektu biznesowego jest zapisywana w transaction cache bieżącej transakcji aplikacji. Gdy transakcja Top Level zostanie zakończona za pomocą commit(), instancja jest
zapisywana w shared cache i staje się trwała w bazie danych. Poniższy rysunek przedstawia związek między managerem obiektów a pamięcią podręczną.
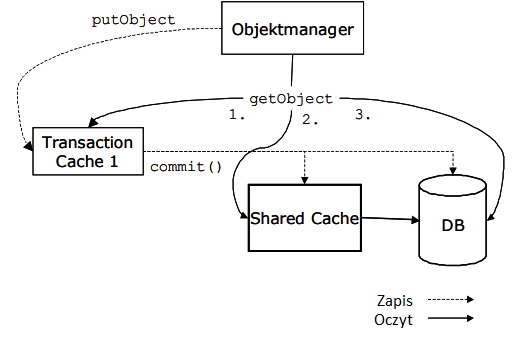
Update Statements
Za pomocą OQL UPDATE, INSERT lub DELETE możliwe jest wykonywanie instrukcji. Pozwala to na zmianę, wstawienie lub usunięcie wielu instancji obiektu biznesowego za pomocą jednego polecenia.
Instrukcja update jest wykonywana dopiero przy commit transakcji top level. Wcześniej instrukcja update nie wpływa na dane, które mają zostać wczytane w transakcji. Podczas commit transakcji top level instrukcje aktualizacji są zawsze wykonywane jako pierwsze. Nie mogą one odnosić się do tych samych obiektów biznesowych, które zostały zarejestrowane w ramach tej samej transakcji do zmiany/usunięcia za pomocą putObject()/deleteObject().
Instrukcja aktualizacji blokuje całą tabelę, na której wykonywana jest instrukcja; żadna inna transakcja nie może wczytać instancji obiektu biznesowego tego typu. Efektywność, np. podczas usuwania wielu rekordów danych, jest znacznie wyższa przez OQL delete niż za pośrednictwem usługi trwałości danych.
Niestety korzystanie z instrukcji aktualizacji ma poważny wpływ na ogólną wydajność systemu. Po zastosowaniu instrukcji aktualizacji wszystkie instancje danego obiektu biznesowe tej bazie danych są usuwane ze wszystkich współdzielonych pamięci podręcznych w całym systemie. Jeżeli inne zastosowania zależą od tego, czy instancje obiektu biznesowego są przechowywane w pamięci podręcznej, wydajność będzie znacznie zmniejszona. Instrukcje aktualizacji są zatem odpowiednie przede wszystkim dla następujących przypadków zastosowania:
- modyfikacja/usuwanie obiektów biznesowych nieprzechowywanych w pamięci podręcznej
- usuwanie tymczasowych danych
Przykład dla beginNew
tm.beginNew();
try {
CisUpdateStatement s = om.getUpdateStatement("DELETE FROM com.cisag.app.edu.obj.Book
o");
om.putUpdateStatement(s);
tm.commit();
}
catch (Exception e) {
tm.rollback();
}
Przykład dla createNew
Try (CisTransaction txn=tm.createNew()) {
CisUpdateStatement s = om.getUpdateStatement("DELETE FROM com.cisag.app.edu.obj.Book
o");
om.putUpdateStatement(s);
txn.commit();
}
Tryb dostępu
Dostęp do instancji obiektów biznesowych jest kontrolowany poprzez tryb dostępu. Ponadto podczas wywoływania odpowiedniej metody można zastosować flagę wskazującą na tryb dostępu. Aby tworzyć, zmieniać i usuwać obiekty biznesowe, należy użyć właściwego trybu dostępu. Jeśli nie ustawiono trybu dostępu, domyślnie używany jest tryb READ.
Tryb dostępu READ udostępnia instancje obiektów biznesowych tylko do odczytu, bez możliwości modyfikacji.
- Tryb dostępu READ_UPDATE udostępnia instancje obiektów biznesowych, które można dowolnie zmieniać lub usuwać.
- Tryb dostępu READ_WRITE zachowuje się tak samo jak READ_UPDATE. Jeśli jednak instancja, do której ma zostać uzyskany dostęp, nie istnieje, zwracana jest nowa instancja. Jeśli nowa instancja zawiera atrybut UpdateInformation, wówczas do UpdateInformation wprowadzany jest czas utworzenia i użytkownik.
- Tryb dostępu CACHE_ONLY umożliwia wyszukiwanie instancji obiektów biznesowych tylko w pamięci podręcznej. Jeśli nie są dostępne w tym miejscu, wyszukiwanie zwraca jest zero, nawet jeśli instancje są one dostępne w bazie danych.
- Tryb dostępu BYPASS_CACHE powoduje, że instancje obiektów biznesowych są odczytywane bezpośrednio z bazy danych. Zarówno współdzielona pamięć podręczna, jak i pamięć podręczna transakcji są ignorowane.
- Tryb dostępu IGNORE_SHARED_CACHE ma taki sam efekt jak jak BYPASS_CACHE, z tą różnicą, że instancje obiektów biznesowych po odczycie nie są zapisywane we współdzielonej pamięci podręcznej . Zapobiega to zastępowaniu ważniejszych obiektów w pamięci podręcznej przez odczytywane obiekty.
- Tryb dostępu READ_PARALLEL jest przydatny w sytuacji, kiedy użytkownik chce użyć do odczytu transakcji dummy z poziomu innej transakcji. Umożliwia to przypisanie obowiązywania iteratorów obiektów i zastawów result do transakcji dummy, a nie do bieżącej transakcji. W bazie danych transakcja dummy musi być otwarta. Dlatego
ta opcja działa tylko na mandancie (firmie głównej), przypisanym do użytkownika. - Tryb dostępu READ_REPEATABLE ustawia blokadę odczytu na obiekcie biznesowym i w ten sposób zapobiega jego zmianom przez inne transakcje. Ten tryb dostępu gwarantuje zatem spójność danych, nawet jeśli kilka serwerów aplikacji pracuje na OLTP DB. Nie jest to możliwe w przypadku normalnej flagi READ, ponieważ synchronizacja pamięci podręcznej między serwerami odbywa się tylko co 30 sekund, a zatem obiekt biznesowy z nieaktualnymi wartościami atrybutów może znajdować się w pamięci podręcznej.
- Tryb dostępu INSERT dezaktywuje sprawdzanie istnienia obiektu i generuje nowy nietrwały obiekt niezależnie od zawartości bazy danych. Jeśli tworzone są nowe obiekty biznesowe, a z logiki programu wynika, że obiekty te nie istnieją jeszcze w bazie danych, nie jest konieczne sprawdzanie ich istnienia w bazie danych przez usługę trwałości danych. Jeśli natomiast, wbrew temu założeniu, obiekt biznesowy istnieje w bazie danych, wówczas wystąpi błąd, gdy transakcja top level zostanie zakończona za pomocą funkcji commit().
- Tryb dostępu NEW_VERSION powoduje, że tworzona jest zawsze nowa, pusta instancja obiektu biznesowego, bez uwzględnienia pamięci podręcznej czy bazy danej. Ta opcja jest użyteczna tylko w trybie Insert Only dla obiektów zależnych od czasu.
Język treści (Content Language)
Język treści umożliwia zarządzanie językiem, w którym wczytywana są atrybuty z możliwością lokalizacji (atrybuty NLS). Jeśli nie zostanie określony język dla wykonywanego zapytania, wówczas stosowany jest język treści ustawiony w sesji zalogowanego użytkownika. Domyślnym językiem dla sesji jest język treści użytkownika z konfiguracji.
Informacje o modyfikacjach / „specjalistyczne” usuwanie
Jeśli w metadanych obiektu biznesowego ustawiona jest flaga maintainUpdateInfo, to do obiektu biznesowego dodawany jest atrybut UpdateInformation wskazujący użytkownika, który utworzył, ostatnio zmienił lub „specjalistycznie” usunął obiekt oraz czas tych operacji. Znacznik „specjalistycznego” usunięcia nie jest analizowany przez usługę trwałości danych, to zadanie należy do aplikacji. Jeśli flaga maintainUpdateInformation jest ustawiona na odpowiedniej definicji obiektu biznesowego, jądro systemu operacyjnego zapisuje datę utworzenia, zmiany lub usunięcia obiektu. Modyfikacje na obiektach zależnych (dependents) są wprowadzane dla przyporządkowanego podmiotu biznesowego. Czas usunięcia jest w tym przypadku tylko flagą, tzn. obiekt biznesowy z datą usunięcia nie jest fizycznie usuwany, a jedynie oznaczony jako usunięty, tak aby zostało to uwzględnione w aplikacji.
Zależność czasowa
Wszystkie operacje odczytu managera obiektów pracują na bieżącym rekordzie danych obiektu biznesowego. W przypadku obiektów biznesowych zależnych od czasu, ta instancja jest bieżąca, w której przedziale obowiązywania (validFrom, validUntil) znajduje się aktualna data i godzina. Przy czym czas validFrom należy do okresu obowiązywania,
a czas określony przez validUntil już nie. Usługa trwałości danych zakłada, że przedziały obowiązywania wszystkich zapisanych instancji obiektów biznesowych z tym samym kluczem podstawowym są ciągłe i nie nakładają się.
Do utrzymania danych zależnych od czasu usługa trwałości wykorzystuje tryb Insert Only i tryb Update. Instancje obiektów biznesowych zależnych od czasu mogą być zapisywane lub usuwane w taki sam sposób, jak wszystkie inne obiekty: za pomocą metod putObject() i deleteObject(). Przypisanie do danej instancji atrybutów validFrom i validUntil reguluje, w którym z tych trybów obsługiwana jest zależność czasowa.
Tryb Insert Only
Ten tryb służy do tworzenia nowej wersji. W tym celu należy za pomocą usługi trwałości danych wygenerować nową instancję z flagą NEW_VERSION. Przed zapisaniem instancji za pomocą putObject, atrybuty validFrom i validUntil należy ustawić na zero, ponieważ atrybuty te są obliczane przez usługę trwałości danych. Wygenerowana w ten sposób instancja posiada czas obowiązywania od bieżącej daty (validFrom) do daty maksymalnej. Data validUntil poprzedniej wersji jest ustawiana jako data validFrom nowej wersji, jeśli następuje po tej dacie, tak aby zachować ciągłość. Jeśli jednak przypada przed datą validFrom nowej wersji, to nie jest ona zmieniana i powstaje luka. Działanie tej funkcji ilustruje poniższy rysunek:

Tryb Update
Tryb Update służy do wstawiania nowej wersji pomiędzy istniejące wersje danej instancji obiektu biznesowego. Początek okresu obowiązywania (validFrom) wersji, która ma zostać wstawiona, jest podany, a atrybut validUntil musi być ustawiony na zero. W tym przypadku jądro systemu operacyjnego automatycznie ogranicza maksymalny okres obowiązywania (validUntil) aktualnie obowiązującej wersji i ustawia odpowiednią wartość atrybutu validUntil wstawianej wersji. Jeśli w danym momencie żadna wersja nie jest obowiązująca, powstaje luka.
