Duże systemy oprogramowania składają się z różnych komponentów. Służy to między innymi zmniejszeniu złożoności poszczególnych komponentów, rozłożeniu obciążenia lub ukierunkowanemu wykorzystaniu ograniczonych zasobów oraz zapewnieniu możliwości rozbudowy. Wymaganiem często pojawiającym się w kontekście rozszerzalności jest integracja istniejącego systemu oprogramowania z nowym komponentem lub nawet innym systemem. Pytania, pojawiające się w tym zakresie, są w dużej mierze niezależne od konkretnego systemu oprogramowania, wybranej platformy lub języka programowania. W konkretnym scenariuszu integracji konieczne jest również wybranie technologii i architektury interfejsu, które są odpowiednie dla danych warunków ogólnych.
W pierwszej części dokumentu wymieniono różne aspekty, odgrywające rolę w integracji systemów oprogramowania, a także opisano ich wpływ na czynniki takie jak wydajność, czas reakcji, zużycie zasobów itp. Druga część opisuje konkretne możliwości integracji systemu oprogramowania, ze szczególnym uwzględnieniem specjalnych cech w przypadku integracji z Comarch ERP Enterprise.
Należy mieć na uwadze, że nie ma jednej technologii interfejsu, która spełniałaby wszystkie wymagania w równym stopniu. Właściwy wybór zależy od konkretnego scenariusza oraz ogólnych warunków. Najlepszym rozwiązaniem może być zarówno wymiana pliku w systemie danych, jak również wywołanie usługi sieciowej przez Internet.
Kwestie związane z treścią integracji, czyli to, jakie usługi, struktury danych i dane musi oferować interfejs, nie są częścią tego dokumentu i nie mają na nie wpływu.
Klient i serwer
Gdy procesy w systemach oprogramowania odbywają się w sposób rozproszony, jeden komponent przyjmuje rolę klienta, wysyłającego zapytania, natomiast inny komponent przyjmuje rolę serwera, który na zapytania odpowiada. Między klientem a serwerem istnieje sieć, która przesyła zapytania z określonym protokołem i kodowaniem. W niektórych przypadkach role klienta i serwera mogą się zmieniać w trakcie komunikacji lub w miarę upływu czasu. Przykładowo Comarch ERP Enterprise Application Server jest serwerem dla klienta przeglądarki, ale sam jest również klientem serwera bazy danych. W dalszej części dokumentu komponent wysyłający zapytanie zawsze jest nazywany klientem.
Ponieważ serwer zazwyczaj musi być w stanie obsłużyć więcej niż jednego klienta w tym samym czasie, potrzebuje zarządzania zalogowanymi klientami i, w razie potrzeby, kilku jednostek wykonawczych do odpowiadania na przychodzące zapytania.
Jakość systemów oprogramowania
Podczas rozszerzania systemu oprogramowania należy zadbać o to, aby nie tylko samo rozszerzenie miało odpowiednią jakość, lecz także, aby wpływ na istniejący system oprogramowania nie pogorszył jego jakości. Podczas implementacji klienta i serwera należy wziąć pod uwagę między innymi następujące cechy jakościowe
- Przepustowość – praca większości systemów oprogramowania opiera się na transakcjach. Przepustowość opisuje liczbę transakcji w danym czasie.
- Czas odpowiedzi – zwłaszcza w systemach interaktywnych, w których użytkownicy oczekują bezpośrednich odpowiedzi na swoje dane, czas ten nie powinien przekraczać pewnego poziomu (około 0,5-2 sekund). Należy zauważyć, że wysoka przepustowość nie jest równoznaczna z niskim czasem reakcji i odwrotnie.
- Zużycie zasobów – zasobami mogą być komputery, pamięć główna, pojemność dysku twardego, karty sieciowe, połączenia sieciowe, procesory, wątki. Ilość zasobów w systemie oprogramowania jest ograniczona. Aby móc przetworzyć jak najwięcej zapytań tak szybko, jak to możliwe, zapytanie powinno zużywać jak najmniej zasobów, natomiast same zasoby powinny zostać zwolnione tak szybko, jak to możliwe. Współdzielone zasoby muszą być chronione przez mechanizmy blokujące. Może to mieć wpływ na przepustowość.
- Skalowalność – system powinien rosnąć wraz z rosnącą liczbą klientów, a co za tym idzie, zwiększać przepustowość bez wydłużania czasu odpowiedzi.
Osiąga się to w szczególności poprzez zminimalizowanie komunikacji sieciowej, wykorzystując caching (pamięć podręczna bazy danych, pamięć podręczna serwera, pamięć podręczna klienta), a także wykonując zadania w ramach jednego zapytania równolegle. - Przenośność – aby w razie potrzeby móc korzystać z innego, bardziej wydajnego sprzętu, rozszerzenie powinno być przenośne. Wpływ na to mają następujące czynniki:
- język programowania
- platforma systemu operacyjnego, określa ona na przykład składnię specyfikacji ścieżek
- używany DBMS, ponieważ pomimo standaryzacji SQL, różne DBMS używają różnej składni i oferują różne typy danych.
