W Comarch ERP Enterprise, wyszukiwania umożliwiają kontrolowane znajdowanie obiektów w bazie danych. Dla użytkownika, wyszukiwania pojawiają się jako narzędzie pomocnicze w formie pomocy wartości dla pól oraz jako wyszukiwania specyficzne dla aplikacji w obszarze nawigacji. Ponadto, wyszukiwania są również używane w aplikacjach, np. w aplikacjach typu lista.
Ten artykuł wyjaśnia, co dzieje się pod powierzchnią, jak przebiega proces wyszukiwania oraz jakie możliwości ingerencji ma programista. Odnosi się także do przypadków specjalnych, np. części specjalnych, ponownego uruchamiania itd.
Grupa docelowa
- Programiści
Opis
Zastosowanie wyszukiwania
Wyszukiwania w Comarch ERP Enterprise są oferowane w różnych miejscach i w różnych formach.
Pomoc wyszukiwania wartości
Pomoc wyszukiwania wartości jest przedstawiana jako lista wyboru lub okno dialogowe wyszukiwania.
Lista wyboru jest zawsze wizualizowana bezpośrednio przy polu, dla którego została wywołana. Wynik wyszukiwania może być zawężony przez treść pola. Lista wyboru zawiera od 2 do 60 pozycji. W zależności od ustawień można wybrać jedną lub więcej pozycji i przenieść je do wywołującego pola.
W oknie dialogowym wyszukiwania wynik może być zawężony przez wprowadzenie wielu kryteriów wyszukiwania. Okno dialogowe wyszukiwania jest podzielone na nagłówek i obszar roboczy. W nagłówku można wprowadzić wspomniane kryteria. Kryteria te można także zapisać jako wzorce wyszukiwania i wykorzystywać je później. Obszar roboczy zawiera listę wszystkich znalezionych elementów. W zależności od ustawień, można wybrać jeden lub więcej elementów z wyników wyszukiwania i przenieść je do wywołującego pola.
Wyszukiwanie specyficzne dla aplikacji w nagłówku aplikacji
W nagłówku znajduje się zakładka Wyszukiwania. Zawartość tej zakładki zależy od aktualnej aplikacji. Poprzez pole wyboru można wybierać różne wyszukiwania. Prezentacja wyszukiwania w tej zakładce jest zbliżona do okna dialogowego wyszukiwania. Ponieważ szerokość wyszukiwania jest mocno ograniczona, nazwy pól w nagłówku aplikacji są wyświetlane nad swoimi polami.
Aplikacje typu lista
Do wyszukiwania obiektów rozwijane są również aplikacje do zapytań. Z możliwości wyszukiwania oferowanych w Comarch ERP Enterprise, tutaj wykorzystywane są jedynie czyste operacje wyszukiwania. Projekt i struktura wyszukiwania nie podlegają żadnym ograniczeniom. Aplikacje do zapytań nie będą dalej omawiane w tym artykule.
Przebieg pomocy wyszukiwania wartości
Przebieg pomocy wyszukiwania wartości odbywa się zasadniczo w czterech krokach: przygotowanie, wstępne wyszukiwanie, wizualizacja i przejęcie wyniku. Najpierw wyszukiwanie jest przygotowywane poprzez załadowanie metadanych i inicjalizację danych czasu działania. W zależności od sposobu uruchomienia i danych wprowadzonych przez użytkownika, może zostać wykonane wstępne wyszukiwanie. Jeśli wstępne wyszukiwanie zwróci dokładnie jeden wynik, jest on od razu przenoszony do pola. W pozostałych przypadkach wyświetlana jest wizualizacja (lista wyboru lub okno dialogowe). W liście wyboru użytkownik może wybrać jedną z wyświetlanych wartości i przenieść ją do pola. W oknie dialogowym wyszukiwania wynik można dodatkowo zawęzić, wprowadzając kryteria wyszukiwania, a następnie przenieść do pola.
W przypadku pól wielowartościowych, w obu wizualizacjach możliwe jest wybranie i przejęcie więcej niż jednego rekordu.
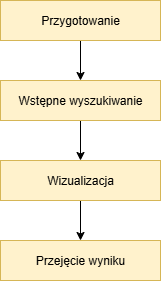
Przegląd przebiegu pomocy wyszukiwania wartości
Wykonanie wyszukiwania
W kolejnych rozdziałach, w niektórych diagramach, pojawia się pojęcie wykonanie wyszukiwania. Kryje się za tym następujący przebieg:
W danych czasu działania zarejestrowany jest SearchIterator. Jest on parametryzowany kryteriami wyszukiwania. Kryteria te mogą pochodzić np. z danych czasu działania lub z dialogu wyszukiwania.
Następnie wyszukiwanie jest wykonywane. Wykonanie wyszukiwania może być modyfikowane za pomocą ExecuteHook.
Nie wszystkie dane są odczytywane z bazy danych naraz. Zamiast tego, dane są udostępniane w blokach po 60 rekordów każdy. Otrzymane rekordy mogą być modyfikowane lub usuwane za pomocą ResultHooks, a także można tworzyć nowe rekordy i dodawać je do bloku danych. Jeśli liczba rekordów z powodu hooków spadnie poniżej 60, a jednocześnie dostępne są kolejne rekordy w iteratorze, odczytywane jest kolejne 60 rekordów, aby uzyskać co najmniej 60 rekordów.
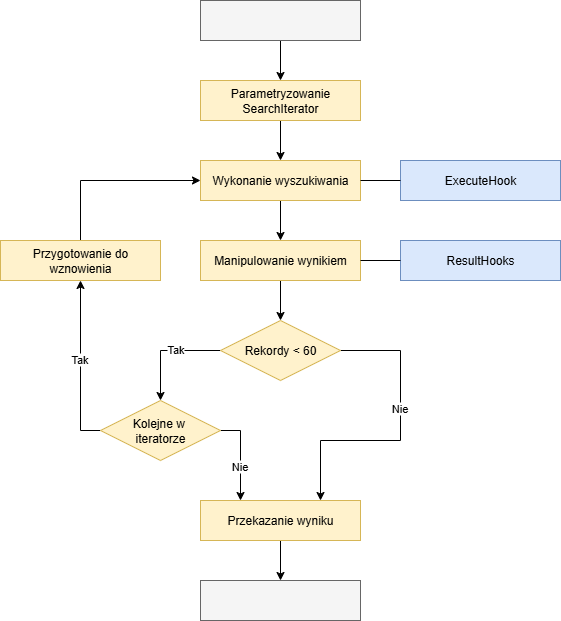
Przebieg wyszukiwania
Przygotowania
Podczas uruchamiania aplikacji, dla wszystkich pól, które wykorzystują wyszukiwanie, inicjowane są zarejestrowane SearchManager. Zazwyczaj jest to klasa DefaultSearchManager.
Gdy tylko wyszukiwanie zostanie wywołane dla elementu wizualnego (VisualElement), w SearchManager wywoływana jest metoda searchValueFor.
Z bazy danych repozytorium tworzone są dane czasu działania dla wyszukiwania. Atrybuty wyszukiwania mogą być przy tym wstępnie wypełnione za pomocą własnego SearchManager.
Następnie tworzony jest SearchIterator. Zazwyczaj jest to CisSearchIterator. Iterator jest dodawany do danych czasu działania. Poprzez implementację SearchIteratorHooks można podłączyć własną implementację SearchIterator.
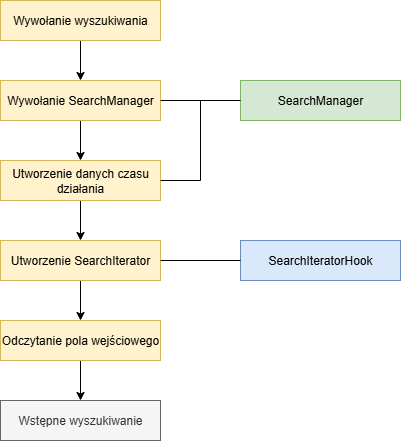
Odczytanie danych wejściowych i przygotowanie wyszukiwania z podaniem hooków
Wstępne wyszukiwanie
Wyszukiwanie OQL jest definiowane w bazie danych repozytorium. Dla dalszej analizy szczególnie interesujące są trzy ustawienia: wyświetlanie, identyfikacja specjalnego zachowania i nazwa specjalnego zachowania.
W wyszukiwaniu określony jest typ wyświetlania. Możliwe wartości to Okno dialogowe i ComboBox. Wraz z tym ustawieniem, zachowuje się oczekiwana ilość danych. Jeśli jest mniejsza niż 60 rekordów danych, należy wybrać ComboBox. Od 60 rekordów danych należy wybrać ustawienie Okno dialogowe. Ponadto, w przypadku ustawienia ComboBox, wyszukiwanie jest gwarantowane, tzn. po otwarciu pomocniczej listy wartości użytkownikowi zawsze oferowany jest wybór, bez konieczności jakiegokolwiek ograniczenia wyniku lub aktywnego rozpoczęcia wyszukiwania. W przypadku ustawienia Okno dialogowe nie można tego zrobić, ponieważ nie da się oszacować, w jakim stopniu wykonanie wyszukiwania obciąży system.
Dwa atrybuty wyszukiwania można opatrzyć specjalnym zachowaniem Identyfikacja i Nazwa. Jednocześnie atrybuty te muszą być wprowadzone jako cecha wyszukiwania, wartość wyświetlana i wartość zwracana. Jeśli podane są oba specjalne zachowania, pomocnicza lista wartości może być ograniczona z pola wprowadzania.
Wyszukiwanie można uruchomić za pomocą różnych skrótów klawiaturowych lub klikając na symbol pomocniczej listy wartości w polu.
Rozróżnia się cztery różne typy uruchomienia:
- Wyszukiwanie po identyfikacji
- Wyszukiwanie po nazwie
- Rozszerzone wyszukiwanie po identyfikacji
- Rozszerzone wyszukiwanie po nazwie
Poniższa tabela zawiera listę skrótów klawiaturowych i działań myszą dla każdego typu uruchomienia.
| Typ uruchomienia | Skrót klawiszowy/Mysz |
| Wyszukiwanie do identyfikacji |
|
| Wyszukiwanie po nazwie |
|
| Rozszerzone wyszukiwanie po identyfikacji |
|
| Rozszerzone wyszukiwanie po nazwie |
|
Jeśli w metadanych nie ma atrybutu ze specjalnym zachowaniem Nazwa, w obu wyszukiwaniach po nazwie zostanie wykonane wyszukiwanie po identyfikacji. Jeśli w metadanych nie ma również atrybutu oznaczonego specjalnym zachowaniem Identyfikacja, to wstępne wyszukiwanie jest pomijane i wyszukiwanie jest wizualizowane.
Wyszukiwanie po identyfikacji i nazwie
W przypadku wyszukiwania po identyfikacji i nazwie wstępne wyszukiwanie jest przeprowadzane tylko wtedy, gdy zawartość pola zawiera symbol wieloznaczny * lub ? lub gdy w metadanych wyszukiwania wpisano ComboBox. W zależności od ustawienia do wizualizacji używana jest lista wyboru lub okno dialogowe wyszukiwania. Okno dialogowe wyszukiwania jest również używane, gdy ustawienia w metadanych są ustawione na ComboBox, a ilość danych jest większa niż 59.
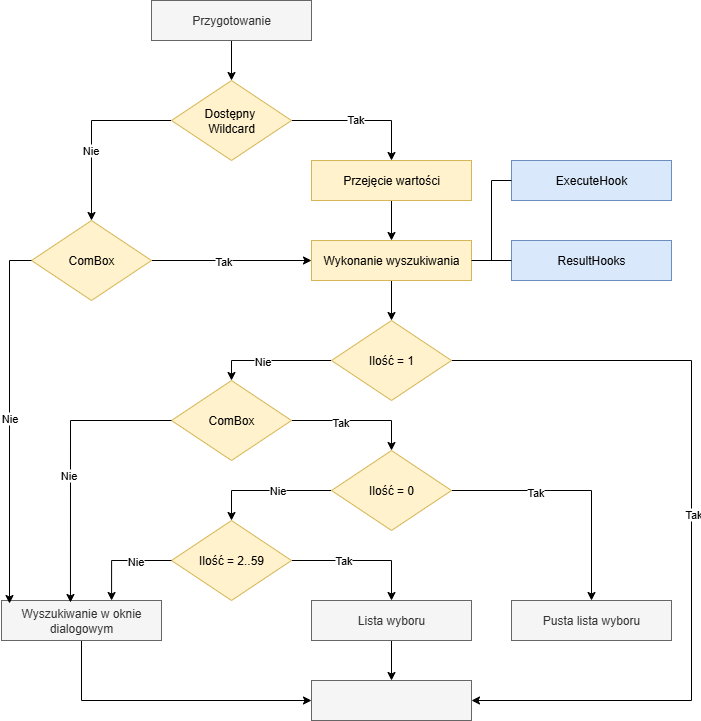
Wyszukiwanie po identyfikacji i nazwie
Rozszerzone wyszukiwanie po identyfikacji i nazwie
Rozszerzone wyszukiwanie po identyfikacji i nazwie ma dwuetapowe wstępne wyszukiwanie. Najpierw system próbuje znaleźć rekord danych pasujący do danych wprowadzonych przez użytkownika. Jeśli to się nie uda, w wyszukiwaniu po identyfikacji do wprowadzonych danych dodawany jest symbol wieloznaczny * na końcu, a w wyszukiwaniu po nazwie – symbol wieloznaczny * na początku i na końcu, po czym wyszukiwanie jest wykonywane ponownie.
W przypadku pola, które nie jest puste, wybór wizualizacji zależy wyłącznie od liczby rekordów danych. Poniżej sześćdziesięciu rekordów wyświetlana jest lista wyboru, a od sześćdziesięciu – okno dialogowe wyszukiwania. W przypadku pustego pola, do wizualizacji ponownie wykorzystywane są ustawienia z metadanych.
