Wprowadzenie Workflow Management wiąże się z takimi celami, jak zwiększenie wydajności, oszczędność kosztów, usprawnienie procesów pracy i współpracy. Zautomatyzowany proces workflow może być wykorzystywany szczególnie efektywnie tam, gdzie procesy pracy muszą być wykonywane wielokrotnie.
Rozpoczęcie pracy z Workflow Management jest niemal łatwe dzięki oferowanym funkcjom zarządzania workflow. Działania mogą być rejestrowane i przetwarzane praktycznie bez wysiłku związanego z konfiguracją i bez konieczności odbycia wielu szkoleń. Wprowadzenie i korzystanie z bardziej złożonych funkcji workflow zorientowanych na procesy i zdarzenia jest znacznie łatwiejsze dzięki prefabrykowanym i konfigurowalnym szablonom workflow, które można przyjąć i aktywować bez dogłębnej wiedzy technicznej.
Workflow Management zostało opracowane przy użyciu własnych modułów systemu i dlatego jest częścią systemu ERP. W związku z tym aplikacje w ramach Workflow Management mogą być obsługiwane tak samo intuicyjnie, jak inne aplikacje. Ponadto podstawowe właściwości i funkcje systemu są wykorzystywane do zarządzania workflow, takie jak uprawnienia, struktura organizacyjna i zarządzanie dokumentami. I odwrotnie, sam workflow jest również wykorzystywany w wielu obszarach systemu ERP, np. w zarządzaniu relacjami lub przetwarzaniu w tle. Ta nienakładająca się architektura poszczególnych komponentów minimalizuje zarówno koszty szkoleń, jak i administracji. Płynna integracja umożliwia każdej aplikacji dostęp do funkcji Workflow Management bez konieczności skomplikowanego programowania interfejsu.
Silnik workflow jest centralnym komponentem w Workflow Management. Silnik workflow generuje działania, gdy wystąpią określone zdarzenia i przypisuje zadania do odpowiednich operatorów. Silnik workflow monitoruje i koordynuje przetwarzanie zadań. Jeśli czas zostanie przekroczony, silnik workflow może zainicjować działania następcze, takie jak przypomnienie użytkownikowi o opóźnionych zadaniach, eskalacja opóźnionych zadań do przełożonego lub powiadomienie właściciela procesu o opóźnieniu.
Niniejszy dokument opisuje model danych Workflow Management i jego komponenty, a także techniczne aspekty tworzenia działań i przetwarzania zadań. Ponadto opisano konfigurację i dostosowywanie powiadomień e-mail przez silnik workflow oraz inne ustawienia konfiguracyjne.
Systemowy język skryptowy wykorzystywany w workflow i jego elementy (zasady, warunki i polecenia) zostały wyjaśnione w artykule Język skryptowy systemu.
Struktura poszczególnych aplikacji workflow i procedury ich obsługi są opisane w dokumentacji aplikacji, np. w artykule Działania.
Sposób mapowania definicji procesów i działań oraz strukturę aplikacji o tej samej nazwie można znaleźć w artykułach Definicje działań i Definicje procesu.
Szczegółowy opis przetwarzania zadań workflow można znaleźć w artykule Wprowadzenie: Workflow Management oraz w Instrukcji obsługi.
Grupa docelowa
Grupą docelową dla tego dokumentu są programiści, konsultanci techniczni i administratorzy workflow, którzy konfigurują lub administrują Workflow Management dla klientów.
Niniejszy dokument zakłada zrozumienie zakresu funkcji workflow widocznych dla użytkownika.
Definicje terminów
Działania
Działanie opisuje czynność, która może być wykonana przez jednego lub więcej użytkowników. Działanie jest przetwarzane przez użytkowników na podstawie jednego lub więcej zadań, w których odpowiednie działanie jest opisane dla każdego użytkownika. Działanie tworzy zatem klamrę wokół wynikowych zadań i zawiera niezbędne informacje o zadaniach. Działania są tworzone jako część Workflow Management lub Zarządzania relacjami i są częścią workflow.
Definicja działania
Definicja działania jest szablonem dla działań generowanych na jej podstawie. Jeśli definicja działania jest aktywna, silnik workflow generuje nowe działanie, gdy wystąpi zarejestrowane zdarzenie, pod warunkiem spełnienia warunku przejścia. Definicje działań są niezależne od bazy danych OLTP i systemu, w którym zostały zarejestrowane, ponieważ nie zawierają ani danych specyficznych dla systemu, ani danych specyficznych dla OLTP. Definicje działań są zapisywane w bazie danych repozytorium.
Zadanie
Zadanie w Workflow Management reprezentuje przypisanie działania wynikającego z działania do użytkownika. Każde zadanie ma zaplanowany okres przetwarzania, który jest określony przez działanie wyższego poziomu, a także status zadania. Czas pierwszej zmiany na nowy status jest dokumentowany.
Status zadania
Status zadania zależy od bieżącego czasu i statusu innych zadań w działaniu wyższego poziomu. Jeśli określony okres przetwarzania działania wyższego poziomu nie został jeszcze osiągnięty, status zadania to Zaplanowane. Jeśli określony okres przetwarzania został już przekroczony, status zadania to Zaległe. Jeśli użytkownik pracuje nad zadaniem, status zadania to W opracowaniu. Jeśli podczas przetwarzania indywidualnego aktualnie przetwarzane jest inne zadanie z działania wyższego poziomu, status sprawy to Zablokowane. Jeśli zadanie zostało przekazane innemu użytkownikowi przez przekierowanie, status zadania to Przekazane. Jeśli zadanie zostało utworzone przez przekazanie innemu użytkownikowi lub przez działanie następcze w przypadku przekroczenia limitu czasu, status zadania to Odebrane. Jeśli zadanie zostało ukończone, jego status to Zrealizowane lub Zakończone bez przetwarzania. Czas pierwszej zmiany na nowy status jest dokumentowany.
Zdarzenie
Zdarzenia stanowią podstawę do tworzenia działań z definicji działań w ramach Workflow Management. Zdarzenia mogą być wyzwalane przez zmiany danych dokonane przez system, aplikację lub działanie użytkownika. Zdarzenia zawierają parametry opisujące zdarzenie. Aby wygenerować działanie w momencie wystąpienia zdarzenia, aktywowana definicja działania musi być zarejestrowana dla tego zdarzenia, a warunek przejścia musi być spełniony.
Prefiks eksportu
Każdy system Comarch ERP Enterprise posiada prefiks eksportu. Prefiks eksportu jest unikalny podczas przesyłania aktualizacji oprogramowania z systemu deweloperskiego do systemu produkcyjnego. W Workflow Management, prefiks eksportu definicji działania jest używany do decydowania, w którym systemie definicja działania może zostać zmieniona i aktywowana. Tylko definicje działań i ról workflow z prefiksem eksportu odpowiadającym prefiksowi eksportu wybranego systemu mogą zostać zmienione. Podczas wprowadzania nowych definicji działań i ról workflow, nowa definicja lub rola otrzymuje prefiks systemu wybranego w momencie wprowadzania.
GUID
GUID jest skrótem od Globally Unique Identifier i odpowiada globalnie unikalnemu identyfikatorowi. GUID to 128-bitowy numer obliczany zgodnie ze schematem Open Software Foundation (OSF) dla rozproszonych środowisk obliczeniowych (DCE). Zawiera on między innymi adres IP komputera generującego, składnik czasu i składnik losowy. Oznacza to, że dwa niezależne komputery mogą zawsze obliczyć różne identyfikatory GUID bez synchronizacji. W Comarch ERP Enterprise identyfikatory GUID są reprezentowane jako tablice bajtów Java o długości 16 i są używane głównie jako kompaktowe klucze podstawowe i obce w Business Objects.
Proces
Proces to techniczny opis części procesu biznesowego. Proces składa się z poszczególnych etapów. Etapy procesu mogą być ze sobą powiązane. Ukończenie etapu procesu może uruchomić przetwarzanie innych etapów procesu. Proces ma zdefiniowany początek i koniec. Kroki procesu mogą uzyskiwać dostęp do zmiennych procesu zadeklarowanych w procesie.
Definicja procesu
Definicja procesu to kompletny opis techniczny procesu operacyjnego lub podprocesu. Składa się z kroków procesu, które opisują proces biznesowy pod względem czasu i organizacji. Definicja procesu jest modelowana jako diagram, którego węzły reprezentują definicje czynności, a krawędzie reprezentują przepływ sterowania. Właściwości procesów i kroków procesu są określane za pomocą definicji procesu i definicji czynności. Definicje procesów są niezależne od bazy danych OLTP i systemu, w którym zostały zarejestrowane, ponieważ nie zawierają ani danych specyficznych dla systemu, ani danych specyficznych dla OLTP. Definicje procesów są zapisywane w bazie danych repozytorium.
Systemowy język skryptowy
Wyrażenia, warunki, polecenia, funkcje i deklaracje są używane do wyrażania złożonych relacji. Wszystkie te wyrażenia są częścią wspólnego języka skryptowego zwanego językiem skryptowym systemu. Składnia języka skryptowego systemu jest oparta na SQL, Pascal i Java. Język skryptowy systemu jest używany w Workflow Management, na przykład do formułowania warunku wstępnego lub warunku przejścia lub do określania operatorów, którzy nie są podsumowani w roli workflow.
Rola workflow
Role workflow są poziomem abstrakcji do mapowania organizacji procesu używanej przez workflow. Właściciele muszą być przypisani do roli workflow, aby można było z niej odpowiednio korzystać. Właścicielami mogą być użytkownicy, osoby, zadania lub organizacje. Przypisanie właścicieli roli workflow jest specyficzne dla bazy danych, ponieważ tylko obiekty w tej bazie danych mogą być użyte do przypisania. Rola zazwyczaj ma różnych właścicieli w różnych bazach danych. Role workflow mogą być również definiowane przy użyciu wyrażenia zamiast przypisanych właścicieli, podobnie jak w przypadku funkcji. Gdy te role są rozwiązywane, właściciele są obliczani przy użyciu wyrażenia.
Architektura
Wszystkie automatyczne zmiany statusu działań i zadań są wykonywane przez centralny silnik workflow. Silnik workflow jest wykonywany na serwerze komunikatów w każdym systemie. Tylko obsługa zdarzeń działa na każdym innym serwerze aplikacji w systemie.
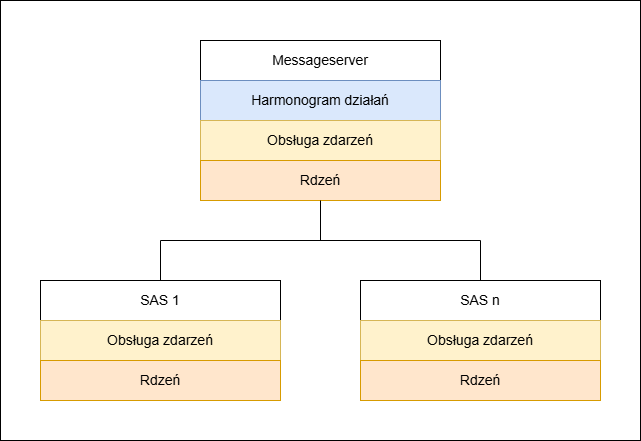
Architektura silnika workflow w systemie
Harmonogram działań jest wykonywany na serwerze komunikatów. Jest on natychmiast powiadamiany o każdym nowym działania. Program planujący jest odpowiedzialny za zmiany statusu na początku i na końcu okresu przetwarzania. Wykorzystywana jest istniejąca komunikacja poprzez zarządzanie blokadami, dzięki czemu nie jest wymagana dodatkowa komunikacja. Scentralizowane przetwarzanie automatycznych zmian statusu zapewnia spójność danych.
Bez dodatkowej komunikacji sieciowej dla zdarzeń, obsługa zdarzeń wykonywana na każdym serwerze aplikacji może bezpośrednio generować działania. Każdy serwer aplikacji generuje zatem działania tylko dla zdarzeń, które zostały również wywołane na tym serwerze aplikacji.
Podobnie jak baza danych repozytorium, każda indywidualna baza danych OLTP działa we własnym wątku w harmonogramie. Może to zwiększyć przepustowość większych instalacji. Lista zadań harmonogramu rozpoznaje zadania, które są aktualnie w toku i jest aktualizowana bardzo szybko ze względu na opisaną powyżej architekturę. Ogólnie rzecz biorąc, zmiany statusu działań są przetwarzane z kilkusekundowym opóźnieniem. Harmonogram uzyskuje dostęp do bazy danych dopiero po przetworzeniu listy zadań do bieżącego punktu w czasie. Takie zachowanie zapewnia krótki czas reakcji przepływu pracy i tylko niewielką utratę szybkości całego systemu.
Okno dokowane wyszukiwania zadań jest aktualizowane poprzez synchronizację pamięci podręcznej. Na serwerze wiadomości okno dokowane jest aktualne z wyjątkiem krótkiego opóźnienia. Na wszystkich innych serwerach aplikacji w systemie okno dokowane wyświetla nowe działania najpóźniej po interwale synchronizacji pamięci podręcznej. Okno dokowane wyszukiwania zadań jest automatycznie aktualizowane za pomocą każdej standardowej akcji paska narzędzi, takiej jak [Otwórz] lub [Zapisz], a także akcji paska narzędzi workflow.
Zmiany w aktywnych definicjach działań stają się aktywne natychmiast po zapisaniu i bez ponownego uruchamiania systemu. Obsługa zdarzeń wszystkich serwerów aplikacji w systemie jest aktualizowana najpóźniej po interwale synchronizacji pamięci podręcznej.
Harmonogram można uruchomić na serwerze aplikacji innym niż serwer komunikatów. Nie jest to jednak zalecane w przypadku wydajnej pracy, ponieważ prowadzi do niepotrzebnych opóźnień w przetwarzaniu działań z powodu synchronizacji pamięci podręcznej. Harmonogram może być obsługiwany tylko na jednym serwerze aplikacji. Uniemożliwia to uruchomienie harmonogramu na więcej niż jednym serwerze aplikacji w tym samym czasie.
Poniższa ilustracja pokazuje, w jaki sposób silnik workflow i powiązane z nim komponenty generują działania po wystąpieniu zdarzeń.
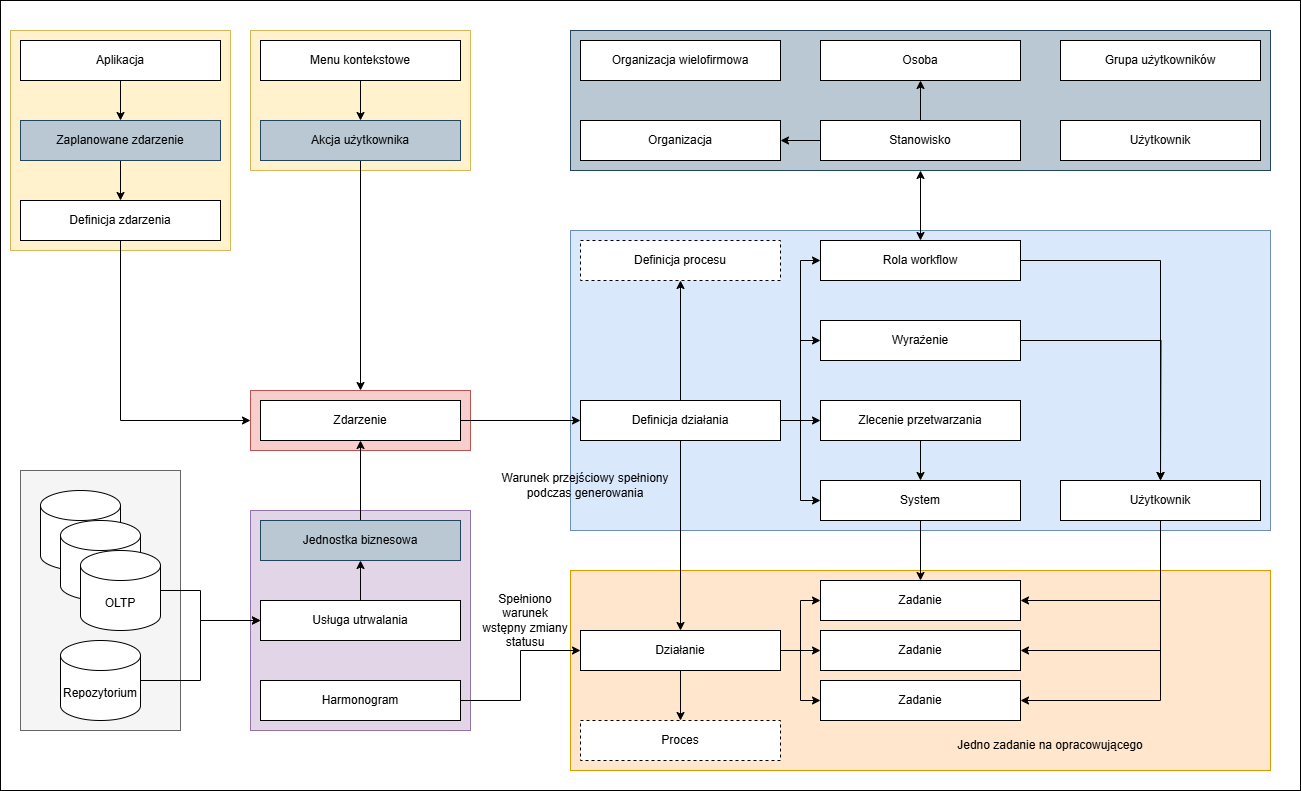
Na początku znajduje się zdarzenie, które miało miejsce. Tak zwane zaprogramowane zdarzenie może zostać wywołane przez aplikację. Zdarzenie typu Jednostka biznesowa jest wyzwalane przez usługę trwałości, gdy instancja obiektu biznesowego jest wstawiana, zmieniana lub usuwana w bazie danych repozytorium lub w bazie danych OLTP. Zdarzenie typu Akcja użytkownika jest wyzwalane, gdy użytkownik uruchamia proces za pośrednictwem menu kontekstowego jednostki biznesowej. Jeśli zdarzenie ma podtyp (np. wstawienie, zmiana lub usunięcie dla typu zdarzenia Jednostka biznesowa), tylko definicje działań, które zarejestrowały się dla zdarzenia z tym samym podtypem, są analizowane w momencie wystąpienia zdarzenia.
