OPT057 – Strojenie wydajnościowe baz MS SQL dla Comarch ERP Optima
Wprowadzenie
Serwer bazy danych jest centralnym miejscem dla całej instalacji Comarch ERP Optima i ma bardzo duże znaczenie dla wydajnej jej pracy. Dlatego bardzo ważne jest odpowiednie skonfigurowanie serwera zarówno pod względem sprzętowym, doboru właściwego oprogramowania oraz jego ustawień. Dodatkowo z biegiem czasu i działalnością klienta spływają nowe dane słownikowe oraz dokumenty, co powoduje przyrost bazy danych. Ważne jest więc monitorowanie stanu serwera SQL i odpowiednie reagowanie w celu zapewnienia jak najlepszej wydajności.
Niniejszy biuletyn zawiera wytyczne dla konfiguracji serwera bazy danych dedykowanego do pracy z Comarch ERP Optima. Przedstawiono w nim również podstawowe metody diagnozy problemów wydajnościowych oraz sposoby optymalizacji. W ostatnim rozdziale znajduje się obszerny opis cyklicznych czynności administracyjnych, których celem jest utrzymanie serwera SQL w dobrej kondycji. Do biuletynu dołączone są skrypty, które pozwalają zautomatyzować cykliczne czynności administracyjne dla wersji Express serwera SQL.
Planowanie instalacji
Dobór konfiguracji sprzętowej dla serwera bazy danych
Serwer bazy danych jest wrażliwym elementem, którego awaria może spowodować przestój całej firmy oraz duże straty finansowe, dlatego warto zainwestować w markowy, sprawdzony sprzęt. Taki serwer w atrakcyjnych cenach można np. nabyć w ramach Zintegrowanej Oferty Comarch.
Konfiguracja sprzętowa
Przy doborze serwera bazy danych należy zwrócić szczególną uwagę to, aby zapewniał on niezawodną pracę i bezpieczeństwo przechowywanych danych. Dlatego warto, aby jak najwięcej komponentów było nadmiarowych usuwając pojedyncze ogniwa awarii. Czyli dobrze jest zastosować podwójne zasilacze oraz zasilanie awaryjne (UPS) pozwalające na prawidłowe zamknięcie systemu w momencie braku prądu.
Jeżeli chodzi o wydajność to przede wszystkim należy zwrócić na ilość pamięci RAM oraz szybkość podsystemu dyskowego. Procesor zwykle odgrywa mniejsze znaczenie. Jednakże powinien zawierać rdzenie nowej generacji (Intel Nehalem lub lepszy) i taktowaniu przynajmniej 2 GHz.
Im więcej dostępnej pamięci tym lepiej, oczywiście ze względu na koszty, jej ilość musi być dobrana do zapotrzebowania, bazując na wielkości instalacji, czyli ilości użytkowników, wielkości baz danych oraz ich ilości. Orientacyjne ilości pamięci RAM dla różnych konfiguracji zostały podane w Podręczniku konfiguracji dla bieżącej wersji Comarch ERP Optima. Później oczywiście należy obserwować liczniki serwera i sprawdzać, czy nie ma potrzeby jej zwiększenia. Informacje na temat przykładowych liczników, na które warto zwrócić uwagę podano w punkcie 4. Diagnoza problemów wydajnościowych.
Podsystem dyskowy powinien być zabezpieczony przed awariami poprzez odpowiednią konfigurację. Zalecana konfiguracja to przynajmniej Raid 1 (mirror) dla wolumenu obsługującego system oraz w miarę możliwości Raid 10 dla wolumenu przechowującego dane. Dodatkowo należy zwrócić uwagę, aby kontroler dyskowy posiadał podtrzymywanie bateryjne, które umożliwia zastosowanie opcji write-back przyspieszającej działanie podsystemu dyskowego.
Najczęściej przyjmowaną jednostką wydajności podsystemu dyskowego jest IOPS[1] (ang. Input/Output Operations Per Second, IOPS), czyli ilość operacji wejścia wyjścia na sekundę. Jako operację wejścia/ wyjścia rozumie się odczyt lub zapis fragmentu danych, najczęściej o rozmiarze 4 kB.
Poniżej znajdują się orientacyjne dane dotyczące wydajności różnych podsystemów dyskowych:
| Dysk | Orientacyjna wartość IOPS[2] |
|---|---|
| Dysk Sata 5400 | ~50-80 |
| Dysk Sata 7200 | ~75-100 |
| Dysk SAS 10k | ~140 |
| Dysk SAS 15k | ~175-210 |
| Dysk SSD | ~400-1000000[3] |
Wymagania co do podsystemu dyskowego zależą od wielkości instalacji to znaczy wielkości bazy oraz ilości równoczesnych użytkowników.
Jako zgrubną zasadę można przyjąć, że dla mniejszych baz danych (<2 GB) należy zarezerwować około 15-25 IOPS dla użytkownika. Natomiast dla większych baz (> 2 GB) dla jednego użytkownika należy przeznaczyć 25-40 IOPS lub więcej.
Jak widać Rozwiązaniem godnym polecenia jest zastosowanie dysków SSD. Przy czym należy pamiętać o zabezpieczeniu ich przed awarią np. poprzez konfigurację RAID 1. Bardziej szczegółowe informacje dotyczące określenia wymagań aplikacji do podsystemu dyskowego można znaleźć w poniższym odnośniku: http://msdn.microsoft.com/en-us/library/ee410782(v=sql.100).aspx
Porównanie wydajności pracy Comarch ERP Optima z dyskami SSD i SATA znajduje się w biuletynie technicznym: OPT076 – Porównanie wydajności HDD vs SSD w Comarch ERP Optima.pdf, który jest dostępny na Indywidualnych Stronach Partnerów (https://www.erp.comarch.pl//partnerzy/default.aspx).