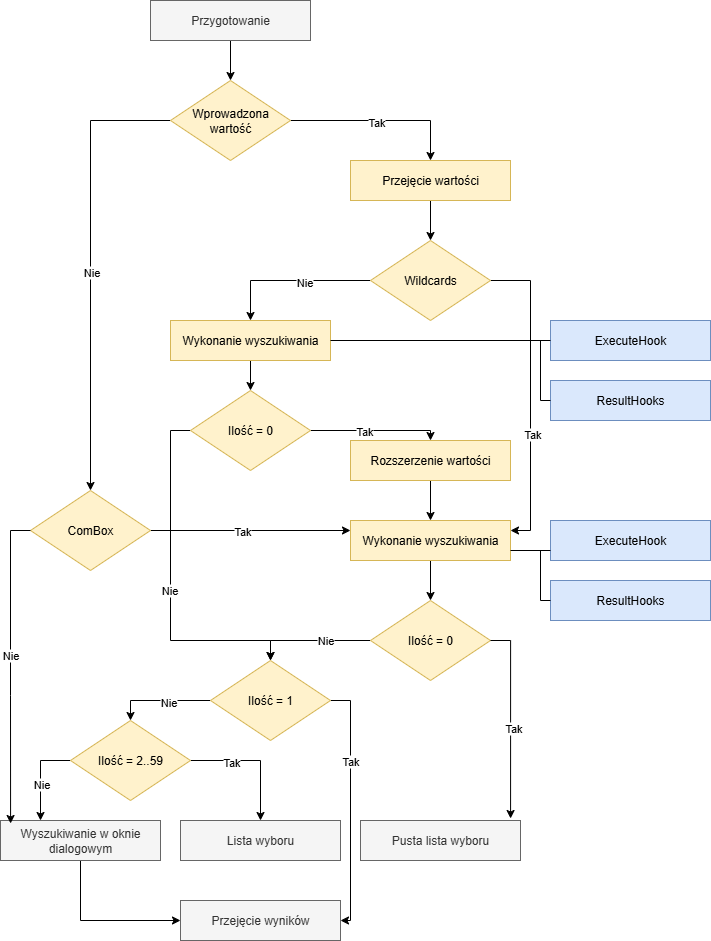
Rozszerzone wyszukiwanie po identyfikacji i nazwie
Wizualizacja jako wyszukiwanie w oknie dialogowym
Okno dialogowe składa się z dwóch obszarów: nagłówka i obszaru roboczego.
W nagłówku znajdują się odpowiednie pola, w zależności od typów danych atrybutów. Za pomocą SelectionFieldHook można zmienić właściwości używanych pól. Istnieje również możliwość użycia własnych pól zamiast tych proponowanych.
W obszarze roboczym do wyświetlania wyników wyszukiwania używany jest Grid-Control. Nazwy kolumn są nadawane na podstawie metadanych. Również tutaj deweloper ma kilka możliwości ingerencji. Za pomocą VisualisationHooks można manipulować wyświetlaniem lub wymienić je na listę.
Ewentualne istniejące predefiniowane wartości dla pól kryteriów wyszukiwania są odczytywane i ustawiane z danych wykonania wyszukiwania. Użytkownik ma teraz możliwość zawężenia wyszukiwania poprzez wpisanie kryteriów.
Wyszukiwanie jest wykonywane na podstawie kryteriów wyszukiwania.
Otrzymane rekordy danych są wyświetlane w obszarze wyświetlania. Użytkownik ma teraz kilka możliwości. Może zmienić wyszukiwanie, wprowadzając inne kryteria, i uruchomić je ponownie. Może również załadować kolejne rekordy, jeśli znaleziono ich więcej niż 60. Ponadto istnieje możliwość zapisania użytych kryteriów wyszukiwania i sortowania jako wzorca zapytania.
Gdy użytkownik znajdzie szukany rekord lub rekordy, musi je wybrać. Następnie, jeśli naciśnie przycisk przeznaczony do zatwierdzenia, wybrane rekordy danych zostaną zapisane w danych wykonania, a okno dialogowe zostanie zamknięte.
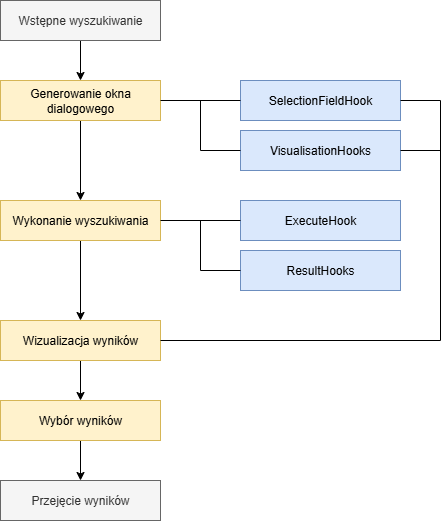
Przebieg wyświetlania okna dialogowego wyszukiwania z możliwościami ingerencji
Wizualizacja jako lista wyboru
W wizualizacji jako lista wyboru należy rozróżnić wybór pojedynczy i wielokrotny. W przypadku wyboru pojedynczego zazwyczaj wyświetlana jest ComboBox w polu. Jest ona podzielona na maksymalnie dwie kolumny. Lewa kolumna zawiera wartości z atrybutu zwracanego, który jest oznaczony jako Identyfikacja. Prawa kolumna zawiera wartości z atrybutu zwracanego, który jest oznaczony jako Nazwa. Jeśli nie podano Nazwy, ta kolumna nie jest wyświetlana. Użytkownik może teraz wybrać żądany rekord danych za pomocą klawiatury lub myszy. ComboBox zamyka się, a wybrany rekord danych zostaje zapisany w danych wykonania.
W przypadku wyboru wielokrotnego, zamiast prostej ComboBox wyświetlane jest okno pop-up z listą i dwoma przyciskami. Na liście można wybrać wiele wartości. Jeśli użytkownik następnie naciśnie przycisk przeznaczony do zatwierdzenia, wybrane rekordy danych zostaną zapisane w danych wykonania, a okno pop-up zostanie zamknięte.
Jeśli w wyszukiwaniu podano ListViewCreator-Hook, zamiast ComboBox zawsze wyświetlane jest okno pop-up z listą.
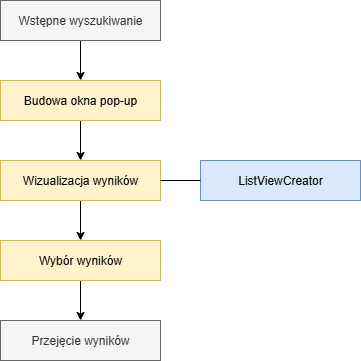
Wyświetlanie okien pop-up z możliwościami ingerencji
Przejęcie wyników
Ostatnim punktem w procesie wyszukiwania jest przejęcie wyników. W tym miejscu deweloper może zmodyfikować wynik wybrany przez użytkownika, nadpisując metodę takeValue w SearchManager.
W grupie wyboru (SelectionGroup) aplikacji pola mogą być oznaczone jako Key lub Key with load. Jeśli pole jest typu Key with load, po wprowadzeniu wartości w polu, aplikacja jest proszona o wyświetlenie tego rekordu danych.
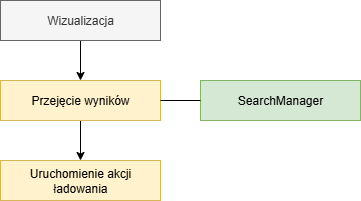
Przejęcie wyników z możliwością ingerencji
Wyszukiwanie standardowe
Szczególnym przypadkiem listy wyboru jest wyszukiwanie standardowe. Dla wyszukiwania standardowego nie istnieją metadane w bazie danych repozytorium. Z definicji wyszukiwanie wyświetla w wynikach tylko dwie kolumny. Zestaw wyników jest predefiniowany przez program. Wyświetlanie zawsze odbywa się na liście wyboru, a zestaw wyników nie jest ograniczony do 60 wierszy. Okno dialogowe nie jest wyświetlane, nawet jeśli jest więcej niż 60 wierszy. Sortowanie rekordów powinno odbywać się za pomocą komparatora specyficznego dla bazy danych, który można pobrać z TransactionManager za pomocą metody getComparator.
Do wyszukiwania standardowego konieczne jest zaimplementowanie klasy pochodnej od DefaultSearchManager. W tej klasie należy nadpisać metodę getResultList. Wewnątrz tej metody lista wyników musi być zbudowana w formie obiektów CisListPartMutable. Dane dla dwóch kolumn wyszukiwania są przechowywane w obiektach CisListPartMutable pod stałymi nazwami DEFAULT_CODE_NAME i DEFAULT_DESCRIPTION_NAME.
class MyDefaultSearchManager extends DefaultSearchManager {
List searchData = …;
public List getResultList(SearchInfo searchInfo) {
List result = new ArrayList();
Iterator iterator = searchData.iterator();
while (iterator.hasNext()){
MyValue value = (MyValue) iterator.next();
CisListPartMutable entry =
new CisListPartMutable();
entry.setObject(
DefaultSearchManager.DEFAULT_CODE_NAME,
value.getName());
entry.setObject(
DefaultSearchManager.DEFAULT_DESCRIPTION_NAME,
value.getExpression());
result.add(entry);
}
return result;
}
}
Dla pola, które ma używać wyszukiwania standardowego, należy zdefiniować nazwę wyszukiwania z określoną wartością i zarejestrować SearchManager.
MyDefaultSearchManager mySearchManager =
new MyDefaultSearchManager();
myFld.setSearchName(DefaultSearchManager.EMPTY_SEARCH_DEFINITION);
myFld.setSearchManager(mySearchManager);
Wyszukiwanie specyficzne dla aplikacji w nagłówku
W nagłówku aplikacji znajduje się zakładka dla wyszukiwań specyficznych dla aplikacji. Zawartość tej zakładki zależy od aktualnej aplikacji. Zakładka może zawierać kilka wyszukiwań, które można wybrać za pomocą pola wyboru.
Widok pojedynczego wyszukiwania odpowiada widokowi dialogowemu, z tą różnicą, że dostępna przestrzeń jest mniejsza. Powoduje to, że nazwy pól znajdują się nad polami, a w szczególnych przypadkach pojedyncze pola mogą zajmować dwie kolumny.
To, które wyszukiwania mają być wyświetlane, jest określane w aplikacji poprzez podanie każdej używanej nazwy wyszukiwania wraz z jej w pełni kwalifikowaną nazwą. Ten wybór wyszukiwań może być ustawiony tylko raz podczas inicjalizacji aplikacji i nie może być później zmieniony.
Dla każdego pojedynczego wyszukiwania atrybuty mogą być jednorazowo wstępnie wypełnione. Ponadto możliwe jest oznaczenie poszczególnych atrybutów w taki sposób, aby wynikowe pola nie były edytowalne lub nie były widoczne. Aby przypisać wartość do atrybutu, należy użyć nazwy atrybutu, która została wprowadzona w wyszukiwaniu. W celu kontrolowania wspomnianych oznaczeń, do atrybutu należy dołączyć stały termin. Wymagane stałe znajdują się w klasie ObjectSearchConstants.
public interface ObjectSearchConstants{
public static final String FIX = „_FIX_PRESET”;
public static final String HIDDEN = „_HIDDEN”;
}
private static final String SEARCHES = new String[] {
„com.cisag.sys…XSearch”,
„com.cisag.sys…YSearch”
};
private void initLocatorSearches() {
CisParameterList[] paramArray = new
CisParameterList[SEARCHES.length];
paramArray[0] = new CisParameterList();
paramArray[0].setString(„userGuid” +
ObjectSearchConstants.HIDDEN,
SelectionSupport.toGuidSelection(env.getUserGuid()));
paramArray[0].setString(„state” +
ObjectSearchConstants.FIX,
SelectionSupport.toShortSelection(State.A));
paramArray[0].setString(„extrastate”,
SelectionSupport.toShortSelection(
new short[]{ExtraState.A, ExtraState.B}));
setSearchNames(SEARCHES, paramArray);
}
Przejmowanie wartości do aplikacji
Wyszukiwanie w obszarze nawigacji umożliwia przejmowanie wartości do aplikacji za pomocą prostego lub podwójnego kliknięcia myszą. Dodatkowo, w niektórych wyszukiwaniach wartość może być użyta za pomocą menu kontekstowego lub metody Drag&Drop.
Aby to zadziałało, w bazie danych repozytorium dla metadanych wyszukiwania musi być zdefiniowany obiekt bazowy, a także musi istnieć powiązanie między jednym lub kilkoma kluczami podstawowymi tego obiektu a kolumnami wynikowymi wyszukiwania. Wartości klucza podstawowego są przekazywane do SelectionGroup aplikacji, co powoduje załadowanie pożądanego obiektu.
Cele operacji Drag&Drop
Operacja Drag&Drop może być użyta w różnych celach. Może być ona skierowana do odpowiedniego EntityField lub do nagłówka aplikacji. Aby można było jej użyć w nagłówku, obiekt bazowy musi być zdefiniowany jako parametr przekazywania dla aplikacji.
Obiekty zależne od czasu
Obiekty zależne od czasu mogą występować w wielu wersjach. Wyszukiwania dają opcję wyświetlania wszystkich wersji lub tylko wersji aktualnej na moment wykonania wyszukiwania.
Ta funkcjonalność jest określana przez przypisanie atrybutu validFrom, który w obiekcie zależnym od czasu należy do klucza podstawowego.
Jeśli użytkownik chce wyświetlić wszystkie wersje obiektu, atrybut validFrom obiektu bazowego musi być powiązany z odpowiednim parametrem w wyszukiwaniu.
Jeśli użytkownik chce wyświetlić tylko aktualną wersję, atrybutowi validFrom nie należy przypisywać żadnego parametru wyszukiwania. W takim przypadku, kernel automatycznie tworzy warunek potrzebny do określenia aktualnej wersji.
SearchManager
Do pola wprowadzania w Comarch ERP Enterprise można przypisać SearchManager. Należy przy tym rozróżnić, że w Comarch ERP Enterprise istnieją dwie warstwy w interfejsie użytkownika, znajdujące się w pakietach com.cisag.pgm.gui oraz com.cisag.pgm.dialog.
Klasy w pakiecie gui zostały zoptymalizowane pod kątem potrzeb rozwoju aplikacji. Klasy tego pakietu bazują na klasach z pakietu dialog. Świadomie jednak uniknięto bezpośredniego dziedziczenia pomiędzy tymi klasami.