Podczas korzystania z trybu Update instancja powinna być załadowana z flagą READ_WRITE i kluczem Time Depend, tak, aby uwzględnić ewentualnie istniejącą wersję instancji obiektu biznesowego.
Działanie tej funkcji ilustruje poniższy rysunek:
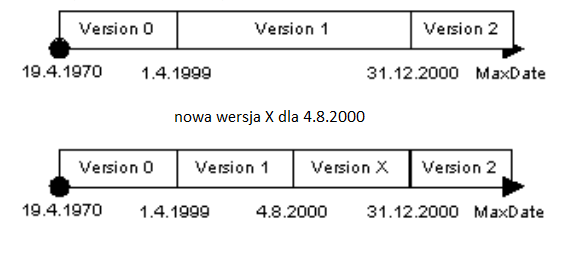
Jeśli dla obiektu biznesowego ustawione są validFrom i validUntil, tzn. wartość jest różna od zera, usługa trwałości danych nie wykonuje żadnych dalszych operacji w celu utrzymania spójności okresów obowiązywania. W takim przypadku wykonywana jest dokładnie ta operacja, którą określa aplikacja, bez względu na ewentualne niespójne stany (nakładające się przedziały czasowe, luki) będące wynikiem tej operacji.
Zarządzanie blokadami
Zarządzanie blokadami służy do synchronizacji transakcji zapisu na instancjach obiektów biznesowych. Instancja
jest zablokowana dla bieżącej transakcji, jeśli wykonano odczyt za pomocą funkcji getObject() (flagi READ_WRITE, READ_UPDATE). Zmiana lub usunięcie jest możliwe tylko w bieżącej transakcji; inna transakcja może tylko odczytać obiekt biznesowy z jego starą wartością. Jeśli inna transakcja próbuje załadować do zapisu obiekt biznesowy zablokowany w ten sposób, wówczas następuje przekroczenie limitu czasu po upływie 60 sekund. W rezultacie pojawia jest wyjątek, który powinien zostać odpowiednio obsłużony przez programistę. Standardową procedurą jest wysłanie wyjątku do kolejki komunikatów aplikacji (mm.sendMessage()), gdzie w centralnej lokalizacji określone typy wyjątków są generycznie konwertowane na odpowiednie komunikaty. W tym przypadku zostałby wygenerowany następujący komunikat: „Obiekt jest zablokowany przez …”. Blokady transakcji podrzędnych są dziedziczone przez transakcję nadrzędną (parent) niezależnie od commit() lub rollback(). Blokady są anulowane dopiero przy commit() lub rollback() transakcji Top Level.
Blokowanie odbywa się za pomocą klucza podstawowego. W przeciwieństwie do klucza biznesowego (business key) nie można bezpośrednio zmienić istniejącego klucza podstawowego (można usunąć i utworzyć nowy).
Aplikacje powinny przetwarzać swoje operacje bazodanowe w blokach ograniczając dostępy do bazy danych (tak rzadko, jak to możliwe i tylko tak długo, jak to konieczne). Oznacza to, że:
- podczas dłuższego przetwarzania (np. w aplikacji GUI) żadna transakcja nie jest otwarta, a zatem żadna instancja obiektu biznesowego nie jest zablokowana dla innych aplikacji
- dane są utrzymywane w odpowiedniej strukturze danych np. za pomocą instancji przejściowej (niezależnej od transakcji) jako kopii załadowanej instancji obiektu biznesowego
- transakcje powinny być jak najkrócej otwarta. Dlatego w transakcji powinien być realizowany tylko absolutnie niezbędny kod programu (otwarcie transakcji, odczyt obiektu z flagami zapisu, zastosowanie zmian, potwierdzenie transakcji).
Praca na obiektach biznesowych
Aktualizacje baz danych
Tworzenie lub zmiana schematu definicji obiektu biznesowego prowadzi do utworzenia nowej tabeli w bazie danych. Jeśli schemat został zmieniony, nowa tabela ma inną strukturę niż dotychczasowa. Nowe atrybuty mogły zostać dodane lub usunięte albo został zmieniony typ danych atrybutu. Aby nie utracić żadnych danych, konieczne jest przeniesienie danych danych z poprzedniej tabeli bazy danych obiektu biznesowego do nowej tabeli.
Ze względu na wspomniane zmiany strukturalne koniecznym może okazać się przekonwertowanie danych podczas ich przenoszenia ze starej do nowej tabeli. Dla nowo dodanych atrybutów należy ustawić wartości domyślne, w celu zdefiniowania stanu początkowego. Przy zmianie danych atrybutu wymagane są funkcje pozwalające na konwertowanie wartości atrybutu ze starego na nowy typ danych. W tym celu programista musi zapisać program aktualizacji dla danego obiektu biznesowego, który jest stosowany przez system do przesyłania danych pomiędzy starą i nową tabelą bazy danych oraz do konwersji danych.
W przypadku większych zmian strukturalnych dotyczących wielu obiektów biznesowych lub w przypadku zmiany semantyki atrybutów wymagane jest określenie bardziej złożonych reguł konwersji, w celu korekty lub migracji danych.
Służy do tego specjalny typ aplikacji w systemie ERP, aktualizacje danych.
Generowanie obiektów biznesowych
Przebieg procesu generowania jest ściśle związany ze statusem przynależnego zadania deweloperskiego.
Aby utworzyć lub edytować obiekt biznesowy, musi on być uwzględniony w istniejącym zadaniu deweloperskim. Po zmianie schematu obiektu biznesowego, np. dodaniu nowego atrybutu, rozpoczyna się faza generowania, w której należy uruchomić odpowiednie narzędzia za pomocą wiersza poleceń SAS.
Obiekt biznesowy jest generowany przez wywołanie narzędzi z odpowiednimi parametrami w kilku etapach, które muszą być wykonane w określonej kolejności. Dla każdego wywołania należy podać numer zadania deweloperskiego za pomocą parametru „-j:nummer” lub ewentualnie nazwę obiektu biznesowego (parametr -o:).
Etap 1 – wygenerowanie obiektu biznesowego
Etap 1 jest podzielony na następujące części:
• Schema
• Source
• Generate
Są one połączone w poniższym wywołaniu narzędzia:
crtbo –j:nummer
Schema
W tej części etapu tworzony jest szablon do generowania tabel w bazie danych (Table Description) na podstawie wprowadzonych metadanych obiektu biznesowego.
Source
W tej części etapu generowane są klasy obiektu biznesowego i klasy mapujące w celu uzyskania dostępu do zmodyfikowanego schematu tabeli. Wygenerowane klasy Java są przechowywane w katalogu roboczym wskazanego zadania deweloperskiego. Dla każdego atrybutu NLS generowany jest obiekt biznesowy i klasy mapujące, ponieważ treści w języku dodatkowym jest przechowywana w oddzielnych tabelach bazy danych.
Katalog roboczy zadania deweloperskiego, zawierającego nowe źródła obiektu biznesowego, musi być zintegrowany ze środowiskiem programistycznym, np. „Eclipse” i skompilowany. Lokalnie uruchomiony SAS musi uwzględniać skompilowane Class Files dla kolejnych etapów (patrz etap 2 i 3).
Przebieg procesu generowania jest ściśle związany ze statusem przynależnego zadania deweloperskiego. Aby utworzyć lub edytować obiekt biznesowy, musi on być uwzględniony w istniejącym zadaniu deweloperskim. Po zmianie schematu obiektu biznesowego, np. dodaniu nowego atrybutu, rozpoczyna się faza generowania, w której należy uruchomić odpowiednie narzędzia za pomocą wiersza poleceń SAS.
Generate
W tej części etapu generowana jest tymczasowa tabela bazy danych dla nowego opisu tabeli (Table Description) w bazie danych. Powielane są tylko tabele, których obiekty biznesowe znajdują się w zadaniu (a nie cała baza danych dla każdego zadania). Przykładowo, jeśli obiekt biznesowy typu „Entity” znajduje się w zadaniu deweloperskim, ale bez powiązanych elementów zależnych, wówczas przy tworzenia nowej instancji jednostki należy zapisać ją w nowej tabeli tymczasowej, a powiązane instancje zależne w ich starych aktywnych tabelach. Wszyscy inni użytkownicy w systemie zapisują nowe instancje jednostek tylko do aktywnych tabel ze starymi aktywnymi mapperami. Oznacza to, że w bazie danych generowane są niespójne stany. Należy mieć tego świadomość podczas testowania większych jednostek. Tabele tymczasowe są zabezpieczone przed zapisem i przy próbie wpisu do tabeli pojawia się wyjątek. To zachowanie można zmienić za pomocą parametru początkowego „-writeConvertedTables” serwera aplikacji. Parametr ten może być zastosowany, jeśli np. zmieniony obiekt biznesowy nie posiada dependents, a programista chce edytować aplikację w tym samym zadaniu co obiekt biznesowy.
Etap 2 – Klasy Update
W tym etapie następuje programowanie klas aktualizacji, które zapewniają poprawny transfer danych z aktywnej tabeli systemu do nowej tabeli tymczasowej.
Obiekty biznesowe atrybutów NLS posiadają również własne klasy aktualizacji służące konwersji treści w języku dodatkowym między starą a nową tabelą NLS.
Więcej informacji na temat klas aktualizacji można znaleźć w rozdziale Rozwój klas Update.
Etap 3 – Konwersja obiektu biznesowego
Ten etap obejmuje przeniesienie danych ze starej tabeli aktywnej w systemie do nowej tabeli tymczasowej. W tym celu należy zastosować następujące wywołanie narzędzia:
cnvbo -j:number
System pobiera i konwertuje dane ze starej do nowej tabeli bazy danych przy użyciu nowych klas aktualizacji. Należy upewnić się, że nowe klasy aktualizacji znajdują się w ścieżce klas serwera aplikacji, na którym przeprowadzana jest konwersja.
W przypadku błędów konwersji danych, proces jest anulowany i powinien zostać powtórzony z poprawionymi klasami aktualizacji. Ten krok można powtarzać dowolną ilość razy, ponieważ tabela tymczasowa jest całkowicie czyszczona przed konwersją.
Etap 4 – Rozwój i testy
W tym etapie wykonywane są testy konwersji, dalszy rozwój programu i testy. Po zmianie schematu w obiekcie biznesowym powinno się również odpowiednio dostosować aplikacje, które wykorzystują ten obiekt biznesowy. Na koniec należy zaewidencjonować (check in) źródła w systemie za pomocą aplikacji „Zadania deweloperskie”.
Dostęp do tabeli tymczasowych
W celu uzyskania dostępu do tabeli bazy danych obiektu biznesowego lokalny SAS używa nowo wygenerowanych klas mappera, które uzyskują dostęp do tabeli tymczasowej. Dla aplikacji działających na tym SAS, nowa wersja jest wersją aktywną i dlatego działają właśnie na niej. Inne SAS-y, które nie zintegrowały nowych klas obiektów biznesowych,
działają na starej aktywnej wersji.