Biura rachunkowe:
Kilka mniejszych baz danych słabiej obciąża serwer niż jedna duża. Dlatego przy skalowaniu serwera SQL dla biura rachunkowego należy przede wszystkim sprawdzić jaka będzie wielkość największej bazy danych i pod nią dobierać konfigurację plus zabezpieczyć dodatkową ilość pamięci RAM współmiernie do ilości baz danych. Raczej nie należy przekraczać ilości 50 baz danych o wielkości do 200 MB na rdzeń procesora.
Edycje serwera SQL
Bardzo duże znaczenie dla wydajnej pracy serwera SQL jest właściwe dobranie edycji serwera SQL. Comarch ERP Optima jest dystrybuowana z darmową serwera SQL o nazwie Express. Edycja ta posiada określone ograniczenia co do możliwości wykorzystania zasobów komputera, na którym jest zainstalowana. Szczegóły znajdują się w poniższej tabeli.
| Edycja | Maksymalna ilość pamięci RAM (dla puli buforów) | Maksymalna wielkość bazy danych | Ilość obsługiwanych procesorów |
|---|---|---|---|
| SQL 2008 Express | 1 GB* | 4 GB | 1 |
| SQL 2008 R2 Express | 1 GB* | 10 GB | 1 |
| SQL 2012 / 2014 Express | 1 GB* | 10 GB | 1 (maksymalnie 4 rdzenie) |
| SQL 2008 R2 Workgroup | 3 GB | Bez ograniczeń (524 PB) | 2 |
| SQL 2008 R2 Standard | 64 GB | Bez ograniczeń (524 PB) | 4 |
| SQL 2012 Standard / BI | 64 GB | Bez ograniczeń (524 PB) | 4 procesory (do 16 rdzeni) |
| SQL 2014 Standard / BI | 128 GB | Bez ograniczeń (524 PB) | 4 procesory (do 16 rdzeni) |
Źródło: http://www.microsoft.com/sqlserver/en/us/product-info/compare.aspx
*Badania niezależne od Producenta pokazują, że wersja Express może wykorzystać maksymalnie 1,4 GB RAM (http://sqlgeek.pl/2010/08/23/pl-sql-server-limity-w-sql-server-2008-r2-express-edition/)
Architektura 32 bit, a 64 bit.
Obecnie obowiązującą architekturą jest architektura 64 bitowa i w miarę możliwości zalecana jest aktualizacja do niej środowisk 32 bitowych, które posiadają ograniczenia związane z ilością adresowanej pamięci, a także różnymi komplikacjami w jej alokacji. W podstawowej konfiguracji proces 32 bitowy może maksymalnie zaadresować 2 GB pamięci, przy zastosowaniu specjalnego przełącznika można tą wartość zwiększyć do 3 GB, ale dzieje się to kosztem ilości dostępnej przestrzeni adresowej dla systemu operacyjnego dlatego należy robić to ostrożnie. Serwer SQL może dodatkowo wykorzystać mechanizm AWE, który pozwala na systemach 32 bitowych wyjść poza zakres 4 GB pamięci. Szczegóły można znaleźć w archiwalnym biuletynie technicznym OPT041-Wydajność Comarch OPT!MA a procesory wielordzeniowe i 64 bitowe, który jest dostępny na stronach walidowanych.
Na systemach 64 bitowych warto zwrócić uwagę, aby instalować również serwer SQL w wersji 64 bitowej ponieważ jego 32 bitowy odpowiednik będzie w stanie wykorzystać jedynie 4 GB z dostępnej pamięci nawet w edycji Standard.
Więcej informacji na temat możliwości wykorzystania pamięci operacyjnej przez poszczególne wersje systemów operacyjnych Windows można znaleźć tutaj:
http://msdn.microsoft.com/en-us/library/windows/desktop/aa366778(v=vs.85).aspx
Konfiguracja serwera SQL
Większość parametrów serwera SQL należy pozostawić bez zmian, ponieważ domyślne wartości są optymalne dla większości warunków pracy. Sugerujemy jednakże zwrócić uwagę na
Maksymalną / Minimalna ilość wykorzystywanej pamięci RAM.
Minimalna i Maksymalna ilość wykorzystywanej pamięci RAM>
Parametr minimalnej i maksymalnej ilości wykorzystanej pamięci RAM odnosi się wyłącznie do jednego z komponentów serwera SQL, czyli puli buforów. Jest to kluczowy element jednakże, przy rezerwowaniu pamięci dla puli buforów należy wziąć pod uwagę również inne składniki samego serwera SQL jak i samego systemu operacyjnego.
Minimum Server Memory
Domyślną wartością parametru Minimum Server Memory jest zero, co oznacza, że serwer będzie dynamicznie zarządzał dostępną pamięcią RAM dla puli buforów. Ustawienie tego parametru powyżej zera oznacza, że serwer SQL nie będzie mógł zwolnić tej pamięci w razie potrzeby. Z drugiej strony w środowisku, gdzie pracuje więcej aplikacji prócz samego serwera SQL może być konieczne zarezerwowanie niezbędnego minimum pamięci, ponieważ niemożność zaalokowania niezbędnego minimum spowoduje konieczność korzystania z pliku wymiany na dysku twardym i znaczną degradację wydajności Serwera SQL. Na komputerach dedykowanych do pracy tylko z serwerem SQL zaleca się pozostawienie domyślnej wartości tego parametru.
Maximum Server Memory
Domyślna wartością tego parametru to: 2147483647 MB, co oznacza że Server SQL będzie chciał zająć całą dostępną pamięć na komputerze. Może to niestety prowadzić do spadku wydajności całego środowiska poprzez to, że pula buforów zajmie pamięć potrzebną do działania systemu operacyjnego lub innych komponentów serwera SQL. Dlatego zaleca się ograniczenie tej pamięci rezerwując niezbędną przestrzeń do działania systemu operacyjnego i pozostałych elementów serwera SQL (oraz ewentualnie dla dodatkowych aplikacji pracujących na tym systemie).