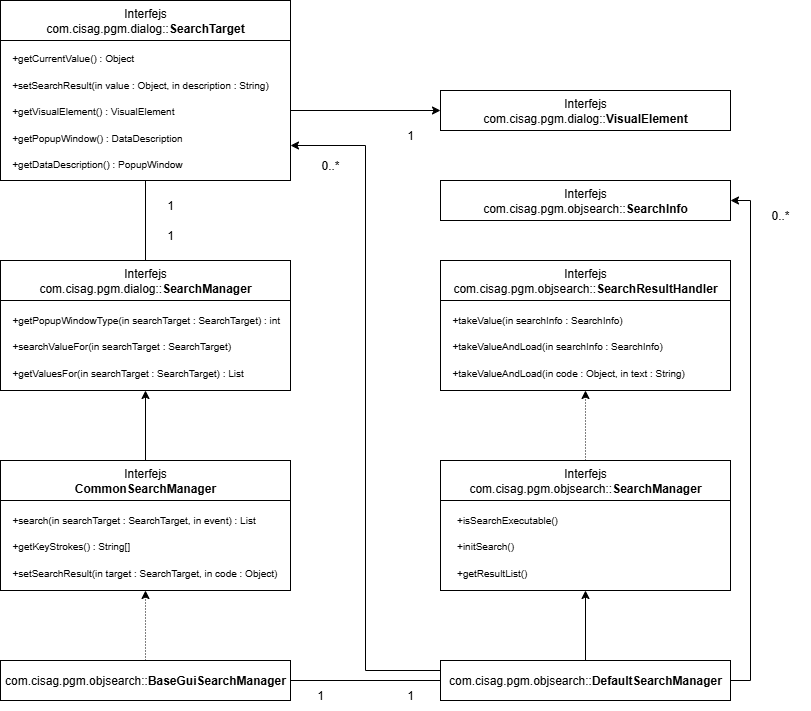
Wyciąg z diagramu klas dla SearchManager
SearchManager w pakiecie com.cisag.pgm.dialog
W pakiecie dialog znajdują się interfejsy SearchManager i CommonSearchManager. Oba ściśle współpracują z SearchTarget, kolejnym interfejsem w tym pakiecie.
Interfejs SearchTarget identyfikuje obiekty, które akceptują wynik lub wyniki zapytania wyszukiwania przekazywanego do SearchManager. Udostępnia on metody wykorzystywane przez SearchManager do zwracania wyników oraz pozyskiwania dodatkowych metadanych i parametrów. Element wizualny (VisualElement), który ma obsługiwać SearchManager — przykładowo pola tekstowe czy tabele — może zaimplementować ten interfejs bezpośrednio albo korzystać z odpowiedniego adaptera.
CommonSearchManager udostępnia metodę, za pomocą której rejestrowane są skróty klawiszowe (KeyStrokes) wywołujące wyszukiwanie dla danego pola. Dodatkowo zawsze używany jest klik myszy na ikonie pomocy wartości.
Metoda search jest wywoływana za każdym razem, gdy naciśnięty zostanie jeden ze skrótów klawiszowych albo gdy kliknięto myszą ikonę pomocy wartości. W ramach metody search decyduje się, czy wyszukiwanie ma zbudować własną wizualizację. Jeśli nie, istnieje możliwość zwrócenia listy obiektów. Obiekty te muszą implementować metodę toString. Zwrócone ciągi znaków są wyświetlane na liście wyboru (ComboBox).
Jeżeli wymagany jest układ dwukolumnowy, wszystkie metody toString muszą zawierać znak tabulatora w łańcuchu. Tekst po lewej stronie tabulatora jest używany jako pierwsza kolumna, a tekst po prawej jako druga kolumna.
Gdy użytkownik wybierze wartość z listy, wywoływana jest metoda setSearchResult. Parametr Code zawiera wybrany obiekt. Jeśli nie został wybrany żaden obiekt, metoda zostaje wywołana z parametrem Code równym null. To wywołanie może zostać wykorzystane do usunięcia z SearchManager obiektów, które nie są już potrzebne.
public interface SearchTarget {
Object getCurrentValue();
void setSearchResult(Object value, String description);
VisualElement getVisualElement();
PopupWindow getPopupWindow();
DataDescription getDataDescription();
}
SearchManager w pakiecie com.cisag.pgm.objsearch
Dla pakietu gui został utworzony własny SearchManager, który znajduje się w pakiecie com.cisag.pgm.objsearch. Ten SearchManager udostępnia kilka metod, które mogą być nadpisywane przez dewelopera, aby w określonych miejscach przebiegu wyszukiwania wprowadzać zmiany.
Sam SearchManager nie implementuje interfejsu SearchManager z pakietu com.cisag.pgm.dialog. Zamiast tego odwołuje się do obiektu, który implementuje SearchManager. SearchManager z pakietu objsearch implementuje dodatkowo interfejs SearchResultHandler.
SearchManager jest zaimplementowany jako klasa abstrakcyjna i zawiera zasadniczo następujące metody:
public boolean isSearchExecutable()
public void initSearch(SearchInfo searchInfo)
public List getResultList(SearchInfo searchInfo)
Metoda isSearchExecutable może być wykorzystana do uwzględnienia warunków, które pozwalają lub uniemożliwiają wykonanie wyszukiwania.
Metoda initSearch może być użyta do ustawienia dodatkowych parametrów wyszukiwania przed jego wykonaniem. Oprócz ustawienia parametrów można odpowiednie pole wstępnie wypełnić lub ustawić jako niewidoczne. Pola wstępnie wypełnione nie mogą być zmieniane podczas wyszukiwania.
public void initSearch(SearchInfo searchInfo) { }
if (partnerField != null) {
if (searchInfo.isSelectionField(„number”)) {
String partnerName = partnerField.getValue();
searchInfo.setParameter(„number”, partnerName);
}
if (searchInfo.isSelectionField(„user”)) {
searchInfo.setParameter(„user”, userName,
SearchInfo.FIX_PRESET);
if (searchInfo.isSelectionField(„type”)) {
searchInfo.setParameter(„type”, types,
SearchInfo.HIDDEN_FIELD);
}
}
}
Metoda getResultList umożliwia wstępne zdefiniowanie wyniku wyszukiwania. W liście wyniki są przechowywane w postaci obiektów CisListPartMutable. Wartości muszą być wprowadzane do odpowiednich obiektów CisListPartMutable za pomocą metody setObject(attrName, attrWert), zgodnie z nazwami zdefiniowanych atrybutów. Obiekty CisListPartMutable są następnie wyświetlane jako wynik wyszukiwania. Jeśli lista zostanie wypełniona, wyszukiwanie w bazie danych nie jest wykonywane.
SearchResultHandler
Interfejs SearchResultHandler służy do przekazania wyniku wyszukiwania, który został zapisany w SearchInfo, dalej do SearchTarget. W tym celu dostępne są trzy metody. Dwie z nich, zawierające dopisek …AndLoad, dodatkowo wywołują akcję Load aplikacji.
public void takeValue(SearchInfo searchInfo)
public void takeValueAndLoad(SearchInfo searchInfo)
public void takeValueAndLoad(Object code, String description)
public void takeValue(SearchInfo searchInfo) {
Object partnerName = searchInfo.getResult(„number”);
if (partnerField!=null && partnerName instanceof String) {
partnerField.setValue((String) partnerName);
}
}
DefaultSearchManager
Standardowe zachowanie wyszukiwań w Comarch ERP Enterprise jest zapisane w klasie com.cisag.pgm.objsearch.DefaultSearchManager. Klasa ta implementuje interfejs com.cisag.pgm.objsearch.SearchManager. DefaultSearchManager przechowuje wewnętrznie mapowanie pomiędzy obiektami SearchTarget i SearchInfo. Programista może utworzyć własną klasę dziedziczącą po tej klasie, aby uzyskać zachowanie wyszukiwania odbiegające od standardowego.
BaseGuiSearchManager
Klasa BaseGuiSearchManager zapewnia połączenie z pakietem com.cisag.pgm.dialog, implementując CommonSearchManager tego pakietu. Zakres zadań tej klasy obejmuje głównie dostęp do obiektu SearchTarget, na którym opiera się wyszukiwanie.
Implementacja własnego SearchManager
Jeśli potrzebny jest własny SearchManager, programista może zdecydować, czy chce użyć klasy pochodnej od DefaultSearchManager, czy też bezpośrednio dziedziczyć po abstrakcyjnej klasie com.cisag.pgm.objsearch.SearchManager. W przypadku dziedziczenia po DefaultSearchManager zachowanie wyszukiwań pozostaje w dużej mierze zachowane. Jeśli natomiast utworzony zostanie całkowicie własny SearchManager, konieczne jest odtworzenie lub samodzielne zaimplementowanie wymaganego zachowania. Zalecane jest dziedziczenie po DefaultSearchManager.
Wyświetlanie wielu widoków lub wyszukiwań w wyszukiwaniu dialogowym
DefaultSearchManager umożliwia wyświetlenie więcej niż jednego wyszukiwania lub widoku w wyszukiwaniu dialogowym. Wybór widoków odbywa się poprzez listę wyboru w pasku narzędzi wyszukiwania dialogowego. Lista ta jest widoczna tylko wtedy, gdy dostępnych jest więcej niż jeden widok. Do rejestrowania widoków w DefaultSearchManager służą metody:
public void initSearchViews()
protected final void addSearchView(SearchView searchView)
protected final void setDefaultSearchView(SearchView searchView)
Aby uzyskać więcej niż jeden widok, należy nadpisać metodę initSearchViews() w klasie DefaultSearchManager. Za pomocą SearchViewFactory można tworzyć SearchViews dla wyszukiwań OQL. Klasa SearchViewFactory zawiera metodę:
public class SearchViewFactory {
static public SearchView createSearchView(
byte[] databaseGuid,
String searchName,
SearchResultHandler resultHandler,
SearchTarget target)
}
Alternatywnie można również zaimplementować własny SearchView, który dziedziczy po abstrakcyjnej klasie SearchView.
Rejestracja SearchView odbywa się poprzez wywołanie metody addSearchView(…) w klasie DefaultSearchManager. Gdy wszystkie widoki zostaną zarejestrowane, za pomocą metody setDefaultSearchView(…) można określić, który SearchView ma zostać wyświetlony użytkownikowi przy otwieraniu wyszukiwania dialogowego. Kolejność rejestracji decyduje również o kolejności widoków na liście wyboru. Jeśli pierwotne wyszukiwanie ma zostać również uwzględnione na liście wyboru, należy w odpowiednim miejscu wywołać metodę initSearchViews(…) w klasie DefaultSearchManager. Przy jej wywołaniu ten SearchView zostaje automatycznie zdefiniowany jako DefaultSearchView. Jeśli jednak ma zostać użyty inny widok jako domyślny, trzeba go ustawić tak, jak opisano wcześniej.
public class MySearchManager extends DefaultSearchManager {
public void initSearchViews() {
SearchView searchView =
SearchViewFactory.createSearchView(
getDatabaseGuid(),
„com.cisag.app.general.MySearchName”,
this,
getSearchTarget());
addSearchView(searchView);
super.initSearchViews();
setDefaultSearchView(searchView);
}
}
SearchViews i lista wyboru
Do wyszukiwania wstępnego używany jest DefaultSearchView. Jeśli DefaultSearchView nie opiera się na wyszukiwaniu standardowym, wówczas do wyszukiwań wstępnych używany jest pierwszy SearchView, który opiera się na wyszukiwaniu standardowym. Jeżeli wyszukiwanie wstępne nie przynosi żadnych wyników, otwierane jest wyszukiwanie dialogowe, a użytkownikowi prezentowany jest widok DefaultSearchView.
SearchIterator
SearchIterator jest używany wyłącznie wewnętrznie podczas wyszukiwania. Do dostępu do bazy danych z użyciem iteratora należy więc korzystać z klasy com.cisag.pgm.util.ResultSetAdapter. Alternatywnie zamiast iteratora można zastosować CisOqlSearchStatement. Wynikiem wyszukiwania jest w tym przypadku CisResultSet.
Pola cech wyszukiwania
Do wyszukiwań dostępne są specjalne pola cech wyszukiwania. Znajdują się one w pakiecie com.cisag.pgm.gui. Pola te charakteryzują się tym, że przy etykiecie posiadają przycisk, za pomocą którego można wyświetlić listę. Lista ta zawiera możliwe wzorce wprowadzania w postaci krótkich wyrażeń, np. zaczyna się od ABC. Jeżeli zostanie wybrany jeden z wpisów z listy, wzorzec ten jest przenoszony do pola i może zostać dostosowany przez użytkownika. W podanym przykładzie do pola zostanie wpisane ABC*. W wygenerowanych wyszukiwaniach pola cech wyszukiwania są używane automatycznie.
Dostępne są następujące pola cech wyszukiwania:
| Pole cechy wyszukiwania | Typ danych |
| TextSelectionField | Ciągi znaków |
| DecimalSelectionField | Liczby naturalne i rzeczywiste |
| AbstractCisQuantitySelectionField | Liczby naturalne i rzeczywiste z jednostką |
| CisDateSelectionField | Data i czas |
Od abstrakcyjnej klasy AbstractCisQuantitySelectionField istnieją szczególne warianty dla wartości specjalnych:
| Pole cechy wyszukiwania | Typ danych |
| QuantitySelectionField | Ilości |
| DurationSelectionField | Czas trwania |
| ForeignAmountSelectionField | Waluty obce |
| DomesticAmountSelectionField | Data i czas |
Pola cech wyszukiwania te znajdują się w pakiecie com.cisag.app.general.gui.
Możliwości wprowadzania w polach cech wyszukiwania
Do pola cechy wyszukiwania użytkownik może wprowadzić jedną lub więcej cech wyszukiwania. Comarch ERP Enterprise obsługuje przy tym następującą gramatykę:
Selection = [CaseSensitiv | CaseInsensitiv] [OrList];
OrList = Parameter {ParameterSeparator Parameter};
Parameter = Range | SingleOperator;
ParameterSeparator = „, „;
Range = LowerRange | UpperRange | FullRange;
LowerRange = „- ” UpperValue;
UpperRange = LowerValue ” -„;
FullRange = LowerValue ” – ” UpperValue;
SingleOperator = [Operator] Value;
Operator = „<” | „>” | „!=”;
CaseSensitiv = „=”;
CaseInsensitiv = „~”;
Value = ? Alle Zeichenfolgen die nicht „, ” oder ” – ” enthalten ?;
UpperValue = ? Alle Zeichenfolgen die nicht „, ” enthalten ?;
LowerValue = ? Alle Zeichenfolgen die nicht „, ” oder ” – ”
enthalten ?;
Wartości dla Value, UpperValue i LowerValue zależą od typu danych. W przypadku cech wyszukiwania dla liczb dozwolone są np. tylko liczby, separator tysięcy oraz separator dziesiętny. W przypadku cech wyszukiwania dla czasu i daty nie są obsługiwane Operator, CaseSensitiv oraz CaseInsentiv. Natomiast oceniane są wartości Value, UpperValue i LowerValue. Opis możliwości dla czasu i daty nie jest częścią niniejszego artykułu.