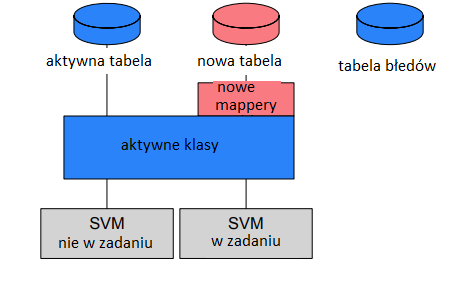
Widoki tymczasowe
Również widoki są najpierw tworzone tymczasowo, aby programista miał możliwość przetestowania zmienionego widoku przed jego aktywacją. Widok może również uzyskiwać dostęp do tymczasowych tabel obiektów biznesowych, które znajdują się w tym samym zadaniu deweloperskim co sam widok.
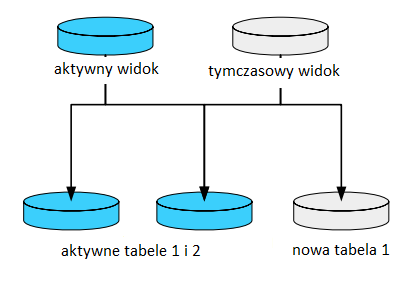
Usuwanie obiektu biznesowego z zadania
Obiektu biznesowego nie można usunąć z zadania deweloperskiego za pomocą aplikacji „Obiekty deweloperskie”. Aby
usunąć obiekt biznesowy, część lub widok, należy użyć narzędzia „rmvbo”:
rmvbo –o:Objektname
Narzędzie usuwa tabele tymczasowe z bazy danych i usuwa obiekt biznesowy z zadania deweloperskiego razem z utworzonymi dla niego źródłami.
Etap 5 – Zwolnienie zadania deweloperskiego
Po edycji obiektu biznesowego i innych obiektów deweloperskich należy zwolnić zadanie deweloperskie, w ramach którego naniesiono zmiany. Po zwolnieniu zadania nie ma już możliwości dalszej edycji obiektu biznesowego i innych obiektów deweloperskich.
Etap 6 – Aktywacja obiektu biznesowego
Ten etap kończy proces generowania. Aktywne tabele są zastępowane nowymi tabelami tymczasowymi, a zawartość jest przenoszona do nowej tabeli przy użyciu klas Update:
actbo –j:nummer
Etap 7 – Aktywacja zadania deweloperskiego
Ostatnim etapem procesu rozwoju jest aktywowanie zadania deweloperskiego.
Rozwój klas Update
Klasy aktualizacji zawierają logikę do konwersji danych starszej wersji obiektu biznesowego na wersję aktywną. Klasy aktualizacji zawierają informacje dla każdej zmienionej kolumny obiektu biznesowego informacje o tym, w jaki sposób ma być obsługiwana zmiana w kolumnie.
Klasy aktualizacji składają się z następujących klas Java:
- UpdateBase – jest generowana podczas tworzenia obiektu biznesowego. W klasie UpdateBase generowana jest metoda abstrakcyjna dla każdego utworzenia nowej kolumny, zmiany lub usunięcia kolumny. Klasa UpdateBase nie może być dostosowywana.
- UpdateLogic – jest tworzona jednorazowo z klasą UpdateBase, później nie jest już ponownie generowana. Klasa
UpdateLogic dziedziczy po UpdateBase i może zostać rozszerzona w przypadku zmian modelów danych. Należy zaimplementować wszystkie metody abstrakcyjne, ale nie nadpisywać metod nieabstrakcyjnych w celu zapisu innej implementacji. Klasa UpdateLogic powinna być zmieniana tylko w tym systemie, w którym został utworzony lub modyfikowany powiązany obiekt biznesowy lub rozszerzenie.
Dla każdego obiektu biznesowego i każdego rozszerzenia istnieją oddzielne klasy aktualizacji. Każda z klas odpowiada za atrybuty przypisanego obiektu. Klasy aktualizacji należą do obszaru nazw „com.<prefiks deweloperski>.upd”, np. „com.cisag.upd.app…”.
Zmiany modelu danych są opracowywane oddzielnie dla każdej kolumny. Każde utworzenie nowego elementu, zmiana lub usunięcie jest odpowiednio oznaczone w kolumnie, aby było wiadomo, jak i z którą wersją kolumna została zmieniona. Podczas normalnej edycji wszystkie zmiany kolumn są zapisywane w standardowym działaniu, które może zostać zmienione/nadpisane przez programistę. W miarę możliwości zmiany są przeprowadzane w tej samej kolejności, co podczas programowania.
Klasy aktualizacji obsługują następujące operacje:
- inicjalizacja nowej kolumny (metoda Init)
- stałe wartości początkowe
- wyliczone wartości początkowe
- usuwanie kolumny (znacznik usuwania na metodzie Init)
- zmiana typu danych dla istniejących kolumn (metoda ChangeDatatype)
- kompatybilna zmiana typu danych
- niekompatybilna zmiana typu danych
- podstawowe korekty danych
Funkcjonowanie klas aktualizacji
Pogrubiona czcionką zaznaczone są zmiany w obiekcie biznesowym i stosowane metody klas aktualizacji

Obiekt biznesowy „Item” jest zmieniany dwukrotnie. Najpierw atrybut „description” jest skracany ze 100 do 80 znaków, a następnie dodawany jest atrybut „unit”.
- metoda changeDatatype€description€str100_str80 oblicza niekompatybilną zmianę typu danych atrybutu „description”
- metoda init€unit€GUID oblicza wartość początkową dla nowego atrybutu „unit”.
Metody te są wywoływane podczas konwersji.
Programowanie partnera
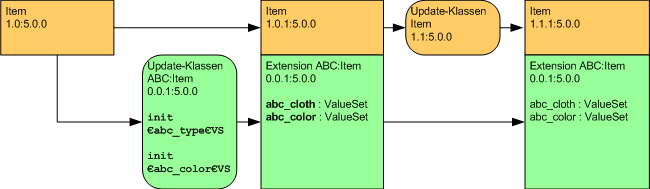
Najpierw tworzone jest rozszerzenie dla obiektu biznesowego „Item” z atrybutami abc_type i abc_color, a następnie
implementowana jest wersja 1.1 obiektu „Item”. Dzięki rozszerzeniu nie jest konieczna ręczna obsługa konfliktów na klasach aktualizacji obiektu biznesowego.
- metoda init€abc_type€VS oblicza wartość początkową dla kolumny abc_type
- metoda init€abc_color€VS oblicza wartość początkową dla kolumny abc_color
Podczas tworzenia rozszerzenia wywoływane są metody klas aktualizacji dla rozszerzenia. Podczas zmiany
odnośnego obiektu biznesowego „Item” nie muszą być zmieniane klasy aktualizacji, nie są też wywoływane żadne metody klasy aktualizacji dla rozszerzenia.
Metoda Init
Za pomocą metody Init obliczana jest wartość początkowa podczas tworzenia nowej kolumny. Wartość początkowa jest wymagana w sytuacji, gdy kolumna istnieje w nowej wersji obiektu biznesowego, ale nie istnieje w starej wersji. W zależności od metody aktualizacji, metoda Init jest używana w różny sposób.
Metoda Init jest generowana w klasie „UpdateBase” ze stałą wartością początkową. Metoda Init może zostać nadpisana w klasie „UpdateLogic” przez inną metodę aktualizacji w celu obliczenia innej wartości początkowej.
Nazwa metody Init składa się z następujących elementów:\
<Java-Datatype> init€<AttributePath>€
<Datatype>(CisGenericObject object)
Ścieżka atrybutu kolumny odpowiada nazwie kolumny w języku OQL. Nawiasy kwadratowe „[]” i kropka „.” są zastępowane przez znak dolara „$”, tak aby ścieżka atrybutu mogła być używana jako identyfikator metody.
Parametr object zawiera stan instancji przed inicjalizacją nowej kolumny. W przypadku metody aktualizacji CONSTANT i metody aktualizacji DATABASE wartość parametru object wynosi zero.
W przypadku atrybutu części (part), oprócz metod init dla powiązanych kolumn, generowana jest również metoda init dla kolumny boolean części. Jej ścieżką atrybutu jest ścieżka atrybutu części. Zwracana wartość metody wskazuje, czy wartość części jest prawidłowa czy nie. Aby inicjować atrybut części z wartością, metoda init dla kolumny boolean części musi zostać nadpisana w ten sposób, aby zwracała wartość true.
Obliczenie wartości początkowej kolumny „description” z typem danych „String” i długością 100.
Ta kolumna została utworzona w wersji 7.3 w wydaniu 5 (release).]
Klasa UpdateBase
@History(created={“7.3:5.0.0“)
@Update(method=CONSTANT)
String init€description€str100(CisGenericObject object) {
return “”;
}
Klasa UpdateLogic
@override
@Update(method=INSTANCE)
String init€description€str100(CisGenericObject object) {
return “Artikel “+object.getString(“number”);
}
Metoda ChangeDatatype
Typ danych kolumny można zmienić. Aby przekonwertować zawartość kolumny ze starego na nowy typ danych, wymagane jest obliczenie. Odbywa się ono metodą ChangeDatatype, która jest generowana w klasie UpdateBase:
<Java-TargetDatatype> changeDatatype€<AttributePath>€<SourceDatatype>_<TargetDatatype>(CisGenericObject object)
Na metodzie ChangeDatatype adnotacja history z właściwością created wskazuje, z którą wersją zmieniony został typ danych.
Zmiana modelu danych jest kompatybilna, jeśli prymitywny typ danych nie został zmieniony, a długość typu danych została zwiększona. Wszystkie inne zmiany są niekompatybilne.
Zmiana ciągu 100 na ciąg 90 jest niekompatybilna.
Zmiana Boolean na ValueSet jest niekompatybilna.
Jeśli zmiana typu danych była niekompatybilna, wówczas metody ChangeDatatype w klasie „UpdateBase” są generowane abstrakcyjnie i muszą zostać zaimplementowane przez programistę. Niekompatybilne zmiany modelu danych zawsze posiadają „UpdateMethod INSTANCE” i dlatego muszą być obliczane dla każdej instancji.
Jeśli zmiana typu danych była kompatybilna, wówczas metody ChangeDatatype w klasie „UpdateBase” są generowane jako ostateczne i nie mogą zostać nadpisane przez programistę. Kompatybilne zmiany modelu danych zawsze posiadają „UpdateMethod CONSTANT” i dlatego mogą być obliczane na bazie danych.
Klasa UpdateBase
@History(created={“7.1:5.0.0“})
@Update(method=UpdateMethod.CONSTANT)
final String changeDatatype€description€str80_str100(CisGenericObject object) {
return object.getString(“description”);
}
@History(created={“8.1:5.0.0“})
@Update(method=UpdateMethod.INSTANCE)
abstract String changeDatatype€description€str100_str90(CisGenericObject object);
Klasa UpdateLogic
@override
String changeDatatype€description€str100_str90(CisGenericObject object) {
String value = object.getString(“description”);
if (value.length()<=90) {
return value;
} else {
return value.substring(0,87)+”…”;
}
}
Usuwanie instancji
Jeśli instancja ma zostać usunięta, a nie przekonwertowana, wówczas jedna z wywołanych metod modyfikacji musi zawierać metodę delete(). Powoduje to anulowanie konwersji bieżącej instancji i jej odrzucenie.