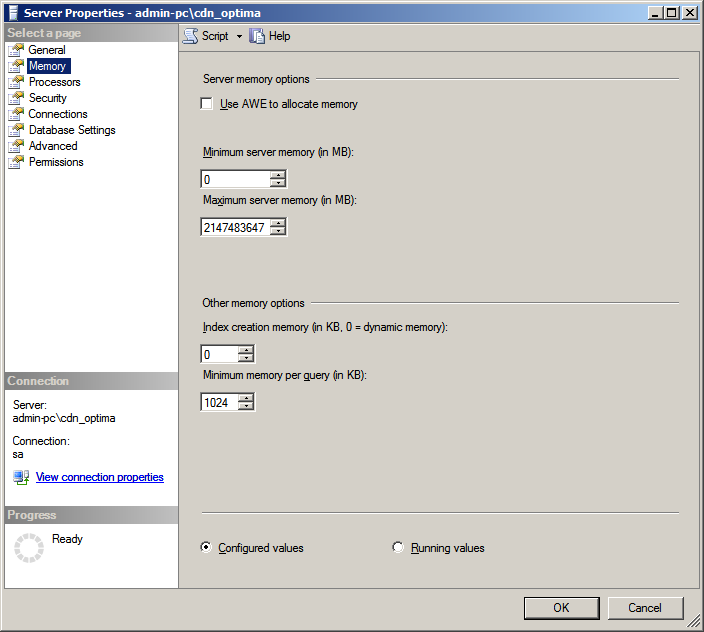
Poniżej znajdują się sugestie ustawień parametru Maximum Server Memory (przy założeniu, że na serwerze nie pracują dodatkowe aplikacje oraz inne moduły serwera SQL takie jak wyszukiwanie pełnotekstowe, analizy czy raporty). Dane te oczywiście dotyczą wersji, które nie posiadają wbudowanych ograniczeń tak jak wersja Express. Dla wersji Express biorąc pod uwagę wcześniej podane informacje można ustawić Maximum Server Memory na 1400 MB.
| Pamięć fizyczna | Maximum Server Memory |
|---|---|
| 2 GB | 1500 MB |
| 4 GB | 3200 MB |
| 6 GB | 4800 MB |
| 8 GB | 6400 MB |
| 12 GB | 10000 MB |
| 16 GB | 13500 MB |
| 24 GB | 21500 MB |
Inne parametry
Optimize for Ad hoc Workloads
Włączenie parametru „Optimize for Ad hoc Workloads” pozwala na lepsze wykorzystanie dostępnej pamięci RAM w sytuacji, gdy na serwerze generowane jest wiele zapytań, które nigdy więcej lub bardzo rzadko są uruchamiane ponownie. Parametr ten powoduje, że plany dla zapytań „ad hoc” nie są zapisywane w pamięci podręcznej do późniejszego wykorzystania. Zapisywany jest tylko ich mały fragment, cały plan jest zapisywany dopiero przy powtórnym wykonaniu tego samego zapytania. W ten sposób oszczędzana jest pamięć RAM, przez co może być ona wykorzystana przez serwer SQL do innych celów, a co za tym idzie zwiększa się jego wydajność.

Zaleca się włączenie tego parametru przy pracy z Comarch ERP Optima. Opcja ta jest dostępna od wersji SQL 2008.
Zajętość pamięci planów dla zapytań można sprawdzić poniższym zapytaniem:
select objtype,
count(*) as number_of_plans,
sum(cast(size_in_bytes as bigint))/1024/1024 as size_in_MBs,
avg(usecounts) as avg_use_count
from sys.dm_exec_cached_plans
group by objtype
Poniższy wynik wskazuje, że plany typu „Adhoc” zajmują 1439 MB pamięci, co jest stosunkowo dużą wartością więc warto włączyć opcję „Optimize for ad hoc workloads”.

Za pomocą komendy:
DBCC FREESYSTEMCACHE('SQL Plans')
można wyczyścić pamięć podręczną planów dla planów typu Adhoc.
Diagnoza problemów wydajnościowych
Temat diagnozy wydajności serwera SQL jest bardzo obszerny, jednakże poniżej wybrano kilka podstawowych wskaźników, które warto sprawdzić, gdy występują problemy wydajnościowe.
Wszystkie poniższe wskaźniki dostępne są z poziomu systemu operacyjnego.
Narzędzia administracyjne \ Monitor wydajności
| Nazwa parametru | Zalecane wartości | Zalecane działania |
|---|---|---|
| Procesor: Czas procesora [%] | < 80% | Jeżeli wartość tego parametru przynajmniej kilka razy dziennie na dłuższy czas przekracza zalecaną wartość należy zaplanować dołożenie drugiego procesora lub jego wymianę na wydajniejszy |
| System: Processor Queue Lenght | < 2 (dla rdzenia) | Jeżeli wartość tego parametru przynajmniej kilka razy dziennie na dłuższy czas przekracza zalecaną wartość należy zaplanować dołożenie drugiego procesora lub jego wymianę na wydajniejszy |
| Pamięć: Strony/s | < 20 | Zbyt mała ilość dostępnej pamięci RAM |
| Pamięć: Dostępne bajty | > 300 | Zbyt mała ilość dostępnej pamięci RAM |
| Dysk fizyczny: Czas dysku [%] (poddzielone przez ilość dysków) | < 55% | Wysoka wartość tego parametru może wskazywać na nie wystarczająco szybki podsystem dyskowy lub zbyt małą ilość dostępnej pamięci RAM. |
| Dysk fizyczny: Średnia długość kolejki dysku (podzielone przez ilość dysków) | < 2 | Wysoka wartość tego parametru może wskazywać na nie wystarczająco szybki podsystem dyskowy lub zbyt małą ilość dostępnej pamięci RAM. |
| (najlepiej w okolicach zera) | ||
| SQL Server Buffer: Buffer Cache Hit Ratio | > 90% | Zbyt mała ilość dostępnej pamięci RAM dla serwera SQL |
| (najlepiej w granicach 99%) | ||
| Page life expectancy | > 300 | Zbyt mała ilość dostępnej pamięci RAM dla serwera SQL |
Zbyt mała ilość dostępnej pamięci dla serwera SQL może wynikać z poniższych czynników:
- Za mało pamięci w serwerze
- Ograniczenia wersji Express
- Nieprawidłowo skonfigurowany parametr Max Server Memory
- Ograniczenia architektury 32 bitowej
Importy dużych dokumentów poprzez pracę rozproszoną lub inne mechanizmy mogą na dłuższy czas blokować dostęp do tabel, a przez co powodować wydłużenie czasu operacji dla pozostałych użytkowników. Dlatego zaleca się, aby szczególnie duże importy były wykonywane poza godzinami pracy innych użytkowników.