Hooki
W Comarch ERP Enterprise dostępnych jest kilka hooków, które pozwalają wpływać na przebieg wyszukiwania. W obiektach deweloperskich do wyszukiwania OQL można przypisać klasę Javy jako hook. Klasa ta musi dziedziczyć po abstrakcyjnej klasie com.cisag.pgm.objsearch.SearchHook. Zawarte w niej hooki można podzielić na pięć grup:
| Grupa hooków | Krótki opis |
| SearchIteratorHook | Wymiana SearchIteratora |
| SelectionFieldHook | Wymiana i manipulacja polami cech wyszukiwania |
| ExecuteHook | Manipulacja i rozszerzanie zapytania OQL przed jego wykonaniem |
| ResultHook | Manipulacja listą wyników |
| VisualisationHook | Użycie własnej wizualizacji do prezentacji wyników |
Niektóre grupy hooków są dalej podzielone. Zawarte w nich hooki mogą być czasami używane w kombinacji, a czasami wyłącznie samodzielnie. Szczegółowe informacje znajdują się w dalszej części dokumentacji opisującej poszczególne hooki.
Alternatywnie, zamiast użycia abstrakcyjnej klasy SearchHook, hook może być zaimplementowany na bazie interfejsów. Jednak interfejsy te zostały oznaczone jako deprecated w Comarch ERP Enterprise 4.3. Hooki oparte na interfejsach powinny zostać w odpowiednim momencie przeniesione na abstrakcyjną klasę.
SearchHook
Aby móc używać hooka z klasy com.cisag.pgm.objsearch.SearchHook, należy z jednej strony zaimplementować odpowiednie metody hooka, a z drugiej strony aktywować go. Aktywacja hooka odbywa się w konstruktorze klasy dziedziczącej poprzez wywołanie następującego konstruktora w klasie SearchHook:
Konstruktor zawiera dwa parametry do ustawiania typów hooków. Możliwe jest zarówno aktywowanie, jak i dezaktywowanie hooków. Dezaktywacja hooków ma znaczenie w przypadku dziedziczenia po już zaimplementowanym hooku, np. aby wymusić inną wizualizację.
Dostępne typy hooków zostały zdefiniowane jako stałe w wewnętrznej klasie HookType:
public static final class HookType {
public static final int SEARCH_ITERATOR = …;
public static final int SELECTION_FIELD = …;
public static final int EXECUTE = …;
public static final int RESULT_CHANGE_CONTENT = …;
public static final int RESULT_FILTER = …;
public static final int VISUALISATION_LIST = …;
public static final int VISUALISATION_TABLE = …;
public static final int VISUALISATION_COLUMN = …;
}
Dla konstruktorów należy stosować następujący wzorzec:
public class MySearchHook extends SearchHook {
public MySearchHook() {
this(0, 0);
}
protected MySearchHook(int activeHookType,
int inactiveHookTypes){
super(HookType.SELECTION_FIELD |
HookType.VISUALISATION_COLUMN | activeHookType,
inactiveHookType);
}
…
}
Każdy SearchHook musi posiadać konstruktor bezparametrowy. Konstruktor ten wywoływany jest przy tworzeniu klasy z wyszukiwania. Standardowa implementacja tego konstruktora zawsze wywołuje this(0, 0). Konstruktor z dwoma wartościami typu int wywołuje z kolei konstruktor klasy nadrzędnej, przekazując mu te wartości. Każda z wartości może być rozszerzona o wymagane typy hooków, które łączy się operatorem I. W poprzednim przykładzie aktywowano SelectionFieldHook oraz VisualisationColumnHook.
Jeżeli hook ma być podstawą dla innego hooka, można po nim dziedziczyć. Jeśli w takim przypadku potrzebny jest inny hook wizualizacji, należy dezaktywować hook wizualizacji klasy nadrzędnej i aktywować nowy hook wizualizacji. Hook SelectionFieldHook klasy nadrzędnej pozostaje przy tym aktywny.
public class AdaptedSearchHook extends MySearchHook {
public AdaptedSearchHook () {
this(0, 0);
}
protected AdaptedSearchHook(int activeHookType,
int inactiveHookTypes){
super(HookType.VISUALISATION_LIST | activeHookType,
HookType.VISUALISATION_COLUMN | inactiveHookType);
}
…
}
SearchIteratorHook
HookType: SEARCH_ITERATOR
public SearchIterator createSearchIterator(SearchInfo searchInfo)
Za pomocą tego hooka można wymienić SearchIterator. Przykładem zastosowania może być dostęp do systemu plików zamiast do bazy danych.
SelectionFieldHook
HookType: SELECTION_FIELD
public Field manipulateSelectionFieldBefore(String name, Field field)
public void manipulateSelectionFieldAfter(String name, Field field)
W wyszukiwaniu dialogowym i w wyszukiwaniu w nagłówku do wprowadzania cech wyszukiwania używane są pola wejściowe. Zwykle wyświetlane pola wybierane są automatycznie w zależności od typu. Na przykład dla Valueset tworzone jest ValueSetField.
Jeżeli do wprowadzania cech wyszukiwania potrzebne są specjalne pola, za pomocą tego hooka można manipulować lub wymieniać używane pola. W Comarch ERP Enterprise podczas budowania interfejsu rozróżnia się dwa momenty. Niektóre ustawienia można przypisać do pola tylko przed dodaniem go do interfejsu, inne dopiero po dodaniu. Dlatego dostępne są dwie metody.
Metoda manipulateSelectionFieldBefore umożliwia wymianę pola lub modyfikację pola proponowanego. Metoda manipulateSelectionFieldAfter pozwala zmienić właściwości istniejącego pola.
Każda metoda przyjmuje dwa parametry: nazwę parametru (taką, jaką w metadanych wyszukiwania OQL zapisano przy danym atrybucie w pozycji Name) oraz pole używane przez wyszukiwanie. Na podstawie nazwy można zdecydować, czy należy zmienić przekazane pole.
public Field manipulateSelectionFieldBefore(String name,
Field field) {
if (name.equals(„definition”)) {
field = new MySpecialField(Guid.toHexString(
WebInterface.getInstanceGuid(field)),
field.getOriginalPath(),…);
field.setSelectionMode(true);
}
return field;
}
public void manipulateSelectionFieldAfter(String name,
Field field) {
if (name.equals(„definition”)) {
field.setSearchManager(null);
}
}
Jeżeli pole zostaje zastąpione, należy pamiętać, aby było ono używane w trybie SelectionMode, ponieważ w ramach wyszukiwań wywoływana jest wyłącznie metoda getSelectionString dla danego pola. Metoda getValue nie jest brana pod uwagę. Ponadto do utworzenia nowego pola należy użyć GUID i ścieżki pierwotnego pola.
SimpleEntityFields i GuidSelection
W Comarch ERP Enterprise ze względów technicznych nie można tworzyć relacji między różnymi bazami danych. Jeśli mimo to użytkownik chce odwołać się do rekordu w innej bazie danych, można w tabeli zapisać jedynie klucz do tego rekordu. Informacji o celu referencji nie da się odzwierciedlić przy użyciu środków Comarch ERP Enterprise. Dopiero w kodzie źródłowym programisty ta informacja jest zawarta.
Wyszukiwania OQL również nie mogą być wykonywane pomiędzy bazami danych. Programista nie ma też możliwości zmodyfikowania w kodzie źródłowym wygenerowanych wyszukiwań w taki sposób, aby wyniki były ustalane ponad bazami danych.
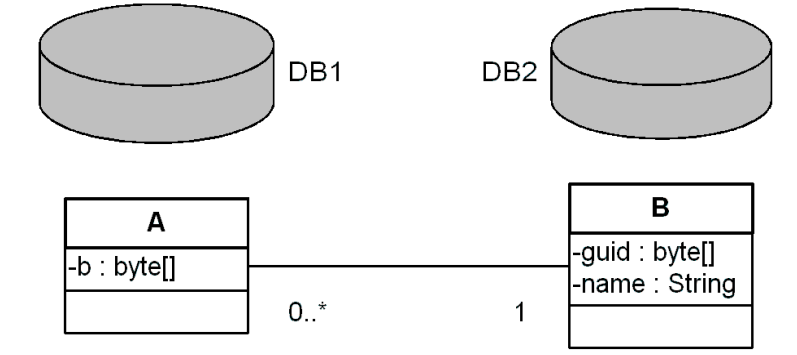
Jeżeli zostanie wykonane zapytanie OQL na tabeli A w bazie DB1, nie ma możliwości odwołania się do atrybutów, np. name, tabeli B w bazie DB2. Jedyną informacją, jaką obiekt A posiada o obiekcie B, jest klucz obiektu B w postaci tablicy bajtów. Informacja o tym, że klucz odnosi się do obiektu w tabeli B, nie może zostać odwzorowana w postaci relacji pomiędzy A i B.
Aby można było wykonać zapytanie na tabeli A, użytkownik musiałby w jakiś sposób znać i wprowadzić GUID-y obiektów B używanych jako ograniczenia, co nie jest dla niego praktyczne. Użytkownik powinien raczej wprowadzać dane w formie czytelnej dla człowieka, takie jak atrybut name w tabeli B. Tego typu atrybuty nie są jednak dostępne przy zapytaniu na tabeli A.
Dlatego użytkownikowi trzeba dać możliwość uzyskania GUID-ów z tabeli B. Rozwiązanie tego problemu polega na kompromisie. Pole typu SimpleEntityField pozwala użytkownikowi wprowadzić tekst, który jako klucz biznesowy jednoznacznie identyfikuje obiekt w tabeli. Oprócz tego klucza biznesowego zazwyczaj istnieje też techniczny klucz w postaci GUID. SimpleEntityFields mapują wprowadzoną przez użytkownika wartość na GUID, który można pobrać dla pola metodą getGuid().
Wyszukiwania OQL w Comarch ERP Enterprise pozwalają dzięki SelectionFieldHook na podmianę pól wejściowych. Zamiast automatycznie utworzonego pola można wtedy zastosować SimpleEntityField. Pole SimpleEntityField musi być odpowiednio ustawione do tego specjalnego zastosowania, aby przy wywołaniu metody getSelectionString został zwrócony właściwy wynik, czyli GUID. W tym celu należy wyłączyć SelectionMode, a włączyć GuidSelectionMode.
public Field manipulateSelectionFieldBefore(String name,
Field field ) {
if (name.equals(„definition”)) {
SimpleEntityField result = new MySimpleEntityField(…);
result.setSelectionMode(false);
result.setGuidSelectionMode(true);
field = result;
}
return field;
}
Kompromis polega na tym, że dla wyszukiwania można użyć jako ograniczającego parametru maksymalnie jednego obiektu z tabeli B. Nie ma możliwości użycia kilku obiektów B jednocześnie.
Za pomocą tej funkcji można również rozwiązać inny problem.
ExecuteHook
HookType: EXECUTE
public String prepareExecute(CisOqlSearchStatement stmt)
ExecuteHook umożliwia wpływanie na sposób łączenia cech wyszukiwania oraz uwzględnianie dodatkowych parametrów i cech podczas wyszukiwania. Jeśli w polu wejściowym zostanie wprowadzonych kilka cech wyszukiwania, w zapytaniu są one łączone operatorem OR.
A=1 OR A LIKE ‘a’ OR A LIKE ‘*b’
Cechy wyszukiwania z kilku pól są natomiast łączone operatorem AND.
(A=1 OR A=2) AND B=3 AND (C LIKE ‘a*’ OR C LIKE ‘b*’)
Czasami jednak pożądane jest, aby niektóre pola wejściowe były połączone operatorem OR, a także aby uwzględnić dodatkowe parametry, np. do sprawdzania uprawnień.
((A=1 OR A=2) OR B=3) AND (C LIKE ‘a*’ OR C LIKE ‘b*’)
Aby uzyskać takie zachowanie, metodzie execute klasy CisOqlSearchStatement można przekazać dodatkowy warunek w postaci łańcucha znaków. Warunek ten może zawierać zarówno dodatkowe, jak i znane już parametry powiązane w OQL. Warunek jest analizowany przez statement – wszystkie parametry w nim znalezione nie są już później ponownie uwzględniane. Pozostałe parametry są łączone standardowo za pomocą operatora AND.
Dzięki ExecuteHook programista uzyskuje dostęp do statementu. W metodzie prepareExecute można zbudować dodatkowy warunek i zwrócić go jako wynik metody. Wartości dodatkowych parametrów muszą zostać ustawione na statement.
public String prepareExecute(CisOqlSearchStatement stmt) {
if (!Logic.getInstance().isAllowedDisplayOthersObjects()){
String condition =
„ac:updateInfo.createUser={userGuid} OR EXISTS ”
+ „(SELECT w:guid FROM com.cisag….obj.XYZ w ”
+ „WHERE w:userGuid={userGuid})”;
CisEnvironment env = CisEnvironment.getInstance();
stmt.setGuid(„userGuid”, env.getUserGuid());
return condition;
} else {
return „”;
}
}
ResultHooks
Za pomocą ResultHooks można manipulować wynikiem wyszukiwania. Manipulacja ta odbywa się w momencie, gdy wynik nie został jeszcze zwizualizowany. ResultHook dzieli się na ResultChangeContentHook, służący do modyfikacji treści wyniku wyszukiwania, oraz ResultFilterHook, służący do zmiany zbioru wyników. Oba hooki mogą być ze sobą łączone, przy czym w kolejności wywołań ResultFilterHook jest wykonywany przed ResultChangeContentHook.
ResultChangeContentHook
HookType: RESULT_CHANGE_CONTENT
public void changeContentInResultList(java.util.List list)
Za pomocą ResultChangeContentHook można manipulować zawartością rekordu. Nie można jednak usuwać ani dodawać rekordów do wyniku. Przekazana lista zawiera maksymalnie sześćdziesiąt obiektów CisListPartMutable. Sama lista jest listą niemodyfikowalną, więc zmiana jej rozmiaru, np. poprzez usuwanie elementów, spowoduje wyjątek.