- protokół komunikacyjny pomiędzy klientem a serwerem
- Dostępność – jeśli rozszerzenie ma być instalowane kilka razy, należy zadbać o to, aby poprawki i nowości, pojawiające się podczas konserwacji i dalszego rozwoju, mogły być przekazywane w kontrolowany sposób i instalowane przy jak najmniejszym przestoju.
- Bezpieczeństwo – aby zapewnić dostępność systemu i chronić zawarte w nim dane przed dostępem osób nieupoważnionych, musi on być w stanie chronić się przed nieautoryzowanymi zapytaniami. W tym celu istnieją różne mechanizmy uwierzytelniania i autoryzacji. Rozszerzenia nie powinny obchodzić mechanizmów bezpieczeństwa istniejącego systemu oprogramowania.
- Testowalność – rozszerzenia systemu powinny być tak łatwe do przetestowania, jak to tylko możliwe, tak aby sprawdzić poprawność działania rozszerzeń i móc badać problemy.
Korzystanie z infrastruktury
Gdy tworzone jest rozszerzenie systemu oprogramowania, musi ono zostać odpowiednio zintegrowane z infrastrukturą istniejącego systemu. Oznacza to, że istniejące usługi, takie jak caching, blokowanie, uprawnienia itp. powinny być wykorzystywane w celu oszczędzania zasobów i minimalizowania wysiłku administracyjnego. Jednocześnie w miejscach, w których usługi te nie są celowo lub obowiązkowo wykorzystywane, nie powstają żadne konflikty ani błędy.
Przykłady usług, które należy uwzględnić:
- pamięć podręczna przeglądarki
- współdzielona pamięć podręczna na Comarch ERP Enterprise Application Server
- pamięć podręczna stron na serwerze bazy danych
Blokady:
- semafory w Javie (użycie synchronized)
- blokady obiektów biznesowych i blokady logiczne w Comarch ERP Enterprise
- blokady tabel, stron i wierszy w bazie danych
Uprawnienia:
- certyfikaty klientów
- uprawnienia i role uprawnień Comarch ERP Enterprise
- uprawnienia bazy danych dotyczące obiektów i użytkowników DBMS
Sieć
Podczas połączenia ze zdalnym interfejsem, każde zapytanie od klienta jest przesyłane przez sieć. Wraz ze wzrostem liczby klientów rośnie wpływ sieci. Następujące właściwości są charakterystyczne dla sieci:
- wielkość bloków – sieci domyślnie wysyłają dane w pojedynczych blokach. W przypadku TCI/IP bloki te nazywane są pakietami i mogą przenosić dane użytkownika do standardowego rozmiaru 4 kilobajtów.
- przepustowość sieci – ilość informacji, która może być przesyłana jednocześnie przez jedno pasmo
- latencja – infrastruktura sieciowa ISO-OSI definiuje różne warstwy transportowe ISO-OSI. Każde przejście do innej warstwy i każde przekazanie zapytanie, np. przekazanie pakietu TCI/IP z jednego routera do następnego routera, pochłania czas.
- topologia – liczba węzłów i ich wzajemne połączenia wpływają na ścieżkę pakietu od źródła do miejsca docelowego
Ma to następujące konsekwencje:
- Na każde zapytanie można odpowiedzieć tak szybko, jak pozwala na to latencja. Nie można tego zmienić, niezależnie od wielkości przepustowości.
- Czas transmisji danych, które mieszczą się w ładunku pojedynczego pakietu, jest określany praktycznie wyłącznie przez latencję. Dlatego też przesyłanie danych w blokach mniejszych niż ten rozmiar przynosi efekt przeciwny do zamierzonego.
- Zwiększenie przepustowości pomaga zminimalizować czas transmisji dużych ilości powiązanych ze sobą danych. Jeśli przesyłane są duże ilości danych, powinny być one przesyłane w blokach, tak aby wykorzystać przepustowość.
Protokół
Aby komunikować się przez sieć, klient i serwer używają protokołu. Określa on sposób nawiązywania połączenia, wysyłania zapytań, odbierania odpowiedzi i kończenia połączenia. Co więcej, protokół definiuje również, jakie stany błędów mogą wystąpić i jak należy je obsługiwać. Następujące właściwości protokołu są szczególnie istotne:
- Protokół stanowy lub bezstanowy
Czy serwer przechowuje jeden stan dla każdego klienta, czy też każde zapytanie jest interpretowane jako nowe zapytanie od dowolnego klienta?