Jeśli warunek przejścia jest spełniony, silnik workflow tworzy działanie. Działanie otrzymuje swoje cechy, takie jak temat, priorytet, czas rozpoczęcia i planowany czas zakończenia, z definicji działania. Procesory działania są również obliczane na podstawie definicji działania. Na przykład rola workflow, zadanie, pracownik lub wyrażenie mogą zostać wybrane jako operator działania w definicji działania. Silnik workflow tworzy zadanie dla każdego użytkownika, który jest możliwym operatorem i przypisuje je do działania. Zadania czerpią swoje podstawowe cechy z działania. Ponadto zadanie ma cechy specyficzne dla zadania, takie jak status oraz rzeczywisty czas rozpoczęcia i zakończenia.
Za pomocą harmonogramu silnik workflow koordynuje przetwarzanie działania i jego zadań, aktualizuje ich status, powiadamia operatorów o osiągnięciu planowanego czasu rozpoczęcia i inicjuje działania następcze, jeśli czas ten zostanie przekroczony. W zależności od trybu przetwarzania, działanie jest uznawane za zakończone, gdy ukończone zostanie pierwsze zadanie lub gdy ukończone zostaną wszystkie zadania powiązane z działaniem.
Obiekty workflow
Dane wymagane do zarządzania workflow można podzielić na następujące grupy:
- Definicje procesów, działań i ról workflow, które są używane między innymi do obsługi zdarzeń, są niezależne od systemu i baz danych OLTP. Są one przechowywane w bazie danych repozytorium i mogą być importowane i eksportowane za pomocą poleceń powłoki narzędziowej.
- Definicje procesów, definicje działań i role workflow zapisane w systemie klienta jako szablon. Są one przechowywane w bazie danych repozytorium i mogą być przenoszone z systemu testowego do systemu produkcyjnego, na przykład za pomocą aktualizacji oprogramowania.
- Konkretne dane, takie jak pracownik i użytkownik, muszą być przypisane do definicji procesów, definicji działań i ról workflow. Przypisanie to nie jest już niezależne od systemu i baz danych OLTP. Konkretne dane muszą być przypisane do definicji działań i ról workflow w każdym systemie.
- Definicje działań służą do tworzenia działań i zadań oraz przechowywania ich w bazie danych, w której zdarzenie zostało wywołane. Ponadto użytkownicy mogą również rejestrować tak zwane ręcznie wprowadzone działania. Użytkownik pracuje z tą bazą danych podczas korzystania z workflow i przetwarzania zadania workflow.
Techniczne nazwy obiektów biznesowych są używane podczas opisywania modelu danych. Obiekty workflow znajdują się w obszarze nazw com.cisag.sys.workflow.obj. Szablony workflow znajdują się w obszarze nazw com.cisag.sys.repository.obj.
Definicje działań
Definicje działań łączą zdarzenia z tworzeniem nowych działań. Definicje działań mogą określać, czy działanie powinno zostać utworzone, gdy wystąpi określone zdarzenie i jakie cechy powinno mieć to działanie. Gdy wystąpi zdarzenie, silnik workflow sprawdza warunki przejścia tych definicji działań, które reagują na zdarzenie. Definicje działań, które reagują na podtyp inny niż wywołane zdarzenie, nie są brane pod uwagę. Jeśli warunek przejścia jest prawdziwy, silnik workflow tworzy nowe działanie.
Wszystkie dane wymagane dla nowego działania są obliczane na podstawie definicji działania. Definicja działania stanowi zatem szablon dla działań generowanych na jej podstawie. Definicje działań są niezależne od bazy danych OLTP i systemu, w którym zostały utworzone, ponieważ nie zawierają ani danych specyficznych dla systemu, ani danych specyficznych dla OLTP. Definicje działań są przechowywane w bazie danych repozytorium.
Tylko aktywowane definicje działań mogą generować działanie. Podczas aktywacji niektóre właściwości, takie jak klasyfikacje działania, mogą być zmieniane w zależności od bazy danych. Ponieważ właściciele specyficzni dla bazy danych są również przypisani do roli workflow, dwa działania utworzone z tej samej definicji działania mogą mieć różnych operatorów, jeśli działania zostały utworzone w różnych bazach danych.
Definicja działania musi być aktywowana w każdej bazie danych, w której ma być używana. Umożliwia to analizę zdarzeń specyficznych dla bazy danych (tj. w szczególności specyficznych dla OLTP). Dane wymagane do aktywacji są przechowywane w bazie danych, w której aktywowana jest definicja działania. Umożliwia to kopiowanie baz danych OLTP w ramach systemu bez konieczności reorganizacji aktywacji definicji działania. Należy użyć polecenia toolshell dltwflacv, aby usunąć aktywacje po skopiowaniu bazy danych.
Poniższa ilustracja przedstawia model danych definicji działania. Wszystkie obiekty biznesowe z wyjątkiem ActivityDefinitionExtension są przechowywane w bazie danych repozytorium. Obiekt biznesowy ActivityDefinitionExtension reprezentuje aktywację definicji działania w określonej bazie danych i jest przechowywany w bazie danych, której dotyczy aktywacja. Zdarzenie, na które reaguje definicja działania i warunek przejścia są przechowywane w obiekcie biznesowym Transition. Jeśli definicja działania jest powiązana z definicją procesu, relacja ProcessDefinition wskazuje na definicję procesu.
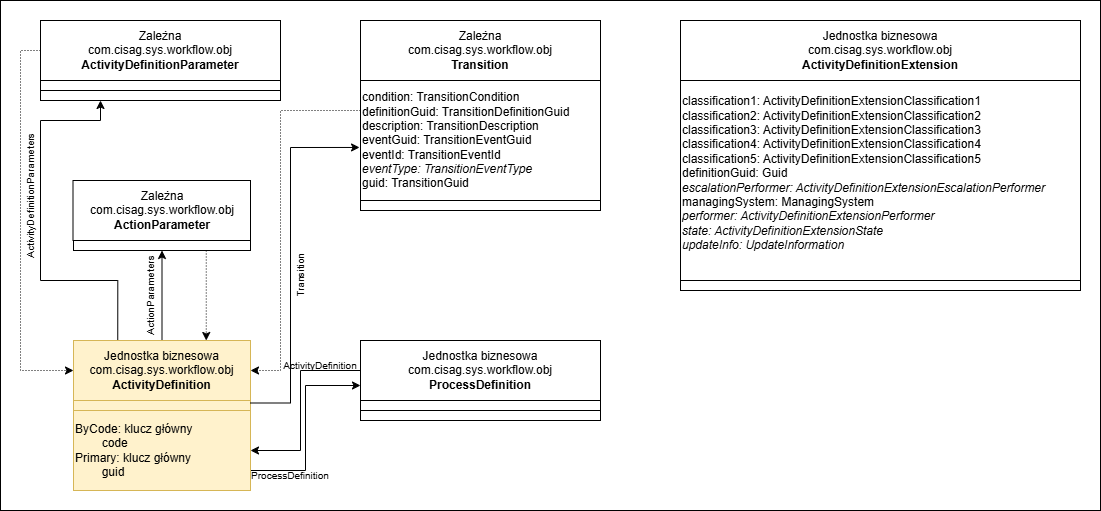
Model danych definicji działania
- ActivityDefinition – definicja działania
- Transition – przypisanie zdarzenia do definicji działania
- ActivityDefinitionParameter – definicja parametrów i wartości zwracanych w definicji działania
- ActionParameter – wartość transferu dla aplikacji powiązanej z definicją działania
- ActivityDefinition Extension – dane dla specyficznej dla bazy danych aktywacji definicji działania
- ProcessDefinition – jeśli definicja działania reprezentuje węzeł w definicji procesu, model danych zawiera również link do definicji procesu
Jak widać na ilustracji, aktywacja specyficzna dla bazy danych ActivityDefinitionExtension składa się również z klasyfikacji działania 1 – 5. Klasyfikacje te można przypisać za pomocą aplikacji Aktywacja definicji działań. Przypisanie jest również możliwe dla nieaktywowanych definicji działań, które reprezentują na przykład węzły akcji definicji procesu.
Działania i zadania
Działania z ich zadaniami są obiektami widocznymi dla użytkownika, który przetwarza działanie lub zadanie. Działania mogą być wprowadzane bezpośrednio przez użytkownika lub przez aplikację (np. w zarządzaniu relacjami). Działania mogą być również generowane przez działania serii, definicję procesu lub przez obsługę zdarzeń silnika workflow.
Jeśli definicja działania nie jest powiązana z definicją procesu, silnik workflow rozróżnia następujące typy działań (tzw. działania samodzielne):
- Pojedyncze działania
- Szablony seryjny
- Działania seryjne
Działanie indywidualne reprezentuje pojedyncze działanie dla jednego lub więcej operatorów. Szablon serii tworzy serie działań w określonym czasie. Różnica między działaniem w ramach serii a działaniem indywidualnym polega na relacji z działaniem serii, która nie występuje w pojedynczym działaniu.
Początkowy status szablonu seryjnego to Planowane. Po osiągnięciu czasu przetwarzania zmienia się on na status Do opracowania, a silnik workflow rozpoczyna przetwarzanie szablonu seryjnego. Silnik workflow tworzy nowe działanie seryjne na podstawie szablonu seryjnego. Właściwości wymagane dla działania seryjnego są kopiowane z szablonu seryjnego bez ponownej oceny deklaracji.
Definicja działania, która nie jest powiązana z definicją procesu, może wykorzystywać typy działań Wiadomość e-mail i Wywołanie funkcji.
Definicja działania typu Wiadomość e-mail wysyła wiadomość e-mail do jednego lub więcej odbiorców bez generowania działania. Ponieważ działanie reprezentuje również dowód przetwarzania, a zatem wysłanej wiadomości e-mail, zaleca się użycie definicji procesu z węzłem wiadomości e-mail, jeśli wymagany jest dowód.
Definicja działania typu Wywołanie funkcji zwraca wynik obliczony przy użyciu deklaracji bez generowania działania. Mogą być one używane na przykład do oceny metod Java w definicjach procesów, które używają języka skryptowego systemu. Na przykład, definicja działania używająca języka skryptowego systemu może wywołać definicję działania typu Wywołanie funkcji za pomocą polecenia call. Jeśli wywołanie funkcji wykorzystuje JavaScript, może na przykład wywołać metodę Java, która oblicza bieżącą ilość towaru w magazynie, a następnie udostępnia wynik wywołującej definicji działania.
Jeśli definicja działania jest węzłem w definicji procesu, silnik workflow również rozróżnia:
- Węzły akcji
- Węzeł zdarzenia
Węzeł akcji jest krokiem procesu, który reprezentuje działanie dla jednego lub więcej procesorów. Działania generowane przez węzeł akcji mogą być przetwarzane przez jednego lub więcej użytkowników, przez zlecenie przetwarzania lub przez system. Węzeł zdarzeń jest krokiem procesu, który reprezentuje zdarzenie istotne dla procesu zamiast działania. Węzły zdarzeń obejmują na przykład zdarzenie początkowe, zdarzenie końcowe i zdarzenie błędu. Działania generowane przez węzeł zdarzeń są przetwarzane przez system.
Węzły akcji są podzielone na następujące typy w celu mapowania określonego działania, takiego jak podejmowanie decyzji lub wysyłanie wiadomości e-mail:
- Węzeł użytkownika
- Węzeł usługi
- Węzeł skryptu
- Węzeł e-mail
- Interaktywny węzeł e-mail
- Węzeł usługi sieci Web
- Węzeł wyboru
- Węzeł decyzji
- Węzeł prezentacji
Węzły zdarzeń są podzielone na następujące typy:
- Zdarzenie początkowe
- Zdarzenie błędu
- Zdarzenie końcowe
- Zdarzenie pośrednie
- Zdarzenie końcowe bez określonego terminu
- Zdarzenie czasomierza
Wszystkie działania mogą mieć powiązanie z dowolną jednostką biznesową. Linki te są używane z jednej strony do dokumentowania działania, a z drugiej strony do określenia, która aplikacja może być używana do przetwarzania działania lub zadania. Jednym z ograniczeń jest to, że linki muszą istnieć w tej samej bazie danych.
Działania mają zadania. Zadanie jest zawsze przypisane do operatora. W zależności od typu działania, operatorem może być system, zlecenie przetwarzania lub jeden lub więcej użytkowników. Zadanie przechowuje również informacje o tym, kto ma je przetworzyć. W przypadku działania przetwarzanego przez użytkowników istnieje tyle zadań, ilu operatorów ma działanie, tj. dla każdego operatora tworzone jest osobne zadanie.
Działania i zadania mogą być zapisywane zarówno w bazie danych OLTP, jak i w bazie danych repozytorium. Działania nie mogą być zapisywane w bazie danych konfiguracji lub OLAP. Jeśli działanie jest zapisane w bazie danych OLTP, odnosi się do działania, które jest specyficzna dla tej bazy danych OLTP. Działania w bazie danych repozytorium odnoszą się do działań, które są specyficzne dla bazy danych repozytorium lub cross-OLTP.
Ponieważ działania mogą być powiązane tylko z obiektami w tej samej bazie danych, działanie nie może być powiązane z konfiguracją lub obiektem OLAP.
Poniższa ilustracja przedstawia model danych działania i zadania (elementu pracy) powiązanego z działaniem.
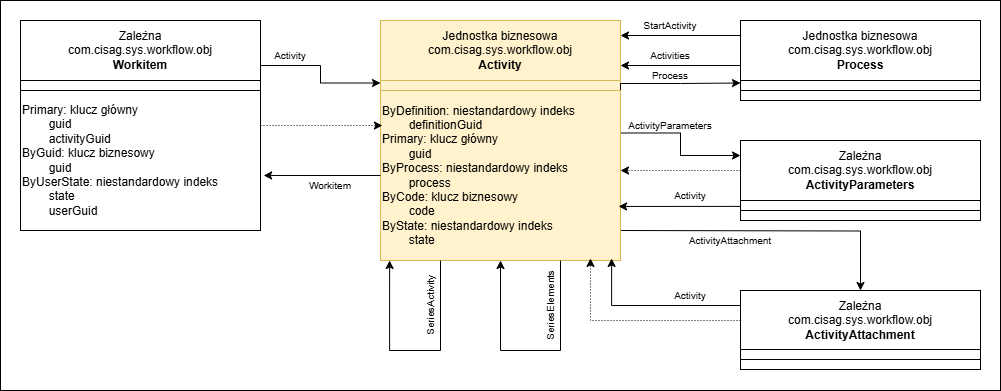
Model danych działania
- Activity – wszystkie działania są zapisywane w obiekcie biznesowym. Definicje działania typu Wiadomość e-mail nie generują działania.
- Workitem – zadania działania. Każde zadanie, które nie jest przetwarzane przez system lub zlecenie przetwarzania, jest przypisane do dokładnie jednego użytkownika. Działania typu Szablon seryjny nie mają zadań.
- ActivityAttachment – powiązanie między dowolną jednostką biznesową a działaniem. Jednostka biznesowa i działanie muszą być przechowywane w tej samej bazie danych.
- ActivityParameters – działania tworzone przez definicje działań mogą mieć parametry wymagane do oceny warunków. Wszystkie parametry są zapisywane jako obiekt blob w zestawie danych.
- Process – jeśli działanie reprezentuje węzeł w procesie, model danych zawiera również link do procesu
Ukończone działania archiwizują wcześniejsze działania. W tym celu działanie zawiera czasy, w których status przyjął określoną wartość po raz pierwszy. Zadania powiązane z działaniami zawierają odpowiednie czasy przetwarzania zadania. Ukończone działania i ich zadania można zatem wykorzystać do śledzenia, które działanie zostało przetworzone w jakim czasie. Użytkownik, którego zadanie doprowadziło do zakończenia działania, jest rejestrowany w atrybucie completeUser działania. Wartość ta jest już dostępna do oceny w funkcji close w deklaracjach.