Ponieważ wielkość wyniku nie ulega zmianie, hook ten może być stosowany bez zakłócania funkcji liczenia rekordów w wyszukiwaniu dialogowym. Każdy CisListPartMutable w liście reprezentuje jeden rekord. Dostęp do poszczególnych kolumn wyniku odbywa się poprzez nazwę atrybutu, tak jak została zdefiniowana w metadanych wyszukiwania. Wszystkie typy prymitywne (np. double, short) są w CisListPartMutable odwzorowane przez swoje klasy opakowujące (Double, Short). Część specjalna jest zawsze przechowywana w CisListPartMutable jako Specialpart, nawet jeśli w bazie danych posiada wiele atrybutów.
public void changeContentInResultList(List list) {
Iterator iterator = list.iterator();
CisListPartMutable row;
while (iterator.hasNext()) {
row = (CisListPartMutable) iterator.next();
code = (String) row.getObject(„code”);
description = (String) row.getObject(„desc”);
row.setObject(„xyz”, code + „-” + description);
}
}
ResultFilterHook
HookType: RESULT_FILTER
public List filterResultList(java.util.List list)
Za pomocą ResultFilterHook można filtrować wynik wyszukiwania. Można przy tym zarówno usuwać, jak i dodawać rekordy. Przekazana lista zawiera maksymalnie sześćdziesiąt obiektów CisListPartMutable. Analogicznie jak w przypadku ResultChangeContentHook każdy obiekt CisListPartMutable reprezentuje rekord, a dostęp do kolumn odbywa się w taki sam sposób. Lista zwrócona przez hook może być listą przekazaną lub nowo utworzoną.
ResultFilterHook powinien być stosowany tylko wtedy, gdy zmieniana jest liczność wyniku, ponieważ w takim przypadku w wyszukiwaniach musi zostać wyłączona funkcja liczenia rekordów. Wynika to z faktu, że liczenie rekordów odbywa się na poziomie bazy danych. Jeśli zbiór wyników zostanie później zmodyfikowany, wynik zliczania nie będzie się zgadzał z faktyczną liczbą rekordów. Aby uzyskać poprawny wynik zliczania, hook musiałby być uruchamiany dla wszystkich rekordów, co ze względu na wydajność i wykorzystanie zasobów nie jest uzasadnione.
public List filterResultList(List list) { case TYPE_C:
for (Iterator i = list.iterator(); i.hasNext();) {
CisListPartMutable row = (CisListPartMutable) i.next();
Short type = (Short) row.getObject(„type”);
switch (type.shortValue()) {
case TYPE_A:
case TYPE_B:
i.remove();
break;
case TYPE_D:
row.setObject(„type”,
CisNumberFactory.getShort(TYPE_A));
break;
}
}
return list;
}
VisualisationHooks
W Comarch ERP Enterprise do wizualizacji wyników wyszukiwania standardowo używane jest Grid-Control. Grid-Control zastępuje listę i tabelę. Łączy w sobie właściwości tabeli i listy, a ponadto oferuje dodatkowe możliwości prezentacji. W Grid-Control można na przykład przesuwać kolumny, zmieniać ich szerokość i układać je w wielu wierszach. Można też usuwać kolumny z widoku i przywracać je w późniejszym czasie. Kolumny oznaczone w modelu danych jako sortowalne mogą być dodawane do sortowania poprzez kliknięcie w nagłówek kolumny.
Używane kolumny są określane na podstawie metadanych wyszukiwania OQL. W zależności od typu danych dobierane są odpowiednie pola do wyświetlenia i ustawiane w Grid-Control.
Jeśli ogólna wizualizacja nie spełnia wymagań, można za pomocą VisualisationHooks manipulować sposobem prezentacji albo całkowicie go wymienić. Do tego zadania dostępne są trzy hooki. Specjalnie dla wizualizacji opartej na Grid-Control istnieje VisualisationColumnHook, który pozwala na manipulowanie poszczególnymi kolumnami. Jeśli wizualizacja ma być przedstawiona w postaci listy, można użyć VisualisationListHook. VisualisationTableHook wraz z wprowadzeniem VisualisationColumnHook praktycznie utracił znaczenie i służy jedynie do wypełniania Grid-Control danymi w formie tabeli.
Hooki wizualizacji nie mogą być ze sobą łączone. Można aktywować tylko jeden z nich.
VisualisationColumnHook
HookType: VISUALISATION_COLUMN
public static abstract class ColumnModel {
public abstract short getVisualisationTarget();
public abstract Column getColumn(String name);
public abstract Column createColumn(String name, String guid,
String displayFieldPath);
public abstract boolean isColumnDefinied(String name);
public abstract java.util.List getColumnNames();
}
public static abstract class Column {
public static final int GENERIC_FIELD = 1;
public static final int SPECIAL_FIELD = 2;
public abstract short getVisualisationTarget();
public abstract String getName();
public abstract String getGuid();
public abstract String getDisplayFieldPath();
public abstract void setDisplayFieldPath(
String displayFieldPath);
public abstract void setDisplayType(int displayType);
public abstract int getDisplayType();
public abstract void setDeleted(boolean state);
public abstract boolean isDeleted();
public abstract Field getDisplayField();
}
public void manipulateColumnModel(ColumnModel model)
public Field createDisplayField(Column column)
public void manipulateDisplayField(Column column)
public void setDisplayFieldValue(Column column,
CisListPartMutable data)
VisualisationColumnHook służy do ukierunkowanej manipulacji kolumnami w wizualizacji wyników. Hook składa się z czterech metod i dwóch klas wewnętrznych. Klasy wewnętrzne opisują model danych używany do manipulacji. Podstawową klasą jest ColumnModel. Posiada ona dla każdej kolumny instancję klasy Column.
Obiekt Column ma nazwę unikalną w ramach wyszukiwania. Jako nazwa używany jest atrybut z metadanych wyszukiwania OQL. Dostęp do kolumny w ColumnModel odbywa się przez metodę ColumnModel#getColumn(String name).
Aby manipulować modelem kolumn, należy zaimplementować metodę manipulateColumnModel(ColumnModel model). Otrzymuje ona jako parametr model kolumn, który został utworzony na podstawie metadanych wyszukiwania OQL. Model ten zawiera jedynie kolumny, które w metadanych mają przypisaną pozycję wyświetlania.
Metody createDisplayField(…), manipulateDisplayField(…) i setDisplayFieldValue(…) trzeba implementować tylko wtedy, gdy zamiast automatycznie generowanych pól do prezentacji wartości w kolumnie ma zostać użyte inne pole.
Połączenie między danymi, kolumnami i możliwością sortowania opiera się na nazwie atrybutu w wyszukiwaniu OQL. Każdy wiersz wyniku jest enkapsulowany w CisListPartMutable. W jego ramach dostęp do konkretnej wartości odbywa się przez nazwę atrybutu. CisListPartMutable zawiera wszystkie atrybuty, które mają przypisaną pozycję zwracaną, czyli może zawierać więcej atrybutów niż tych z przypisaną pozycją wyświetlania. Na podstawie logicznego typu danych atrybutu, który używany jest w wyświetlaniu, określany jest typ prymitywny wartości. Na tej podstawie dobierane jest pole do prezentacji. Wartość jest rzutowana na odpowiedni typ danych i przypisywana do pola poprzez odpowiednią metodę. Wiedzę tę można wykorzystać, jeśli chce się w wynikach wyszukiwania wyświetlać dodatkowe kolumny.
Zasadniczo manipulacje na kolumnach powinny być wykonywane tylko wtedy, gdy ogólna prezentacja nie jest wystarczająca. Dotyczy to na przykład sytuacji, gdy do prezentacji potrzebne są ikony lub EntityFields. Przy nowych kolumnach należy sprawdzić, czy zachowanie domyślne jest wystarczające. W takim przypadku wystarczy zadbać, aby CisListPartMutable miał przypisaną wartość do nazwy kolumny z odpowiednim typem danych. Można to osiągnąć np. poprzez użycie ResultChangeContentHook i przypisanie wartości do nazwy kolumny.
W dalszej części na podstawie konkretnych zadań pokazane są możliwe implementacje.
Wykluczenie kolumny z wyświetlania
Aby wykluczyć kolumnę z wyświetlania, należy oznaczyć ją jako usuniętą. W Grid-Control można ukrywać kolumny i użytkownik może je później ponownie dodać. Kolumna oznaczona jako usunięta nie zostanie jednak dodana do Grid-Control i nie może być przez użytkownika przywrócona.
public void manipulateColumnModel(ColumnModel model) {
model.getColumn(„name”).setDeleted(true);
}
Wyświetlanie dodatkowej kolumny
Dodatkową kolumnę można dodać do modelu za pomocą metody createColumn(…). Nazwa użytej kolumny może, ale nie musi, być znana w wyszukiwaniu jako atrybut. Wymagane są zawsze GUID oraz logiczny typ danych. Na ich podstawie w przypadku ogólnym budowane jest pole, które zostanie wykorzystane do prezentacji danych.
public void manipulateColumnModel(ColumnModel model) {
model.createColumn(„name”,
„0000541C2E541D1082DD846464090000”,
„com.cisag.app.general.ui:PartnerName.lt”);
}
Dla pozyskiwania danych istnieją trzy warianty:
- w wyszukiwaniu OQL istnieje atrybut o tej samej nazwie, który ma przypisaną pozycję zwracania,
- w wyszukiwaniu OQL istnieje atrybut o tej samej nazwie, który nie ma przypisanej pozycji zwracania,
- w wyszukiwaniu OQL nie istnieje atrybut o podanej nazwie.
W pierwszym przypadku w CisListPartMutable znajduje się już atrybut z wartością potrzebną do wyświetlenia. W dwóch pozostałych przypadkach należy za pomocą ResultChangeContentHook podstawić wartość dla atrybutu. Jeżeli atrybut w wyszukiwaniu jest oznaczony jako sortowalny, trzeba upewnić się, że wyświetlane wartości pasują do sortowania. Oznacza to, że gdy użytkownik kliknie nagłówek kolumny, dane będą pobierane z bazy w nowej kolejności. Jeśli w polu zamiast wartości użytych do sortowania zostaną wyświetlone inne, może wystąpić niespójność między wartościami a kolejnością sortowania.
Zastąpienie pola do wyświetlania
Jak już wspomniano, pola do wyświetlania należy zastępować tylko wtedy, gdy automatycznie tworzone pola nie spełniają wymagań. Zwykle ma to miejsce przy prezentacji ValueSets jako ikony lub gdy wymagane jest EntityField. W takich przypadkach można dla kolumny ustawić odpowiednią flagę.
public void manipulateColumnModel(ColumnModel model) {
model.getColumn(„name”).setDisplayType(Column.SPECIAL_FIELD);
}
Po ustawieniu flagi należy zaimplementować metody createDisplayField(…), manipulateDisplayField(…) i setDisplayFieldValue(…) dla odpowiedniej kolumny. Metody te wywoływane są wyłącznie dla kolumn, dla których ustawiono flagę Column.SPECIAL_FIELD.
Podobnie jak w przypadku cech wyszukiwania, istnieją dwie metody do tworzenia i manipulacji polem wyświetlania. Metoda createDisplayField(…) tworzy pole wyświetlania. Należy przy tym możliwie wykorzystać GUID i ścieżkę z obiektu Column. Metoda manipulateDisplayField(…) jest wywoływana po dodaniu wygenerowanego pola do Grid-Control. Tutaj można wprowadzić zmiany w polu, które możliwe są dopiero po dodaniu go do interfejsu.
public Field createDisplayField(Column column) {
if (column.getName().equals(„name”)) {
return new MySpecialField(column.getGuid(),
column.getDisplayPath());
}
}
public void manipulateDisplayField(Column column) {
if (column.getName().equals(„name”)) {
MySpecialField field = (MySpecialField)
column.getDisplayField();
field.set…;
}
}
Po utworzeniu pola należy zaimplementować przypisywanie wartości do tego pola. Metoda setDisplayFieldValue(…) otrzymuje oprócz obiektu Column, zawierającego wygenerowane pole, także CisListPartMutable dla bieżącego wiersza. Dane potrzebne do wypełnienia pola można pobrać z dowolnych wpisów w wierszu. Można to wykorzystać np. do wypełniania wielowarstwowego IconField na podstawie kilku statusów.
public void setDisplayFieldValue(Column column,
CisListPartMutable part) {
if (column.getName().equals(„name”)) {
MySpecialField field = (MySpecialField)
column.getDisplayField();
String value1 = (String) part.getObject(„value1”);
String value2 = (String) part.getObject(„value2”);
…
field.setValue(value1, value2,…);
}
}
VisualisationListHook
HookType: VISUALISATION_LIST
public void initList(List list, short type)
public ListView createView(short type)
public static final class VisualisationTarget {
public static final short DIALOG = …;
public static final short LOCATOR = …;
}
Jeśli standardowe rozwiązanie nie wystarcza do prezentacji wyników, można utworzyć własną listę. Metoda createView tworzy w zależności od przekazanego typu obiekt ListView. Jako możliwe wartości przekazywane są VisualisationTarget.DIALOG albo VisualisationTarget.LOCATOR. Dzięki temu wygląd prezentacji może zostać dostosowany do miejsca użycia. W nawigatorze aplikacyjnym (LOCATOR) dostępna szerokość jest mniejsza niż w oknie dialogowym (DIALOG).
Metoda initList umożliwia ustawienie nazw i szerokości kolumn. Podobnie jak w metodzie createView wygląd może być dostosowany w zależności od wartości VisualisationTarget.
VisualisationTableHook
HookType: VISUALISATION_TABLE
public void initTable(Table table, short type)
public void dataToTable(CisListPartMutable data, short type)
public static final class VisualisationTarget {
public static final short DIALOG = …;
public static final short LOCATOR = …;
}
Jeśli standardowe rozwiązanie nie wystarcza do prezentacji wyników, można utworzyć własną tabelę. Metoda initTable umożliwia ustawienie nazw i szerokości kolumn.
Podobnie jak w przypadku prezentacji listy, za pomocą parametru type określa się przeznaczenie tabeli. Jako możliwa wartość przekazywana jest jedna z dwóch stałych z klasy wewnętrznej VisualisationTarget.
Metoda dataToTable umieszcza dane w poszczególnych polach tabeli.
public void dataToTable(CisListPartMutable part, short type) {
switch(type) {
case (VisualisationTarget.DIALOG):
….
break;
case (VisualisationTarget.LOCATOR):
….
break;
}
}
Przestawienie InterfaceHooks na abstrakcyjną klasę SearchHook
W Comarch ERP Enterprise 4.3 interfejsy InterfaceHooks zostały oznaczone jako przestarzałe (deprecated). Działają one nadal bez ograniczeń także od wersji 4.3, jednak zaleca się, aby wyszukiwania zostały przeniesione na abstrakcyjną klasę SearchHook, szczególnie w celu pełnego wykorzystania możliwości Grid-Control. Przestawienie na abstrakcyjną klasę SearchHook jest na ogół bezproblemowe. Ważne jest jednak, aby oprócz implementacji metod hook został zarejestrowany w konstruktorze.