Po wykonaniu metody delete() należy zamknąć metodę modyfikacji za pomocą return. Po delete() nie może już być żadnych innych komend.
Adnotacja Update
Adnotacja aktualizacji określa, czy konwersja kolumny musi być wywoływana dla każdej instancji lub czy wszystkie instancje danej bazy danych mogą być obsługiwane w ten sam sposób. Właściwość method adnotacji aktualizacji precyzuje kontekst wywołania, zwany w dalszej części dokumentu „metodą aktualizacji”.
Metoda aktualizacji CONSTANT
W przypadku metody aktualizacji CONSTANT nie jest przekazywana żadna konkretna instancja obiektu biznesowego. Metoda nie ma możliwości dostępu do żadnych obiektów w żadnej bazie danych. Wynik metody jest stosowany do dowolnej liczby instancji w dowolnej bazie danych.
Składnia:
@Update(method=UpdateMethod.CONSTANT)
Metoda aktualizacji DATABASE
W przypadku metody aktualizacji DATABASE żadna konkretna instancja obiektu biznesowego nie jest do niej przekazywana. Metoda może uzyskać generyczny dostęp do obiektów bazy danych. Wynik metody jest stosowany do wszystkich instancji w danej bazie danych.
Składnia:
@Update(method=UpdateMethod.DATABASE)
Metoda aktualizacji INSTANCE
W przypadku metody aktualizacji INSTANCE przekazywana jest określona instancja obiektu biznesowego.
Dla tej instancji musi zostać wyliczona konwersja. Metoda może uzyskać generyczny dostęp do obiektów bazy danych.
Wynik metody jest stosowany tylko dla tej przekazanej instancji.
Zastosowanie co najmniej jednej metody poprzez metodę aktualizacji INSTANCE zawsze skutkuje konwersją instancja po instancji. Należy pamiętać, że metoda jest wywoływana dla każdej instancji. W przypadku wykonywania złożonych obliczeń w tej metodzie, konwersja danych w kolejnych systemach może potrwać dość długo.
Składnia:
@Update(method=UpdateMethod.INSTANCE)
Generyczny dostęp do obiektów biznesowych
Klasa com.cisag.pgm.datatype.CisGenericObject umożliwia generyczny dostęp do dowolnej wersji obiektu biznesowego. Kolumny generycznego obiektu biznesowego mogą być wyszukiwane poprzez ścieżkę atrybutu. Dla każdego prymitywnego typu danych, jak również dla special parts istnieją odpowiednie metody get i set.
Zapytanie o kolumnę ciągu description:object.getString(”description“);
Dostęp usługi trwałości danych
Za pomocą zwykłych mapperów obiektów biznesowych nie jest możliwy dostęp do obiektów biznesowych w klasach aktualizacji. Każdy dostęp usługi trwałości, np. getObject, który w innym przypadku zwróciłby instancję BusinessObject, w klasach aktualizacji zwraca obiekt generyczny.
W dostępie generycznym do obiektów biznesowych można korzystać ze wszystkich metod dostępu managera obiektów, tj. getObject, getObjectIterator, getResultSet, itp. Manager obiektu zawsze uzyskuje dostęp do aktywnej wersji obiektu biznesowego w bazie danych. Można użyć generycznego dostępu do stanu bazy danych przed zmianą modelu danych. Nie można używać żadnych metod managera obiektów, które są służą do zapisu do bazy danych.
Za pomocą metody buildPrimaryKey można wygenerować klucz podstawowy lub uzależniony czasowo klucz podstawowy obiektu biznesowego.
Przykładowe zastosowanie CisGenericObjects przy pomocy CisObjectManager:CisGenericObject item = (CisGenericObject)om.getObject(CisGenericObject.buildPrimaryKey(”com.cisag.app.general.obj.Item“,ite
mGuid)
oldDescription=item.getString(”description“);
Inicjalizacja
W celu konwersji danych obiektu biznesowego w bazie danych generowana jest jedna lub więcej instancji klas aktualizacji. Klasy aktualizacji konwertują dane wersji źródłowej, tj. aktywnej wersji w bazie danych, na wersję docelową, tj. wersję zablokowaną dla programisty w zadaniu deweloperskim.
Zapytanie o schemat wersji źródłowej i docelowej można wykonać za pomocą następujących metod:
CisObjectSchema getFromSchema() CisObjectSchema getToSchema()
Metoda initialize() klasy aktualizacji jest wywoływana przed zastosowaniem na każdej instancji. Metoda initialize może
zostać nadpisana w klasie UpdateLogic w celu zainicjowania instancji klasy aktualizacji do zastosowania na bazie danych. W tej metodzie można uzyskać dostęp odczytu do obiektów biznesowych za pośrednictwem dostępu generycznego.
W metodzie initialize dla każdej inicjalizacji należy sprawdzić za pomocą metody getFromSchema(), czy jest ona wymagana. W celu weryfikacji należy użyć schematu wersji źródłowej.
Dla metody Init kolumny „myUnit” wartość domyślna jest obliczana w metodzie initialize. Wartość domyślna jest wymagana tylko wtedy, gdy kolumna „myUnit” nie istnieje w wersji źródłowej.
byte[] myUnitDefault;
void initialize() {
if (getFromSchema().getColumn("myUnit")==null) {
myUnitDefault=…
}
}
@override
@Update(method=DATABASE)
byte[] init$myUnit$guid(CisGenericObject
object) {
return myUnitDefault;
}
Aktualizacja danych
Programy aktualizacji, odnoszące się zawsze do obiektu biznesowego, mogą okazać się niewystarczające. Wówczas wymagana jest specjalna aplikacja typu Aktualizacja danych, która przeprowadza korektę lub migrację danych.
Taka sytuacja może nastąpić w następujących przypadkach:
- wprowadzono złożone zmiany schematów dla wielu obiektów biznesowych, w których dane są ze sobą logicznie powiązane. Aby możliwe było określenie prawidłowych wartości, konwersja danych jednego obiektu biznesowego wymaga zdefiniowanego stanu wszystkich powiązanych obiektów deweloperskich. W takich przypadkach zmiany schematu są najpierw aktywowane i, jeśli to konieczne, wcześniej pisane programy aktualizujące dla poszczególnych obiektów biznesowych. Potem następuje aktualizacja danych na zdefiniowanym stanie klasy.
- jeśli do konwersji danych mają zostać użyte zaimplementowane już funkcje logiczne, należy to zrobić w aktualizacji danych, ponieważ w programach aktualizacji nie można używać zewnętrznych klas logicznych.
- muszą zostać poprawione błędy czysto logiczne, a nie było żadnych zmian w schemacie. Programy aktualizujące są wykonywane tylko w przypadku zmian w schemacie.
- w celu konwersji użytkownik musi jeszcze ręcznie wprowadzić dane
Wady
Jeżeli to możliwe, należy zawsze używać programów aktualizujących do korekty danych, ponieważ są one wykonywane automatycznie, gdy aktywowana jest nowa wersja obiektu biznesowego. Dzięki temu zachowana jest prawidłowa kolejność przy większej ilości wersji. Może jednak okazać się konieczne ręczne wykonanie niektórych aktualizacji danych po zainstalowaniu aktualizacji oprogramowania. Nie wolno o tym zapomnieć, bo skutkiem byłaby praca aplikacji na niepoprawnych danych, a w najgorszym przypadku wygenerowanie bezużytecznych danych. Ponieważ aktualizacja danych wymaga zdefiniowanego statusu, istnieje ryzyko, że nie będzie ona już później możliwa, ponieważ zostaną zainstalowane kolejne aktualizacje oprogramowania, a obiekty biznesowe, których dotyczy aktualizacja, są dostępne w innych wersjach. Aktualizacje danych, które wymagają ręcznej interwencji, oznaczają więcej pracy dla partnera, ponieważ musi on przeprowadzić ten proces na każdym systemie, w którym zaimplementowano aktualizację danych.
Typy aktualizacji danych
Istnieją różne typy aktualizacji danych, które różnią się sposobem ich wykonywania, przez co posiadają określone zalety i wady. Istnieją następujące typy:
- aktualizacja danych w dialogu
- aktualizacja danych wykonywana automatycznie podczas instalacji aktualizacji oprogramowania
- aktualizacja danych wykonywana w tle
Dostęp odczytu przez managera obiektów
Manager obiektów (klasa com.cisag.pgm.appserver.CisObjectManager) zapewnia deweloperowi metody dostępu do odczytu: getObject(), getObjectArray(), getObjectIterator() oraz getResultSet(). Zapytania mogą być wykonywane na aktualnym środowisku:
CisEnvironment env= CisEnvironment.getInstance();
CisObjectManager om= env.getObjectManager();
mapper, String oqlString)
Metoda getObject()
Metoda getObject() odczytuje dokładnie jedną instancję obiektu biznesowego dla danego klucza usługi trwałości. Odczytywana jest zawsze cała instancja ze wszystkimi atrybutami. Klucz usługi trwałości wymagany do identyfikacji wczytywanej instancji jest generowany przy użyciu odpowiedniej statycznej metody klasy obiektu biznesowego:
- Metoda służąca do generowania klucza usługi trwałości z klucza podstawowego obiektu biznesowego: buildPrimaryKey()
- Metoda build…Key() służy do generowania klucza usługi trwałości z klucza funkcjonalnego lub innego klucza pomocniczego dla obiektu biznesowego, gdzie „…” odpowiada nazwie przekazanego klucza.
Sygnatura metody to:
public <T extends CisObject> <T> getObject(byte[] key, int flags)
Parametr key jest generowanym kluczem usługi trwałości. Parametr flag określa zachowanie dostępu.
Sposób działania getObject()
Najpierw programista generuje klucz usługi trwałości za pomocą odpowiedniej metody statycznej build…Key() klasy obiektu biznesowego. Następnie wywoływana jest metoda getObject() na managerze obiektów z kluczem usługi trwałości i flagami dostępu jako parametrami. Manager obiektów próbuje odczytać instancję obiektu biznesowego z pamięci podręcznej transakcji. Jeśli nie zostanie tam znaleziona, następuje wyszukiwanie we współdzielonej pamięci podręcznej. Jeśli i tam wyszukiwanie będzie bezskuteczne, wówczas następuje dostęp do bazy danych. Wykonywane jest następujące zapytanie SQL, które jako wynik zwraca jeden wiersz lub brak wiersza:
SELECT * FROM table WHERE keyAttributes='?'
Manager obiektów generuje instancję klasy obiektu biznesowego, mapuje wynik zapytania na atrybuty i zwraca instancję do aplikacji jako obiekt CisObject. Tutaj musi nastąpić TypeCast z ogólnej klasy CisObject na konkretną klasę odczytywanego obiektu biznesowego. Jeśli nie uzyskano żadnego wyniku z bazy danych, wówczas zwracana jest wartość null.