Działania zawierają wszystkie informacje wymagane do przetwarzania. Oznacza to, że zmiana definicji działania nie ma wpływu na istniejące działania, zwłaszcza w przypadku działań, które zostały utworzone przy użyciu definicji działań. Działanie zawiera jednak odniesienie do definicji działania, które można wykorzystać do zapytań i analiz.
Ponieważ działania tworzą ważną historię, nie mogą być usuwane przez użytkownika, ale tylko za specjalną zgodą i poprzez reorganizację.
Definicje procesów
Definicja procesu łączy definicje działań, które razem reprezentują proces. Podobnie jak definicja działania, definicja procesu jest jednoznacznie identyfikowana poprzez jej identyfikator i prefiks eksportu.
Definicja działania węzła startowego określa, czy proces powinien zostać utworzony po wystąpieniu określonego zdarzenia i jakie cechy powinien mieć ten proces. Jeśli węzeł startowy nie reaguje na zdarzenie, proces można uruchomić tylko ręcznie. Pośrednie węzły zdarzeń nie mogą być użyte do uruchomienia procesu. Po osiągnięciu pośredniego węzła zdarzeń generowane jest działanie typu Zdarzenie pośrednie. Takie działanie zdarzenia pośredniego tworzy nowy token (przepływ procesu) za każdym razem, gdy zdarzenie zapisane w definicji działania jest wyzwalane, a warunek przejścia jest spełniony.
Wszystkie dane wymagane dla procesu są obliczane na podstawie definicji procesu i definicji działania węzła początkowego. Definicja procesu stanowi zatem szablon dla procesów generowanych na jej podstawie. Definicje procesów są niezależne od bazy danych OLTP i systemu, w którym zostały zarejestrowane, ponieważ nie zawierają ani danych specyficznych dla systemu, ani danych specyficznych dla OLTP. Definicje procesów są zapisywane w bazie danych repozytorium.
Definicja działania musi zostać aktywowana w każdej bazie danych, w której ma być używana. Gdy definicja procesu jest aktywowana, definicja działania węzła początkowego i definicje działań wszelkich zdarzeń pośrednich bez krawędzi przychodzących są aktywowane w imieniu definicji procesu.
Poniższa ilustracja przedstawia model danych definicji procesu. Wszystkie obiekty biznesowe są przechowywane w bazie danych repozytorium.
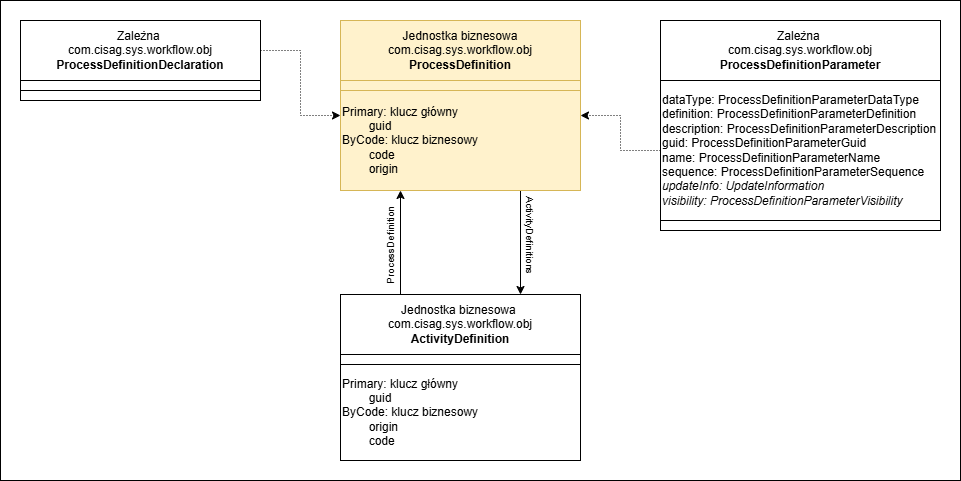
Model danych definicji procesu
- ActivityDefinition – definicja działania węzła definicji procesu
- ProcessDefinition – definicja procesu
- ProcessDefinitionDeclarations – deklaracje definicji procesu
- ProcessDefinitionParameter – definicja zmiennych procesu zdefiniowanych w definicji procesu
Procesy
Proces podsumowuje wszystkie działania należące do procesu wraz z ich zadaniami. Proces i wszystkie powiązane z nim działania i zadania muszą być zapisane w tej samej bazie danych. Proces nie może mieć działań w dwóch różnych bazach danych OLTP.
Poniższa ilustracja przedstawia model danych procesu.
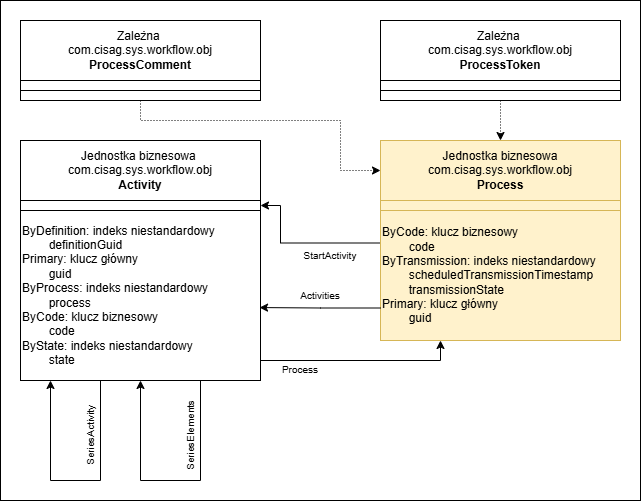
Model danych procesu
- Activity – działanie generowane na podstawie definicji działań powiązanych z węzłami
- Process – identyfikator procesu
- ProcessComment – komentarze, zarejestrowane dla procesu
- ProcessToken – token jest wewnętrzną reprezentacją przepływu sterowania
Jeśli zdarzenie jest przechowywane w definicji działania dla węzła startowego, proces może zostać uruchomiony tylko przez to zdarzenie. Jeśli zdarzenie typu Akcja użytkownika jest przechowywane, proces może być uruchomiony tylko poprzez menu kontekstowe jednostki biznesowej przechowywanej w węźle startowym. Jeśli w definicji działania nie zapisano żadnego zdarzenia, proces można uruchomić tylko ręcznie. Proces można następnie uruchomić w aplikacji Procesy lub w dokowanym oknie Menu użytkownika i ulubione. Proces można uruchomić tylko w oknie dokowanym Menu użytkownika i ulubione, jeśli definicja procesu została utworzona z szablonu definicji procesu, który jest powiązany z aplikacją interaktywną o specjalnym zastosowaniu Definicja procesu. Jeśli użytkownik nie ma uprawnień do uruchomienia tej aplikacji, nie pojawi się ona w menu użytkownika. Uprawnienia dla aplikacji powiązanej z szablonem definicji procesu są również stosowane w aplikacji Procesy. Oznacza to, że aplikacja powiązana z szablonem definicji procesu z ustawieniem wyświetlania Brak wyświetlania może być używana do przypisywania uprawnień do uruchamiania instancji procesu w aplikacji Procesy.
Procesów nie można edytować bezpośrednio. Edycja odbywa się za pośrednictwem działań i zadań powiązanych z procesem. To, które działania są generowane, jest określane przez przepływ sterowania. Przepływ sterowania jest reprezentowany przez tokeny, które są kierowane wzdłuż krawędzi łączących węzły. Za każdym razem, gdy token dociera do węzła, tworzone jest nowe działanie zgodnie z definicją działania powiązaną z węzłem, a token jest zużywany przez działanie. Gdy działanie zostanie zakończone, generowany jest nowy token i przekazywany wzdłuż wychodzącej krawędzi. Jeśli węzeł nie ma krawędzi wychodzącej, nowy token nie jest generowany.
Za pomocą tak zwanych bramek przepływ sterowania może zostać podzielony (rozgałęziony) i ponownie połączony. W zależności od typu rozgałęzienia i warunku przejścia, dla każdej wychodzącej krawędzi rozgałęzienia generowany jest token lub nie jest generowany żaden token. W zależności od typu, scalenie może zużywać token z pojedynczej krawędzi lub token z każdej z przychodzących krawędzi. Następnie powiązanie generuje nowy token i przesyła go wzdłuż wychodzącej krawędzi. Jeśli przepływ sterowania zostanie podzielony i scalony przy użyciu sprzężenia zwrotnego, tak że węzeł zostanie osiągnięty przez kilka przepływów sterowania, dla każdego tokena zostanie wygenerowane nowe działanie.
Gdy tylko przepływ sterowania osiągnie węzeł końcowy, proces kończy się, a wszystkie działania, które zostały utworzone, ale nie zostały jeszcze ukończone, są automatycznie kończone bez edytowania. Jeśli podczas wykonywania procesu lub podczas przetwarzania działania wystąpi nieodwracalny błąd, przepływ sterowania jest przekierowywany przez węzeł błędu i tworzone jest nowe działanie dla węzła błędu. Po zakończeniu działania powiązanego z węzłem błędu proces zostaje zakończony. Błąd występuje również wtedy, gdy proces nie ma już wystarczającej liczby tokenów, więc przepływ sterowania nie może już dotrzeć do węzła końcowego. Nie ma specjalnego statusu zakończenia dla procesu, który kończy się za pośrednictwem węzła błędu, ale kod błędu i oznaczenie błędu są zapisywane w procesie i mogą być również wyszukiwane w dwóch aplikacjach list dla procesów. Przepływ sterowania jest również kierowany przez węzeł błędu, jeśli polecenie abort jest używane w funkcji create w deklaracjach definicji działania, która należy do definicji procesu. W węźle startowym polecenie abort oznacza, że nie zostanie utworzona żadna instancja procesu.
Jeśli jest to wymagane, proces może również zostać zakończony bez przetwarzania poprzez akcję użytkownika. W takim przypadku przepływ sterowania jest kierowany bezpośrednio do węzła końcowego, a proces otrzymuje status końcowy Zakończone bez przetwarzania.
Proces ma działania z przypisanymi zadaniami. Jeśli zadanie jest przypisane do użytkownika, użytkownik ten jest automatycznie upoważniony do otwarcia procesu za pośrednictwem zadania, np. w celu wprowadzenia tam komentarzy. Wyzwalacz i osoba odpowiedzialna (jako użytkownik lub jako rola workflow) mogą być również przechowywane w procesie. Definicja procesu określa, jakie uprawnienia mają te i inne role w procesie. Użytkownikowi można również przypisać specjalne umiejętności dla struktury Workflow Management, która pozwala użytkownikowi otwierać procesy i edytować działania i zadania niezależnie od ustawień autoryzacji w definicji procesu. Więcej informacji na temat uprawnień definicji procesów można znaleźć w artykule Definicje procesu.
Akcja Zastosuj uprawnienia do procesów w aplikacji Aktywacja definicji działań może być użyta do przeniesienia uprawnień aktualnie ustawionych w definicji procesu do instancji procesu, które zostały już utworzone. Ta funkcja jest przydatna, na przykład, jeśli organizacja procesu istotna dla definicji procesu uległa zmianie lub jeśli osoba odpowiedzialna za proces jest użytkownikiem, a nie rolą workflow, a odpowiedzialność ma zostać przeniesiona na nowego użytkownika.
W przeciwieństwie do działania, proces nie może być powiązany z żadną jednostką biznesową. W dwóch aplikacjach typu lista dla procesów można jednak nadal wyszukiwać procesy za pośrednictwem preferowanej powiązanej jednostki biznesowej. Powiązania węzła początkowego mają również zastosowanie do procesu. Na przykład, jeśli użytkownik chce mieć możliwość wyszukiwania procesów za pośrednictwem powiązanego zamówienia sprzedaży, można powiązać zamówienie sprzedaży z procesem w węźle początkowym za pomocą polecenia addAttachment. Połączenie utworzone jako pierwsze jest połączeniem preferowanym. W przypadku niektórych typów zdarzeń, takich jak Jednostka biznesowa i Akcja użytkownika, obiekt biznesowy, do którego odwołuje się polecenie parameters.object, jest automatycznie łączony z węzłem początkowym. Podmiot procesu jest również definiowany za pośrednictwem węzła początkowego. Nawet jeśli system jest procesorem węzła początkowego, ważne jest, aby przypisać znaczący temat do węzła początkowego, np. za pomocą polecenia formatSubject.
Ukończone procesy archiwizują przeszłe działania. Przechowywanie jest obowiązkowe dla niektórych procesów. Aby zapobiec przedwczesnej reorganizacji takich procesów, w definicji procesu można określić okres przechowywania. Działająca w tle aplikacja Reorganizacja generowanych procesów odejmuje okres przechowywania od czasu procesu. Na przykład, jeśli reorganizowane są procesy starsze niż 52 tygodnie, proces z okresem przechowywania wynoszącym 104 tygodnie musi mieć co najmniej trzy lata lub 156 tygodni, aby został uwzględniony w reorganizacji.
Role workflow
Role workflow są poziomem abstrakcji do mapowania organizacji procesu używanej przez workflow. Podobnie jak definicja działania, rola workflow jest jednoznacznie identyfikowana poprzez jej identyfikację i prefiks eksportu.
Sama rola workflow nie zawiera żadnych danych istotnych dla przetwarzania działań i zadań. Właściciele muszą być przypisani do roli workflow, aby można było z niej odpowiednio korzystać. Przypisanie właścicieli ról workflow jest specyficzne dla bazy danych, ponieważ obiekty biznesowe mogą być używane w tej bazie danych podczas przypisywania. Rola workflow ma zazwyczaj różnych właścicieli w różnych bazach danych.
Jeśli proces lub działanie ma być obsługiwane przez strukturę organizacyjną, do roli workflow jako właściciela można przypisać organizację lub organizację wielofirmową. W szczególności w przypadku procesów zatwierdzania przydatne może być zdefiniowanie przetwarzania jako macierzy ról workflow i zadań.
Aby spełnić ten wymóg, rejestrowane jest po jednym stanowisku dla kierownika działu, kierownika ds. zakupów i dyrektora zarządzającego. Następnie tworzone są trzy role workflow dla małych, średnich i dużych zamówień. Stanowisko kierownika działu jest przypisane jako właściciel wszystkich trzech ról workflow. Stanowisko kierownika ds. zakupów jest przypisane jako właściciel ról workflow dla średnich i dużych zamówień. Stanowisko dyrektora zarządzającego jest przypisane tylko do roli workflow dla dużych zamówień.
Przypisanie posiadaczy jest zależne od czasu: Każde przypisanie posiadacza ma okres ważności. Przypisanie jest dodawane do anulowania tylko w tym okresie. Pozwala to na rejestrowanie zmian zaplanowanych na przyszłość dla posiadaczy.
Poniższa ilustracja przedstawia model danych roli workflow. Obiekt biznesowy WorkflowRole jest przechowywany w bazie danych repozytorium. Obiekt biznesowy WorkflowRoleElement jest przechowywany w bazie danych, do której odnosi się przypisanie właściciela.
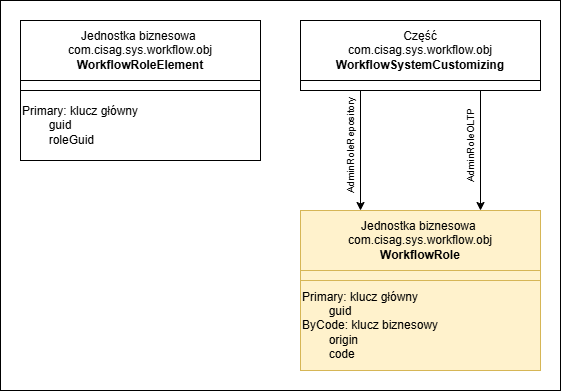
Model danych roli workflow
- WorkflowRole – rola workflow
- WorkflowRoleElement – specyficzne dla bazy danych przypisanie właściciela do roli workflow
- WorkflowSystemCustomising – funkcja konfiguracji Workflow Management z relacjami dla roli administratorów workflow w bazie danych repozytorium i w bazach danych OLTP
W poprzednich wersjach właściciele roli workflow mogli być definiowani przez wyrażenie, które jest oceniane, gdy ta rola workflow jest rozwiązywana. Role workflow oparte na wyrażeniach ułatwiały obsługę i zrozumienie, szczególnie w przypadku obsługi eskalacji. Od czasu wprowadzenia silnika skryptowego dla JavaScript ta opcja już nie istnieje, ponieważ takie role workflow nie mogą być oceniane przez wszystkie silniki skryptowe. Zamiast tego operatorzy działania (lub operatorzy w przypadku przekroczenia limitu czasu) mogą być obliczani za pomocą wyrażenia w definicji działania.
Jeśli nie można określić operatora podczas tworzenia działania, np. ponieważ używana rola workflow nie ma właściciela, działanie jest przypisywane do właściciela jednej z ról workflow dla administratorów przechowywanych w funkcji konfiguracji Workflow Management.