Poniżej znajduje się tabela z krótkim zestawieniem, który InterfaceHook należy przekształcić na który HookType klasy SearchHook:
| InterfaceHook | SearchHook.HookType |
| CisObjectSearchIteratorCreator | SearchIteratorHook |
| SearchIteratorCreatorHook | SearchIteratorHook |
| CisObjectSearchFieldManipulation | SelectionFieldHook |
| CisObjectSearchExecuteHook | ExecuteHook |
| SearchResultManipulation |
|
| ResultListHook (SearchListManager, ListViewCreator) |
|
| SearchTableManager (TableDataManager) |
|
CisObjectSearchIteratorCreator i SearchIteratorCreatorHook
CisObjectSearchIteratorCreator jest już od Comarch ERP Enterprise 4 oznaczony jako przestarzały i powinien być, jeśli to możliwe, zastąpiony przez SearchIteratorCreatorHook. Zamiast SearchIteratorCreatorHook należy teraz stosować SearchIteratorHook. Nazwa metody pozostaje taka sama, a sposób działania nie został zmieniony.
public SearchIterator createSearchIterator(SearchInfo searchInfo)
CisObjectSearchFieldManipulation
Zamiast hooka CisObjectSearchFieldManipulation należy stosować SelectionFieldHook. Do przestawienia wystarczy dostosować nazwy metod, ponieważ sposób działania nie został zmieniony.
Dwie metody hooka CisObjectSearchFieldManipulation:
public Field manipulateFieldBefore(String name, Field field)
public void manipulateFieldAfter(String name, Field field)
Dwie metody hooka SelectionFieldHook:
public Field manipulateSelectionFieldBefore(String name,
Field field)
public void manipulateSelectionFieldAfter(String name, Field field)
CisObjectSearchExecuteHook
Zamiast CisObjectSearchExecuteHook należy stosować ExecuteHook. Nazwa metody pozostaje taka sama, a sposób działania nie został zmieniony.
public String prepareExecute(CisOqlSearchStatement stmt)
SearchResultManipulation
Zamiast hooka SearchResultManipulation należy stosować jeden z dwóch ResultHooks: ResultChangeContentHook lub ResultFilterHook.
Hook SearchResultManipulation posiada następującą sygnaturę metody:
public List getManipulatedList(List list)
Jeśli ma zostać zmieniona liczba rekordów, należy zastosować ResultFilterHook. Implementacja metody może pozostać bez zmian:
public java.util.List filterResultList(java.util.List list)
Jeśli manipulowany ma być jedynie zawartość rekordów, należy użyć ResultChangeContentHook. W tym hooku przekazywana jest niemodyfikowalna lista, dlatego w implementacji trzeba wprowadzić odpowiednie dostosowania:
public void changeContentInResultList(java.util.List list)
ResultListHook (SearchListManager, ListViewCreator)
Do prezentacji wyników w formie listy istnieje kilka interfejsów. Podstawą jest ListViewCreator, na którym bazują ResultListHook oraz SearchListManager. SearchListManager został od Comarch ERP Enterprise 4 oznaczony jako przestarzały i powinien być zastąpiony przez SearchResultList. Oba interfejsy różnią się jedynie dodatkowym parametrem, który określa, czy lista ma być zbudowana dla nawigatora aplikacyjnego, czy dla okna dialogowego.
ListViewCreator:
public ListView createView(String viewName)
SearchListManager:
public void initList(List list)
SearchResultList:
public void initList(List list, String type)
Jako zamiennik dla trzech interfejsów dostępny jest w SearchHook VisualisationListHook z następującymi metodami:
public ListView createView(short type)
public void initList(List list, short type)
Przy przestawieniu należy pamiętać, że jako cel wizualizacji trzeba przekazać wartość typu short. Odpowiednie stałe znajdują się w klasie VisualisationTarget. Funkcjonalność obu metod pozostaje taka sama, więc poza obsługą parametru type nie trzeba wprowadzać żadnych zmian.
public static final class VisualisationTarget {
public static final short DIALOG = …;
public static final short LOCATOR = …;
}
SearchTableManager (TableDataManager)
Bezpośrednim zamiennikiem SearchTableManager jest VisualisationTableHook. SearchTableManager dziedziczy po TableDataManager.
SearchTableManager:
public void initTable(Table table)
TableDataManager:
public void dataToTable(CisListPartMutable data)
public void dataFromTable(CisListPartMutable data)
Metoda dataFromTable klasy TableDataManager była w wyszukiwaniach zawsze implementowana jako pusta, ponieważ w tym przypadku nie istnieje funkcjonalność przekazywania danych z tabeli z powrotem do modelu.
Metody VisualisationTableHook zostały więc zredukowane do dwóch. Dodatkowo pojawia się parametr typu short, który określa, czy tabela ma być wyświetlana w nawigatorze aplikacyjnym, czy w oknie dialogowym.
public void initTable(Table table, short type)
public void dataToTable(CisListPartMutable data, short type)
Dane wykonywania wyszukiwania
W obiektach deweloperskich dla wyszukiwań w Comarch ERP Enterprise zapisywane są metadane. Wyszukiwanie, podobnie jak każde inne obiekty deweloperskie, jest jednoznacznie identyfikowane przez kombinację przestrzeni nazw i nazwy. Na podstawie metadanych tworzone są dla wyszukiwań dane wykonywania, które przechowywane są w SearchInfo.
SearchInfo obejmuje nazwę wyszukiwania, pełną nazwę kwalifikowaną oraz nazwę wyświetlaną. Dodatkowo można zapisywać i odczytywać parametry domyślne za pomocą metod setParameter i getParameter. Informacje te mogą być wykorzystywane przy implementacji własnego SearchManagera w metodzie initSearch.
W metadanych można zapisać nazwę klasy hooka. Jeżeli taka nazwa jest obecna, tworzona jest instancja i odkładana w SearchInfo. Oprócz hooka w SearchInfo tworzony i przechowywany jest również SearchIterator. Dzięki użyciu SearchIteratorHook można w SearchInfo umieścić własny SearchIterator.
Każdy atrybut wyszukiwania w metadanych jest odwzorowany w obiekcie CisSearchField. W zależności od zastosowania CisSearchField, SearchInfo utrzymuje do niego kilka referencji. Możliwe zastosowania to: pole wyszukiwania, pole wyświetlania, pole sortowania, pole zapytania lub pole zwracane. Dla każdego z tych zastosowań w SearchInfo istnieje lista, którą można odczytać.
Rekordy wybrane przez użytkownika na liście wyników są w SearchInfo przechowywane do przekazania do pola wywołującego.
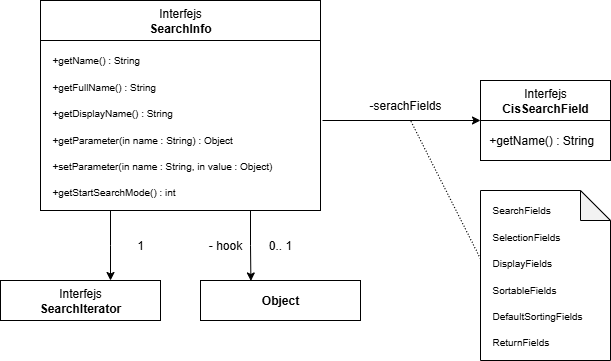
Wyciąg z danych wykonawczych
Zachowania specjalne
Poszczególne atrybuty w metadanych mogą być opatrzone specjalnym zachowaniem.
Identyfikacja i oznaczenie
Atrybuty ze specjalnym zachowaniem Identyfikacja lub Oznaczenie są w wyszukiwaniach odczytywane w kilku miejscach. Każde specjalne zachowanie może być przypisane tylko do jednego atrybutu w wyszukiwaniu. Zarówno Identyfikacja, jak i Oznaczenie muszą być zdefiniowane jako cecha wyszukiwania, pole wyświetlania oraz wartość zwracana. Znaczenie tych dwóch specjalnych zachowań zostało częściowo wyjaśnione już w rozdziale dotyczącym wyszukiwania wstępnego.
Przy zastosowaniu znacznika usuwania parametr Identyfikacja jest również wykorzystywany. Szczegóły można znaleźć w opisie znacznika usuwania.
Po tym, jak użytkownik wybierze z listy wyników żądane rekordy i przejmie je, w przypadku wyboru pojedynczego rekordu zawartość pól Identyfikacja i Oznaczenie jest przekazywana do pola wywołującego. Przy wielu wybranych rekordach zawartość pola Identyfikacja każdego rekordu jest łączona i przekazywana do pola wywołującego. Zawartość pól oznaczenia nie jest w tym przypadku uwzględniana.
Znacznik usuwania
To specjalne zachowanie może być przypisane tylko atrybutom opartym na znaczniku czasu (Timestamp). Zazwyczaj chodzi tu o atrybut deleteTime z części UpdateInformation obiektu biznesowego. Dodatkowo atrybut musi być oznaczony jako pole zapytania i wyświetlania. W ramach jednego wyszukiwania tylko jeden atrybut może mieć przypisane specjalne zachowanie Znacznik usuwania.
Jeżeli wymienione warunki są spełnione, w obszarze zapytania wyszukiwania pojawia się pole ValueSet z wpisami Ze znacznikiem usuwania oraz Bez znacznika usuwania. Dzięki temu użytkownik może wyszukiwać obiekty ze znacznikiem usuwania albo obiekty bez niego, bez konieczności ręcznego podawania czasu usunięcia.
W obszarze roboczym dla obiektów ze znacznikiem usuwania wyświetlane jest odpowiednie ikonograficzne oznaczenie. Ikona zawsze pojawia się w kolumnie danego pola po prawej stronie, które posiada specjalne zachowanie Identyfikacja. Atrybut ze specjalnym zachowaniem Znacznik usuwania nie otrzymuje w tabeli wyników własnej kolumny.
Niewidoczny
Atrybuty ze specjalnym zachowaniem Niewidoczny mogą być używane jako ukryte parametry zapytania. Pola te są generowane i dodawane do interfejsu użytkownika, a następnie przełączane na tryb niewidoczny. To specjalne zachowanie może być używane wyłącznie w zapytaniach.
Kontekst wyszukiwania
Dla tych atrybutów nie są generowane pola cech wyszukiwania. Służą one wyłącznie do kontekstu wyszukiwania.
Ustawienia w definicjach wyszukiwania
Funkcjonalność kontekstu wyszukiwania opiera się na tym, że istnieje zestaw nazw atrybutów, które w zbiorze wyszukiwań mają to samo znaczenie. Z tego zestawu nazw atrybutów wyszukiwanie może korzystać. Tylko użyte parametry są pobierane w kontekście wyszukiwania.
Atrybuty wykorzystywane w kontekście wyszukiwania muszą być cechami wyszukiwania i oznaczone specjalnym zachowaniem kontekstu wyszukiwania. Ważne jest przy tym, aby nazwa parametru, czyli alias w OQL, była taka sama we wszystkich wyszukiwaniach.
Interfejsy
Temat kontekstu wyszukiwania obejmuje trzy interfejsy: SearchContextProvider, SearchContext i SearchContextData.
SearchContextProvider
Aplikacja może zaimplementować SearchContextProvider, aby udostępniać SearchContext.
public interface SearchContextProvider {
public SearchContext getSearchContext();
}
SearchContext
SearchContext dostarcza dla cechy wyszukiwania ciąg wyszukiwania. Ciąg ten zostaje przypisany do iteratora wyszukiwania. Do tworzenia ciągu wyszukiwania powinna być używana klasa com.cisag.pgm.objsearch.SelectionSupport.
public interface SearchContext {
String getSelectionString(SearchContextData searchContextData);
}
SearchContextData
Instancje SearchContextData są tworzone i przekazywane do SearchContext. Oprócz nazwy atrybutu przekazywana jest również nazwa wyszukiwania oraz GUID bazy danych, w której wyszukiwanie jest wykonywane. Na podstawie tych informacji tworzona jest cecha ograniczająca wyszukiwanie, która zostaje zwrócona przez SearchContext w metodzie getSelectionString(…).
public interface SearchContextData {
public byte[] getDatabaseGuid();
public String getSearchName();
public String getParameterName();
}
Klasa pomocnicza SearchContextUtility
Klasa pomocnicza SearchContextUtility umożliwia zarejestrowanie SearchContextProvider na polu oraz ponowne odczytanie tej informacji.
public class SearchContextUtility {
static public void setSearchContextProvider(
Field guiField, SearchContextProvider provider)
static public SearchContextProvider
getSearchContextProvider(Field guiField)
static public SearchContextProvider
getSearchContextProvider(
com.cisag.pgm.dialog.VisualElement dialogElement)
}
Kolejność ustalania
Gdy wyszukiwanie zostaje otwarte na polu, próba ustalenia SearchContextProvider odbywa się w kolejności: SearchManager, Field, Application.
Najpierw w SearchManager za pomocą metody getSearchContextProvider() podejmowana jest próba uzyskania providera. Jeśli metoda ta nie została nadpisana w ramach własnego SearchManager, zwraca wynik null.
searchManager.getSearchContextProvider()
Jeżeli w SearchManager nie znaleziono SearchContextProvider, to dla pola wyszukiwanie odbywa się poprzez klasę pomocniczą SearchContextUtility.
SearchContextUtility.getSearchContextProvider(field)
Dopiero gdy dla pola nie uda się ustalić SearchContextProvider, sprawdzane jest, czy bieżąca aplikacja, do której należy to pole, implementuje interfejs SearchContextProvider.
application instanceof SearchContextProvider
Jeśli w którymś z trzech kroków udało się ustalić SearchContextProvider, to po otwarciu wyszukiwania zostaje on przypisany każdemu polu cechy wyszukiwania za pomocą klasy SearchContextUtility.
Gdy następnie otwierane jest wyszukiwanie na jednym z pól cech wyszukiwania, w pierwszej kolejności sprawdzany jest SearchManager tego pola. Jeżeli metoda getSearchContextProvider() nie została nadpisana, to za pomocą klasy SearchContextUtility sprawdzane jest, czy SearchContextProvider został przypisany do pola.
Kontekst wyszukiwania w wyszukiwaniu nawigatora zależnym od aplikacji
Jeśli aplikacja implementuje interfejs SearchContextProvider, to także wyszukiwania w nawigatorze tej aplikacji korzystają z tego kontekstu wyszukiwania. Zasadniczo pola kluczowe aplikacji i wyszukiwanie w nawigatorze powinny używać tego samego SearchContextProvider.