- Protokół szyfrowany lub nieszyfrowany
Czy klient i serwer tworzą szyfrowanie połączenia, czy też dane są przesyłane bez szyfrowania?
Protokoły stanowe znają zasadę stałego połączenia, podobnego do połączenia telefonicznego między dwoma uczestnikami. Połączenie nawiązywane jest raz, identyfikacja uczestników jest również przeprowadzana tylko raz, a wszystkie dalsze zapytania przesyłają tylko dane użytkownika. Kosztowne działania są zatem wykonywane tylko raz. Kluczowym protokołem należącym do tej kategorii jest protokół, z którym Object Request Broker komunikują się za pośrednictwem protokołu TCP/IP w przypadku CORBA.
Najbardziej znanym protokołem bezstanowym jest HTTP (Hypertext Transfer Protocol). W tym protokole zapytanie z parametrami jest wysyłane na adres, na który serwer odpowiada, wysyłając stronę HTML. Ponieważ serwer nie zna klienta ani użytkownika klienta, nie może rozpoznać następujących po sobie zapytań jako ciągłych. Nie stanowi to problemu w przypadku prostych stron internetowych, ale nie jest wystarczające do realizacji złożonych procesów.
Procesy takie jak bankowość internetowa, obsługa Comarch ERP Enterprise lub eksport dużych ilości danych wymagają przechowywania stanów dla każdego klienta. Jeśli z przyczyn technicznych użycie protokołu stanowego nie jest możliwe, należy zasymulować istnienie takiego protokołu. Wymaga to więcej logiki zarówno po stronie klienta, jak i serwera. Jeśli klient nie ma tej logiki i nie można jej rozszerzyć, należy to zrekompensować, na przykład poprzez ponowne uwierzytelnienie przy każdym zapytaniu.
Pod warunkiem, że klient posiada odpowiednią logikę (np. pliki cookie w przypadku klienta przeglądarki internetowej), w bardzo prostych przypadkach stan może być przechowywany na samym kliencie i wysyłany jako parametr przy każdym zapytaniu. W tym przypadku serwer jest bezstanowy, a zasoby są przechowywane tylko na czas przetwarzania zapytania. W bardziej złożonych przypadkach stan musi zostać zapisany na serwerze. W takim przypadku klient zwykle przechowuje i wysyła tylko „identyfikator sesji”, który został przypisany przez serwer po wstępnym uwierzytelnieniu.
Zapytania
Zapytania od klientów mogą być opisane przez następujące właściwości
- Liczba klientów
Ilu klientów wysyła zapytania równolegle?
- Częstotliwość zapytań
Ile zapytań składa klient w danym czasie?
- Oczekiwany czas odpowiedzi
Czy odpowiedź musi być szybko dostępna?
- Objętość danych
Jaka ilość danych jest wysyłana wraz z zapytaniem i jaka ilość danych jest oczekiwana w odpowiedzi?
- Format danych
Czy dane są zakodowane binarnie czy tekstowo?
Czy struktura danych jest zastrzeżona czy ustandaryzowana? Czy dane są szyfrowane w samym zapytaniu?
- Dostęp do odczytu lub zapisu
Czy klient chce tylko zapytać o dane, czy też chce je również zmienić? Jak aktualne muszą być odczytane dane?
- Połączenie synchroniczne lub asynchroniczne
Jakiej części odpowiedzi klient oczekuje natychmiast?
- Aktywne połączenie lub polling
Czy klient w ogóle wysyła określone zapytanie, czy też okresowo sprawdza obecność określonych danych w określonej lokalizacji?
- Połączenie bezstanowe lub stanowe
Czy serwer utrzymuje stan przez wiele zapytań?
Przed zaprojektowaniem lub wyborem interfejsu należy ustalić wszystkie te kwestie, ponieważ mają one znaczący wpływ na projekt. Poniżej wymieniono konsekwencje, jakie pociągają za sobą poszczególne właściwości.
Liczba klientów
W przypadku serwerów stanowych każdy zalogowany klient oznacza zarezerwowaną ilość pamięci głównej na serwerze na czas logowania.
Pamięć ta jest rzadko wymagana i jest przechowywana przez stosunkowo długi czas. W przypadku serwerów bezstanowych ilość pamięci na każde zapytanie jest dominująca i zwykle wyższa niż w przypadku zapytania do serwera stanowego. Jeśli nie można podzielić transmisji odpowiedzi do klienta na kilka połączeń, tymczasowo przydzielane są potencjalnie bardzo duże ilości pamięci głównej.
Częstotliwość zapytań
Jeśli oczekiwana jest duża liczba zapytań w danym czasie, a logika serwera na to pozwala, kilka jednostek wykonawczych na serwerze powinno przetwarzać zapytania klientów równolegle, aby osiągnąć niezbędną przepustowość.