Jeżeli jakiś scenariusz działania okazuje się szczególnie wolny prosimy o opisanie go krok po kroku i zgłoszenie go przez System Obsługi Zgłoszeń (SOZ).
Optymalizacja dużych baz danych
Program jest dostosowany do pracy w większości warunków, jednakże niektóre szczególnie duże bazy ze względu na specyficzny rozkład danych w tabelach mogą wymagać dodatkowej optymalizacji. Za duże bazy danych uważamy te, które mają rozmiar rzędu kilku gigabajtów lub więcej. Przed przystąpieniem do poniższych czynności dobrze upewnić się, czy serwer jest prawidłowo skonfigurowany i posiada odpowiednią ilość zasobów.
Wyszukiwanie brakujących indeksów
Microsoft SQL Server posiada wbudowane mechanizmy, które pozwalają określić orientacyjnie jakich indeksów może brakować. W tym celu można uruchomić na serwerze następujące zapytanie:
select d.*
, s.avg_total_user_cost
, s.avg_user_impact
, s.last_user_seek
,s.unique_compiles
from sys.dm_db_missing_index_group_stats s
,sys.dm_db_missing_index_groups g
,sys.dm_db_missing_index_details d
where s.group_handle = g.index_group_handle
and d.index_handle = g.index_handle
order by s.avg_user_impact desc
go
Zapytanie to najlepiej uruchomić po dłuższej pracy użytkowników wykonujących swoje zadania z Comarch ERP Optima w szczególności w obszarach, gdzie zauważają problemy wydajnościowe. Należy pamiętać, że dane o brakujących indeksach są usuwane po restarcie serwera SQL.
Przykładowy wynik powyższego zapytania (pominięto kilka kolumn, aby zachować czytelność).

Po pierwsze patrzymy na kolumny avg_user_impact oraz avg_total_user_cost, podają one zysk jaki można uzyskać przy zastosowaniu danego indeksu. Pierwszy z nich avg_user_impact wskazuje na procentową poprawę w zmniejszeniu kosztu wykonania zapytań użytkownika . Drugi natomiast avg_total_user_cost podaje całkowity zysk w koszcie wykonywanych przez użytkownika zapytań.
Należy mieć również świadomość, że podejście to ma również swoje ograniczenia. Najbardziej istotne z nich jest takie, że podane dane należy traktować jako sugestię, a nie jako konieczność. Pozostałe ograniczenia podane są tutaj: http://msdn.microsoft.com/en-us/library/ms345485(v=sql.105).aspx
Poniżej znajduje się skrypt używany przez Dział Wsparcia Microsoft:
(http://msdn.microsoft.com/en-us/library/ms345421.aspx)
PRINT 'Missing Indexes: '
PRINT 'The "improvement_measure" column is an indicator of the (estimated) improvement that might '
PRINT 'be seen if the index was created. This is a unitless number, and has meaning only relative '
PRINT 'the same number for other indexes. The measure is a combination of the avg_total_user_cost, '
PRINT 'avg_user_impact, user_seeks, and user_scans columns in sys.dm_db_missing_index_group_stats.'
PRINT ''
PRINT '-- Missing Indexes --'
SELECT CONVERT (varchar, getdate(), 126) AS runtime,
mig.index_group_handle, mid.index_handle,
CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) AS improvement_measure,
'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' + CONVERT (varchar, mid.index_handle)
+ ' ON ' + mid.statement
+ ' (' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '')
+ ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement,
migs.*, mid.database_id, mid.[object_id]
FROM sys.dm_db_missing_index_groups mig
INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle
WHERE CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) > 10
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
PRINT ''
GO
Przygotowuje on od razu definicję indeksu wraz z przykładową nazwą sortując indeksy po polu „miara poprawy”, które jest wyliczane biorąc pod uwagę wspomniane wcześniej kolumny: avg_total_user_cost, avg_user_impact, oraz dodatkowo user_seeks i user_scans z sys.dm_db_missing_index_group_stats.
Należy przygotować skrypt dodający oraz usuwający dodawane indeksy, ponieważ dodatkowe indeksy uniemożliwią wykonanie konwersji do nowej wersji programu. Po skonwertowaniu bazy można na nowo dodać przygotowane indeksy
Dodane indeksy mogą mieć negatywny wpływ na operacje dodawania, aktualizowania i usuwania rekordów w bazie, dlatego należy przetestować ich wpływ na całościowe funkcjonowanie programu.
Database Engine Tuning Advisor
Pełne wersje Microsoft SQL Server posiadają dodatkowe narzędzie o nazwie Database Engine Tuning Advisor. Pozwala ono również na dodanie brakujących indeksów na podstawie zapisanego wcześniej ruchu SQL. Ruch ten można zapisać za pomocą innego narzędzia Microsoft SQL Server Profiler, które również jest dostępne w pełnej wersji serwera SQL.