Jeśli jednak w aplikacji wszystkie pola (poza polami kluczowymi) wymagają bardziej specjalistycznego SearchContextProvider, np. dlatego, że pola mają być zależne od załadowanego obiektu, to deweloper musi — korzystając z dotychczas opisanych możliwości — ustawiać SearchContextProvider na każdym polu aplikacji. Jest to sprzeczne z ideą kontekstu wyszukiwania, według której SearchContextProvider powinien być ręcznie ustawiany wyłącznie dla wyjątków.
W takim przypadku można postąpić następująco: SearchContextProvider aplikacji zostaje przygotowany dla szczególnego przypadku, który jednak dotyczy większości pól. Pola kluczowe, których liczba jest zazwyczaj niewielka, otrzymują własny SearchContextProvider.
Wyszukiwania w nawigatorze również wymagają własnego SearchContextProvider. Aby go udostępnić, można w klasie CisUiApplication nadpisać następującą metodę:
public class CisUiApplication {
…
public SearchContextProvider getLocatorSearchContextProvider(){…}
…
}
W kolejności ustalania SearchContextProvider w wyszukiwaniach nawigatora metoda ta jest wywoływana jako pierwsza. Jeśli zwróci — jak w standardzie — wartość null, to sprawdzane jest, czy aplikacja implementuje interfejs SearchContextProvider. Jeśli tak, to jest on używany w wyszukiwaniach nawigatora.
Części specjalne
W wyszukiwaniach niektóre wyróżnione części (Parts) są traktowane w sposób szczególny. Dla tych części stosuje się specjalne pola wprowadzania. Również podczas wyszukiwania i przygotowywania wyników wyszukiwania są one obsługiwane odrębnie. W wyszukiwaniach nazywa się je częściami specjalnymi.
Części specjalne nie mogą być używane w wyszukiwaniu ani jako atrybuty kluczowe, ani jako kryteria sortowania. W obu przypadkach wznawianie wyszukiwania nie będzie wtedy działało poprawnie.
Poniżej przedstawiono krótko, jakie części specjalne są obsługiwane:
DomesticAmount
Comarch ERP Enterprise potrafi jednocześnie operować trzema walutami, tzn. przy wprowadzaniu kwoty należy podać walutę. Może być ona wybrana spośród trzech z góry określonych walut. Kwoty dla pozostałych dwóch walut są zazwyczaj obliczane automatycznie. W przypadku dalszych obliczeń przeprowadzane są oddzielne kalkulacje dla wszystkich trzech walut. Dzięki temu unika się błędów zaokrągleń podczas przeliczania między walutami.
Na podstawie wybranej waluty (jednej z trzech możliwych) można określić, do której kolumny w bazie danych należy wprowadzony ciąg wyszukiwania. W danym momencie możliwe jest wyszukiwanie tylko w jednej walucie. W przypadku środowiska wielofirmowego wyszukiwanie odbywa się zawsze wyłącznie w walucie krajowej, wspólnej dla wszystkich organizacji.
ForeignAmount, Quantity, Duration
- ForeignAmount — waluta obca, która oprócz kwoty zawiera również walutę
- Quantity — ilość, która oprócz wartości liczbowej posiada jednostkę
- Duration — czas trwania, składający się z wartości liczbowej oraz jednostki
Wszystkie trzy części mają wspólną cechę: w wyszukiwaniu są określane poprzez ciąg wyszukiwania dla wartości liczbowej oraz identyfikator GUID dla waluty lub jednostki.
StorageLocation_RLB (Row-Level-Bin)
Zarządzanie miejscami składowania zapisuje w tej części lokalizację magazynową z dokładnym wskazaniem miejsca składowania. Rozróżnia się tu rząd, poziom i miejsce. Do prezentacji poszczególne elementy przedstawiane są w podanej kolejności i oddzielane myślnikiem, np. 10-2-4. Wprowadzanie StorageLocation_RLB obsługuje symbole wieloznaczne (wildcards) jedynie na końcu, np. 10-2-*.
Przy wprowadzaniu Row-Level-Bin obowiązuje konwencja dotycząca liczby podanych części. Podanie tylko jednej części danych jest traktowane jak podanie miejsca składowania (Bin), np. 70*. Podanie dwóch części danych jest traktowane jak podanie rzędu i miejsca (Row-Bin), np. 10-70*. Dopiero podanie trzech części danych jest traktowane jako wskazanie rzędu, poziomu i miejsca (Row-Level-Bin), np. 10-5-70*
Duration
Okres czasu opisany jest przez dwa punkty: początek i koniec. Jeśli podane są oba punkty, mówi się o okresie zamkniętym. Jeśli brakuje jednego lub obu punktów, jest to okres otwarty. Wyszukiwania w Comarch ERP Enterprise interpretują wprowadzony okres czasu.
Valueset – wartości 0
W Comarch ERP Enterprise wartości zestawu (Valuesets) powinny z definicji mieć wartość większą niż 0. Tworzenie stałych dla zestawu wartości zależy od poziomu wersjonowania systemu, na którym prowadzi się rozwój.
Valueset składa się z kolekcji stałych, np. 1, 2, 3, 4, 5, 6. Zestawy wartości mogą być ograniczane poprzez hierarchię dziedziczenia typów logicznych, co dodatkowo zmniejsza liczbę możliwych stałych, np. 1, 2, 4, 5.
W bazie danych w odpowiednim polu zawsze zapisany jest dokładnie jeden element zestawu Valueset. Ponieważ przy zapisie jądro systemu nie sprawdza, czy zapisana wartość pochodzi z możliwego zestawu, może być tam zapisane także 0.
Pole Valueset zwraca w metodzie getSelectionString wyliczenie wybranych stałych zestawu Valueset, oddzielonych przecinkiem i spacją (np. 1, 2, 3, 4).
W opisie danych (Data-Description) można określić, czy wprowadzenie wartości do typu logicznego jest wymagane, czy nie. Tylko jeśli wprowadzenie nie jest wymagane, metoda getSelectionString zwraca oprócz wybranych stałych zestawu również wartość 0, np. 0, 1, 2, 3, 4.
Podczas wyszukiwania analizowany jest otrzymany łańcuch wyszukiwania Valueset. Jeśli zostanie w nim znalezione 0, ciąg znaków zostaje rozszerzony o null jako dodatkową możliwą wartość. Zachowanie to jest zdefiniowane systemowo.
Wartości ciągu wyszukiwania są łączone operatorem OR i dodawane jako warunek do klauzuli WHERE.
Powód dodawania wartości null
Pole Valueset zawsze zwraca łańcuch z parametrami ograniczającymi wynik wyszukiwania. Zachowuje się więc inaczej niż większość innych pól, które mogą zwrócić pusty łańcuch znaków, co skutkuje tym, że odpowiadający parametr nie jest brany pod uwagę w klauzuli WHERE.
Outer Join zwraca również rekordy wtedy, gdy dla danego rekordu nie ma odpowiadającego wpisu w tabeli połączonej. Jeśli w SELECT znajdują się atrybuty tabeli dołączanej, to są one wypełniane wartością null.
Dla wyjaśnienia przyjęto następujące założenie: zarówno w SELECT, jak i w WHERE znajduje się ten sam zestaw Valueset tabeli połączonej. W opisie danych (Data-Description) zestawu Valueset jest określone, że wprowadzenie jest wymagane. Zgodnie z opisanymi wcześniej zasadami zestaw Valueset dostarcza wtedy jedynie wybrane przez użytkownika stałe jako parametry zapytania.
Jeśli takie ograniczenie zostanie zastosowane do rekordu, którego atrybuty w tabeli dołączonej są równe null, to rekord ten zostaje usunięty z wyników, ponieważ null nie odpowiada żadnej z możliwych stałych zestawu. Powstaje więc dokładnie takie zachowanie, którego Outer Join miał unikać.
Jeśli natomiast wprowadzenie do zestawu Valueset nie byłoby wymagane, to w klauzuli WHERE pojawiłoby się dodatkowe is Null i rekord pozostałby w wynikach.
W pierwszym przypadku w opisie danych (Data-Description) ustawiono wprowadzenie jako wymagane. Użytkownik wybrał wartość Wszystkie w polu Valueset. Metoda getSelectionString zwraca następujący łańcuch: 1, 2, 4, 6.
Wznawianie wyszukiwań
Wyszukiwanie w Comarch ERP Enterprise zazwyczaj nigdy nie ładuje pełnego zestawu danych. Zamiast tego zawsze wczytywana jest tylko ograniczona liczba rekordów. W udostępnionych wizualizacjach wyszukiwania — wyszukiwaniu dialogowym, wyszukiwaniu w obszarze nawigacyjnym itd. — liczba ta jest ograniczona do 60 rekordów. Jeśli potrzebne są kolejne rekordy, wyszukiwanie musi zostać wznowione w poprzednim miejscu, aby dociągnąć następne rekordy.
Aby możliwe było wznowienie, w wygenerowanym na podstawie metadanych zapytaniu OQL należy wprowadzić pewne rozszerzenia. Proces ten zostanie wyjaśniony na przykładzie.
Tabela Table1 posiada atrybuty a, b, e, f, k, m. Atrybuty k i m tworzą kluczowe atrybuty rekordu. Na podstawie metadanych wyszukiwania opartego na tej tabeli można wygenerować następujące zapytanie OQL.
SELECT a, b
FROM Table1
WHERE (a = 'abc’ AND f=y)
ORDER BY e, f
Do ponownego uruchomienia konieczne jest jednoznaczne zachowanie kolejności sortowania tabeli. Może się zdarzyć, że dla określonych kryteriów sortowania istnieje więcej niż jeden rekord. Aby jednoznacznie ustalić kolejność, klauzula ORDER BY zostaje rozszerzona o atrybuty klucza głównego k i m.
SELECT a, b
FROM Table1
WHERE (a = 'abc’ AND f=y)
ORDER BY e, f, k, m
Aby później możliwe było ponowne uruchomienie, należy zapamiętać ostatni odczytany rekord. Ponieważ atrybuty a i b nie wystarczają do jednoznacznego określenia rekordu w bazie danych z uwzględnieniem sortowania, wszystkie atrybuty z klauzuli ORDER BY muszą zostać również uwzględnione w klauzuli SELECT.
SELECT a, b, e, f, k, m
FROM Table1
WHERE (a = 'abc’ AND f=y)
ORDER BY e, f, k, m
Za pomocą tego OQL można teraz wykonać pierwsze zapytanie. Ostatni odczytany rekord n zawiera jako wynik następujące dane:
an, bn, en, fn, kn, mn
Do ponownego uruchomienia należy następnie utworzyć dodatkowy warunek, za pomocą którego można określić rekordy następujące po rekordzie n.
e > en
OR (e = en AND f > fn)
OR (e = en AND f = fn AND k > kn)
OR (e = en AND f = fn AND k = kn AND m > mn)
Wbudowane w OQL daje to dla poniższych wyszukiwań następujące wywołanie:
SELECT a, b, e, f, k, m
FROM Table1
WHERE (a = 'abc’ AND f=y)
AND e > en
OR (e = en AND f > fn)
OR (e = en AND f = fn AND k > kn)
OR (e = en AND f = fn AND k = kn AND m > mn)
ORDER BY e, f, k, m
Sortowania
Wyszukiwanie może zwrócić dużą liczbę rekordów. Aby móc lepiej zarządzać tym zbiorem, konieczne jest wykonanie sortowania. Sortowanie odbywa się już na poziomie bazy danych.
Metadane
Podczas rejestrowania metadanych wyszukiwania w bazie danych repozytorium można określić atrybuty, które zostaną zakwalifikowane jako możliwe do sortowania. Spośród tych atrybutów można następnie wskazać te, które mają być faktycznie używane do sortowania. Oznacza to, że jeśli użytkownik nie wprowadzi innych ustawień, znalezione rekordy zostaną posortowane zgodnie z tymi ustawieniami.
Oprócz wyboru atrybutów sortowania można również określić kierunek sortowania dla każdego atrybutu. Sortowanie może być rosnące lub malejące.
Dialog sortowania
W wyszukiwaniu dialogowym oraz w wyszukiwaniu w obszarze nawigacyjnym użytkownik ma możliwość zmiany sposobu sortowania wyników. W tym celu otwierany jest dialog. Składa się on z dwóch list oraz różnych przycisków umieszczonych między nimi.
Na liście po lewej stronie znajdują się atrybuty aktualnie używane do sortowania. Istotna jest kolejność, w jakiej atrybuty zostały umieszczone. Parametr znajdujący się najwyżej jest jednocześnie pierwszym atrybutem w sortowaniu. Obok każdego atrybutu widoczny jest symbol określający kierunek sortowania – rosnący lub malejący.
Na liście po prawej stronie znajdują się natomiast atrybuty, które są dostępne do sortowania, ale obecnie nie są wykorzystywane.
Łącznie atrybuty w obu listach odpowiadają dokładnie zbiorowi atrybutów oznaczonych w metadanych wyszukiwania jako możliwe do sortowania.
Za pomocą przycisków można przenosić atrybuty z jednej listy na drugą. Można także, po zaznaczeniu atrybutu z pierwszej listy, zmienić jego kierunek sortowania.
Kolejność sortowania w bazie danych i Comarch ERP Enterprise
Jak już wspomniano, sortowanie odbywa się zgodnie z kolejnością sortowania bazy danych. Różne bazy danych mogą mieć różne porządki sortowania. Kolejność sortowania w bazie danych opiera się na języku bazy danych. Te same dane mogą być więc różnie posortowane w różnych bazach danych.
Aby uwzględnić ten fakt, w TransactionManager można pobrać Comparator dla każdej bazy danych podłączonej do systemu. Może on zostać wykorzystany do porównywania list rekordów. Alternatywnie dostępna jest klasa com.cisag.pgm.objsearch.DefaultComparator, która umożliwia porównywanie obiektów typu CisListPartMutables w sposób specyficzny dla danej bazy danych. Wewnątrz ta klasa opiera się na opisanym Comparatorze z TransactionManager.
To sortowanie jest używane wewnątrz wyszukiwań w DefaultSearch.
SortOrderAction
SortOrderActions można wykorzystać do wyświetlania SortOrderDialog, np. w nagłówkach tabel. W połączeniu z SortOrder i Comparator można również wykonywać sortowania w pamięci operacyjnej.
SortOrder można utworzyć na potrzeby wyszukiwania, używając nazwy wyszukiwania jako parametru dla SortOrder.