Oczekiwany czas odpowiedzi
Aby latencja sieci nie była zbyt dużym problemem, zapytania od klientów powinny być zawsze łączone (tj. w bloki). Tylko w ten sposób można wykorzystać dostępną przepustowość sieci.
Objętość danych
W przypadku zapytania należy wysłać i zapytać tylko o te dane, które są faktycznie potrzebne. Na przykład w przypadku dostępu SQL do bazy danych ilość kolumn i wierszy w wyniku powinna być jak najmniejsza.
Format danych
Korzystanie z binarnych formatów danych zmniejsza ilość przesyłanych danych i jest preferowane w przypadku transmisji danych o dużej objętości. Zakres, w jakim dane binarne mogą być poprawnie interpretowane na różnych platformach, zależy także od innych czynników. Na przykład CORBA oferuje format binarny, który jest kompatybilny z różnymi platformami i który jest w razie potrzeby konwertowany do specyfiki platformy (Byte Order: little lub big endian, kodowanie znaków) przez warstwę pośrednią ORB.
Korzystanie z formatów tekstowych ma sens w przypadku niewielkich ilości danych oraz gdy zaangażowani klienci i serwery używają jedynie niewielkiej logiki lub bardzo różnych technologii (np. serwer C++ i klient Perl). Zasadniczo korzystanie z formatów tekstowych oznacza zwiększenie ilości danych, które mają być przesyłane przy tej samej ilości danych użytkownika. W zależności od formatu waha się ona od 1,5-4 (kodowanie Base64, kodowanie hex) do 10-15 (XML ze znacznikami początkowymi, końcowymi i meta). Zwiększona objętość danych może być częściowo skompensowana przez kompresję. Należy jednak rozważyć, czy wynikający z tego zwiększony wysiłek obliczeniowy i sprzętowy jest uzasadniony.
Korzystanie z zastrzeżonych struktur danych może mieć sens w przypadku systemów zamkniętych, w których klient i serwer pochodzą z tego samego źródła. W przypadku zmian w wymaganiach możliwa jest zatem szybsza i bardziej odpowiednia reakcja. W przypadku komunikacji wykraczającej poza granice własnego systemu zasadniczo właściwe jest korzystanie ze standardowych formatów (np. EDI).
Podczas komunikacji poza granicami własnego systemu szyfrowanie danych jest istotne, jeśli mają one być przesyłane niezabezpieczonymi kanałami, np. przez Internet za pośrednictwem protokołu HTTP lub jako wiadomość e-mail. Zastosowane tutaj procesy wymagają dodatkowej logiki i metadanych do szyfrowania na kliencie i serwerze.
Dostęp do odczytu lub zapisu
Dostęp do odczytu z reguły wymaga mniej zasobów niż dostęp do zapisu. Jeśli wynik odczytu nie musi być w 100% aktualny, można odstąpić od wymogu blokady i zwrócić dane z pamięci podręcznej.
Połączenie synchroniczne lub asynchroniczne
W przypadku połączenia synchronicznego klient oczekuje na natychmiastową odpowiedź od serwera. Jest to standardowy przypadek, ponieważ należy uwzględnić potwierdzenie, że zapytanie zostało przyjęte przez serwer. Jeśli rzeczywista odpowiedź nie jest potrzebna lub jest potrzebna w późniejszym czasie, serwer ma możliwość oczekiwania na dostępność zasobów.
Aktywne połączenie lub polling
Gdy serwer jest aktywnie wywoływany przez klienta, klient i serwer muszą komunikować się synchronicznie przynajmniej przez część czasu. Zaletą jest to, że serwer dostarcza dane tylko wtedy, gdy klient tego oczekuje. W przypadku pollingu klient okresowo sprawdza, czy dane, np. w postaci pliku, są dostępne w lokalizacji, do której obie strony mogą uzyskać dostęp bez wcześniejszego zapytania do serwera. Polling jest odpowiedni do przesyłania dużych ilości danych, które mogą być dostarczane przez serwer bez dodatkowych parametrów wejściowych. Informacje zwrotne o błędach na kliencie przesyłane do serwera zwykle nie mają miejsca. Istnieje również możliwość połączenia wariantów aktywne połączenie i polling.
W tym przypadku klient najpierw wysyła zapytanie do serwera, a dopiero potem rozpoczyna polling.