Poniższy fragment kodu źródłowego ładuje instancję obiektu biznesowego Item za pomocą klucza podstawowego:
byte[] guid = ...; byte[] primKey = Item.buildPrimaryKey( guid ); Item item = om.getObject(primKey, CisObjectManager.READ);
Następny fragment kodu źródłowego ładuje instancję obiektu biznesowego Item za pomocą klucza funkcjonalnego number:
String number = ...; byte[] busKey = Item.buildByNumberKey( number ); CisObject obj = om.getObject(busKey, CisObjectManager.READ); Item item = (Item) obj;
Jeśli obiekt biznesowy jest zależny od czasu i powinna zostać załadowana inna wersja niż wersja aktywna, wówczas stosowana jest metoda buildTimeDependentKey(). Jako parametry przekazywane są atrybuty klucza podstawowego i atrybut validFrom:
byte[] guid = ...; Date validFrom = ...; byte[] primKey = Item.buildTimeDependentKey(guid, validFrom); Item item = om.getObject(primKey, CisObjectManager.READ);
Metoda getObjectArray()
Metoda getObjectArray() odczytuje wiele instancji jednego obiektu biznesowego dla podanych kluczy. Zawsze odczytywana jest cała instancja ze wszystkimi atrybutami. Wymagany klucz usługi trwałości jest generowany przy użyciu odpowiedniej metody statycznej klasy obiektu biznesowego, na przykład buildPrimaryKey(), jeśli używany jest klucz podstawowy. Można zastosować wszystkie unikalne klucze obiektu biznesowego.
Sygnatury metody:
CisObject[] getObjectArray(byte[][] persKeys, int flags) CisObject[] getObjectArray(java.util.List persKeys, int flags)
Parametr persKeys jest tablicą lub listą kluczy usługi trwałości wygenerowanych z wartości kluczy instancji dla wczytywanych obiektów biznesowych. Parametr flags określa zachowanie dostępu.
Sposób działania getObjectArray()
Najpierw należy wygenerować klucze usługi trwałości z kluczy podstawowych wczytywanych instancji obiektów biznesowych z zastosowaniem statycznej metody buildPrimaryKey() klasy obiektów biznesowych. Następnie na managerze obiektów wywoływana jest metoda getObjectArray(), która jako parametry otrzymuje tablicę byte z kluczami usługi trwałości i flagami dostępu. Manager obiektów próbuje odczytać instancje obiektu biznesowego z pamięci podręcznej transakcji. Instancje, które nie zostały znalezione, są wyszukiwane we współdzielonej pamięci podręcznej. Pozostałe instancje, których również tam nie znaleziono, wyszukiwane są w bazie danych za pomocą zapytania SQL: SELECT * FROM table WHERE primaryKeyAttributes IN
(’?’,…,’?’)
Manager obiektów generuje instancje klasy obiektu biznesowego, mapuje wynik zapytania na atrybuty i zwraca instancje do aplikacji jako tablicę CisObject. W tym miejscu musi nastąpić Type Cast z ogólnej klasy CisObject na konkretną klasę odczytanych obiektów biznesowych. Jeśli nie znaleziono żadnej instancji dla klucza, wówczas odpowiednia pozycja w tablicy CisObject otrzymuje wartość zero. Jeśli nie znaleziono żadnego wyniku, zwracana jest pusta tablica CisObject.
Poniższy fragment kodu źródłowego wczytuje obiektu biznesowego Item za pomocą kluczy podstawowych:
byte[] primKey1 = Item.buildPrimaryKey( guid1
);
...
byte[] primKeyN = Item.buildPrimaryKey( guidN
);
byte[][] primaryKeys = new byte[][]{primKey1,
...., primKeyN};
CisObject[] objects = om.getObjectArray(primaryKeys, CisTransactionManager.READ);
for (int i=0; i< objects.length;i++) {
// Position in objects entspricht Position
in primaryKeys
Item item = (Item) objects[i];
...
}
Metody getObjectList()
Podobnie jak w przypadku metody getObjectArray(), również metoda getObjectList() odczytuje wiele instancji obiektu biznesowego dla podanych kluczy. Funkcja getObjectList() i getObjectArray() jest identyczna, ale getObjectList() zwraca listę obiektów biznesowych, podczas gdy getObjectArray() zwraca tablicę z obiektami biznesowymi. Rozmiar listy odpowiada liczbie przekazanych kluczy.
Sygnatura metody:
<T extends CisObject> List<T> getObjectList(CisList persKeys, int flags)
Typ danych List jest jako zwracana wartość umożliwia prosty Type Cast na listę z faktycznie wczytanymi obiektami biznesowymi.
Poniższy fragment kodu źródłowego wczytuje instancje obiektu biznesowego Item za pomocą kluczy podstawowych:
CisList primaryKeys = new CisArrayList();
primaryKeys.add(Item.buildPrimaryKey( guid1
));
...
primaryKeys.add(Item.buildPrimaryKey( guidN
));
List<Item> items = om.getObjectArray(primaryKeys,
CisTransactionManager.READ);
for (Item item : items) {
//Position in items entspricht Position in
primaryKeys
...
}
Metoda getObjectIterator()
Metoda getObjectIterator() odczytuje wiele instancji obiektu biznesowego. Odczytywana jest zawsze cała instancja
ze wszystkimi atrybutami. Metoda otrzymuje instrukcję SELECT w języku OQL, która opisuje instancje do załadowania.
Sygnatura metody:
<T extends CisObject> CisObjectIterator<T> getObjectIterator(String oqlString, int flags)
Parametr oqlString zawiera ciąg OQL, parametr flags określa zachowanie dostępu.
Sposób działania getObjectIterator()
Najpierw należy wygenerować iterator (CisObjectIterator) poprzez wywołanie metody getObjectIterator() na managerze obiektów i przekazanie ciągu OQL oraz flag dostępu. Ciąg OQL zezwala na Sub Selects w klauzuli WHERE. Joins nie są obsługiwane. Metoda zwraca iterator, który jest używany w aplikacji do ładowania instancji obiektów biznesowych. Następnie ustawiane są parametry OQL podane w ciągu OQL jako symbol zastępczy „?”. Pierwsze wywołanie hasNext() lub next() na iteratorze wyzwala dostęp do bazy danych. Metoda hasNext() sprawdza, czy można jeszcze przesyłać instancje. Metoda next() dostarcza następną instancję do aplikacji. Jeśli obiekt biznesowy jest przechowywany w pamięci podręcznej, wówczas jako pierwsze ładowane są wartości klucza podstawowego:
SELECT primkeyAttr FROM table [WHERE ...]
Instancje obiektów biznesowych są generowane przy użyciu wewnętrznie wywoływanej metody getObjectArray(), która ładuje instancje blok po bloku za pomocą klucza podstawowego. Domyślny rozmiar bloku to 16. Jeśli instancja obiektu biznesowego jest oznaczona jako usunięta w aktualnej Transaction Cache, to zostanie odfiltrowana i nie zwrócona jako wynik. Iterator obiektów nigdy nie zwraca zera. W aplikacji musi nastąpić Type Cast z ogólnej klasy CisObject na konkretną klasę odczytywanych obiektów biznesowych.
Jeśli obiekt biznesowy nie jest przechowywany w pamięci podręcznej, wszystkie atrybuty są odczytywane bezpośrednio z bazy danych i generowane są instancje obiektu biznesowego.
Poniższy fragment kodu źródłowego wczytuje instancje obiektu biznesowego Item, do których przypisana jest określona jednostka miary (Business Object UnitOfMeasure). Ich klucz podstawowy typu „guid” jest ustawiany jako parametry w iteratorze za pomocą metody setGuid().
Parametry OQL:
try (CisObjectIterator<Item> iter = om.getObjectIterator( "SELECT FROM
com.cisag.app.general.obj.Item i WHERE
i:uom=?")) {
iter.setGuid(1, uomGuid);
while (iter.hasNext()) {
Item item = iter.next();
...
}
}
Poniższy fragment kodu źródłowego wczytuje instancje obiektu biznesowego SupplierProposalDetail …
Sub Select:
String oql = "SELECT FROM
com.cisag.app.purchasing.obj.SupplierProposalDetail spd WHERE spd:deliverySupplier <>
(SELECT delInfo:supplierData.supplier FROM
com.cisag.app.purchasing.obj.PurchaseOrderDeliveryInfo delInfo WHERE delInfo:header=spd:header AND delInfo:detail=spd:guid)";
try (CisObjectIterator <SupplierProposalDetail> iter = om.getObjectIterator(oql)){
while (iter.hasNext()) {
SupplierProposalDetail spd = iter.next();
...
}
}
Metoda getResultSet()
Metoda getResultSet() odczytuje wybrane atrybuty z jednego lub wielu obiektów biznesowych. Atrybuty wyników można dowolnie łączyć za pomocą instrukcji SELECT w OQL. Z bazy danych nie są odczytywane kompletne instancje obiektów biznesowych. Zestaw wyników (Result Set) wykorzystuje całkowicie połączenie z bazą danych do momentu jego jawnego zamknięcia. Dlatego niezwykle ważne jest, aby zminimalizować czas otwarcia zestawu wyników, ponieważ liczba dostępnych połączeń z bazą danych jest ograniczona. Złożone lub długie operacje powinno się wykonywać dopiero po zamknięciu zbioru wyników. Ważne jest również, aby każdy z zagnieżdżonych zestawów wyników używał własnego połączenia z bazą danych, czyli liczba dostępnych połączeń z bazą danych ogranicza głębokość zagnieżdżenia. Dlatego zaleca się utrzymywać jak najmniejszą głębokość zagnieżdżenia.
Sposób działania getResultSet()
Najpierw należy wygenerować zestaw wyników (CisResultSet) poprzez wywołanie metody getResultSet() w managerze obiektów i przekazanie ciągu OQL, w którym dozwolone są Joins i Sub Selects. Metoda zwraca zestaw wyników, który
jest używany w aplikacji do ładowania atrybutów. Następnie ustawiane są parametry OQL, które w ciągu OQL zostały wprowadzone jako symbol zastępczy „?”. Pierwsze wywołanie metody next() na zestawie wyników uruchamia dostęp do bazy danych. Metoda next() zwraca następny zestaw atrybutów do aplikacji. Wykonywane jest następujące zapytanie SQL:
SELECT attr1[, attr2, ...] FROM table1 [JOIN table2 ON ... [JOIN ...]] [WHERE ...]
Aplikacja musi odebrać atrybuty odczytanego rekordu z zestawu wyników przy użyciu właściwej metody (w zależności od typu). Należy upewnić się, że zestaw wyników jest zamykany jawnie za pomocą close(), aby móc zwolnić połączenie bazy danych, jeśli transakcja dummy jest używana do odczytu. W przypadku wywołania commit() lub rollback() dla bieżącej transakcji, wszystkie otwarte zestawy wyników są zamykane niejawnie. Ponieważ zestaw wyników jest „AutoClosable”, to zestaw przypisany w try jest zamykany automatycznie, nawet bez „finally, po opuszczeniu bloku try.
Poniższy fragment kodu źródłowego ładuje tylko atrybuty „guid” (klucz podstawowy) i „number” (klucz funkcjonalny) instancji obiektu biznesowego, do których przypisana jest określona jednostka miary (obiekt biznesowy UnitOfMeasure).