Definicje transportowego workflow
Szablony workflow
Definicje workflow (definicje procesów, definicje działań i role workflow) mogą być zapisywane jako szablony w systemie klienta. Szablony workflow są przechowywane w obszarze nazw com.cisag.sys.respoitory.obj bazy danych repozytorium. Jednak identyfikatory i lokalizacje przechowywania różnią się w każdym przypadku. Efekty są również różne. Podczas gdy definicje workflow są używane do tworzenia procesów i działań, szablony ról workflow są używane do uproszczonej administracji.
Aby definicja workflow mogła zostać później utworzona z szablonu workflow, szablony workflow mają podobny model danych do modelu definicji workflow, jak wskazuje poniższa ilustracja modelu danych szablonu definicji działania.
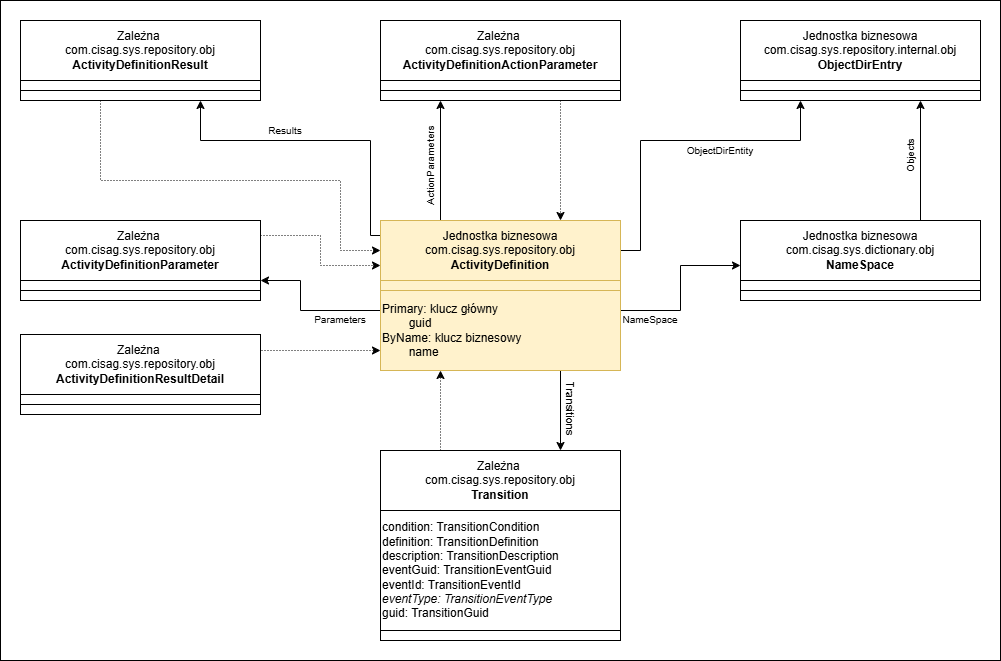
Model danych szablonu definicji działania
Szablon workflow można utworzyć w następujący sposób:
- Otworzyć istniejącą definicję workflow w odpowiedniej aplikacji workflow (Definicje procesu, Definicje działań lub Role workflow) i zapisać ją jako szablon.
- Otworzyć aplikację workflow i wybrać wartość Tak w polu Szablon. Wybrać przycisk [Nowy], aby utworzyć nowy szablon.
- Otworzyć aplikację Obiekty deweloperskie i utworzyć nowy obiekt deweloperski z typem żądanego szablonu workflow. Następnie wybrać przycisk, aby przełączyć się do odpowiedniej aplikacji workflow i wprowadzić tam pozostałe cechy definicji wokflow.
Należy wybrać procedurę, która najlepiej odpowiada wymaganiom użytkownika. Jeśli chce on zapisać istniejącą definicję workflow jako szablon, należy otworzyć istniejącą definicję workflow i wykonać akcję. Jeśli chce utworzyć nową definicję workflow, możliwe są wszystkie trzy procedury. Można na przykład utworzyć nowy szablon. Można również utworzyć nową definicję workflow i zapisać ją jako szablon po pomyślnym przetestowaniu.
Aby zapewnić integralność referencyjną obiektów deweloperskich, należy najpierw zapisać wszystkie role workflow, do których odwołuje się definicja procesu lub definicja działania jako szablon, zanim będzie można zapisać definicję procesu lub definicję działania jako szablon. Podczas zapisywania definicji procesu lub definicji działania jako szablonu, wszystkie role workflow, do których istnieją odwołania, są zastępowane przez szablon roli workflow powiązany z rolą workflow. Podczas zapisywania definicji procesu jako szablonu, wszystkie definicje działania powiązane z definicją procesu są również automatycznie zapisywane jako szablon. Nie ma zatem potrzeby jawnego zapisywania definicji działań dla węzłów zdarzeń i akcji jako szablonu. System i tak temu zapobiega ze względu na integralność referencyjną.
Po utworzeniu szablonu workflow generowany jest nowy obiekt deweloperski i przypisywany do zadania deweloperskiego. Jeśli istnieje już otwarte zadanie deweloperskie dla obiektu deweloperskiego, używane jest to zadanie deweloperskie. W przeciwnym razie automatycznie tworzone jest nowe zadanie. Dopóki zadanie deweloperskie jest otwarte, można zmieniać i zapisywać szablon workflow bez tworzenia nowej wersji szablonu workflow. Gdy tylko zadanie deweloperskie zostanie aktywowane, nowa wersja szablonu zostanie automatycznie utworzona, gdy szablon workflow zostanie zmieniony i zapisany. W tym samym czasie tworzone jest również nowe zadanie deweloperskie, które jest powiązane z szablonem workflow. Zadania deweloperskie dla szablonów workflow można aktywować za pomocą akcji aktywacji zadań deweloperskich w aplikacji Lista: Obiekty deweloperskie systemu produkcyjnego. Gdy zadania są aktywowane, system jest również restartowany, aby nowe obiekty deweloperskie były znane systemowi.
Lista: Obiekty deweloperskie systemu produkcyjnego może być również używany do przenoszenia szablonów workflow utworzonych jako obiekty deweloperskie z systemu źródłowego do kolejnych systemów. Na przykład definicja procesu, która została zarejestrowana w systemie testowym klienta i zapisana tam jako szablon, może zostać przetransportowana do systemu produkcyjnego klienta. Jako medium transportowe wykorzystywane są aktualizacje oprogramowania instalowane w kolejnych systemach. Szablon roli workflow może być transportowany z właścicielem lub bez niego. Ponieważ szablony workflow są zapisywane w bazie danych repozytorium, szablon roli workflow może mieć tylko właścicieli typów, które nie są zapisane w bazie danych OLTP. Szablon roli workflow może zatem mieć tylko właścicieli typu Użytkownik i Grupa użytkowników. System docelowy jest restartowany podczas instalacji. Dlatego należy użyć akcji Zaplanuj instalację, aby zainstalować aktualizacje oprogramowania w sposób kontrolowany czasowo.
Więcej informacji na ten temat można znaleźć w artykułach: Wprowadzenie: Logistyka oprogramowania, Obiekty deweloperskie i Lista: Obiekty deweloperskie systemu produkcyjnego.
Ponieważ szablon workflow nie może zostać wykonany, należy utworzyć i aktywować definicję workflow z szablonu, aby móc przetestować szablon. Utworzona definicja workflow jest automatycznie powiązana z szablonem. Jeśli test nie powiódł się lub użytkownik chce dostosować szablon, powinien wprowadzić zmiany bezpośrednio w szablonie workflow, a nie w definicji workflow. Jeśli utworzy się nową definicję workflow z tym samym identyfikatorem ze zmodyfikowanego szablonu, zmiany zostaną przeniesione do istniejącej definicji workflow. Należy powtarzać tę procedurę, aż szablon workflow nie będzie już wymagał dostosowania. Jeśli aplikacja definicji workflow (Definicje procesu, Definicje działań lub Role workflow) oferuje akcję aktualizacji szablonu można przenieść wszelkie zmiany w definicji workflow do szablonu workflow. Podobnie jak w przypadku zapisywania, nowa wersja szablonu jest tworzona, jeśli nie ma otwartego zadania deweloperskiego dla obiektu szablonu.
Szablony workflow utworzone w systemie nadrzędnym nie mogą być zmieniane w systemach podrzędnych. System, w którym utworzono szablon workflow, można rozpoznać po obszarze nazw szablonu. Szablon można zmienić tylko wtedy, gdy obszar nazw odpowiada bieżącemu systemowi.
Szablon workflow dostarczony z systemem ERP lub utworzony i dostarczony przez jednego z partnerów zazwyczaj musi być dostosowany do specyficznych wymagań każdego klienta. Na przykład role workflow przechowywane w definicjach działań muszą zostać zastąpione rolami workflow specyficznymi dla klienta. Ponieważ nie można zmienić dostarczonych szablonów workflow, można zamiast tego zduplikować szablon w systemie testowym. Podczas duplikowania nowy szablon jest tworzony w obszarze nazw systemu i przypisywany do automatycznie generowanego zadania deweloperskiego. Nowy szablon workflow można następnie zmienić bezpośrednio w systemie testowym, jak opisano powyżej. Alternatywną procedurą jest utworzenie definicji workflow z dostarczonego szablonu workflow. Nie należy jednak wprowadzać żadnych zmian w tej definicji workflow, ponieważ jest ona już powiązana z szablonem i dlatego nie można jej ponownie zapisać jako szablonu. Zamiast tego należy powielić wygenerowaną definicję workflow, wprowadzić zmiany, a następnie zapisać zmodyfikowaną definicję workflow jako nowy szablon. Co do zasady, dostarczone szablony definicji procesów są zaimplementowane w taki sposób, że można je dostosować za pomocą stałych wartości w deklaracjach definicji procesu. Można tam również znaleźć instrukcje dotyczące dostosowywania i uruchamiania definicji procesu.
Podczas tworzenia definicji workflow z szablonu, nowa definicja workflow jest automatycznie łączona z szablonem. Podczas zapisywania definicji workflow jako szablonu, definicję workflow można połączyć z szablonem tylko wtedy, gdy opcja ta jest wyraźnie oferowana w oknie dialogowym akcji. Jeśli akcja nie jest oferowana, nadal można utworzyć łącze, tworząc nową definicję workflow z szablonu o tym samym identyfikatorze, co definicja workflow, z której utworzono szablon. Gdy istniejąca definicja workflow zostanie nadpisana, zostanie ona automatycznie połączona z szablonem. Definicja workflow utworzona z szablonu workflow nie może zostać zmieniona w celu zapewnienia, że definicja workflow odpowiada szablonowi.
Jeśli szablon roli workflow, który został przetransportowany do systemu produkcyjnego klienta i tam aktywowany, ma zostać poprawiony lub dostosowany do zmienionych wymagań, szablon workflow powinien zostać dostosowany w systemie testowym klienta wyższego szczebla. Gdy wynikowa nowa wersja szablonu zostanie pomyślnie przetestowana, można aktywować zadanie deweloperskie i zaplanować instalację w systemie produkcyjnym klienta.
Jeśli konieczne jest natychmiastowe i niezwłoczne poprawienie definicji workflow utworzonej z szablonu workflow, definicję workflow można otworzyć do edycji w systemie produkcyjnym klienta za pomocą akcji Edytuj tymczasowo. Wszelkie wprowadzone zmiany są wtedy natychmiast skuteczne. Definicja workflow pozostaje edytowalna do następnej aktualizacji z szablonu. Jeśli funkcja automatycznej aktualizacji na zakładce Ustawienia szablonu jest aktywowana w definicji workflow w systemie produkcyjnym klienta, definicja workflow jest automatycznie aktualizowana po zainstalowaniu lub aktywowaniu nowej wersji szablonu. Jeśli funkcja nie jest aktywna, definicja workflow jest aktualizowana tylko wtedy, gdy wykonywana jest akcja [Utwórz lub zaktualizuj wg szablonu] w menu standardowego paska narzędzi.
Podczas aktualizacji istniejącej roli workflow z szablonu roli workflow, nowi właściciele mogą zostać dodani do roli workflow zgodnie z szablonem. Istniejący właściciele, którzy nie są przypisani do nowej wersji szablonu, pozostają w roli workflow.
Aktualizacja definicji procesu utworzonej z szablonu może mieć negatywny wpływ na otwarte instancje procesu.
Aby zapobiec takim błędom w czasie wykonywania, zwykle lepiej jest nie aktywować funkcji automatycznej aktualizacji definicji procesu i zamiast tego specjalnie utworzyć nową definicję procesu z nowej wersji szablonu za pomocą akcji [Utwórz lub zaktualizuj wg szablonu]. Nowo utworzona definicja procesu powinna mieć swój własny identyfikator. Nowa definicja procesu jest następnie aktywowana, a istniejąca definicja procesu dezaktywowana. Nowe instancje procesu używają definicji procesu utworzonej na podstawie nowej wersji szablonu. Jednak wszelkie instancje procesu, które zostały utworzone na podstawie istniejącej definicji procesu, nadal używają starej definicji procesu i mogą być wykonywane do końca.
Błąd uruchomieniowy może również wystąpić po zmianie wersji. Jeśli działanie zapisuje obiekt biznesowy z atrybutem specyficznym dla klienta, który jest zaimplementowany jako rozszerzenie w starej wersji i jako dodatek w nowej wersji, działanie nie może deserializować obiektu biznesowego i wystąpi błąd uruchomieniowy. W takich przypadkach polecenia powłoki narzędziowej dltwflact i dltwflprc mogą być używane do usuwania działań lub procesów, które nie mogą być już przetwarzane z bazy danych.
Jeśli później okaże się, że nowa wersja szablonu jest nieprawidłowa, można przywrócić dowolną poprzednią wersję. W tym celu należy otworzyć szablon workflow i wybrać wersję do przywrócenia w polu Wersja. Następnie należy wykonać akcję [Utwórz lub zaktualizuj wg szablonu]. Jeśli przypisana jest nazwa istniejącej definicji workflow, zostanie ona zastąpiona wybraną wersją. Aby zapobiec błędom wykonania z otwartymi instancjami procesu, należy przypisać nowy, unikalny identyfikator. Następnie należy aktywować nowo utworzoną definicję procesu i dezaktywować istniejącą.
Jeśli szablon workflow jest oznaczony jako przestarzały, komunikat ostrzegawczy jest wyświetlany podczas aktywacji definicji procesu lub definicji działania, jeśli jest ona powiązana z zapisanym szablonem workflow lub używa odrzuconego szablonu roli workflow. Aby odrzucić szablon workflow, należy utworzyć nową wersję szablonu i otworzyć ją w aplikacji Obiekty deweloperskie. Następnie należy wykonać akcję Odrzuć. Po aktywacji zadania deweloperskiego odrzucona wersja szablonu może zostać przetransportowana do dalszego systemu i tam zainstalowana.
Szablony workflow mogą być również usuwane w aplikacji Obiekty deweloperskie. Ponieważ szablony workflow są zapisywane jako obiekty deweloperskie w bazie danych repozytorium, nie można ich usunąć w konwencjonalnym sensie. Zamiast tego tworzona jest nowa tak zwana wersja do usunięcia. Ta usunięta wersja może być aktywowana jak normalna wersja szablonu i przetransportowana do dalszego systemu. Jeśli podczas aktywacji definicji procesu lub działania powiązanej z odrzuconym szablonem workflow pojawi się komunikat ostrzegawczy, dla usuniętego szablonu workflow pojawi się komunikat o błędzie uniemożliwiający aktywację. Ponadto nie można utworzyć instancji z definicji procesu lub definicji działania powiązanej z usuniętym szablonem. Właściciele nie są określani na podstawie roli workflow powiązanej z usuniętym szablonem.
Import i eksport za pomocą polecenia Toolshell
Szablony workflow są preferowanym środkiem transportu definicji workflow z systemu nadrzędnego do systemu podrzędnego. Jeśli szablon workflow ma zostać przetransportowany do systemu, który nie jest dostarczany z aktualizacjami oprogramowania przez system źródłowy, można użyć poleceń powłoki narzędzi expwfl i impwfl. Transport przy użyciu tych poleceń jest kompatybilny do przodu, ale nie wstecz. Jeśli system docelowy ma niższy status wydania, transport może nie być już możliwy. W takim przypadku definicja workflow może zostać ponownie wprowadzona tylko w systemie docelowym.
Transport przy użyciu poleceń powłoki narzędziowej nie obsługuje NLS. Teksty wielojęzyczne, takie jak nazwa i temat w definicji działania, są transportowane w głównym języku bazy danych repozytorium.
Role workflow można utworzyć za pomocą polecenia powłoki narzędziowej
expwfl -f:<str> [-role:<str-1> … -role:<str-n>*]
mogą być eksportowane. Symbol zastępczy <str> oznacza plik eksportu, który ma zostać wygenerowany, a symbole zastępcze <str-1> do <str-n> oznaczają identyfikatory ról workflow, które mają zostać wyeksportowane. Role workflow, do których odwołuje się definicja procesu lub definicja działania, są automatycznie eksportowane i importowane wraz z definicją procesu lub definicją działania. Eksport nie uwzględnia właścicieli ról workflow.