Połączenie bezstanowe lub stanowe
Podczas korzystania z połączeń bezstanowych uwierzytelnianie musi być wykonywane ponownie dla każdego zapytania, co ma negatywny wpływ, jeśli ich częstotliwość jest wysoka. Co więcej, w przypadku połączeń bezstanowych złożone procesy muszą być zawsze spakowane w jedno zapytanie, a cały wynik wysłany w jednej odpowiedzi. Prowadzi to do interfejsów złożonych z niewielu modułów. Ponieważ zapytania i odpowiedzi zwykle muszą być w całości przechowywane w pamięci głównej, przynajmniej tymczasowo, w celu przetworzenia zapytania, ten typ połączenia nie nadaje się również do przesyłania danych masowych. W przypadku połączeń stanowych overhead uwierzytelniania występuje tylko raz, złożone połączenia można podzielić na wielokrotnie wykorzystywane części, a przesyłanie parametrów wejściowych może odbywać się w kilku blokach.
Technologie interfejsów
W tej sekcji przedstawiono technologie interfejsów, które można wykorzystać do integracji systemów oprogramowania. Omówiono również poziom wsparcia, jaki Comarch ERP Enterprise oferuje w tym zakresie w standardzie.
Konkretne rozwiązanie problemu integracji będzie zazwyczaj oparte na połączeniu kilku z tych technologii, jak pokazano w niektórych przykładach.
Pliki
Gdy dane są przesyłane w formie plików, są one udostępniane w centralnej lokalizacji, do której serwer ma dostęp do zapisu, a klient przynajmniej do odczytu.
Pliki są również dobrze przystosowane do dużych ilości danych. Przykładem wykorzystania plików do wymiany danych między różnymi systemami jest BIS. Pozwala on na automatyczny import lub eksport danych.
Jedną z wad plików jest brak transakcji. To, kiedy plik staje się widoczny lub dostępny dla innego procesu i który z nich jest odczytywany, zależy w dużej mierze od systemu operacyjnego.
Comarch ERP Enterprise obsługuje system plików serwera aplikacji i Knowledge Store.
System plików serwera aplikacji
Comarch ERP Enterprise może uzyskiwać dostęp do systemu plików serwera aplikacji. W zależności od konfiguracji systemu operacyjnego dostępny jest zarówno lokalny system plików, jak i zdalne systemy plików („dyski sieciowe”).
Pliki są wywoływane przez ich ścieżkę. Należy zauważyć, że ścieżki plików zależą od komputera i jego systemu operacyjnego, a zatem mogą nie być używane na różnych serwerach aplikacji. Jednym ze sposobów na odzyskanie niezależności jest użycie ścieżek plików odnoszących się do folderu „semiramis/usr”. Ścieżka serwera plików do folderu „semiramis” może być wywoływana na każdym serwerze aplikacji Comarch ERP Enterprise w odpowiedniej dla niego notacji[1]. Odpowiednie zmienne („{semiramis}”) są już dostępne w tym celu w BIS, w danych wyjściowych dokumentów, jak również w reorganizacjach.
Knowledge Store
Knowledge Store zapewnia system plików obsługiwanych przez bazę danych. Ścieżki plików są ważne dla wszystkich serwerów aplikacji i są niezależne od systemu operacyjnego.
Oprogramowanie zewnętrzne może uzyskać dostęp do Knowledge Store za pośrednictwem WebDAV przy użyciu protokołu https. Umożliwia to dostęp bezpośrednio z komputerów klientów, które nie mają dostępu do systemu plików serwera aplikacji. Ponieważ WebDAV jest stosunkowo nowym standardem, ten rodzaj dostępu nie jest jeszcze oferowany przez wszystkie systemy operacyjne i aplikacje. Uwierzytelnianie odbywa się za pomocą certyfikatu lub hasła.
Dokładnie informacje można znaleźć w artykule Knowledge Store.
Bazy danych
SQL (dostęp bezpośredni)
Bezpośredni dostęp do baz danych jest możliwy z poziomu języka Java, na przykład za pośrednictwem interfejsu JDBC, przy czym dla danej bazy danych musi być używany sterownik JDBC. Dostęp do bazy danych może zależeć od systemu DBMS pomimo korzystania z JDBC.
Dostęp do zewnętrznych baz danych
Dostęp do zewnętrznych baz danych można uzyskać z poziomu Comarch ERP Enterprise. W tym celu można na przykład użyć standardowego interfejsu JDBC JDK.
Dostęp do baz danych Comarch ERP Enterprise
Z technicznego punktu widzenia możliwy jest również bezpośredni dostęp do baz danych Comarch ERP Enterprise. Nie jest to jednak zalecane z następujących powodów:
- Mapowanie Comarch ERP Enterprise Business Objects i odpowiednich typów danych jest specyficzne dla DBMS, a ich forma nie jest gwarantowana przez Comarch ERP Enterprise Software AG.
- Na poziomie DBMS istnieje techniczny model danych, w którym identyfikatory GUID są danymi binarnymi, a znaczniki czasu są przechowywane w kompaktowym formacie, którego żaden DBMS nie może bezpośrednio ocenić.