W skrócie proces optymalizacji można przedstawić w poniższych krokach:
- Zapis ruchu za pomocą Microsoft SQL Server Profiler
- Przygotowanie optymalizacji w Database Engine Tuning Advisor
- Zapis rekomendacji
- Przygotować plik usuwający dodatkowe indeksy i statystyki
- Utworzenie dodatkowych indeksów i statystyk
Zapis ruchu za pomocą Microsoft SQL Server Profiler
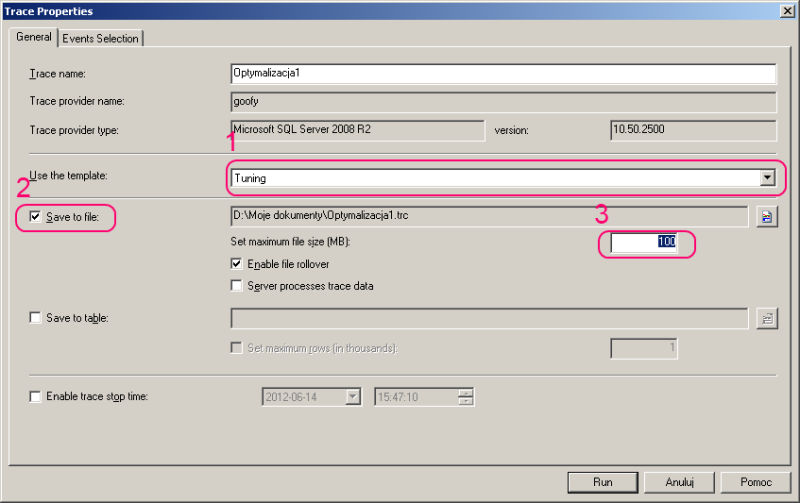
Po wyborze nowego trace’a należy wskazać szablon Tuning, zaleca się zapisać plik od razu na dysk i ograniczyć jego rozmiar np. do 100 MB. Zaznaczony domyślnie parametr Enable file rollover powoduje utworzenie nowego pliku po osiągnięciu zadanego limitu. Zbyt duże pliki znacząco zwiększają czas analizy przez Database Engine Tuning Advisor.
Przygotowanie optymalizacji w Database Engine Tuning Advisor
Po zakończeniu zapisu ruchu przechodzimy do Database Engine Tuning Advisor.
Na pierwszej zakładce „General” nowej sesji wskazujemy plik (File) jako źródło ruchu do optymalizacji oraz podajemy bazę do analizy. Na drugiej zakładce „Tuning Options” pozostawiamy domyślne parametry.
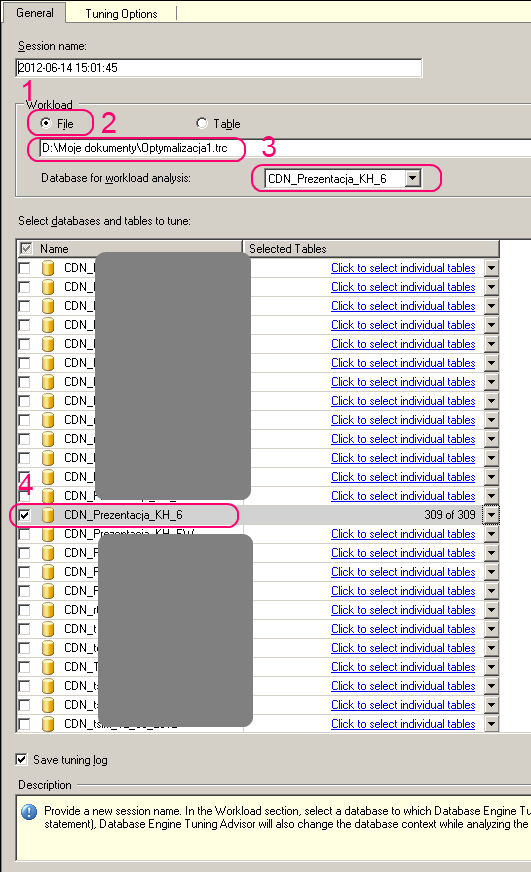
W celu uruchomienia analizy klikamy ikonę Start Analysis (menu Actions \ Start Analysis)

Zapis rekomendacji
Po zakończonej analizie otrzymujemy szacowany wzrost wydajności oraz rekomendacje co do założenia dodatkowych indeksów i statystyk. Przygotowane rekomendacje należy zapisać w pliku poprzez przejście do menu Action \ Save Rekommendations.
Z tak przygotowanych rekomendacji można wybrać kilka lub wszystkie indeksy i statystyki, jednakże należy pamiętać, że każdy dodatkowy indeks będzie spowalniał operacje dodawania, aktualizowania i usuwania rekordów w tabeli, której on dotyczy. Następnie wybrane indeksy i statystyki należy zapisać w skrypcie nadając im nazwy, które będą łatwe do identyfikacji. Na koniec należy również przygotować skrypt, który będzie usuwał niestandardowe indeksy i statystyki, ponieważ trzeba je usuwać przed przystąpieniem do konwersji bazy danych. Po zakończeniu konwersji można je ponownie dodać.
Należy przygotować skrypt dodający oraz usuwający dodawane indeksy, ponieważ dodatkowe indeksy uniemożliwią wykonanie konwersji do nowej wersji programu. Po skonwertowaniu bazy można na nowo dodać przygotowane indeksy.
Dodane indeksy mogą mieć negatywny wpływ na operacje dodawania, aktualizowania i usuwania rekordów w bazie, dlatego należy przetestować ich wpływ na całościowe funkcjonowanie programu.
Cykliczne czynności administracyjne
Cykliczne czynności administracyjne są bardzo istotne z punktu widzenia bezpieczeństwa jak i wydajności serwera SQL i należy traktować je jako obowiązkowe, a nie opcjonalne.
Do najważniejszych czynności administracyjnych można zaliczyć:
- Kopia bezpieczeństwa
- Cykliczne odtwarzanie kopii bezpieczeństwa w celu weryfikacji poprawności backupu.
- Optymalizacja indeksów
- Kontrola poprawności baz danych DBCC CHECKDB
Dla wydajności szczególnie dla większych baz duże znaczenie ma cykliczna optymalizacja indeksów w bazie, które ze względu na swoją defragmentację będą spowalniać pracę Comarch ERP Optima.
W kolejnych podrozdziałach opisano w jaki sposób można zautomatyzować niektóre z wymienionych czynności administracyjnych.