Aby wyeksportować definicje działania i definicje procesów, należy użyć parametru definition lub processDefinition zamiast role. Podczas eksportowania definicji procesu automatycznie eksportowane są również wszystkie powiązane definicje działań.
Z pomocą polecenia
impwfl -f:<str>
wyeksportowane role workflow mogą zostać zaimportowane do systemu docelowego. Więcej informacji na temat eksportowania i importowania definicji workflow można znaleźć w artykułach Eksport definicji workflow (expwfl) i Import definicji workflow (impwfl).
Definicje workflow, które zostały utworzone w systemie z innym prefiksem eksportu, muszą najpierw zostać przeniesione, zanim będą mogły zostać użyte. Definicja workflow jest kopiowana w momencie jej przyjęcia. Kopia otrzymuje prefiks eksportu bieżącego systemu. Zaimportowane definicje workflow z prefiksem eksportu, który różni się od bieżącego systemu, służą jedynie jako szablon dla definicji workflow aktywnych w systemie. Aby odwzorować to w modelu danych, definicja workflow jest jednoznacznie identyfikowana przez identyfikator i prefiks eksportu systemu, w którym definicja workflow została utworzona. Prefiks eksportu bieżącego systemu jest wyświetlany w widoku System w aplikacji Panel system.
Działania i praca nad zadaniami
W tej sekcji wyjaśniono szczegóły techniczne dotyczące przetwarzania działań i zadań w workflow. Zakłada się, że podstawowe przetwarzanie działań i zadań jest znane.
Artykuły Wprowadzenie: Workflow Management, Działania i rozdział Workflow Management w Podręczniku użytkownika opisują opcje przetwarzania i zmiany statusu działań i zadań.
Działania związane z edycją
Działanie można przenieść do przetwarzania za pośrednictwem dokowanego okna wyszukiwania zadań lub za pośrednictwem adresu URL. W dokowanym oknie wyszukiwania zadań można rozpocząć przetwarzanie działania za pomocą akcji Otwórz w menu kontekstowym zadania. Zostanie otwarta odpowiednia aplikacja, aby osoba edytująca działanie mogła wykonać zadanie związane z działaniem. To, która aplikacja zostanie otwarta, określa się w następujący sposób:
- Jeśli działanie zostało utworzone na podstawie definicji działania i wprowadzono tam aplikację, zostanie ona otwarta.
- Jeśli działanie ma co najmniej jedno łącze, obiekt jest otwierany za pomocą preferowanego łącza. Aplikacja otwierana dla tego obiektu może być ustawiona przez użytkownika.
- Jeśli nie istnieje preferowane łącze ani aplikacja nie jest zdefiniowana przez definicję działania, samo działanie jest otwierane w aplikacji Działania.
Jeśli aplikacja Działania nie jest jeszcze otwarta, najważniejsze informacje z działania, takie jak temat i nazwa, a także wszelkie komunikaty dotyczące zadania, są wyświetlane w dokowanym oknie informacji o działaniu.
Zadania powiązane z działaniem mogą być przetwarzane w trybie przetwarzania pojedynczego lub w trybie przetwarzania wielokrotnego. W trybie pojedynczego przetwarzania działanie jest również zakończone po zakończeniu zadania. Jeśli zadanie zostanie ukończone bez przetwarzania, działanie również otrzyma status Zakończone bez przetwarzania. W przypadku przetwarzania wielokrotnego wszyscy operatorzy muszą ukończyć swoje zadania lub ukończyć je nieprzetworzone, zanim działanie zostanie uznane za ukończone. W takim przypadku działanie jest uznawane za ukończone, gdy co najmniej jedno zadanie zostało ukończone. Jeśli wszystkie zadania zostały ukończone bez przetwarzania, działanie jest również uważane za ukończone bez przetwarzania. W związku z tym musi istnieć co najmniej jedno ukończone zadanie, aby działanie zostało uznane za ukończone. Przetwarzanie wielokrotne może odbywać się równolegle lub sekwencyjnie. W przypadku równoległego przetwarzania wielokrotnego operatorzy mogą przetwarzać swoje zadania w tym samym czasie. W przypadku sekwencyjnego przetwarzania wielokrotnego wszystkie inne otwarte zadania są blokowane, gdy tylko operator rozpocznie przetwarzanie swojego zadania. Jeśli użytkownik ukończy zadanie (z edycją lub bez) lub zawiesi je, zablokowane zadania zostaną ponownie odblokowane. Zapewnia to, że nie więcej niż jeden użytkownik pracuje nad działaniem w tym samym czasie.
Jeśli w definicji działania ustawiony jest tryb edycji ciągłej, warunek wstępny uniemożliwia edycję ciągłą. Przetwarzanie ciągłe jest możliwe tylko wtedy, gdy spełnione są następujące warunki:
- Działanie nie ma warunku wstępnego.
- Działanie rozpoczyna się za 0 milisekund.
- Użytkownik, który ukończy działanie, jest również jednym z edytorów działania uzupełniającego.
Dodatkowe zadania mogą być dodawane do działania w trakcie przetwarzania. Można to zrobić ręcznie, dodając nowych operatorów lub automatycznie, jeśli okres przetwarzania zostanie przekroczony.
Zmiany statusu i warunki
Status działania zmieniany jest zarówno ręcznie przez użytkownika, jak i automatycznie przez silnik workflow. Zmiany statusu inicjowane przez użytkownika są zazwyczaj oparte na rozpoczynaniu lub kończeniu zadań przez użytkownika. Silnik workflow zmienia statusy, gdy okres przetwarzania zostanie osiągnięty lub przekroczony.
Działania tworzone na podstawie definicji działań mogą mieć warunek wstępny. Warunek wstępny działania wyraża, czy działanie powiązane z działaniem zostało już wykonane, czy też stało się zbędne. Warunek wstępny jest sprawdzany za każdym razem, gdy zmienia się status działania. Jeśli warunek wstępny nie jest już spełniony, status działania jest zmieniany na Zakończone bez przetwarzania.
parameters.newObject:modified = parameters.object:modified
Jeśli warunek wstępny nie zostanie spełniony, działanie zmieni status z Zaplanowana na Nieprzetworzona, a silnik workflow nie wyśle wiadomości e-mail.
Nie każda zmiana statusu zadania prowadzi do zmiany statusu działania. Jeśli na przykład działanie jest przetwarzane w trybie wielokrotnego procesowania, działanie zmienia status na W opracowaniu tylko wtedy, gdy przetwarzane jest pierwsze zadanie. Jeśli inny procesor przejmie zadanie do przetwarzania, status działania pozostanie W opracowaniu. Podobnie, działanie w trybie wielokrotnego przetwarzania zmienia status na Zakończone lub Zakończone bez przetwarzania dopiero po ukończeniu ostatniego zadania. Użytkownik, który ukończył działanie poprzez wykonanie zadania, jest zapisywany w atrybucie completeUser działania. Atrybut ten jest już dostępny w funkcji close dla analiz.
W węźle startowym niespełniony warunek wstępny oznacza, że proces nie zostanie uruchomiony. Jeśli węzeł startowy ma wyniki, funkcja validate jest wykonywana przed funkcją create. Umożliwia to sprawdzenie danych wejściowych użytkownika przed utworzeniem instancji procesu.
Jeśli działanie ma jednego lub więcej użytkowników jako operatorów, warunek kontynuacji jest oceniany po zakończeniu działania. Jeśli warunek końcowy nie jest spełniony, użytkownik nie może ukończyć swojego zadania, jeśli doprowadziłoby to również do zakończenia działania. Wszelkie komunikaty dla użytkownika można wysyłać za pomocą polecenia sendMessage zarówno w warunku wstępnym, jak i końcowym. W takim przypadku należy wybrać ustawienie Deklaracja dla pola Warunek wstępny w definicji działania, ponieważ polecenia mogą być używane tylko w deklaracjach.
Działania bez operatora
Przypisanie operatora do działania może nie być możliwe. Jest to możliwe na przykład na stronie jeśli:
- operator jest rolą workflow bez właściciela
- operatorem jest osoba bez przypisanego użytkownika
- operator przetwarzający jest organem i nie znaleziono zastępców lub przedstawicieli w momencie rozwiązania powiązań między partnerami
- operator jest rolą procesu (taką jak właściciel procesu) i ta rola procesu jest niezajęta
Działanie bez edytora nie ma również zadań i dlatego nie może być edytowana przez nikogo. Z tego powodu do działania zawsze musi być przypisany co najmniej jeden operator.
Jeśli podczas tworzenia działania nie zostanie znaleziony żaden operator, używane są role workflow dla administratorów zdefiniowane w funkcji konfiguracji Workflow Management. Jeśli nie można określić operatorów z tymi rolami workflow , administrator jest wprowadzany jako operator. Administrator workflow lub administrator może dowiedzieć się, z jakiego powodu nie znaleziono operatora i przekazać zadanie odpowiedniemu użytkownikowi.
Działania i szablony seryjne
Serie są mapowane jako specjalne działania w systemie. Działanie typu Szablon seryjny służy jako szablon kopii dla działań seryjnych utworzonych na jego podstawie. Początek okresu przetwarzania dla serii to czas, w którym ma zostać utworzone nowe działanie seryjne. Po utworzeniu działania seryjnego początek okresu przetwarzania jest zmieniany na czas, w którym ma zostać utworzone kolejne działanie seryjne. Jeśli nie ma być tworzonych więcej działań seryjnych, szablon seryjny otrzymuje status Zakończony.
Podczas tworzenia działania seryjnego z szablonu seryjnego deklaracje nie są ponownie oceniane. Działanie seryjne otrzymuje zatem swoje właściwości, w tym temat i opis, z szablonu seryjnego. Gdy tworzone jest działanie seryjne, oceniany jest warunek wstępny i warunek serii. Jeśli warunek wstępny nie jest spełniony, działanie seryjne jest pomijane. Jeśli warunek serii nie zostanie spełniony, cała seria zostanie zakończona.
Aby uzyskać większą elastyczność, zamiast definicji działania typu Szablon seryjny można użyć definicji procesu ze zdarzeniem czasomierza. Podobnie jak w przypadku szablonu serii, wzorzec serii może być przechowywany w zdarzeniu czasomierza. Zdarzenie czasomierza generuje nowy token dla każdego punktu w czasie wzorca serii i przekazuje go do następnego węzła (węzłów) przez krawędź wychodzącą.
Przetwarzanie w tle
Po wprowadzeniu zleceń przetwarzania generowane jest działanie, gdy używany jest wewnętrzny harmonogram. Działanie to może być pojedynczym działaniem lub serią działań. Po osiągnięciu okresu przetwarzania działania uruchamiane jest przypisane zlecenie przetwarzania. Działanie zostaje zakończone, gdy zlecenie przetwarzania zostanie pomyślnie wykonane.
Działania utworzone na podstawie definicji działania mogą generować i wyzwalać zlecenia przetwarzania oraz wykonywać aplikacje działające w tle. W tym celu zlecenie przetwarzania jest wprowadzane jako procesor w definicji działania. Po utworzeniu działania tworzone jest również zlecenie przetwarzania. Zlecenie przetwarzania jest zwalniane, gdy jego status zmienia się z Planowane na Do przetworzenia.
Czas zakończenia działania zależy od ustawienia Oczekuje na zadanie przetwarzania w definicji działania. Jeśli pole wyboru nie jest zaznaczone, działanie zostanie zakończone natychmiast po utworzeniu zadania przetwarzania. Jeśli pole wyboru jest aktywne, działanie zostanie zakończone dopiero po wykonaniu zlecenia przetwarzania. W pierwszym przypadku działanie otrzymuje status Zrealizowane, jeśli zlecenie przetwarzania mogło zostać utworzone bez błędów. W drugim przypadku działanie otrzymuje status Zrealizowane, jeśli zlecenie przetwarzania zostało wykonane pomyślnie. W przeciwnym razie działanie otrzymuje status Zakończone bez przetwarzania. Status działania jest zatem niezależny od błędów występujących podczas wykonywania zadania przetwarzania.
Aby zadanie przetwarzania zostało pomyślnie zarejestrowane, definicja działania musi określać aplikację działającą w tle, użytkownika i kolejkę. Aplikacja działająca w tle i jej parametry są przechowywane na zakładce Aplikacja. Użytkownik, który ma zostać wykorzystany dla zadania przetwarzania i kolejka są określane za pomocą poleceń setJobUser i setJobQueue w deklaracjach. Polecenia te zastępują wartości domyślne z funkcji konfiguracji Workflow Management. Należy upewnić się, że użytkownik używany do przetwarzania zadania jest uprawniony do wykonywania aplikacji działającej w tle, w przeciwnym razie przetwarzanie w tle zakończy się błędem.
Jeśli pole wyboru Oczekuje na zadanie przetwarzania jest aktywowane w definicji działania, wyniki aplikacji działającej w tle są dostępne w funkcji close. Poniższa deklaracja ocenia wynik akcji CreateCountLists aplikacji działającej w tle Rozpocznij akcje inwentaryzacyjne (com.cisag.app.inventory.physical.log.PhysicalInventoryCountProcessing) i wyświetla wygenerowaną listę inwentaryzacyjną w dzienniku:
function close(state as Number)
{
var rp as HashMap; /* parametry wyniku */
var clGenerated as Number; /* zliczanie wygenerowanych list */
var clGuids as Guid[]; /* zliczanie identyfikatorów guid listy */
var cl as CisObject(com.cisag.app.inventory.physical.obj.PhysicalInventoryCountList);
rp := cast(HashMap, getJobResult().resultParmeters);
clGenerated := cast(Number, rp.ResultNumberOfSuccessfulResults);
clGuids := cast(Guid[], rp.ResultPhysicalInventoryCountListGuids);
echo(format(clGenerated, „0”) + ” count list(s) generated:”);
for (g : clGuids) {
cl := getByPrimaryKey(CisObject(com.cisag.app.inventory.physical.obj.PhysicalInventoryCountList), g);
echo(cl->PhysicalInventory->Type:code + „-” + cl->PhysicalInventory:number + ” ” + cl:number);
}
}
Wynik znajduje się zazwyczaj w parametrze resultParmeters.
Wyniki aplikacji działającej w tle są wyświetlane w oknie dialogowym właściwości zadania przetwarzania na zakładce Opracowanie po wykonaniu aplikacji działającej w tle.
Zakładka Zlecenie w oknie dialogowym właściwości zawiera również parametry transferu. Jeśli użytkownik chce zautomatyzować zadanie za pomocą aplikacji działającej w tle, takiej jak wysyłanie potwierdzenia zamówienia po zwolnieniu zamówienia sprzedaży, może wprowadzić i zwolnić zamówienie sprzedaży. Następnie wykonać zadanie, które ma zostać zautomatyzowane w tle i zapytać o parametry transferu. Na zakładce Aplikacja definicji działania należy wprowadzić te same wartości parametrów, co w oknie dialogowym właściwości. Artykuł Przetwarzanie zadań zawiera dalsze informacje na ten temat.
Tylko parametry aplikacji zadeklarowane w obiekcie deweloperskim są wyświetlane na zakładce Aplikacja definicji działania. Tylko te zadeklarowane parametry aplikacji mogą być używane w definicji działania. Jeśli w obiekcie deweloperskim brakuje ważnego parametru aplikacji lub jeśli w ogóle nie zadeklarowano tam żadnych parametrów aplikacji, można użyć aplikacji w tle Wywołaj aplikacje batch w workflow (com.cisag.app.general.log.Activity2BatchJob), aby wywołać rzeczywistą aplikację w tle. Aby to zrobić, należy wprowadzić aplikację w tle Wywołaj aplikacje batch w workflow na zakładce Aplikacja definicji działania. W parametrze aplikacji ProcessParameters wprowadzić nazwę techniczną, w tym obszar nazw aplikacji działającej w tle, która ma zostać wywołana. W parametrze aplikacji Parameters należy przekazać parametry aplikacji w tle, która ma zostać wywołana, w postaci tabeli haszującej. Wartości parametrów są przypisywane w deklaracjach. Więcej informacji można znaleźć w artykule Wywołanie aplikacji działających e tle w workflow.