- Dostęp do odczytu omija caching Comarch ERP Enterprise. Zmniejsza to szybkość dostępów.
- Dostęp do zapisu omija caching i locking Comarch ERP Enterprise. Powoduje to odczyt potencjalnie niespójnych danych.
- Nie są przeprowadzane żadne kontrole autoryzacji, z wyjątkiem środków DBMS.
Zamiast tego należy użyć Comarch ERP Enterprise ODBC lub Comarch ERP Enterprise Persistence Service.
ODBC Comarch ERP Enterprise
ODBC Comarch ERP Enterprise umożliwia dostęp do baz danych Comarch ERP Enterprise poprzez zintegrowany z Comarch ERP Enterprise interfejs ODBC, który może być wykorzystywany przez oprogramowanie zewnętrzne. Dostęp jest niezależny od DBMS baz danych Comarch ERP Enterprise.
W przypadku ODBC Comarch ERP Enterprise należy zauważyć, że możliwy jest jedynie dostęp do baz danych w trybie odczytu. Z technicznego punktu widzenia dostęp wymaga użycia protokołu HTTPS.
ODBC Comarch ERP Enterprise udostępnia schemat bazy danych wzbogacony na podstawie metadanych Comarch ERP Enterprise. Jako atrybuty wirtualne zawiera klucze biznesowe z relacji, a także opis wartości valueset w języku naturalnym. Ponadto uwzględniono wirtualne tabele umożliwiające dostęp do Knowledge Store i obiektów dynamicznych. Możliwe jest również udostępnianie własnych danych dodatkowych i obliczeń w postaci wirtualnych tabel i funkcji wirtualnych. Dla każdego atrybutu w schemacie bazy danych dostępny jest możliwy do przetłumaczenia opis.
Uprawnienia na poziomie jednostki biznesowej są oceniane podczas uzyskiwania dostępu do ODBC Comarch ERP Enterprise.
Persystencja Comarch ERP Enterprise
Usługa persystencji Comarch ERP Enterprise może być używana tylko w ramach Comarch ERP Enterprise. Zdalny dostęp może być jednak realizowany za pomocą warstwy pośredniej.
W tym celu można na przykład utworzyć aplikację działającą w tle w Comarch ERP Enterprise, która jest następnie wywoływana zewnętrznie za pośrednictwem CORBA lub usług webowych. Niezależność od kanału wywołującego aplikacje w tle stanowi bezpieczną inwestycyjnie alternatywę, ponieważ programiści nie muszą zajmować się okolicznościami i zależnościami między wersjami konkretnego kanału.
Usługa persystencji Comarch ERP Enterprise jest niezależna od DBMS. Umożliwia ona odczyt i zapis, a także korzystanie z cachingu Comarch ERP Enterprise, blokad i opcjonalnie uprawnień. Obsługuje zarówno dostęp oparty na obiektach, jak i krotkach (ang. tuple), a także pojedyncze i masowe operacje. Umożliwia uruchamianie bardzo prostych aplikacji działających w tle, np. wykonywanie pojedynczego dostępu do bazy danych za pomocą Comarch ERP Enterprise -OQL, a także dowolne złożone logiki. Wykorzystując istniejące już klasy logiczne, można również osiągnąć wysoki stopień ponownego wykorzystania funkcjonalnego.
Łączenie zdalne
Zdalne wywołania są używane do synchronicznego wykonywania określonych działań w zdalnym systemie. Do połączenia używany jest określony protokół.
CORBA
CORBA to protokół do połączeń zdalnych, który może być używany na różnych platformach. CORBA może działać w sposób stanowy i dlatego nadaje się do przesyłania danych masowych.
Comarch ERP Enterprise jako serwer CORBA
Comarch ERP Enterprise zawiera serwer CORBA. Format danych interfejsu, zgodnie z którym muszą działać klienci, jest zdefiniowany w pliku IDL.
Wszelkie aplikacje działające w tle w Comarch ERP Enterprise mogą być wywoływane przez interfejs CORBA. Ponadto dostępna jest funkcja BIS (wymiana danych).
Gdy klienci logują się na serwera CORBA, odbywa się uwierzytelnianie i weryfikacja autoryzacji w Comarch ERP Enterprise.
Dokładnie informacje można znaleźć w artykule Interfejs CORBA.
Comarch ERP Enterprise jako klient CORBA
W ramach adaptacji, zdalny serwer CORBA może być również dostępny z poziomu Comarch ERP Enterprise. Comarch ERP Enterprise zawiera tylko ORB, powiązane biblioteki i dokumentację przykładowych klientów CORBA dla samego Comarch ERP Enterprise jako wsparcie w standardzie, ponieważ sposób dostępu jest całkowicie określony przez odpowiedni serwer CORBA.