Ich klucz podstawowy typu „guid” jest ustawiany jako parametr w zestawie wyników za pomocą metody setGuid()
(pasującą do typu), do której jako parametry przeniesiona jest pozycja w instrukcji OQL i wartość. Blok try catch finally gwarantuje, że zestaw wyników zostanie zamknięty, nawet jeśli wystąpi wyjątek.
byte[] uomGuid = ... ;
CisResultSet rs = om.getResultSet("SELECT
i:guid, i:number
FROM com.cisag.app.general.obj.Item i
WHERE i:uom=?");
try {
rs.setGuid(1, uomGuid);
while (rs.next()) {
//read next
byte[] guid = rs.getGuid(1);
String number = rs.getString(2);
...
}
}
finally {
rs.close();
}
Wytyczne dotyczące użytkowania
Poniższe zestawienie zawiera wskazówki dotyczące stosowania opisanych metod w celu osiągnięcia właściwej wydajności.
- Metoda getObjectArray() (ArrayFetch) nie jest nigdy wykonywana wolniej niż n razy metoda getObject(),
ale często szybciej. Wymaga najwyżej jednego zapytania do bazy danych w przeciwieństwie do maksymalnie n zapytań do bazy bazy. Kolejną zaletą jest to, że mapping atrybutów między OQL, SQL i Java musi być ustalone tylko jeden raz. - Jeśli dla wczytywanego obiektu biznesowego jest aktywowany caching, metody getObject(), getObjectArray() i
getObjectIterator() zawsze najpierw odczytują Shared Cache.
Dodają one również instancje załadowane z bazy danych do pamięci podręcznej. W przypadku często używanych obiektów biznesowych (np. dane podstawowe) metody te są przydatne, ponieważ podczas dostępu zawsze uwzględniają pamięć podręczną. Natomiast bez użycia odpowiednich flag dostępu nie są one odpowiednie dla
masowych operacji na danych transakcyjnych (np. zapytanie o dostępność artykułów), ponieważ mogą one wypierać z pamięci Shared Cache inne często używane dane, mimo że dodane dane prawie nigdy nie zostaną użyte. Dlatego takie dane powinny być zaczytane z flagą dostępu IGNORE_SHARED_CACHE. Tworzenie wielu obiektów Java, które są potrzebne tylko tymczasowo, jest również bardzo czasochłonne i zajmuje dużo miejsca w pamięci głównej.
Za pomocą metody getResultSet() można jest wczytywać tylko te atrybuty, które są potrzebne, a nie całą instancję obiektu biznesowego z dziesiątkami atrybutów. Pozwala to utrzymać ilość danych na odpowiednio niskim poziomie, również dlatego, że w Javie tworzonych jest mniej obiektów. W przypadku getResultSet() na programiście spoczywa znacznie większa odpowiedzialność, ponieważ otwarty zestaw ResultSet wyłącznie zajmuje połączenie z bazą danych. Ponadto programista sam odpowiada za mapowanie wyników z zestawu na atrybuty Java.
Wczytywanie za pomocą relacji
Jeśli dla obiektu biznesowego są zdefiniowane relacje, powiązane instancje mogą być mogą być wczytywane za pomocą metod relacji retrieve…(). Dostęp do odczytu poprzez managera obiektów (getObject() lub getObjectIterator()) odbywa się w sposób przejrzysty dla deweloperów. Wynikiem relacji „1 do 1” jest null, jeśli jeden z atrybutów relacji ma wartość null. Wynik relacji „1 do n” nie jest sortowany. Wewnętrznie stosowana jest instrukcja OQL (patrz Metoda getObjectIterator()).
Ładowanie za pomocą relacji „ do 1“:
Poniższy fragment kodu źródłowego pokazuje ładowanie powiązanej instancji obiektu biznesowego Country za pomocą metody relacyjnej retrieveCountry() obiektu biznesowego Region.
Region region = (Region)om.getObject(primKey); Country country = region.retrieveCountry();
Ładowanie za pomocą relacji „1 do n“:
Poniższy fragment kodu źródłowego pokazuje ładowanie powiązanych instancji obiektu biznesowego Region za pomocą metody relacyjnej retrieveRegions() obiektu biznesowego Country bez przyporządkowania w Try.
CisObjectIterator<Region> iter = country.retrieveRegions();
try {
while (iter.hasNext()) {
Region region = iter.next();
}
} finally {
iter.close();
}
Ten sam przykład z przyporządkowaniem w Try:
try (CisObjectIterator<Region> iter = country.retrieveRegi-ons()) {
while (iter.hasNext()) {
Region region = iter.next();
}
}
Dostępy zapisu przez managera obiektów
Do zmiany lub usunięcia instancji obiektu biznesowego służą metody menedżera obiektów putObject() i deleteObject().
Metody putObject()
Metoda putObject() rejestruje do zapisu w bazie danych instancję obiektu biznesowego. Zostaje ona zapisana w pamięci podręcznej transakcji bieżącej i staje się trwała dopiero po wykonaniu commit() dla transakcji.
Aby utworzyć lub zmienić instancję obiektu biznesowego, należy najpierw otworzyć transakcję Top Level. Następnie
instancja jest wczytywana za pomocą getObject() z określeniem żądanego trybu dostępu. Tryb dostępu READ_UPDATE dostarcza instancje, które można dowolnie zmienić lub usunąć. Tryb dostępu READ_WRITE działa w taki sam sposób. Jeśli jednak nie istnieje instancja żądanego obiektu, jest on tworzony na nowo. W takim przypadku READ_UPDATE zwraca wartość null. Odczytana instancja obiektu biznesowego jest zablokowana dla innych transakcji przez usługę trwałości danych. Jeśli inna transakcja chce odczytać tę samą instancję obiektu biznesowego, po określonym czasie może wystąpić przekroczenie limitu czasu. Zmiany atrybutów są dokonywane za pomocą metod set…() danego obiektu biznesowego. Wywołanie metody putObject() z instancją obiektu biznesowego jako parametrem przenosi zmiany do bieżącej pamięci Transaction Cache. Ponowne getObject() w tej transakcji zwraca tym razem zmienioną instancję obiektu biznesowego. Przy commit() transakcji brane są pod uwagę tylko zmiany zarejestrowane za pomocą putObject(). Zarejestrowane zmiany staną się trwałe w bazie danych dopiero po wykonaniu commit() transakcji Top Level. W przypadku wystąpienia błędu przed lub podczas wykonywania commit() dla bieżącej transakcji, należy wywołać jawny rollback(), jeśli transakcja została otwarta za pomocą beginNew(), a nie za pomocą createNew().
Poniższy fragment kodu źródłowego ładuje instancję obiektu biznesowego UnitOfMeasure z bazy danych lub
tworzy nową instancję za pomocą beginNew().
tm.beginNew();
try {
byte[] key = UnitOfMeasure.buildByCodeKey(code);
// Laden der Instanz zum Ändern/Anlegen
UnitOfMeasure unitOfMeasure = (UnitOfMeasure)
om.getObject(key, CisObjectManager.READ_WRITE);
// Setzen der Attribute
unitOfMeasure.setDescription(description);
...
// Registrieren der Änderungen im Transaction-Cache
om.putObject(unitOfMeasure);
// Beenden der Transaktion, Schreiben der
Änderungen
tm.commit();
} catch (RuntimeException e) {
// explizites Rollback bei Fehler
tm.rollback();
throw e;
}
Poniższy fragment kodu źródłowego ładuje instancję obiektu biznesowego UnitOfMeasure z bazy danych lub
tworzy nową instancję za pomocą createNew().
try (CisTransaction txn =tm.createNew()) {
byte[] key = UnitOfMeasure.buildByCodeKey(code);
//Laden der Instanz zum Ändern/Anlegen
UnitOfMeasure unitOfMeasure = (UnitOfMeasure) om.getObject(key, CisObjectManager.READ_WRITE);
//Setzen der Attribute unitOfMeasure.setDescription(description); ...
//Registrieren der Änderungen im Transaction-Cache
om.putObject(unitOfMeasure);
//Beenden der Transaktion, Schreiben der
Änderungen
txn.commit();
}
Metoda deleteObject()
Metoda deleteObject() usuwa instancję obiektu biznesowego z bazy danych.
Aby usunąć instancję, najpierw należy otworzyć transakcję Top Level. Obiekt biznesowy, który ma zostać zmieniony, jest następnie pobierany za pomocą getObject() w trybie dostępu READ_UPDATE. Wywołanie deleteObject() z instancją obiektu biznesowego jako parametrem powoduje zaznaczenie instancji do usunięcia w aktualnej pamięci Transaktion Cache. Operacja na bazie danych nie jest wykonywana aż do commit() transakcji najwyższego poziomu.
Jeśli wystąpi błąd przed lub w trakcie commit() bieżącej transakcji
należy wywołać jawną funkcję rollback(), jeśli transakcja została otwarta za pomocą funkcji beginNew(), a nie createNew(). Operacja na bazie danych zostanie wykonana dopiero przy commit() transakcji Top Level. W przypadku wystąpienia błędu przed lub podczas wykonywania commit() dla bieżącej transakcji, należy wywołać jawny rollback(), jeśli transakcja została otwarta za pomocą beginNew(), a nie za pomocą createNew().
Poniższy fragment kodu źródłowego pobiera instancję obiektu biznesowego UnitOfMeasure z bazy danych. Jeśli
instancja nie zostanie znaleziona, zwracana jest wartość null. Znaleziona instancja będzie oznaczona do usunięcia. Wykonanie commit() powoduje usunięcie instancji.
byte[] transGuid= tm.beginNew();
try {
byte[] key = UnitOfMeasure.buildByCodeKey(code);
//Laden der Instanz zum Ändern/Anlegen
UnitOfMeasure unitOfMeasure = (UnitOfMeasure) om.getObject(key,
CisObjectManager.READ_UPDATE);
if (unitOfMeasure==null) {
//nicht gefunden
...
} else {
// Markieren zum Löschen
om.deleteObject(unitOfMeasure);
}
// Beenden der Transaktion, Schreiben der
Änderungen
tm.commit(transGuid);
} catch (RuntimeException e) {
// explizites Rollback bei Fehler
tm.rollback(transGuid);
throw e;
}
Ten sam przykład z użyciem funkcji createNew():
try (CisTransaction txn =tm.createNew()) {
byte[] key = UnitOfMeasure.buildByCodeKey(code);
//Laden der Instanz zum Ändern/Anlegen UnitOfMeasure
unitOfMeasure = (UnitOfMeasure) om.getObject(key, CisObjectMan-ager.READ_UPDATE);
if (unitOfMeasure==null) {
//nicht gefunden ...