Jeśli działanie generuje dokument końcowy lub dokument raportu, używane są ustawienia użytkownika dla zlecenia przetwarzania. Generowanie dokumentu musi jednak znać szablon dokumentu końcowego, który ma zostać użyty. Dlatego zawsze należy ustawić polecenie setJobVoucherDocumentOutputOptions(true), aby użyć domyślnego szablonu dokumentu końcowego dla odbiorcy. Jeśli parametr polecenia ma wartość true, ustawienia wyjściowe z szablonu dokumentu końcowego są używane zamiast ustawień użytkownika. Do wersji 6.2 należy stosować ustawienia wyjściowe z szablonu dokumentu końcowego. Od wersji 6.3 można również użyć poleceń setJobVoucherDocumentOutputOptions(false) i setJobDeliveryMethod, aby użyć ustawień wyjściowych użytkownika dla określonego nośnika wyjściowego. Od wersji 6.3 dostępne są również dalsze polecenia umożliwiające określenie indywidualnych ustawień wyjściowych dla użytkownika, podobnie jak na zakładce Ustawienia wyjściowe w oknie dialogowym aplikacji. Jeśli polecenie setJobVoucherDocumentOutputOptions(true) zostało wysłane podczas tworzenia dokumentu w celu użycia standardowego szablonu dokumentu końcowego dla odbiorcy, ustawienia wyjściowe użytkownika są stosowane tylko wtedy, gdy w szablonie dokumentu końcowego wybrano ustawienie Z ustawień użytkownika. Artykuł Język skryptowy systemu: Funkcje workflow opisuje te i inne polecenia, które mogą być używane w definicjach działań ze zleceniem przetwarzania jako operator w rozdziale Funkcje dla węzłów usług.
Status błędu działania
W przypadku wystąpienia błędu podczas przetwarzania działania w silniku workflow, działanie zostaje zatrzymane i otrzymuje status błędu Niepoprawny. Działanie jest wykluczane z dalszego przetwarzania w silniku workflow. Zapobiega to wielokrotnym próbom przetwarzania działań, które prowadzą do błędów. Zatrzymane działania mogą być dalej przetwarzane ręcznie, tj. na przykład zakończone.
Aplikacje Lista: Działania/Baza danych OLTP i Lista: Działania/Baza danych repozytorium mogą być używane do wyszukiwania zatrzymanych działań. Po usunięciu przyczyny błędu można użyć aplikacji Działania, aby ponownie uruchomić działania ze statusem błędu Błędnie.
Ocena zdarzeń
Zdarzenia stanowią podstawę do tworzenia działań z definicji działań. Zdarzenie jest wyzwalane przez zmianę stanu w aplikacji, przez system lub przez użytkownika. Zdarzenie występuje w określonym czasie i zawiera dodatkowe parametry, które dodatkowo opisują zdarzenie.
Obsługa zdarzeń w silniku workflow przetwarza zdarzenia z możliwie najkrótszym opóźnieniem. Zdarzenia są przetwarzane asynchronicznie. W związku z tym nie są one przetwarzane jednocześnie z wyzwoleniem zdarzenia, ale tylko wtedy, gdy przyczyna, która doprowadziła do wyzwolenia zdarzenia, została już zakończona. Oznacza to, że przyczyna ta mogła już zostać anulowana przez inne zmiany. W definicji działania warunek wstępny może być użyty do sprawdzenia, czy istnienie działania jest nadal uzasadnione.
Zdarzenia nie są zapisywane na stałe. Jeśli serwer aplikacji, na którym zdarzenie zostało wywołane, zostanie zamknięty lub w inny sposób zakończony przed oceną zdarzenia, zdarzenie zostanie utracone, a działanie nie będzie mogło zostać wygenerowane.
Zaprogramowane wydarzenia
W przypadku specjalnych przypadków użycia zdarzenia mogą być wbudowane bezpośrednio w aplikację lub klasę logiczną. Te tak zwane zaprogramowane zdarzenia mogą być również dodawane przez partnerów w ramach adaptacji lub rozwiązań branżowych. Zaprogramowane zdarzenie jest wbudowane w kod źródłowy Java aplikacji przez programistę.
Zaprogramowane zdarzenie jest obiektem deweloperskim i jest rejestrowane za pomocą aplikacji Obiekty deweloperskie. Do wyzwalania zaprogramowanych zdarzeń dostępny jest interfejs programowania.
Zaprogramowane zdarzenia mogą mieć dowolne parametry. Parametry zaprogramowanego zdarzenia można sprawdzić w aplikacji Obiekty deweloperskie.
Wyzwolenie zaprogramowanego zdarzenia zajmuje zazwyczaj stosunkowo niewiele czasu. Dla porównania, każda definicja działania, która ocenia zdarzenie, zajmuje stosunkowo dużo czasu. Podczas wprowadzania definicji działania należy zauważyć, że ocena warunku przejścia wymaga czasu. Zdarzenia, które nie są analizowane przez żadną definicję działania, nie powodują zatem problemu z szybkością.
Im bardziej specyficzne jest zdarzenie i im rzadziej jest wyzwalane, tym mniejsza jest utrata wydajności. Jednak bardzo specyficzne zdarzenia mają tylko bardzo specyficzny cel aplikacji. W przeciwieństwie do tego, niespecyficzne zdarzenia mogą być ograniczone przy użyciu warunków w definicji działania. Jednak ocena tych warunków jest bardziej złożona niż sprawdzanie ich w aplikacji, która wyzwala zdarzenie. Przy podejmowaniu decyzji o tym, jak specyficzne jest zdarzenie, należy rozważyć szybkość w stosunku do użyteczności zdarzenia. W przypadku bardzo specyficznych zdarzeń i zdarzeń, które wymagają złożonej oceny w warunku przejścia i są często wyzwalane, zaleca się zatem zaimplementowanie oddzielnego zaprogramowanego zdarzenia jako części adaptacji.
W aplikacji Lista: Zaprogramowane zdarzenia można sprawdzić, które zaprogramowane zdarzenia istnieją w systemie i są używane w definicjach działań.
Zdarzenie Zmiana jednostki biznesowej
Silnik systemu wyzwala zdarzenie Zmiana jednostki biznesowej, gdy instancja obiektu biznesowego jest tworzona, zmieniana lub usuwana. To zdarzenie dostarczane przez system może być używane do rozwiązywania prostych zadań. Problem ze zdarzeniami tego typu polega na tym, że są one wyzwalane stosunkowo niespecyficznie. Oznacza to, że zdarzenie jest wyzwalane za każdym razem, gdy instancja obiektu biznesowego jest zmieniana. Zdarzenie to nie zawsze jest powiązane przyczynowo z konkretnym procesem biznesowym. Ogólnie rzecz biorąc, jest ono jednak przeznaczone do reagowania na bardzo konkretne procesy. Jest to jeden z powodów, dla których definicja działania z warunkiem przejścia może być powiązana ze zdarzeniem.
Działanie jest tworzone z definicji działania tylko wtedy, gdy wystąpi odpowiednie zdarzenie i zostanie spełniony warunek przejścia. Dostęp do starego i nowego stanu zmienionego obiektu można uzyskać w celu oceny zdarzenia, tj. w szczególności warunku przejścia.
parameters.oldObject:status <> parameters.newObject:status
Parametr zdarzenia oldObject zawiera kopię instancji obiektu biznesowego bezpośrednio przed transakcją bazy danych, która wywołała zdarzenie. Parametr zdarzenia newObject zawiera kopię instancji obiektu biznesowego bezpośrednio po transakcji bazy danych. Parametr object odnosi się do instancji obiektu biznesowego. Zastosowanie object prowadzi zatem do porównania z aktualnym stanem instancji obiektu biznesowego w momencie oceny. Ponieważ zdarzenia są przetwarzane asynchronicznie, ważne jest, aby użyć odpowiednich parametrów zdarzenia dla zadania w warunku przejścia.
Atrybuty wielojęzyczne są przenoszone w zestawie języków dla bazy danych. Jeśli, na przykład, opis artykułu zostanie zmieniony w jednym z zainstalowanych języków dodatkowych, wywołane zostanie zdarzenie Jednostka biznesowa z podtypem Change, ale parameters.oldObject:description i parameters.newObject:description będą miały tę samą wartość, a mianowicie opis w głównym języku bazy danych.
Zwłaszcza podczas tworzenia definicji procesów i działań przydatne może być rejestrowanie wyzwolonego zdarzenia za pomocą funkcji echo, aby upewnić się, że zdarzenie zostało wyzwolone zgodnie z oczekiwaniami. Ponieważ funkcja echo zawsze zwraca wartość true, warunek przejścia w poprzednim przykładzie można rozszerzyć w następujący sposób:
echo(definition:code) and echo(„transition condition”) and echo(event) and (parameters.oldObject:status <> parameters.newObject:status)
Polecenie echo powoduje wysłanie zdarzenia do pliku dziennika na serwerze aplikacji, na którym zdarzenie zostało wywołane. Jeśli echo jest używane w warunku wstępnym, dane wyjściowe są tworzone w pliku dziennika na serwerze aplikacji, na którym działa silnik workflow lub harmonogram. Parametr definition odwołuje się do definicji działania. Do definicji procesu można odwołać się na przykład poprzez relację definition->ProcessDefinition. Numer activity:number wylosowany dla instancji działania może być również odpytywany w funkcji create. Numer procesu nie jest jeszcze dostępny w węźle początkowym, ponieważ instancja procesu nie została jeszcze utworzona w momencie wywołania funkcji create.
Zdarzenie typu Jednostka biznesowa rozróżnia podtypy wstawiania, zmiany u usuwania instancji obiektu biznesowego. Dlatego należy wybrać odpowiedni podtyp dla zadania w definicji działania. Można również wybrać różne podtypy dla tego samego obiektu biznesowego w tej samej definicji działania.
Należy pamiętać, że zdarzenie z podtypem Delete jest wyzwalane tylko wtedy, gdy instancja obiektu biznesowego zostanie usunięta z bazy danych. W przypadku obiektów biznesowych, dla których można ustawić wskaźnik usunięcia (takich jak obiekt biznesowy Partner), oznacza to, że zdarzenie z podtypem Delete jest wyzwalane tylko wtedy, gdy partner jest reorganizowany. Jeśli użytkownik chce zareagować na ustawienie wskaźnika usunięcia, może na przykład użyć następującego warunku przejścia dla zdarzenia z podtypem Change:
isNull(parameters.oldObject.updateInfo.deleteUser) and not
isNull(parameters.newObject.updateInfo.deleteUser)
Ponieważ wskaźnik usunięcia jest przechowywany w atrybutach updateInfo.deleteUser i updateInfo.deleteTime, ten warunek przejścia jest spełniony, jeśli zmieniona instancja obiektu biznesowego nie miała wskaźnika usunięcia przed zmianą, ale miała wskaźnik usunięcia po zmianie.
Niektóre dokumenty końcowe są tworzone przy użyciu kilku transakcji w bazie danych. Na przykład faktura sprzedaży jest najpierw generowana bez numeru. Dopiero w kolejnej transakcji w bazie danych pobierany jest numer dokumentu ze schematu numeracji i zapisywany na fakturze sprzedaży. Jeśli na przykład powiadomienie ma zostać wysłane dla wygenerowanych faktur sprzedaży o kwocie brutto przekraczającej 10 000 EUR, a definicja działania reaguje na zdarzenie z podtypem Insert, prawdopodobnie numer faktury sprzedaży jest nadal nieznany w momencie oceny. Aby upewnić się, że powiadomienie ma miejsce tylko wtedy, gdy faktura sprzedaży została całkowicie wygenerowana, definicja działania może reagować na zdarzenie zarówno z podtypem Insert, jak i Change. Warunek przejścia zdarzenia z podtypem Insert:
parameters.newObject:number<>””
oraz warunek przejścia zdarzenia z podtypem Change:
parameters.oldObject:number=”” i parameters.newObject:number<>””
pozwala upewnić się, że wysyłane jest tylko jedno powiadomienie.
Niektóre dokumenty końcowe są przetwarzane w blokach. Na przykład zamówienie sprzedaży jest przetwarzane w blokach po 16 pozycji. Każdy blok 16 pozycji reprezentuje oddzielną transakcję w bazie danych. Można to rozpoznać na przykład po tym, że zamówienie sprzedaży jest automatycznie zapisywane po wprowadzeniu 16 pozycji zamówienia sprzedaży. Innym wskaźnikiem przetwarzania blokowego jest obecność atrybutu statusBackup w obiekcie biznesowym dokumentu. Jeśli status dokumentu końcowego ma zostać zmieniony, a dokument ma więcej pozycji niż można przetworzyć w jednym bloku, dokument końcowy jest przenoszony do statusu Niepoprawny z pierwszym blokiem, a poprzedni status jest zapisywany w atrybucie statusBackup. Dopiero po przetworzeniu ostatniego bloku dokument końcowy jest przenoszony do nowego statusu Zwolniony, a wartość w atrybucie statusBackup jest usuwana.
Możliwy warunek przejścia dla definicji działania, który powinien reagować na zmianę statusu dokumentu np. z W opracowaniu (1) na nowy status Wydany (2), mógłby zatem wyglądać następująco:
(parameters.oldObject:status=1 and parameters.newObject:status=2) or
(parameters.oldObject:status=6 and parameters.newObject:status=2 and parameters.oldObject:statusBackup=1)
Druga część warunku przejścia sprawdza, czy status zmienia się z wartości Niepoprawny (6) na Zwolniony (2), a poprzedni status przechowywany w atrybucie statusBackup to W opracowaniu (1). Dla jasności, warunek przejścia może być również podzielony na dwa zdarzenia z podtypem Change.
Zdarzenie Zmiana jednostki biznesowej może być również zastosowane do jednostek zależnych jednostki biznesowej. W takim przypadku, oprócz starego i nowego statusu zmienionej jednostki zależnej (w parametrach oldObject i newObject), dostępny jest również stary i nowy status powiązanej jednostki biznesowej (w parametrach oldEntity i newEntity). Informacje na temat parametrów zdarzeń typu Jednostka biznesowa można znaleźć w artykule Język skryptowy systemu.
Jeśli podczas oceny warunku przejścia wystąpi błąd, warunek przejścia zostanie uznany za niespełniony. W takim przypadku nie jest generowane żadne działanie. Natomiast warunek wstępny z błędem uznaje się za spełniony. Jeśli działanie może zostać pomyślnie utworzone, błąd w warunku wstępnym nie prowadzi do automatycznego zakończenia działania bez zmiany.
Zdarzenie Zmiana jednostki biznesowej jest zazwyczaj stosunkowo niespecyficzne. Jeśli użytkownik korzysta z tego zdarzenia, powinien wziąć pod uwagę wydajność całego systemu.
Jeśli zadanie ze zdarzeniem Zmiana jednostki biznesowej prowadzi do bardzo dużych strat prędkości, specjalnie zaprogramowane zdarzenie może być w stanie rozwiązać problem bardziej efektywnie. Jednak zaprogramowane zdarzenia zawsze oznaczają programowanie dostosowywania, a zatem większy wysiłek w zakresie tworzenia i konserwacji.
Użytkownik może dowiedzieć się, które zdarzenia typu Jednostka biznesowa są używane w definicjach działań w systemie, korzystając ze szczegółowego wyszukiwania definicji zdarzeń w aplikacji Lista: Definicje działania.
Zdarzenie Akcja użytkownika
Zdarzenie typu Akcja użytkownika jest wyzwalane, gdy użytkownik uruchamia proces za pomocą pozycji Rozpocznij proces w menu kontekstowym jednostki biznesowej. Typ Akcja użytkownika jest dostępny tylko w definicjach działania, które reprezentują zdarzenie początkowe lub zdarzenie pośrednie definicji procesu. Nazwa definicji procesu jest używana dla wpisu w menu kontekstowym.
Jeśli warunek przejścia nie jest spełniony, proces nie może zostać uruchomiony, a odpowiedni wpis w menu kontekstowym jednostki biznesowej jest dezaktywowany. Poniższy warunek przejścia uniemożliwia działanie użytkownika w zamówieniu sprzedaży o statusie W opracowaniu (1):
parameters.object:status<>1
Jeśli proces nie jest wyświetlany w menu kontekstowym użytkownika, może to być spowodowane tym, że definicja procesu nie jest aktywna. Jeśli definicja procesu jest powiązana z szablonem definicji procesu, w którym przechowywana jest aplikacja specjalnego zastosowania Definicja procesu, może to również wynikać z faktu, że użytkownik nie jest uprawniony do otwarcia tej aplikacji.
Akcja użytkownika może być również autoryzowana przy użyciu ról workflow. Na przykład następujący warunek przejścia oznacza, że tylko właściciele roli workflow MANAGERS mogą rozpocząć proces. Pozycja w menu kontekstowym jest nieaktywna dla wszystkich innych użytkowników:
contains(resolveRole(„MANAGERS”), parameters.userGuid)
Jeśli ocena warunku przejścia zwróci wartość null, warunek przejścia nie zostanie uznany za spełniony i proces nie będzie mógł zostać uruchomiony. Jeśli ocena warunku przejścia prowadzi do błędu wykonania, komunikat o błędzie jest wyświetlany natychmiast po wybraniu pozycji w menu kontekstowym.
Poszczególne komunikaty mogą być wyprowadzane w funkcji validate, ponieważ funkcja ta jest również wywoływana, jeśli definicja działania nie ma wyników. Z drugiej strony, ostrzeżenie lub komunikat o błędzie w funkcji create zawsze uniemożliwia uruchomienie.
Informacje na temat parametrów zdarzeń typu Akcja użytkownika można znaleźć w artykule Język skryptowy systemu.