Web service
Web service wykorzystuje protokół SOAP do połączeń zdalnych, który może być używany na różnych platformach. Inną opcją jest zaimplementowanie zasady REST podczas realizacji usługi sieciowej. Są one alternatywą dla CORBA, gdy nie ma potrzeby przesyłania danych masowych, ponieważ usługi sieciowe nie obsługują połączeń stanowych.
Comarch ERP Enterprise jako serwer web service’owy
Comarch ERP Enterprise zawiera serwer web sevice’owy. Wymaga on użycia protokołu HTTPS. Określa on za pomocą pliku WSDL format danych interfejsu (ew. SOAP), z którego muszą korzystać klienci.
Za pośrednictwem interfejsu web service’u funkcjonalność jest dostępna analogicznie do serwera CORBA.
Gdy klienci logują się na serwer web service’u, odbywa się uwierzytelnianie za pomocą hasła lub certyfikatu użytkownika i weryfikacja uprawnień w Comarch ERP Enterprise.
Comarch ERP Enterprise jako klient web service’owy
Adaptacje w Comarch ERP Enterprise mogą również uzyskiwać dostęp do zdalnego serwera web service’u. Comarch ERP Enterprise zawiera powiązane biblioteki i dokumentację przykładowych klientów web service’u dla samego Comarch ERP Enterprise jako wsparcie w standardzie, ponieważ sposób dostępu jest całkowicie określony przez odpowiedni serwer web service’u.
Protokoły macierzyste (navite protocols)
Możliwe jest także korzystanie z innych protokołów, takich jak TCP/IP, FTP lub Java RMI. Są one szczególnie interesujące w przypadku adresowania zewnętrznych serwerów z Comarch ERP Enterprise za pośrednictwem jego interfejsów. Comarch ERP Enterprise nie oferuje jednak tutaj żadnego wsparcia w standardzie.
Jeśli adaptacja w Comarch ERP Enterprise ma na celu realizację serwera dla protokołu macierzystego, zaleca się zamiast tego stworzenie tego serwera poza Comarch ERP Enterprise i umożliwienie mu dostępu do Comarch ERP Enterprise za pośrednictwem CORBA.
Połączenie różnych technologii
Comarch ERP Enterprise może dokonywać zapisów w tej tabeli bazy danych poprzez JDBC. Usługa lub zdalnie wywoływana aplikacja w tle może teraz w efekcie uzyskać dane za pomocą usługi persystencji Comarch ERP Enterprise, przygotować je i zapisać w tej tabeli za pośrednictwem JDBC. Stanowi to następującą zaletę: wszystkie funkcje Comarch ERP Enterprise zwiększające wydajność, np. caching semiramis i Perpared-Statement mogą być wykorzystywane do wyszukiwania danych.
Kwestie związane z wydajnością
Ochrona przed wąskimi gardłami zasobów
Systemy serwerowe, takie jak Comarch ERP Enterprise, nie mogą działać z optymalną wydajnością, jeśli zbyt wiele połączeń zdalnych jest przetwarzanych jednocześnie przez serwer aplikacji. Można tego uniknąć, podejmując odpowiednie działania.
Każda sesja, którą klient otwiera w systemie Comarch ERP Enterprise za pośrednictwem połączeń zdalnych, zużywa zasoby, takie jak pamięć, czas obliczeniowy i połączenia z bazą danych na serwerze aplikacji, z którym łączy się klient. Jeśli scenariusz wymaga bardzo dużej liczby klientów, z których wszyscy są stale połączeni z serwerem CORBA, mogą wystąpić wąskie gardła (obniżenie przepustowości) zasobów. Krytycznymi zasobami w tym przypadku są głównie sesje (i połączenia z bazą danych). Każda sesja zajmuje wątek Comarch ERP Enterprise od momentu jej utworzenia, tj. pamięć sterty (ang. heap) dla stosu wątków (threadstack) i zasobów macierzystych w zależności od systemu operacyjnego. Podczas przetwarzania zapytania wykorzystywany jest wątek. Jeśli dane muszą zostać odczytane z bazy danych w celu przetworzenia zapytania CORBA, wykorzystywane są dodatkowe tymczasowe połączenia z bazą danych.
Pamięć, wątki i połączenia z bazą danych są ograniczonymi zasobami na serwerze aplikacji. Wąskie gardło zasobów prowadzi do wydłużenia czasu przetwarzania połączenia zdalnego. W najgorszym przypadku stabilność całego serwera aplikacji może być zakłócona.
Istnieje kilka sposobów na uniknięcie wąskich gardeł w zasobach. Podstawową kwestią jest koordynacja dostępu do krytycznych zasobów w celu uniknięcia zbyt wielu dostępów na raz.