} else {
//Markieren zum Löschen
om.deleteObject(unitOfMeasure);
} //Beenden der Transaktion, Schreiben der
Änderungen
txn.commit(transGuid);
}
Obsługa błędów transakcji
Należy pamiętać, że transakcja otwarta za pomocą begin() lub beginNew() anulowana jest zawsze za pomocą rollback() lub zamykana za pomocą commit(). Dlatego konieczna jest obsługa wyjątków występujących w ramach bloku transakcji. Ponadto w określonych miejscach programu należy unikać ewentualnego wystąpienia wyjątków. W przypadku zagnieżdżonych transakcji należy zadbać o to, aby nie doprowadzić do wymieszania stosu transakcji, np. jeśli przez pomyłkę zamknięta zostanie również transakcja nadrzędna. Aby zminimalizować ryzyko, że Rollback lub Commit zostanie wykonany dla niewłaściwej transakcji, można wykorzystać identyfikator transakcji Guid. beginNew()/begin() zwraca jako wartość identyfikator GUID bieżącej transakcji, który może zostać przekazany jako parametr dla rollback() i commit(). Jeśli podczas wykonywania commit() identyfikator nie odpowiada identyfikatorowi bieżącej transakcji, wówczas występuje wyjątek, a nieprawidłowa transakcja nie zostanie utrwalona. W przypadku funkcji rollback() pojawia się tylko ostrzeżenie, że identyfikatory transakcji nie są zgodne. Każda transakcja Top Level ma swój własny identyfikator transakcji, podczas gdy transakcje Sub Level zawierają identyfikator transakcji Top Level. Obecnie zastosowanie identyfikatora transakcji chroni przed niezamierzonym zamknięciem niewłaściwej transakcji Top Level, ale takie błędy są nadal możliwe w przypadku transakcji podrzędnych. W kolejnym wydaniu wersji ten mechanizm ochrony może zostać rozszerzony również na transakcje podrzędne, tak aby każda z tych transakcji posiadała swój własny identyfikator transakcji. Dlatego również w przypadku transakcji podrzędnych powinny być stosowane identyfikatory Guid. Transakcje tworzone za pomocą create() lub createNew() w „try” jako „AutoClosable” są automatycznie zamykane po opuszczeniu bloku try. Jeśli transakcja jest używana jako „AutoClosable”, wówczas nie ma możliwości nieprawidłowego użycia, ponieważ Java zapewnia prawidłowe zamknięcie transakcji.
Transakcja odczytu przez begin
Transakcja odczytu, która została otwarta za pomocą begin() lub beginNew() musi zawsze odpowiadać przedstawionemu poniżej szablonowi. W punktach oznaczonych /*xx*/ nie może zostać wywołany żaden wyjątek. Oznacza to, że te miejsca powinny zawierać kodu, ale tylko instrukcje, które nie mogą wywołać wyjątku. Transakcja tylko do odczytu powinna być zawsze wycofana za pomocą rollback(), ponieważ żadne zmiany nie są wprowadzane na bazie danych. Blok try finally gwarantuje, że zawsze wykonywany jest rollback(), niezależnie od tego, czy wyjątek wystąpi w bloku transakcji, czy nie.
Szablon dla transakcji odczytu:
byte[] transGuid= tm.begin...(..);
/*xx*/
try {
...
} finally {
/*xx*/
tm.rollback(transGuid);
...
}
Wyjątek w oznaczonych miejscach mógłby skutkować tym, że transakcja nie zostanie wycofana przez rollback().
Transakcja pozostałaby zatem otwarta i zostałaby zamknięta dopiero przy wykonaniu następnych funkcji commit() lub rollback() przeznaczonych dla innej transakcji. Stos transakcji nie byłby już spójny, co prowadziłoby do utraty danych.
Transakcja odczytu przez create
Transakcja odczytu otwarta za pomocą create lub createNew musi zawsze odpowiadać przedstawionemu poniżej szablonowi. Zawsze należy stosować wygenerowaną transakcję w „try” jako „AutoClosable”, ponieważ w przeciwnym razie stos transakcji może być niespójny.
Szablon dla transakcji odczytu:
try (CisTransaction txn=tm.create...(..)) {
...
}
Transakcja zapisu przez begin
Transakcja zapisu, która została otwarta za pomocą begin() lub beginNew() musi zawsze odpowiadać przedstawionemu poniżej szablonowi. W punktach oznaczonych /*xx*/ nie może zostać wywołany żaden wyjątek. Oznacza to, że te miejsca powinny zawierać kodu, ale tylko instrukcje, które nie mogą wywołać wyjątku. Transakcję zapisu można przerwać za pomocą rollback() lub zakończyć za pomocą commit(). W przypadku przerwania transakcji wszystkie zmiany wprowadzone w transakcji lub w transakcjach podrzędnych zostaną odrzucone. Za pośrednictwem usługi trwałości dozwolone są dostępy odczytu i modyfikacji. Blok try catch gwarantuje, że w przypadku wystąpienia wyjątku w bloku transakcji transakcja jest jawnie anulowana za pomocą funkcji rollback(). W innym przypadku transakcja jest zamykana za pomocą commit().
Szablon dla transakcji zapisu:
byte[] transGuid= tm.begin...(..);
/*xx1*/
try {
...
tm.commit(transGuid);
/*xx2*/
} catch (RuntimeException ex) {
/*xx3*/
tm.rollback(transGuid);
...
}
Wyjątek w miejscu /*xx1*/ prowadzi do tego, że otwarta transakcja nie zostanie zamknięta za pomocą instrukcji należącej do bloku. Wyjątek w miejscu /*xx2*/ spowodowałby wykonanie rollback() w bloku catchBlock, co przerwałoby transakcję nadrzędną. Bieżąca transakcja została już zamknięta za pomocą commit(). Wyjątek w miejscu /*xx3*/ prowadzi do tego, że funkcja rollback() nie zostanie wykonana, a transakcja pozostanie otwarta.
Transakcja zapisu przez create
Transakcja zapisu, która została otwarta za pomocą create lub createNew musi zawsze odpowiadać przedstawionemu poniżej szablonowi. W miejscach oznaczonych /*xx*/ nie jest dozwolony dostęp do managera obiektów. Dlatego po commit nie powinien pojawiać się żaden kod.
Szablon dla transakcji zapisu:
try (CisTransaction txn=tm.create…(..)) {
…
txn.commit();
/*xx*/
}
Transakcja otwarta za pomocą create jest już zamknięta w miejscu /*xx*/. Manager obiektów nie używa transakcji otwartej w „try” w miejscu /* xx */.
Transakcja zapisu blokowego przez create
Transakcja powinna mieć ograniczony rozmiar. Jeśli ma zostać zapisana nieograniczona ilość danych, to dane te powinny być zapisywane w blokach o ograniczonym rozmiarze. Rozmiar bloku może być narzucony jako stała (np. 100 rekordów danych na transakcję) lub obliczany dynamicznie przez managera transakcji. W miejscach oznaczonych /*xx*/ nie jest dozwolony dostęp do managera obiektów. Dlatego po commit nie powinno być żadnego kodu.
Szablon transakcji ze stałymi rozmiarami bloków z commitBlock():
try (CisTransaction txn=tm.create...(..)) {
int i=0;
while (…) {
...
Om.putObject(o);
if (++i%100=0) {
txn.commitBlock();
}
}
txn.commit();
/*xx*/
}
Szablon transakcji z dynamicznymi rozmiarami bloków z commitIfSizeLimitExceeded:
try (CisTransaction txn=tm.create...(..)) {
int i=0;
while (…) {
…
Om.putObject(o);
txn.commitIfSizeLimitExceeded();
}
txn.commit();
/*xx*/
}
Transakcja otwarta za pomocą create jest już zamknięta w miejscu /*xx*/. Manager obiektów nie używa w miejscu
/*xx */ transakcji otwartej w „try”.
Trwałe i przechodnie obiekty biznesowe
Instancja obiektu biznesowego przyjmuje dwa ortogonalne stany w odniesieniu do bazy danych i przynależności do transakcji. Zapytanie o te stany można wykonać za pomocą metod is_persistent() oraz is_transient().
Metoda is_persistent() służy do określania, czy instancja obiektu biznesowego jest zapisana w bazie danych. Jeśli metoda zwróci wartość true, oznacza to, że instancja istnieje w bazie danych; jeśli wynikiem jest false, instancja nie istnieje w bazie danych. Metoda is_transient() służy do określenia, czy instancja obiektu biznesowego ma kontekst transakcji, tzn. czy instancja jest przechowywana w Transaction Cache bieżącej transakcji. Wartość false wskazuje na istnienie kontekstu transakcji dla przedmiotowej instancji obiektu biznesowego i jej ważności tylko w bieżącej transakcji. Jeśli metoda zwraca wartość true, oznacza to, że instancja nie jest powiązana z transakcją. Dla nowo wygenerowanych instancji, które zostały zarejestrowane do zapisu za pomocą putObject(), ale nie zostały jeszcze zapisane w bazie (transakcja Top Level nie jest jeszcze commited), metoda is_persistent zwraca wartość false. Za pomocą is_newObject() można ustalić, czy nowo wygenerowana instancja została już zarejestrowana do zapisu. Ta metoda zwraca wartość true, jeśli obiekt nie jest ani trwały, ani nie został zarejestrowany za pomocą putObject().
Należy przestrzegać tych znaczników podczas pracy z obiektami biznesowymi, aby móc tworzyć aplikacje spójne z systemem ERP. Nieprzechodnia instancja obiektu biznesowego, która została wczytana np. za pomocą getObject(), getObjectArray() lub getObjectIterator(), jest zawsze powiązana z bieżącą transakcją i dlatego traci ważność po zakończeniu transakcji. W przypadku transakcji podrzędnej instancje nieprzechodnie są włączane do kontekstu transakcji nadrzędnej i mogą być tam nadal używane. Dalsze korzystanie z instancji poza transakcją może
może prowadzić do błędów programu i dlatego jest zabronione.
Dla metod putObject() i deleteObject() przewidziane są nieprzechodnie instancje obiektów biznesowych jako jako parametry, za pomocą których można załadować lub wygenerować metody getObject(), getObjectIterator()
i getObjectArray() określając odpowiednie flagi dostępu.
Metoda getTransientCopy()
Jeśli instancja obiektu biznesowego została załadowana poprzez getObject() z określeniem flagi READ, READ_UPDATE lub READ_WRITE (wczytywana instancja istnieje w bazie danych), wówczas is_persistent() zwraca true, a is_transient() zwraca false. Aby zastosować instancję dla wszystkich transakcji, należy wygenerować nową przechodnią kopię za pomocą metody getTransientCopy() klasy obiektu biznesowego. Oprócz wartości atrybutów
kopiowana jest również flaga persistent, a flaga transient jest ustawiana na wartość true. Utworzona w ten sposób przechodnia instancja obiektu biznesowego nie należy do żadnej transakcji i może być używana dla wszystkich transakcji. Ta metoda jest bardzo przydatna, jeśli chce się zapamiętać zawartość instancji obiektu biznesowego po zakończeniu transakcji, np. do wyświetlenia GUI.
Metoda newTransientInstance()
Ta metoda klasy obiektu biznesowego generuje pustą przejściową, nietrwałą instancję obiektu biznesowego (is_persistent() zwraca wartość false, a is_transient() zwraca wartość true).