Aby sprawdzić, jakie definicje działań są używane dla zdarzenia typu Akcja użytkownika w systemie, należy skorzystać z wyszukiwania szczegółowego definicji zdarzeń w aplikacji Lista: Definicje działania.
Brak zdarzenia
Definicja działania bez definicji zdarzenia nie reaguje na zdarzenie. W związku z tym nie są generowane żadne działania. Jeśli definicja działania reprezentuje węzeł początkowy procesu, proces można uruchomić tylko ręcznie. Ponieważ taki proces nie ma warunku przejścia, definicja działania może być autoryzowana tylko przy użyciu szablonu definicji procesu i wykorzystaniu specjalnego zastosowania Definicja procesu.
Podobnie jak w przypadku zdarzenia typu Akcja użytkownika, poszczególne komunikaty mogą być wysyłane w funkcji validate. Jednak ostrzeżenie lub komunikat o błędzie w funkcji create zawsze uniemożliwia uruchomienie procesu. Jeśli proces jest uruchamiany ręcznie za pośrednictwem aplikacji Procesy, wszelkie komunikaty typu informacja nie są wyświetlane użytkownikowi, ponieważ dokowane okno informacji jest czyszczone po załadowaniu instancji uruchomionego procesu.
Informacje na temat parametrów dostępnych podczas uruchamiania procesu bez zdarzenia można znaleźć w artykule Język skryptowy systemu.
Aplikacja w tle Wywołaj zdarzenia
Aplikacja działająca w tle Wywołaj zdarzenia (com.cisag.sys.workflow.log.EventGenerator) wyzwala zdarzenie Wywołanie zdarzenia przez aplikację w tle Wywołaj zdarzenia (com.cisag.pgm.workflow.InstanceEvent) dla wszystkich instancji obiektów biznesowych wybranych przez instrukcję OQL. Aplikacja działająca w tle może być wykonywana jednorazowo za pomocą zlecenia przetwarzania lub, na przykład, regularnie zgodnie z wzorcem serii. Działania mogą być generowane przy użyciu definicji działań, które zarejestrowały się dla wywołanego zdarzenia. Więcej informacji można znaleźć w artykule Wywołaj zdarzenia.
Silnik workflow sprawdza warunek przejścia wszystkich definicji działań, które reagują na wywołane zdarzenie z tym samym podtypem. Na przykład, jeśli 10 definicji działań reaguje na zdarzenie Wywołanie zdarzeń dla bazy OLTP (com.cisag.pgm.workflow.GenericOLTPEvent) bez podtypu (podtyp 0), a zdarzenie jest wyzwalane przez działającą w tle aplikację Wywołaj zdarzenia (com.cisag.sys.workflow.log.EventGenerator) dla 1000 klientów, wówczas ocenianych jest 10 000 warunków przejścia. Może to prowadzić do znacznych strat wydajności i opóźnień między wyzwoleniem zdarzenia a wygenerowaniem działania.
Zdarzenia są analizowane w kolejności, ale nie są trwale przechowywane w bazie danych. Jeśli serwer aplikacji, na którym zdarzenie zostało wyzwolone, zostanie zamknięty przed przeanalizowaniem wszystkich zdarzeń, zdarzenia, które nie zostały przeanalizowane, zostaną utracone. Dlatego należy starać się zminimalizować zarówno liczbę definicji działań, które reagują na ten sam podtyp zdarzenia, jak i całkowitą liczbę wyzwalanych zdarzeń. Zamiast wyzwalać zdarzenie dla każdego klienta w aplikacji działającej w tle Wywołaj zdarzenia i tylko decydować w warunku przejścia, czy działanie powinno zostać wygenerowane, czy nie, często lepiej jest wyzwalać zdarzenia tak konkretnie, jak to możliwe. Oznacza to, że ogólnie wyzwalanych jest mniej zdarzeń, a warunki przejścia są prostsze lub nawet puste. Jeśli nie można zmapować prostego warunku przejścia za pomocą OQL, zamiast aplikacji działającej w tle Wywołaj zdarzenia można użyć definicji procesu. Na przykład węzeł skryptu może analizować klientów i wyzwalać zdarzenie dla każdego klienta, dla którego ma zostać utworzone działanie przy użyciu funkcji fireEvent. Jeśli zdarzenie Wywołanie zdarzeń dla bazy OLTP oferuje podtyp w używanej wersji, należy użyć osobnego podtypu dla każdego przypadku użycia, który reaguje na to zdarzenie.
Zmiana obiektów biznesowych
Działania workflow zazwyczaj mają jedynie dostęp do odczytu obiektów biznesowych. Gdy tylko działanie wywoła metodę w Javie, która próbuje zmienić instancję obiektu biznesowego, pojawia się wyjątek, a generowanie działania kończy się błędem. Dzięki atrybutom workflow i polom zdefiniowanym przez użytkownika (pola dodatkowe), Workflow Management oferuje dwie opcje trwałego przechowywania informacji z działania w obiekcie biznesowym. Te dwie opcje zostały opisane w tym rozdziale. Więcej informacji na temat korzystania z atrybutów workflow i pól zdefiniowanych przez użytkownika w definicjach działań można znaleźć w artykule Język skryptowy systemu: Funkcje OLTP.
Atrybuty workflow
Atrybuty workflow mogą być wprowadzane w systemie z poziomem wersjonowania 7 i używane jako produktywny system testowy lub system produktywny. Nie jest do tego wymagana żadna wiedza programistyczna. Podobnie jak atrybut zdefiniowany przez użytkownika, atrybut workflow jest również zapisywany przy użyciu obiektu biznesowego, który jest sklasyfikowany jako suplement zarządzany.
Suplement zarządzany z atrybutami zdefiniowanymi przez użytkownika ma zastosowanie Standard, a suplement zarządzany z atrybutami workflow ma zastosowanie Workflow. Można wprowadzić dowolną liczbę takich suplementów workflow. Dystrybucja atrybutów workflow w kilku suplementach workflow ma tę zaletę, że gdy działanie zapisuje atrybuty workflow po raz pierwszy, a tym samym tworzy nową instancję suplementu workflow, atrybuty workflow należące do innych suplementów workflow nie są wstępnie przypisane z wartościami domyślnymi. Tworzenie zbyt wielu suplementów workflow dla tego samego obiektu biznesowego może zmniejszyć wydajność systemu, ponieważ jego suplementy są ładowane z bazy danych wraz z obiektem biznesowym. Jeśli atrybuty workflow dla różnych procesów workflow są rejestrowane w tym samym suplemencie workflow, korzystne jest, jeśli każdy proces workflow ma atrybut, którego wartość domyślna wskazuje, czy instancja procesu przypisała wartości do atrybutów workflow, czy nie.
Przykładem takiego atrybutu workflow jest status zatwierdzenia zamówienia. Pusty ciąg znaków oznacza, że proces zatwierdzania zamówienia nie został jeszcze rozpoczęty. Jeśli użytkownik rozpocznie proces zatwierdzania, węzeł początkowy powinien przypisać atrybutowi workflow wartość inną niż wartość domyślna, taką jak W trakcie przeglądu. Zamiast ciągu znaków, status zatwierdzenia może być również mapowany za pomocą wartości liczbowych. W tym przypadku domyślna wartość 0 oznaczałaby, że nie ma jeszcze procesu zatwierdzania zamówienia, a wartość 1 mogłaby oznaczać, że zamówienie jest w trakcie przeglądu.
Atrybuty workflow mogą być dodawane do dostosowywanych aplikacji i wyświetlane, pod warunkiem, że zarządzany dodatek należy do widoku obiektu aplikacji. W przeciwieństwie do niestandardowego atrybutu, atrybut workflow nie może być edytowany ani w aplikacji, ani poprzez import. Tylko definicje działań mogą przypisać wartość do atrybutów workflow. Istnieje zatem wyraźny podział odpowiedzialności między atrybutami zdefiniowanymi przez użytkownika a atrybutami workflow.
Pola zdefiniowane przez użytkownika
W wielu aplikacjach pola zdefiniowane przez użytkownika mogą być tworzone na zakładce Inne pola w celu wprowadzenia dodatkowych informacji o jednostce biznesowej powiązanej z aplikacją. Pola zdefiniowane przez użytkownika są zawsze powiązane z odpowiednią jednostką biznesową (i ewentualnie określonym widokiem). Pola zdefiniowane przez użytkownika mają typ pola. Dla każdego typu pola dostępne są odpowiednie funkcje w języku skryptowym systemu. Zazwyczaj oferowana jest także dodatkowa funkcja dla typów pól z listą wartości. Funkcje są podzielone na następujące kategorie:
- Funkcje Getter zwracają wartość pola zdefiniowanego przez użytkownika.
- Funkcje Setter przypisują wartość do pola zdefiniowanego przez użytkownika.
- Funkcja Reset resetuje pole zdefiniowane przez użytkownika do wartości domyślnej.
- Funkcje Validate sprawdzają, czy dana wartość może zostać przypisana do innego pola.
dboString(„EXTPartner”, loadPartner(„10010”), „REFERENCE”)
zwraca wartość zdefiniowanego przez użytkownika pola o nazwie REFERENCE dla partnera 10010, a wyrażenie
setDboString(„EXTPartner”, loadPartner(„10010”), „REFERENCE”, „Hello World!”)
przypisuje wartość Hello World! do tego samego pola zdefiniowanego przez użytkownika.
Jak pokazują te dwa przykłady, nazwa schematu składa się z przedrostka EXT, po którym następuje nazwa jednostki biznesowej.
Wysyłanie wiadomości e-mail
Wiadomość e-mail to wiadomość wysyłana w ramach workflow. Przykładem wiadomości e-mail jest wiadomość informująca klienta o nowej dacie dostawy. Powiadomienie e-mail to wiadomość e-mail wysyłana automatycznie po wystąpieniu określonych stanów procesu w celu poinformowania osób zaangażowanych w proces. Należy zapoznać się z tym rozdziałem, aby dowiedzieć się, jak skonfigurować wysyłanie wiadomości e-mail i powiadomień e-mail.
Wiadomości e-mail
Definicje działania typu Wiadomość e-mail, Węzeł e-mail lub Interaktywny węzeł e-mail mogą wysyłać wiadomości e-mail. Jeśli definicja działania ma jednego lub więcej użytkowników jako edytorów, wiadomość e-mail jest wysyłana dla każdego użytkownika na adres e-mail użytkownika przechowywany w aplikacji Panel System. Jeśli w definicji działania wybrano operatora System, należy określić odbiorcę za pomocą polecenia setMailRecipientsTo. Alternatywnie można również użyć poleceń setMailRecipientsCC i setMailRecipientsBCC. Jeśli wiadomość e-mail ma kilku odbiorców, należy oddzielić adresy e-mail przecinkiem. Adres e-mail przechowywany w aplikacji Serwer poczty serwera e-mail oznaczonego jako domyślny jest używany jako adres e-mail odpowiedzi. Te i inne cechy wiadomości e-mail można również określić za pomocą poleceń w deklaracjach. Opis poleceń dla wiadomości e-mail można znaleźć w artykule Język skryptowy systemu: Funkcje workflow.
Definicja działania typu Wiadomość e-mail nie generuje działania. Ponieważ działanie reprezentuje również dowód wysłania wiadomości e-mail, definicja procesu z węzłem e-mail jest preferowana, jeśli wymagany jest dowód.
Jeśli w definicji działania wybrano operatora innego niż System, wiadomości e-mail są wysyłane w języku treści danego odbiorcy. Jeśli wybrano operator System, używany jest domyślny język systemu. Aby wysłać wiadomość e-mail w języku partnera, który nie jest użytkownikiem systemu, można użyć poleceń zmiany języka treści i wyświetlania. Poniższy przykład zmienia język wyświetlania na język korespondencji partnera 10010:
var language := loadPartner(„10010”)->Language:isoCode;
if (not isNull(language)) {
setNLSDisplayLanguage(language);
}
Warunek if oznacza, że język wyświetlania jest zmieniany tylko wtedy, gdy u partnera zapisany jest język korespondencyjny. Opis funkcji zmiany języka wyświetlania i treści, a także kilka przykładów użycia można znaleźć w dokumentacji Język skryptowy systemu: Funkcje podstawowe.
Powiadomienia e-mail
Mechanizm workflow może powiadamiać użytkowników o istotnych zmianach statusu przypisanego im zadania. Wiadomości e-mail mogą być wysyłane w następujących momentach:
- Jeśli działanie otrzyma status Do realizacji, powiadomienia e-mail mogą być wysyłane do wszystkich użytkowników posiadających zadanie.
- Jeśli działanie otrzyma status Zaległe lub Zaległe w opracowaniu, powiadomienia e-mail mogą być wysyłane do wszystkich użytkowników, którzy jeszcze nie ukończyli swojego zadania.
- Jeśli działanie otrzyma status Zaległe lub Zaległe w opracowaniu, powiadomienie e-mail może zostać wysłane do osób odpowiedzialnych za proces.
- Jeśli proces otrzyma status Zaległe, powiadomienie e-mail może zostać wysłane do osób odpowiedzialnych za proces.
- Jeśli w procesie wystąpi błąd i proces zakończy się za pośrednictwem węzła błędu, powiadomienie e-mail może zostać wysłane do osób odpowiedzialnych za proces.
- Jeśli w procesie wystąpi błąd i proces zakończy się za pośrednictwem węzła błędu, powiadomienie e-mail może zostać wysłane do administratora (administratorów) workflow.
- Jeśli zadanie zostanie przekazane innemu użytkownikowi, może on otrzymać powiadomienie e-mail.
- Jeśli zadanie zostanie przekazane innemu użytkownikowi, powiadomienie e-mail może zostać wysłane do pierwotnego użytkownika, aby poinformować go o zmianach statusu przekazanego zadania.
Ponadto definicja procesu może również zawierać inne węzły e-mail, które wysyłają wiadomości e-mail do uczestników procesu w dowolnym momencie lub gdy wystąpi jakikolwiek status procesu. Na przykład węzeł wiadomości e-mail może informować właściciela (właścicieli) procesu, jeśli krok procesu lub punkt kontrolny w procesie zostanie osiągnięty zbyt późno, a cały proces jest zagrożony eskalacją. Definicje działań w procesie mogą również wykorzystywać polecenia takie jak setActivityWorkDuration i setActivityPriority do obliczania planowanego czasu trwania przetwarzania lub priorytetu działania, które ma zostać utworzone przy użyciu czasów wykonania poprzednich kroków procesu. Jeśli poprzedni punkt kontrolny został osiągnięty zbyt późno, czas trwania przetwarzania zostanie odpowiednio skrócony lub priorytet zostanie zwiększony.
To, czy powiadomienie e-mail zostanie faktycznie wysłane do użytkownika w odpowiednim czasie, zależy zarówno od ustawień w definicji działania lub definicji procesu, jak i od ustawień użytkownika odbiorcy.
W ustawieniach użytkownika można ustawić dla bazy danych OLTP i bazy danych repozytorium, czy powiadomienia e-mail mają być wysyłane, a jeśli tak, to z jakiego priorytetu.
Jeśli wartość Tak jest ustawiona dla opcji Powiadomienie e-mail i wartość 5 (średni priorytet) jest ustawiona dla opcji Dla działań z priorytetu, wówczas wiadomość e-mail jest wysyłana dla wszystkich działań o priorytecie 5 lub wyższym (tj. priorytecie <= 5).
Jeśli opcja Powiadomienie e-mail jest ustawiona na Nie, wiadomości e-mail nie będą wysyłane.
W przypadku definicji działania ustawienia Wyślij e-mail i Powiadom operatora po przekroczeniu limitu czasu z wartością Zawsze lub Nigdy nie uwzględniają ustawień użytkownika. Definicja działania i definicja procesu oferują podobne pola do powiadamiania właściciela procesu i administratorów workflow.
Szablony wiadomości e-mail
Workflow wysyła wiadomości e-mail w formacie HTML. Wszystkie wiadomości e-mail wysyłane przez workflow są generowane na podstawie szablonu wiadomości e-mail zależnego od bazy danych, który można sparametryzować za pomocą danych kontekstowych.
Miejsce przechowywania
Standardowy szablon wiadomości e-mail w języku niemieckim jest przechowywany pod nazwą Mailtemplate_en.html w Knowledge Store bieżącego systemu, w folderze Documents/Workflow standardowego obszaru roboczego, który ma taką samą nazwę jak bieżąca baza danych. W przypadku innych języków kod ISO de w nazwie pliku należy zastąpić żądanym kodem ISO. W Knowledge Store rozróżniana jest wielkość liter. Dlatego plik musi mieć dokładnie określoną pisownię.
W zależności od kontekstu użycia, inne szablony są używane do powiadomień e-mail. Jeśli szablon nie istnieje w folderze Documents/Workflow, używany jest standardowy szablon z tabeli ciągów com.cisag.sys.workflow.template.MailTemplates.