SortOrder sortOrder = new SortOrder(„com.cisag….”);
Alternatywnie można również ręcznie ustawić wszystkie istotne dane w postaci list tablicowych (Array-Listen). Nazwy nie są w tym przypadku ścieżkami ani odwołaniami do tabel znakowych, lecz rzeczywiście wyświetlanymi nazwami w dialogu.
String[] availableDisplayNames = …;
String[] availableFieldNames= …;
String[] defaults= …;
boolean[] defaultDirections = …;
SortOrder sortOrder = new SortOrder(availableDisplayNames,
availableFieldNames,
defaults,
defaultDirections);
Aby utworzyć SortOrderAction dla wygenerowanej SortOrder, należy utworzyć SortOrderAction i przypisać SortOrder do tej akcji. Zarejestrowany ActionListener zostanie wywołany w momencie, gdy sortowanie w dialogu zostanie zmienione i dialog zostanie zamknięty.
SortOrderAction sortOrderAction = new SortOrderAction();
sortOrderAction.setSortOrder(sortOrder);
sortOrderAction.addActionListener(this);
Tak wygenerowana SortOrder może być następnie wyświetlana na interfejsie, np. jako HeaderElement listy.
List list = new List(…);
Button sortOrderButton = list.addHeaderElement(sortOrderAction);
W aplikacjach zapytań SortOrderAction powinien zawsze być uwzględniany w SelectionGroup. Jeśli parametry aplikacji są zapisywane, zapisywane są również ustawienia sortowania.
CisUiApplication application = …;
SelectionGroup result = application.getSelectionGroup();
result.setSortOrderAction(sortOrderAction);
Gdy dialog sortowania zostanie zamknięty, wykonywana jest akcja o identyfikatorze Action.SORTORDER_CHANGED. Może ona następnie zostać obsłużona w zarejestrowanym ActionListener.
Jeśli wymagane jest własne sortowanie danych, należy zaimplementować Comparator, który przejmie to zadanie. Comparator jest przekazywany liście do metody sort(…).
public void performAction(Action action) {
if (action.getId() == Action.SORTORDER_CHANGED) {
list.sort(new AComparator(sortOrderAction.getSortOrder()));
}
}
Zalecana implementacja własnego Comparator może wyglądać następująco. Do porównywania powinien być, jak już wspomniano, używany Comparator bazy danych.
class AComparator implements Comparator {
Comparator databaseComparator;
public ACompatator() {
CisTransactionManager tm = …;
databaseComparator = tm.getComparator(…);
}
public int compare(Object o1, Object o2) {
CisListPartMutable row1 = (CisListPartMutable) o1;
CisListPartMutable row2 = (CisListPartMutable) o2;
MyObject obj1 = (MyObject) row1.getData();
MyObject obj2 = (MyObject) row2.getData();
String[] attrs = sortOrder.getSelectedFieldNames();
boolean[] dirs = sortOrder.getSelectedDirections();
// dirs[] = true –> asc-sort else desc-sort
for (int i = 0; i < attrs.length; i++) {
int r = 0; // -1:(o1<o2), 0:(o1=o2), +1:(o1>o2)
if („code”.equals(attrs[i])) {
r = databaseComparator.compare(obj1.getCode(),
obj2.getCode());
} else if („description”.equals(attrs[i])) {
r = databaseComparator.compare(obj1.getDescription(),
obj2.getDescription());
} …
if (r != 0) {
return dirs[i] ? r : -r;
}
}
return row1.getIndex() – row2.getIndex();
}
}
Wielkość liter
W systemach Comarch ERP Enterprise dla każdego atrybutu typu ciąg znaków określone jest zachowanie podczas wprowadzania i wyszukiwania, które ma wpływ na tworzone dla niego pola wprowadzania. O ile nie występują wyjątki, identyfikatory (Business Keys) zawierają wyłącznie wielkie litery. Wszystkie pozostałe atrybuty typu ciąg znaków mogą zawierać zarówno małe, jak i wielkie litery.
Indeksy są zwykle stosowane w obiektach biznesowych w celu zwiększenia wydajności. Jeśli jednak wyszukiwanie odbywa się niezależnie od wielkości liter, baza danych nie może wykorzystać indeksu. Z tego powodu, o ile nie występują wyjątki, w przypadku wyszukiwania w atrybutach, dla których istnieje indeks, uwzględniana jest wielkość liter. Natomiast przy wyszukiwaniu we wszystkich pozostałych atrybutach, tj. atrybutach bez indeksu, bez wyjątków lub identyfikatorów, wielkość liter nie jest uwzględniana. W szczególności wszystkie pola oznaczenia są wyszukiwane niezależnie od wielkości liter.
Wyjątki:
- Z wyjątkiem danych konfiguracyjnych, we wszystkich atrybutach systemowych obiektów biznesowych wielkość liter jest uwzględniana przy wprowadzaniu i wyszukiwaniu, niezależnie od ustawień systemowych.
- W następujących obiektach biznesowych przy identyfikacji wielkość liter jest uwzględniana: języki, zwroty grzecznościowe, tytuły, jednostki, relacje partnerskie. W klasie implementacyjnej hooka com.cisag.app.general.log.CaseSensitivityRegistryHookImpl zarejestrowane są te odstępstwa od zachowania wyszukiwania i wprowadzania. Klasa ta zawiera wyjątki obowiązujące w standardzie. Na potrzeby rozwoju partnerskiego, klientowskiego lub aplikacji należy wprowadzić własną implementację hooka com.cisag.pgm.appserver.hook.CaseSensitivityRegistryHook, który został zdefiniowany w kontrakcie hooka com.cisag.pgm.appserver.Server. W klasie com.cisag.app.general.log.CaseSensitivityRegistry można zarejestrować dodatkowe wyjątki, które nie muszą mieć określonego prefiksu deweloperskiego. Może to być konieczne np. wtedy, gdy rozwój partnerski nie zawiera własnej implementacji hooka, ale w adaptacji klienta ma zostać zarejestrowany wyjątek z tego rozwoju partnerskiego.
- Stałe w kręgach numeracyjnych muszą być zapisywane wielkimi literami, aby były generowane tylko numery zapisane wielkimi literami.
Ustawienia rejestru CaseSensitivityRegistry
Klasa com.cisag.app.general.log.CaseSensitivityRegistry zawiera metodę, która dostarcza listę domyślnych ustawień dotyczących rozróżniania wielkości liter.
Każdy wyjątek jest definiowany za pomocą złożonego ciągu znaków. Pierwsza wartość w tym ciągu, po której następuje średnik, musi być albo PATH albo PARENT.
PATH jest używany wtedy, gdy dokładnie jeden atrybut obiektu biznesowego jest objęty regułą. W takim przypadku po Path podaje się pełną, kwalifikowaną nazwę obiektu biznesowego, dwukropek oraz nazwę atrybutu (czyli tzw. Atrybut-Path). Następnie, po średniku, określa się sposób wyszukiwania. Do wyboru są wartości: CASE_SENSITIV, UPPER i CASE_INSENSITIV.
PARENT może być używany wyłącznie w hierarchiach i grupach. Po PARENT i średniku podaje się nazwę części oraz sposób wyszukiwania. Wszystkie obiekty biznesowe, które dziedziczą po danej części, używają wskazanego sposobu wyszukiwania.
List caseSensitivityDefaults) {
caseSensitivityDefaults.add(„PATH;” +
„com.cisag.app.general.obj.Language:isoCode;” +
„CASE_SENSITIVE”);
caseSensitivityDefaults.add(„PATH;” +
„com.cisag.app.general.obj.NumberRange:” +
„format[0].constant;” +
„UPPER”);
caseSensitivityDefaults.add(„PARENT;” +
„com.cisag.app.general.obj.Code;” +
„UPPER”);
…
}
Rejestrowanie wyjątków w implementacji hooka odbywa się w podobny sposób — informacje na ten temat można znaleźć w dokumentacji Javy dla interfejsu com.cisag.pgm.appserver.hook.CaseSensitivityRegistryHook.CaseSensitivityRegistry.
Nie jest możliwe rejestrowanie wyjątków typu PARENT w implementacji hooka.
SearchActions
SearchActions to specjalny rodzaj akcji, które po wywołaniu uruchamiają dialog wyszukiwania. Gdy użytkownik wybierze jeden lub więcej elementów i wybierze przycisk [Akceptuj], powiadamiany jest acceptListener. Tekst na przycisku może być zdefiniowany przez programistę.
W konstruktorze SearchAction podaje się ActionListener, który jest powiadamiany, gdy użytkownik dokona wyboru i kliknie przycisk potwierdzenia. Obiekt ActionEvent, oprócz acceptId, zawiera w swoim state tablicę obiektów CisParameterLists. W przypadku pojedynczego wyboru, tablica ta zawiera dokładnie jedną CisParameterLists. W tej liście parametrów, wyniki z wybranego wiersza są przechowywane pod nazwami atrybutów, które zostały zdefiniowane w wyszukiwaniu.
Poniżej znajduje się lista dostępnych metod dla klasy SearchAction.
public SearchAction(int acceptId, String actionPath, ActionListener
acceptListener)
public void setSearch(String search)
public void setAcceptName(String acceptName)
public void setAcceptNameFrom(String absPath, Object[] parameters)
public void setVisualElement(VisualElement visualElement)
public void setMultiSelection(boolean multiSelection)
public void setSearchManager(SearchManager searchManager)
public void startSearch()
Buforowanie wyników wyszukiwania w pamięci podręcznej
Wszystkie rodzaje wyszukiwania — dialogowe, listy wyboru i te w nagłówku — obsługują buforowanie wyników w pamięci podręcznej (cache). Mechanizm ten jest zintegrowany z CisOqlSearchStatement. Listy wyboru zawsze wyświetlają aktualne dane, które mogą pochodzić bezpośrednio z bazy danych lub z pamięci podręcznej. Natomiast wyszukiwanie w nagłówku i dialogi wyszukiwania mogą pokazywać również dane nieaktualne. Jeśli dane pochodzą z cache w nagłówku listy wyników pojawia się odpowiednia informacja. Jeśli dane są potencjalnie nieaktualne, dodatkowo zostanie wyświetlony tooltip. Aby zaktualizować dane i odświeżyć pamięć podręczną, wystarczy ponownie uruchomić wyszukiwanie.
System decyduje, czy dane w pamięci podręcznej są aktualne, analizując używane obiekty biznesowe. Jeśli w którejś z tabel zawierających te obiekty doszło do zmian (dodania, usunięcia lub modyfikacji danych), system oznaczy wpis w pamięci podręcznej jako nieaktualny przy następnym dostępie. Należy jednak pamiętać, że takie oznaczenie nie zawsze wskazuje na to, że dane są przestarzałe, ponieważ buforowane informacje mogły nie zostać zmienione.
Pamięć podręczna używa unikalnego klucza składającego się z bazy danych, języka, zapytania OQL (wraz z typami danych) oraz cech wyszukiwania. Każdy wpis w cache przechowuje maksymalnie 61 rekordów. Na każdy serwer aplikacji Comarch ERP Enterprise przypada jeden cache wyszukiwania, dzięki czemu inni użytkownicy, wysyłający identyczne zapytanie, mogą również skorzystać z wcześniej buforowanych danych.
Domyślna wielkość pamięci podręcznej to 300 wpisów. W przypadku dużej liczby użytkowników, zaleca się zwiększenie jej rozmiaru. W tym celu należy ustawić właściwość com.cisag.sys.objsearch.SearchCacheMaxSize na wyższą wartość.
Wstępne wypełnianie danych
Jeśli użytkownik chce wstępnie wypełnić dane w wyszukiwaniu, musi przestrzegać kilku zasad:
Wstępne wypełnianie musi być realizowane zarówno dla list wyboru, jak i dla wyszukiwania dialogowego. Aby to zagwarantować, wstępne wypełnianie musi być realizowane za pomocą własnego SearchManager. W metodzie initSearch można wstępnie wypełnić każdy atrybut wyszukiwania. Wstępne wartości można ustawiać tylko dla prostych atrybutów, takich jak ciągi znaków (String) czy zestawy wartości (ValueSet). Specjalne części, czas i data są wykluczone.
W metodzie manipulateSelectionFieldAfter w SelectionFieldHook również można wstępnie wypełniać pola. Jednakże, ponieważ te wartości nie są używane we wstępnych wyszukiwaniach, nie zaleca się ich tam ustawiania.
Debugowanie
Wyświetlanie OQL na konsoli
Dzięki wbudowanej funkcji debugowania w systemie Comarch ERP Enterprise, można wyświetlić wewnętrznie używane zapytanie OQL na konsoli. Zapytanie jest wyświetlane na poziomie Debug.FINE.
Aby to zrobić, nalezy wprowadzić następującą komendę w konsoli działającego serwera aplikacji Comarch ERP Enterprise (SAS):
dbgcls –class:com.cisag.sys.objsearch.log.CisOqlSearchStatement
–level:100
Po wykonaniu zapytania OQL, na konsoli zostanie wyświetlone samo zapytanie oraz wartości jego parametrów.
Zmiana maksymalnej liczby rekordów
Domyślna maksymalna liczba rekordów wyświetlanych w wartościach pomocniczych lub w pomocy nawigacyjnej związanej z aplikacją to 500. W niektórych przypadkach może być konieczne, aby celowo zmienić tę wartość dla poszczególnych wyszukiwań. Wartość może być ustawiona na mniejszą lub większą niż 500.
Ustawienie odbywa się za pomocą właściwości com.cisag.sys.objsearch.SearchResultSize, zgodnie z opisem w artykule Właściwości Comarch ERP Enterprise, w rozdziale dotyczącym usługi trwałości.
Wydajność
Każdy dodatkowy join zwiększa złożoność zapytania do bazy danych. Dzięki użyciu fragmentów, tabele potrzebne do selekcji lub sortowania są włączane do zapytania tylko wtedy, gdy są faktycznie niezbędne. Dlatego zaleca się dzielenie zapytań OQL na jak największą liczbę fragmentów. Duża liczba fragmentów nie ma negatywnego wpływu na wydajność wyszukiwania.
Wybór kolejności sortowania oraz użycie DISTINCT może mieć negatywny wpływ na wydajność wyszukiwania. Kiedy użytkownik stosuje DISTINCT lub sortuje wyniki, konieczne jest obliczenie całego zestawu wyników zapytania. W przypadku dużych zbiorów danych może to prowadzić do bardzo długiego czasu wykonania. Dlatego DISTINCT należy używać tylko wtedy, gdy jest to absolutnie konieczne.