Maintenance Plan – zautomatyzowane strojenie dla pełnych wersji MS SQL
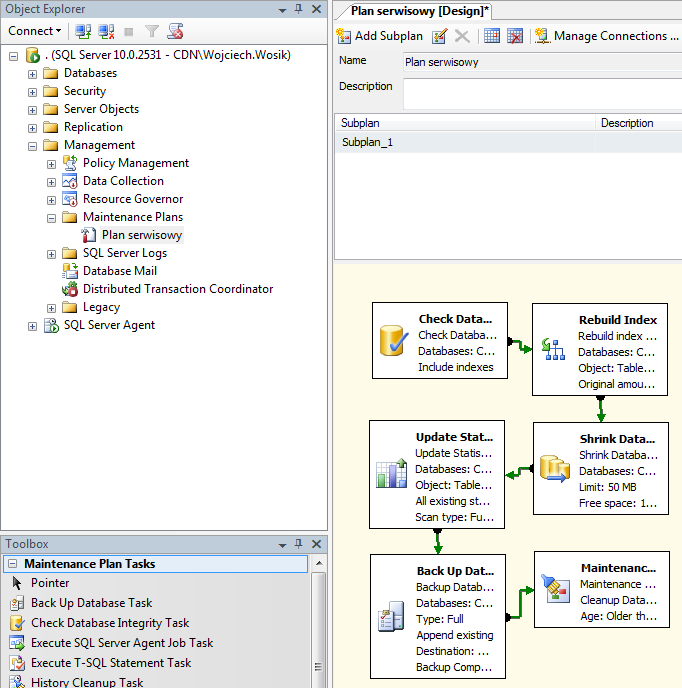
Każda pełna wersja MS SQL posiada mechanizm automatyzacji procesów, których zadaniem jest optymalizowanie bazy danych oraz kreowanie kopii bezpieczeństwa. Raz skonfigurowany zestaw operacji nazywany Maintenance Plan’em, czyli planem serwisowym, może być wielokrotnie uruchamiany w zadanym czasie. Tworzony jest zatem pewien „automat”, który o konkretnej porze wykona za nas operacje, które można wykonać z interfejsu programu Comarch ERP Optima.
W niniejszym podrozdziale przedstawiony został przykład planu serwisowego obejmującego:
- Sprawdzenie spójności i ciągłości bazy danych (element testów integralności)
- Odbudowę indeksów (ikona pioruna na oknie listy baz danych w konfiguracji)
- Aktualizację statystyk
- Wykonanie kopii bezpieczeństwa bazy konfiguracyjnej oraz firmowej
- Usunięcie plików powstałych na potrzeby wykonywania planu
Materiał został sporządzony przy pomocy MS SQL 2008 za pomocą kreatora. Dla wcześniejszych wersji silnika bazy danych postępuje się podobnie.
Krok 1 – Uruchomienie kreatora Maintenance Plan’u
Kreator uruchamiany jest z poziomu programu Management Studio (pełna wersja).
SQL Server /Management/Maintenance Plan Wizard

Krok 2 – Wskazanie nazwy planu oraz terminu jego wykonywania
Kolejnym oknem kreatora, na które natrafiamy, jest krótki opis możliwości samego kreatora. Możemy zaznaczyć opcję, aby nie pokazywało się ono następnym razem. Interesuje nas następne okno.
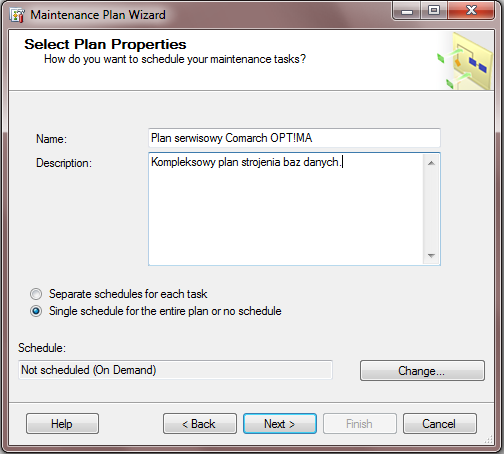
Wypełniamy w nim pola odpowiadające za nazwę oraz opis planu. Deklarujemy następnie jego ramy czasowe. Mamy dwie możliwości:
„Seperate schedule for each task” – opcja pozwala na ustalenie terminu wykonania dla każdej operacji planu osobno.
„Single schedule for entire plan or no schedule” – opcja pozwala na ustalenie terminu wykonania całego planu lub wykonania go na życzenie (on demand).
Naciskając przycisk „Change” przechodzimy do okna konfiguracji ram czasowych.
Poniższy obraz przedstawia wybór ram czasowych dla opisywanego przykładu.
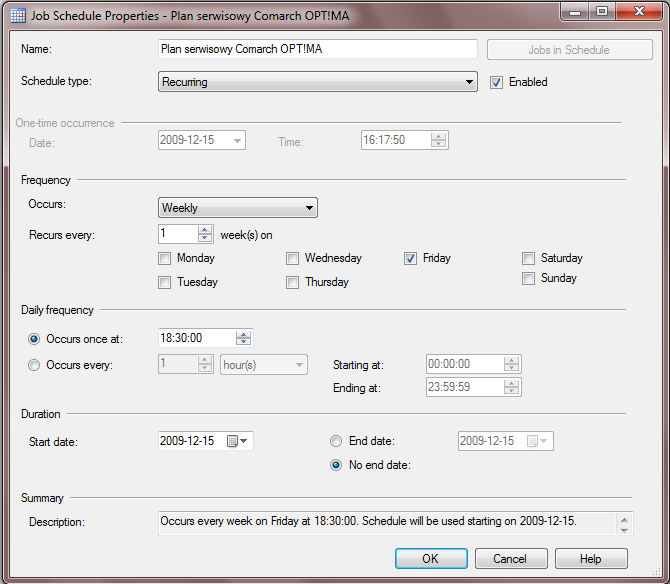
Istnieją cztery kombinacje ram czasowych dla planu. Mamy zatem:
- „Start automatically (…)” – plan uruchomi się tuż po uruchomieniu serwera oraz usługi SQL Agent
- „Start whenever when CPU (…)” – plan uruchomi się, kiedy procesor nie będzie obciążony
- „Recurring” – plan ustala się według interwałów rok / miesiąc / dzień
- „On time” – plan wykona się tylko raz w zadanym dniu i godzinie
W przykładzie użyjemy opcji terminarza według interwału co tydzień. Na obrazku widać, iż ma wykonywać się w każdy piątek o godzinie 18:30. Plan ma rozpocząć się od 15 grudnia 2009 roku i ma nie mieć końca.