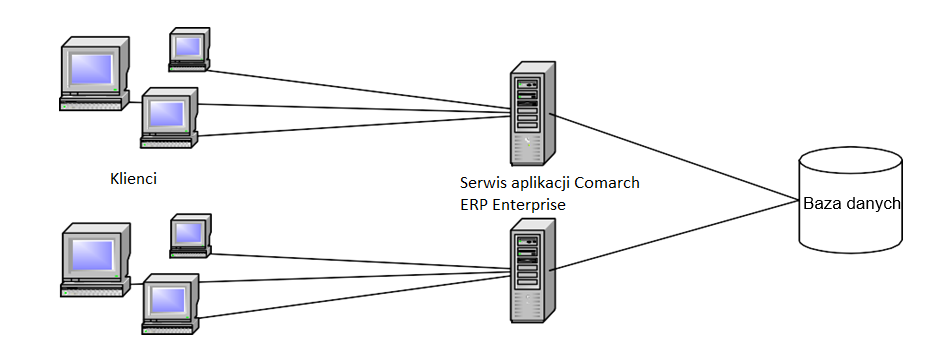
W pierwszym rozwiązaniu przedstawionym na rysunku poniżej, kilka serwerów aplikacji Comarch ERP Enterprise jest używanych do dystrybucji dostępu klientów. W przykładzie użyto klientów CORBA, ale opisany pomysł ma ogólne zastosowanie.
Poprzez dystrybucję danych na kilka serwerów aplikacji Comarch ERP Enterprise, zmniejszone jest zużycie pamięci na serwer aplikacji. Rozwiązanie to może jednak prowadzić do dużego obciążenia bazy danych, jeśli wiele do serwera aplikacji w tym samym czasie dociera większa ilość zapytań.
W drugim możliwym rozwiązaniu wykorzystywany jest niezależny proces (CORBA Proxy Queue), który jest niezależny od Comarch ERP Enterprise. Zapytania klientów trafiają najpierw do tego procesu, który kolejkuje je, a następnie w tym samym czasie przekazuje ograniczoną ich liczbę do Comarch ERP Enterprise. Ogranicza to liczbę sesji CORBA i liczbę połączeń z bazą danych w Comarch ERP Enterprise. CORBA Proxy Queue działa jako serwer dla zdalnych połączeń oraz jako klient CORBA. Implementacja takiej kolejki może być zatem wykonana w dowolnym języku programowania, który jest dostosowany do danego przypadku.
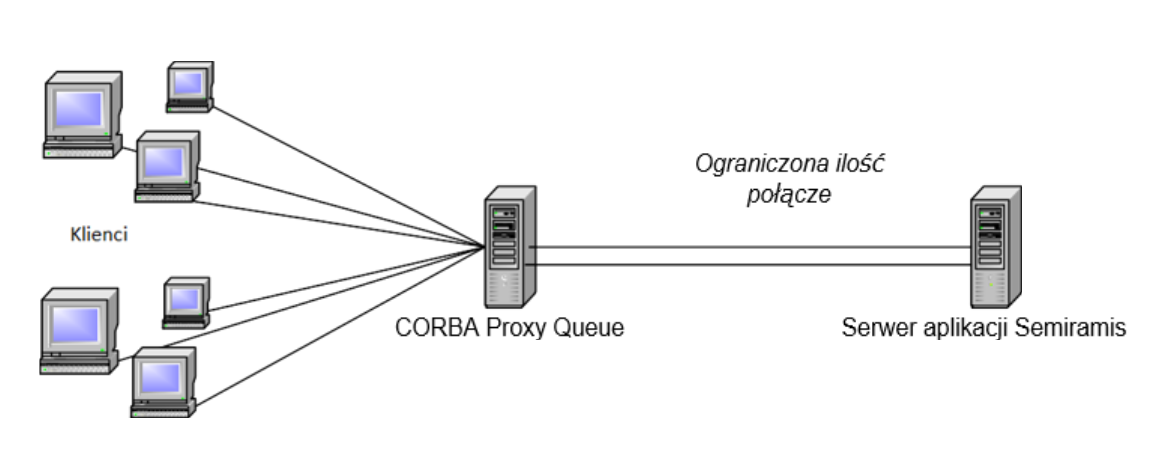
W obu tych rozwiązaniach zakłada się, że każdy proces działa na własnym komputerze i tym samym ma wyłączny dostęp do jego ograniczonych zasobów. Rozwiązanie CORBA Proxy Queue również powinno działać także na własnym komputerze.
Nawet podczas tworzenia połączenia z Comarch ERP Enterprise za pośrednictwem połączeń zdalnych, testy powinny być przeprowadzane z uwzględnieniem oczekiwanej liczby klientów. W ten sposób można określić, czy środki potrzebne do ochrony zasobów w danym przypadku są konieczne.