Metoda copyTo()
Ta metoda klasy obiektów biznesowych może być używana do kopiowania wartości atrybutów danej instancji do innej instancji tego samego obiektu biznesowego. Obiektem źródłowym lub docelowym mogą być zarówno trwałe jak i przechodnie instancje. W każdym przypadku copyTo() przenosi wartości atrybutów i klucz biznesowy źródła do obiektu docelowego. Specjalne postępowanie wymagane jest w następujących przypadkach:
- Jeśli obiekt docelowy jest instancją przechodnią, to kopiowane są również flaga trwałości i klucz podstawowy źródła.
- Jeśli obiekt docelowy nie jest instancją trwałą, to kopiowany jest klucz podstawowy źródła.
- Jeśli obiekt docelowy jest przechodni, a dla klasy obiektów biznesowych jest wymagana informacja i aktualizacji, to pełna informacja o aktualizacji jest również kopiowana ze źródła. Funkcjonalne oznaczenie usuwania dla źródła
(flaga delete) jest zawsze kopiowana do obiektu docelowego. - Jeśli obiekt docelowy jest przechodni i zależny od czasu, kopiowane są również atrybuty validFrom i validUntil źródła.
Ogólna zasada brzmi: Do nieprzechodniego, trwałego obiektu docelowego nie jest kopiowany żaden atrybut ani flaga, które mogłyby zmienić kontekst transakcji obiektu biznesowego. Na przechodni obiekt docelowy kopiowane jest wszystko.
Poniższy rysunek przedstawia możliwe kombinacje flag przechodnich i trwałych flag instancji obiektu biznesowego
i określa możliwe metody wymiany danych między instancjami nieprzechodnimi i przechodnimi. Metoda getObject() jest tutaj używana jako zamiennik dla metod getObjectArray() i getObjectIterator(), które wewnętrznie odwołują się do metody getObject().
![]()
Blokady logiczne
Blokady logiczne są używane do synchronizacji uruchomionych aplikacji, które pracują na tych samych instancjach obiektów biznesowych. Nie mają one nic wspólnego z blokadami ustawianymi przez transakcje na instancjach obiektów
biznesowych. Blokady logiczne muszą być zapewnione przez programistę aplikacji.
Aplikacje dialogowe działają w następujący sposób:
- instancja obiektu biznesowego wybrana przez użytkownika jest wczytywana poprzez transakcję odczytu
- użytkownik zmienia dane
- instancja jest zapisywana poprzez transakcję zapisu
Podczas gdy jeden użytkownik zmienia dane, drugi użytkownik może również załadować, edytować, a nieco wcześniej zapisać tę samą instancję obiektu biznesowego. Pierwszy użytkownik mógłby nadpisać zmiany wprowadzone przez drugiego użytkownika, ponieważ zaczytał stare dane. Należy oczywiście unikać tego typu sytuacji. Istnieją dwa sposoby rozwiązania tego konfliktu: blokowanie optymistyczne i blokowanie pesymistyczne.
Blokowanie optymistyczne
W wielu przypadkach wystarcza blokada optymistyczna. Instancja obiektu biznesowego, która ma zostać zmieniona, jest wtedy wczytywana bez ustawiania blokady. Przed zapisaniem system sprawdza, czy instancja obiektu została zmieniona w bazie danych od momentu ostatniego załadowania. Jeśli nie została wprowadzona żadna zmiana, wówczas instancja obiektu jest zapisywana. W przeciwnym wypadku instancja nie jest zapisywana, a użytkownik otrzymuje komunikat, że dane zostały w międzyczasie zmienione przez innego użytkownika i przed edycją należy aktualizować dane.
Blokowanie pesymistyczne
W przypadku złożonych wielkości technicznych, np. zlecenia, zaleca się możliwie jak najwcześniejsze zablokowanie, aby uniknąć wprowadzenia innych zmian, ponieważ nie można oczekiwać, że użytkownik powtórzy wpisy. W systemie ERP pesymistyczne blokady są realizowane za pomocą tak zwanych locks. Są one ustawiane przez aplikacje i zarządzane centralnie za pośrednictwem managera aplikacji. Lock jest wyrażony poprzez ciąg znaków stosowany przez aplikację jako nazwa dla zasobu. W ten sposób aplikacja żąda od managera aplikacji blokady z odpowiednim lock string. Jeśli blokada już istnieje pod tą nazwa, blokada nie może zostać ustawiona. Jeśli natomiast nie ma jeszcze blokady pod tą nazwą, lock string jest dodawany do listy blokad i blokada zostaje ustawiona. Od tego momentu żadna inna aplikacja z tym samym lock string nie może otrzymać blokady od managera aplikacji. Aplikacja musi jawnie zwolnić ustawioną blokadę. Wszystkie ustawione locks są niejawnie zwalniane po zakończeniu danej sesji (np. zamknięcie przeglądarki). Jeśli kilka aplikacji używa tych samych Lock strings dla zasobów, trzeba upewnić się, że odnoszą się one do tego samego zasobu. Dlatego najlepiej stosować zawsze unikalny string, np. dodając wartość klucza. Ponadto lock string powinien zawierać numer GUID bazy danych, w której zmieniana jest instancja obiektu biznesowego, aby zagwarantować unikalność, w przypadku gdy ten obiekt biznesowy istnieje w wielu bazach danych.
Aby korzystać z centralnego zarządzania blokadami w aplikacji, należy najpierw wykonać przez środowisko sesji zapytanie o managera aplikacji (klasa com.cisag.pgm.appserver.CisApplicationManager):
CisEnvironment env = CisEnvironment.getInstance(); CisApplicationManager am = env.getApplicationManager();
Poniższy fragment kodu źródłowego pokazuje żądanie blokady z managera aplikacji. Blokada ma zostać ustawiona dla instancji obiektu biznesowego PriceList. Lock string jest tworzony z nazwy klasy obiektu biznesowego i klucza podstawowego instancji. Jeśli blokada jest już ustawiona, system nie czeka na zwolnienie.
//eindeutigen Lock-String erzeugen
String lockString = PriceList.class.getName() +
Guid.toHexString(priceListGuid) ;
//Datenbank-Information der aktiven OLTP-DB hinzufügen
lockString = tm.buildDatabaseLock(lockString);
//Sperre anfordern
boolean locked = am.acquireLock(lockString);
if (locked) {
//lock success
...
} else {
//already locked
//User-Information der schon gehaltenen Sperre
ermitteln
String user = am.getLockInformation(lockString);
...
}
Zwolnienie blokady odbywa się w odpowiednim miejscu aplikacji za pomocą:
am.releaseLock(lockString);
Metoda acquireLock()
Metoda acquireLock() w managerze aplikacji może być użyta do ustawienia pesymistycznych blokad. Metoda ta ma kilka sygnatur, których można użyć do ustawienia jednej lub więcej blokad:
public boolean acquireLock(String value); public boolean acquireLock(String values[]); public boolean acquireLock(String value, long timeout); public boolean acquireLock(String[] values,long timeout);
Maksymalny czas oczekiwania na zwolnienie istniejących już blokad można określić za pomocą parametru timeout. Wartość true jest zwracana, jeśli udało się ustawić blokadę, w przeciwnym wypadku zwracana jest wartość false. W przypadku żądania blokad dla wielu zasobów zwracana jest tylko wartość true, jeśli udało się żądanie wszystkich blokad. Mogła zostać również zablokowana część zasobów, wtedy muszą one zostać pojedynczo i jawnie ponownie zwolnione.
Metoda releaseLock()
Metoda releaseLock() zwalnia ustawioną blokadę. Określony lock string jest usuwany z tabeli blokad managera aplikacji. Metoda ma następującą sygnaturę:
public void releaseLock(String value);
Metoda getLockInformation()
Metoda ustala nazwę użytkownika dla istniejącej blokady i niejawnie ponownie zwalnia tę blokadę. Z tego powodu metoda powinna być używana tylko po nieudanym żądaniu blokady, aby uzyskać informacje o tym, kto ustawił istniejącą blokadę. Metoda ma następującą sygnaturę:
public String getLockInformation(String value);
Dynamiczny OQL
Składnia dostępnego języka zapytań jest podobna do SQL. Zapytania są formułowane na obiektach biznesowych, a nie na tabelach bazy danych. Atrybuty są oddzielone od nazwy klasy znakiem”:”, tak jak w SQL. Potencjał wyrażeń OQL, możliwych do sformułowania, w dużej mierze odpowiada potencjałowi wyrażeń SQL. I tak na przykład w klauzuli WHERE są dozwolone Sub Selects, można formułować Joins.
bo:part1.part2 jako x, bo:part1. part2.attr2 jako y …).
Szczegółowy opis składni OQL można znaleźć w dokumentacji OQL.
Joins
OQL Joins pracują zawsze z dwiema definicjami obiektów biznesowych, które są połączone za pomocą klauzuli atrybutu. Wynikiem jest wirtualna definicja obiektu biznesowego, której atrybuty są pobierane od partnerów join.
To, które atrybuty są przenoszone do wyniku pod jaką nazwą, można wybrać za pomocą klauzuli SELECT. Istnieje możliwość zagnieżdżania joins. Oznacza to, że można tworzyć bardzo złożone zapytania, które
używane na przykład dla wyszukiwania OQL lub widoków OQL. Istnieje kilka wariantów join, ich krótki opis znajduje się poniżej. W celu zachowania przejrzystości podczas formułowania joins należy stosować długą formę pisowni.
Inner Join
Składnia:
bo1 bo1_alias INNER JOIN bo2 bo2_alias ON bo1_alias:attr = bo2_alias:attr
Zbiór wyników jest określany przez bo1 i bo2. Powiązanie odbywa się jest przy użyciu tych samych wartości dla atrybutów określonych w klauzuli on. Instancje bo1 będą uwzględniane w wyniku zawsze wtedy, gdy odpowiedni partner został znaleziony bo2. Skrócona forma pisowni to „JOIN”.
Left Outer Join
Składnia:
bo1 bo1_alias LEFT OUTER JOIN bo2 bo2_alias ON bo1_alias:attr = bo2_alias:attr
Zbiór wyników jest określany przez bo1. Powiązanie odbywa się przy użyciu tych samych wartości dla atrybutów określonych w klauzuli on. Instancje bo1 będą uwzględniane w wyniku zawsze wtedy, gdy w bo1 istniał partner. Skrócona forma pisowni to „OUTER JOIN”.
Right Outer Join
Składnia:
bo1 bo1_alias RIGHT OUTER JOIN bo2 bo2_alias ON bo1_alias:attr = bo2_alias:attr
Zbiór wyników jest określany przez bo2. Powiązanie odbywa się przy użyciu tych samych wartości dla atrybutów określonych w klauzuli on. Instancje bo2 będą uwzględniane w wyniku zawsze wtedy, gdy w bo2 istniał partner.
Full Outer Join
Ten typ join nie jest obsługiwany przez OQL.
Schematy numeracji
Schematy numeracji to zakresy numerów używane podczas przypisywania unikalnych numerów dla instancji
obiektów biznesowych, które są identyfikowane przez ten numer. Numer ten zwykle przedstawia klucz funkcjonalny. Numery przypisane za pośrednictwem schematu numeracji odpowiadają formatowi określonemu w definicji schematu numeracji, a przyrost odbywa się w określonym odstępie.