Plan ma symulować koniec tygodnia roboczego, kiedy po godzinie 18:00 wszyscy pracownicy skończyli pracę, a serwer SQL nie jest już niczym obciążony.
Poprawne wskazanie ram czasowych dla planu jest bardzo istotne. Uruchomienie go podczas szczytu aktywności pracowników może nawet uniemożliwić im pracę. Podczas optymalizacji serwer pobiera dużo zasobów sprzętowych oraz blokuje elementy struktury bazy danych.
Krok 3 – wskazanie składników planu serwisowego
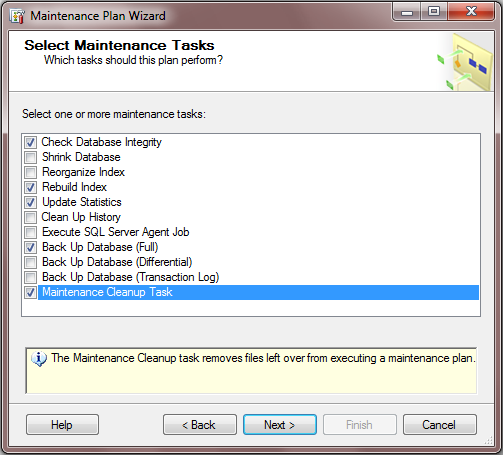
Kolejne okno kreatora planu przedstawia zakres czynności, jakie można wykonać. Są to:
- „Check Database Inegrity” – kontrola poprawności struktury bazy danych. Nie można mylić jej z testami integralności, które walidują poprawność samych danych.
- „Shrink Database” – pomniejszenie wielkości bazy danych poprzez usunięcie już niepotrzebnej rezerwy. Serwer SQL podczas pracy alokuje nowe zasoby na potrzeby przyszłych danych oraz operacji. Nie usuwa natomiast powstałem w tej sposób nadwyżki, kiedy dane zostaną usunięte a operacja się zakończy. Shrink pozwala na uwolnienie tych danych. Należy jednak pamiętać o tym, iż usunięcie nadmiarowych danych skutkuje fragmentacją dysku i może negatywnie wpływać na wydajność SQL. Nie zaleca się shrinkowania bazy danych tuż po wykonaniu odbudowy indeksów. Może to przynieść efekt odwrotny od zamierzonego.
- „Reorganize Index” – defragmentacja indeksów.
- „Rebuild Index” – odbudowa indeksów na nowo. Operacja ta jest bardziej długotrwała aniżeli defragmentacja, lecz daje lepsze efekty.
- „Update Statistics” – aktualizacja “query optimizer’a” dzięki której serwer będzie potrafił wydajniej wykonywać polecenia.
- „Clean Up History” – usuwanie historii wykonywania i odtwarzania kopii baz danych.
- „Execute SQL Server Agent Job” – wykonanie “Job’a”.
- „Back Up Database” – wykonanie kopi bezpieczeństwa bazy danych.
- „Maintenance Cleanup Task” – usunięcie plików powstałych podczas wykonywania planu.
Poniższy obraz przedstawia wybór opcji, które realizowane są w opisywanym przykładzie.
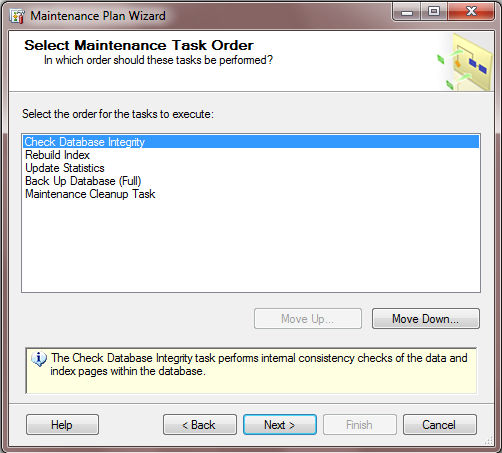
Krok 4 – wskazanie kolejności wykonywania składników planu serwisowego
Kolejne okno kreatora planu pozwala na zadecydowanie, w jakiej kolejności powinny wykonać się poszczególne składniki planu serwisowego.
Krok 5 – wskazanie baz danych dla każdego elementu planu serwisowego
Każdy element planu serwisowego można wykonać dla dowolnego zestawu baz danych. Naszym celem będzie baza konfiguracyjna i baza firmowa.
Krok ten pozwala na elastyczność podczas tworzenia planu dla serwera przechowującego dużą ilość baz danych. Każdej z nich można przypisać oddzielne punkty planu.
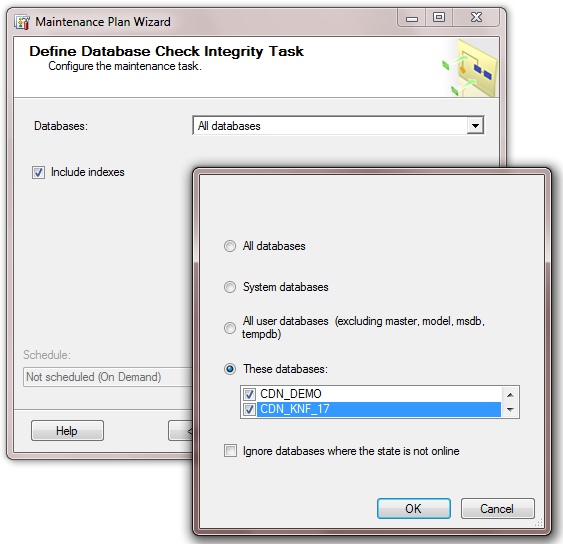
Ogólna zasada wyboru baz danych jest wspólna dla wszystkich elementów planu serwisowego. Możemy wybrać:
- „All databases” – operacja zostanie wykonana na wszystkich bazach danych znajdujących się na serwerze.
- „System databases” – operacja zostanie wykonana tylko dla systemowych baz danych (przykład nie zakłada żadnych optymalizacji na tym typie baz danych).
- „All user databases” – operacja zostanie wykonana tylko dla baz danych użytkownika, czyli niesystemowych. Dzięki tej opcji mamy pewność, iż zoptymalizujemy wszystkie bazy danych i nie narazimy na niebezpieczeństwo bazy systemowe.
- „These databases” – operacja zostanie wykonana tylko dla zaznaczonych baz danych. Opisywany przykład wykorzystuję tę opcję.
- „Ignore databases (…)” – wszystkie te bazy danych, których stan nie jest „Online” nie będą podlegać optymalizacji.
Poniższy obraz przedstawia wybór baz danych poddawanych sprawdzaniu poprawności. Każde kolejne okno opiera się na podobnym wyborze.
Krok 6 – charakterystyczne opcje dla każdego elementu planu serwisowego
Podczas wskazywania, które bazy danych mają zostać zoptymalizowane, możemy ustalić pewne opcje charakterystyczne dla elementu planu serwisowego.
Dla elementów wykorzystanych w przykładzie mamy:
- Check Database Inegrity
-Include indexes – po odznaczeniu proces kontroli nie obejmie indeksów, zajmie więc mniej czasu. - Rebuild Index
-Reorganize pages with the default amount of free space – odbudowa indeksów z domyślnym
“fill factor”. Oznacza to, iż indeksy zostaną odbudowane zgodnie z ustawieniami zadanymi podczas kreowana bazy danych, czyli przewidziane przez Comarch.
-Change free space per page percentage to … – wskazanie wartości “fill factor” samodzielnie.
-Sort results in tempdb – zastosowanie SORT_IN_TEMPDBoption.
-Keep index online while reindexing – podczas odbudowy indeksy będą możliwe do odczytu (ta opcja dostępna jest dla edycji Enterprise) - Update Statistics
-Update: – wybór elementów poddanych aktualizacji.
-Scan type: – zakres elementów poddanych aktualizacji. - Back Up Database
-Sekcja „Create a backup file for every database” – opcje związane z katalogiem, w którym zostaną umieszczone pliki kopii zapasowych. - Maintenance Cleanup Task
-Dostępne opcje pozwalają na zadecydowanie jaki typ danych historycznych ma podlegać kasowaniu. Wskazuje się albo pewien plik, albo folder. Określa się również wymagany wiek pliku.
Krok 7 – wskazanie sposobu raportowania wyników wykonania planu serwisowego oraz zakończenie pracy z kreatorem.
Ostatnim etapem tworzenia planu serwisowego jest wskazanie ścieżki dostępu dla pliku raportu. Zawiera on zestawienie podjętych czynności oraz wyniki ich działania.
Po zakończeniu kreatora, nowy plan znajduje się na liście Maintenance Plans w programie Management Studio.
Na tym etapie kończy się konfiguracja planu serwisowego. Wykona się w następny piątek o godzinie 18:30.
Szerszy opis wszystkich elementów Maintenance Plan’u w języku angielskim można uzyskać na stronie: http://msdn.microsoft.com/en-us/library/ms188981.aspx
Plan serwisowy dla bezpłatnych wersji MS SQL
Opisany wcześniej plan serwisowy zbudować można tylko dla płatnych wersji silnika bazy danych. Nic nie stoi jednak na przeszkodzie, aby samemu sporządzić podobną funkcjonalność i zaproponować ją klientowi. Podobny efekt uzyskamy poprzez sporządzenie:
- Skryptu SQL, który zawierał będzie wszystkie potrzebne dla optymalizacji zapytania.
- Skryptu JS/VBS lub pliku .bat, który będzie zdalnie uruchamiał skrypt SQL z poziomy konsoli.
- Harmonogramu systemu Windows, w którym zawrze się ramy czasowe planu.
W niniejszym biuletynie technicznym załączone zostały dwa pliki:
Plik StrojenieBazy.sql to skrypt zawierający wszystkie niezbędne zapytania, aby przeprowadzić plan tożsamy
z wcześniej opracowanym Maintenance Plan’em. Przed użyciem należy zmodyfikować w nim dwa parametry:
SET @Nazwa_bazy = 'CDN_DEMO’ — Tu wpisz nazwę bazy danych do optymalizacji
SET @Sciezka = N’C:\BACKUP\’ — Tu wpisz ścieżkę dostępu do katalogu dla kopii baz
Skrypt optymalizuje tylko jedną, wybraną bazę danych. Został tak sporządzony dla łatwiejszego zrozumienia jego działania. Warto prześledzić jego strukturę.
Drugi skrypt o nazwie StrojenieBazCDN.sql wymaga wskazania ścieżki dostępu do katalogu dla kopii baz. Zastosowano w nim kursor wyszukujący wszystkie bazy danych, których nazwa zaczyna się od ‘CDN’. Dla każdej z nich przeprowadzona zostanie optymalizacja.
Przed uruchomieniem skryptu należy zmodyfikować w nim następujące elementy:
sqlcmd.exe -S SERWER -E -i D:\StrojenieBazCDN.sql -o C:\Backup
- SERWER – nazwa serwera, na którym znajdują się bazy danych.
- D:\StrojenieBazCDN.sql – ścieżka dostępu oraz nazwa skryptu SQL.
- C:\Backup – ścieżka docelowego miejsca składowania kopii baz danych (katalog musi istnieć).
Aby uruchomić automatyczne wykonywanie planu serwisowego należy w harmonogramie systemu Windows utworzyć nową regułę, która będzie w zadanym czasie uruchamiać odpowiedni skrypt VBS. Tym sposobem uzyskamy ten sam efekt, jaki przynieść może Maintenance Plan.