Konteksty użytkowania
Poniżej opisano, który szablon jest używany w jakim kontekście użytkowania:
- ActivityTimeoutTemplate – szablon ten jest używany, gdy działanie zostanie zakończone, aby poinformować użytkowników o otwartym zadaniu. Szablon ten jest również używany dla wszystkich operatorów dodanych w ramach działań następczych. Jeśli nie można znaleźć żadnego szablonu, używany jest szablon z tabeli ciągów znaków ze stałą ACTIVITY_TIMEOUT.
- AdhocMailtemplate – jest to standardowy szablon dla działań, które nie zostały utworzone przez silnik workflow, ale przez użytkownika. Szablon ten może zatem odnosić się do twórcy działania. Jeśli nie można znaleźć żadnego szablonu, używany jest szablon z tabeli ciągów znaków ze stałą ADHOC.
- DelegationBeginMailtemplate – ten szablon jest wysyłany do zastępcy na początku nieobecności. Szablon ten może zatem zawierać parametry związane z zastępstwem lub nieobecnością. Jeśli nie można znaleźć żadnego szablonu, używany jest szablon z tabeli ciągów znaków ze stałą DELEGATION_BEGIN.
- DelegationEndMailtemplate – ten szablon jest wysyłany do zastępcy, gdy nieobecność jest anulowana. Szablon ten może zatem zawierać parametry związane z zastępstwem lub nieobecnością. Jeśli nie można znaleźć żadnego szablonu, używany jest szablon z tabeli ciągów znaków ze stałą DELEGATION_END.
- MailOnlyMailtemplate – jest to domyślny szablon dla działań utworzonych z definicji działania typu Wiadomość e-mail lub Węzeł wiadomości e-mail. Szablon nie powinien zawierać żadnych parametrów związanych z zadaniem, działaniem lub procesem. Jeśli nie można znaleźć szablonu, używany jest szablon z tabeli ciągów znaków ze stałą MAIL_ONLY.
- Mailtemplate – jest to standardowy szablon dla działań, które zostały utworzone na podstawie definicji działania i nie są powiązane z procesem. Szablon ten nie powinien zawierać żadnych parametrów odnoszących się do procesu. Szablon jest używany, gdy status działania zmienia się na Do opracowania, aby poinformować użytkowników o zadaniu. Jeśli nie można znaleźć żadnego szablonu, używany jest szablon z tabeli ciągów znaków ze stałą DEFAULT.
- ProcessErrorTemplate – ten szablon jest używany podczas kończenia procesu za pośrednictwem węzła błędu w celu poinformowania właściciela procesu lub administratorów workflow. Szablon ten może zawierać przykładowo parametry związane z błędem. Jeśli nie można znaleźć żadnego szablonu, używany jest szablon z tabeli ciągów znaków ze stałą PROCESS_ERROR.
- ProcessMailtemplate – jest to standardowy szablon dla działań, które zostały utworzone na podstawie definicji działania i są węzłami procesu. Szablon ten może zatem zawierać parametry odnoszące się do procesu. Ten szablon jest używany, gdy status działania zmienia się na Do opracowania, aby poinformować użytkowników o zadaniu. Jeśli nie można znaleźć żadnego szablonu, używany jest szablon z tabeli ciągów znaków ze stałą DEFAULT.
- ProcessTimeoutTemplate – ten szablon jest używany, gdy wystąpi przekroczenie limitu czasu procesu w celu poinformowania osoby odpowiedzialnej za proces. Jeśli nie można znaleźć żadnego szablonu, używany jest szablon z tabeli ciągów znaków ze stałą PROCESS_TIMEOUT.
- TaskTrackingTemplate – ten szablon służy do informowania użytkownika, który przekazał zadanie, o przyszłych zmianach statusu zadania. Jeśli nie można znaleźć szablonu, używany jest szablon z tabeli ciągów znaków ze stałą TASK_TRACKING.
Szablony zależne od statusu
W niektórych kontekstach użycia mogą być również używane szablony zależne od statusu. Na przykład, inny szablon może być użyty dla przekazanych zadań niż dla zadań przypisanych przez silnik workflow. Szablony zależne od statusu są przechowywane w tym samym katalogu co inne szablony, ale stała wartość odpowiedniego statusu jest dołączana do nazwy.
Następujące szablony obsługują nazwy zależne od statusu:
- AdhocMailtemplate
- Mailtemplate
- ProcessMailtemplate
Wybór języka
Język wyświetlania użytkownika określa, który plik szablonu jest używany. Jeśli nie ma pliku szablonu dla kontekstu użycia w języku wyświetlania użytkownika, używany jest plik szablonu w języku wyświetlania systemu.
Jeśli system używa języka wyświetlania en i istnieje plik o nazwie ProcessMailtemplate_en.html, zostanie on użyty.
Jeśli nie istnieje plik o nazwie ProcessMailtemplate_en.html, używany jest standardowy szablon z tabeli stringów com.cisag.sys.workflow.template.MailTemplates ze stałą wartością DEFAULT.
Polecenie setMailTemplate
Można użyć dowolnego szablonu wiadomości e-mail za pomocą polecenia setMailTemplate w deklaracjach definicji działań. Podobnie jak w przypadku standardowych szablonów, własne szablony również muszą być przechowywane w folderze Documents/Workflow w Knowledge Store bieżącego systemu, a ich nazwa musi kończyć się podkreśleniem i kodem ISO języka.
Documents/Workflow/MyMailTemplate_en.html
Możliwe jest utworzenie własnego szablonu wiadomości e-mail MyMailTemplate w języku angielskim w następujący sposób:
Documents/Workflow/MyMailTemplate_en.html
Termin setMailTemplate(„MyMailTemplate”); w funkcji create deklaracji definicji działania powoduje użycie szablonu wiadomości e-mail MyMailTemplate. To, który z dwóch plików szablonów jest używany, zależy od bieżących ustawień języka.
Język wyświetlania użytkownika określa, który z możliwych plików szablonów o określonej nazwie jest używany. Jeśli nazwa Standard zostanie przekazana do polecenia, a język angielski (en) jest zapisany jako język wyświetlania w ustawieniach użytkownika, użyty zostanie plik szablonu Standard_en.html. Jeśli w ustawieniach użytkownika odbiorcy zapisany jest język treści, dla którego nie ma pliku szablonu o określonej nazwie, używany jest plik szablonu dla domyślnego języka systemu. Polecenie setMailTemplate działa nie tylko w definicjach działania typu Wiadomość e-mail, Węzeł e-mail i Interaktywny węzeł e-mail, ale ma również zastosowanie do wszystkich typów działań dla powiadomień e-mail przez silnik workflow.
Aby nie używać szablonu wiadomości e-mail, należy przekazać pusty ciąg do polecenia w następujący sposób:
setMailTemplate(„”)
W takim przypadku używany jest szablon wiadomości e-mail ze stałą EMPTY z tabeli ciągów znaków com.cisag.sys.workflow.template.MailTemplates. Jeśli przesyłany jest nieistniejący szablon wiadomości e-mail, używany jest standardowy szablon wiadomości e-mail z tabeli ciągów znaków com.cisag.sys.workflow.template.MailTemplates ze stałą DEFAULT.
Formatowanie HTML
Do sformatowania szablonu wiadomości e-mail można użyć znaczników HTML. Szablon wiadomości e-mail w języku niemieckim może wyglądać na przykład tak:
<html>
<title>Nowe zadanie: {$code} {$subject}</title>
<body>
<p>Witam {$odbiorca},</p>
<p>Jesteś nowym edytorem zadania <a href=”{$workitemUrl}”>{$subject}</a> w statusie "{$state}".</p>
<p>Zadanie powinno mieć priorytet "{$priority}" i zostać ukończone do {$endTime}. Aby uzyskać więcej informacji, zapoznaj się z działaniem<a href=”{$activityUrl}”>{$code}</a> i następującym opisem zadania:</p>
<p><dir>{$description}</dir></p>
</body>
</html>
Adresy URL muszą być wprowadzane bezpośrednio jako adres URL, np. w odnośniku.
Tytuł strony HTML jest używany jako temat wysyłanej wiadomości e-mail. Parametr description ma zawartość HTML. Zawartość tego parametru może zawierać własne formatowanie HTML. W tym celu należy użyć polecenia formatDescriptionHTML. Szczegółowy opis polecenia można znaleźć w artykule Język skryptowy systemu: Funkcje workflow.
Parametry szablonu
Jak pokazano w przykładzie w rozdziale Formatowanie HTML, szablony wiadomości e-mail mogą zawierać parametry takie jak {$subject}. Parametry są określone w nawiasach klamrowych z wiodącym znakiem dolara. Otaczające formatowanie określa również sposób formatowania tekstu lub zawartości parametru.
Powoduje, że stan (state) jest wyświetlany kursywą.
Poniżej omówione zostały parametry odnoszące się do zadań:
- actionUrl – URL, który wykonuje akcję otwierania dla zadania. Nie powoduje to jednak przełączenia do trybu workflow, jak ma to zwykle miejsce w przypadku akcji Otwórz.
- forwardUser – pełna nazwa użytkownika, który przekazał zadanie
- forwardText – tekst wprowadzony podczas przekazywania zadania
- forwardUser – pełna nazwa użytkownika, który przekazał zadanie
- forwardText – tekst wprowadzony podczas przekazywania zadania
- oldState – status zadania bezpośrednio przed zdarzeniem, które doprowadziło do wysłania powiadomienia
- state – status zadania
- user – imię i nazwisko osoby pracującej nad zadaniem
- workitemUrl – URL, który wykonuje akcję Otwórz dla zadania
Poniżej omówione zostały parametry związane z działaniami:
- activityUrl – URL, który wykonuję akcję Działanie, dla zadania
- code – numer działania
- createUser – pełna nazwa użytkownika, który zarejestrował działanie. Ten parametr może być używany na przykład do powiadamiania o ręcznie zarejestrowanym działaniu.
- database – nazwa bazy danych, w której zostało wyzwolone zdarzenie prowadzące do wysłania powiadomienia
- definition – nazwa definicji działania
- description – opis działania wraz z formatowaniem
- endTime – koniec okresu przetwarzania dla działania
- priority – priorytet działania
- startTime – początek okresu przetwarzania dla działania
- subject – przedmiot działania
Poniżej przedstawiono parametry odnoszące się do procesów:
- processUrl – URL, który wykonuje akcję Proces dla zadania
- processCode – numer procesu
- processSubject – przedmiot procesu
- processInitiator – wyzwalacz procesu
- processOwner – właściciel procesu
- processComments – liczba komentarzy zarejestrowanych dla procesu
- processStartTime – początek okresu przetwarzania procesu
- processEndTime – koniec okresu przetwarzania procesu
- processError – opis przyczyny błędu, gdy proces jest kończony przez węzeł błędu
- definition – nazwa definicji działania
Poniżej przedstawiono parametry odnoszące się do odbiorcy wiadomości e-mail:
- greeting – spersonalizowane powitanie dla użytkownika, do którego wysyłane jest powiadomienie
- recipient – pełna nazwa użytkownika, do którego wysyłane jest powiadomienie
- valediction – spersonalizowana formuła zamknięcia dla użytkownika, do którego wysyłane jest powiadomienie
Poniżej przedstawiono parametry odnoszące się do nieobecności:
- absentWorker – użytkownik, którego nieobecność rozpoczyna się lub kończy
- delegatedWorkitems – liczba otwartych zadań nieobecnego użytkownika, które mogą być przetwarzane w ramach delegacji
- endOfDelegation – koniec nieobecności
- startOfDelegation – początek nieobecności
Powiadomienie o uwagach dotyczących procesu
Podczas wprowadzania nowego komentarza w procesie, okno dialogowe akcji oferuje trzy pola wyboru, aby powiadomić właścicieli następujących ról procesu:
- Właściciel procesu
- Inicjator
- Uczestnicy
W tym przypadku powiadomienie nie jest wysyłane przy użyciu standardowych szablonów wiadomości e-mail. Zamiast tego aplikacja uruchamia zaprogramowane zdarzenie com.cisag.pgm.workflow.ProcessCommentCreated. Zdarzenie jest wyzwalane raz dla każdego właściciela wybranej roli procesu. Parametr zdarzenia recipient zawiera identyfikator GUID użytkownika, który ma zostać powiadomiony. Pozostałe parametry zawierają informacje o twórcy, komentarzu i instancji procesu.
- creator – identyfikator GUID użytkownika, który wprowadził komentarz
- processDefinition – identyfikator (kod) definicji procesu
- recipient – identyfikator GUID użytkownika, który ma zostać powiadomiony
- comment – odniesienie do komentarza procesu (obiekt biznesowy cisag.sys.workflow.obj.ProcessComment)
- process – odwołanie do instancji procesu (obiekt biznesowy cisag.sys.workflow.obj.Process)
- startNode – odwołanie do węzła początkowego (obiekt biznesowy cisag.sys.workflow.obj.Activity)
Konfiguracja
W tym rozdziale opisano odpowiednie ustawienia Workflow Management. Opis ustawień języka skryptowego systemu znajduje się w artykule Język skryptowy systemu.
Opis ustawień konfiguracji znajduje się w rozdziale dotyczącym głównej funkcji Workflow Management w artykule Konfiguracja: Workflow Management.
Harmonogram działań na dowolnym serwerze aplikacji systemu ERP
Do celów testowych harmonogram działania można uruchomić na serwerze aplikacji (SAS) innym niż serwer komunikatów. Nie jest to zalecane do użytku produkcyjnego. Pomocne może być jednak uruchomienie harmonogramu na lokalnym serwerze aplikacji w systemie testowym lub deweloperskim, szczególnie w celu sprawdzenia wyników debugowania przy użyciu polecenia echo. Harmonogram jest zatrzymywany na serwerze komunikatów, gdy harmonogram jest uruchamiany na innym serwerze aplikacji. Gdy tylko serwer aplikacji z harmonogramem zostanie zamknięty, harmonogram na serwerze komunikatów wznawia swoją pracę. Tylko jeden serwer aplikacji w systemie może przejąć harmonogram z serwera komunikatów.
Opcja workflowEngineMaster powoduje, że harmonogram jest uruchamiany na tym serwerze aplikacji, gdy uruchamiany jest serwer aplikacji. Ta specyfikacja nie jest konieczna dla serwera komunikatów.
Serwer docelowy dla linków
Wiadomości e-mail wysyłane przez workflow mogą zawierać łącza do zadań, działań i dowolnych jednostek biznesowych. Można skonfigurować serwer aplikacji, na który linki te powinny wskazywać, tj. na którym serwerze link powinien zostać wykonany.
W systemach z serwerem aplikacji nie jest wymagana dalsza konfiguracja. Serwer docelowy to serwer aplikacji, na którym uruchomiony jest silnik workflow.
Jeśli system składa się z kilku serwerów aplikacji, należy wprowadzić serwer aplikacji dialogu w polu Docelowy serwer dla atrybutów linka dla wszystkich serwerów aplikacji. Serwer ten jest używany dla wszystkich łączy w wiadomościach e-mail workflow wysyłanych przez serwer wiadomości.
Jeśli serwer docelowy jest zależny od użytkownika, można użyć ról workflow, aby przypisać serwery docelowe specyficzne dla użytkownika.
Maksymalna liczba działań
Jeśli definicja procesu zawiera pętlę, dzięki czemu przepływ procesu może być kierowany z definicji działania z powrotem do tej samej definicji działania, wówczas błędny warunek przejścia w zakładce Przejścia może spowodować, że silnik workflow będzie generował coraz więcej działań dla procesu, aż baza danych zostanie zapełniona i system ulegnie awarii.
Aby temu zapobiec, liczba działań w procesie jest ograniczona do 1000. Jeśli proces podejmie próbę wygenerowania większej liczby działań, proces zakończy się za pośrednictwem węzła błędu z błędem WFL-00582 Przekroczono maksymalną liczbę działań.
W razie potrzeby maksymalną liczbę działań można zmienić za pomocą właściwości com.cisag.sys.workflow.process.MaxActivities.
Dostosowywanie informacji o działaniach
Aplikacja Informacje o działaniach zapewnia prosty i szybki przegląd działań workflow w dokowanym oknie. Aplikacja jest otwierana automatycznie po otwarciu zadania, a działanie wyższego poziomu jest powiązane z aplikacją lub obiektem biznesowym. Oznacza to, że zarówno obiekt biznesowy, który ma być przetwarzany, jak i najważniejsze informacje o działaniu zawsze pozostają widoczne. Układ aplikacji, a tym samym wyświetlane pola, można zmienić za pomocą dostosowywanego interfejsu.
Aplikację Informację o działaniach można dostosować, ale jeśli jest ona otwarta jako okno dokowane, nie można jej dostosować. Aby dostosować aplikację, należy otworzyć ją za pomocą serwera aplikacji, który używa następującej właściwości:
com.cisag.pgm.base.CisInfoApplicationOpenDialog=Never
Aby otworzyć aplikację jako okno dokowane, należy użyć wartości Always:
com.cisag.pgm.base.CisInfoApplicationOpenDialog=Always
Jeśli właściwość ma wartość Always, okno dokowane używa widoku aplikacji oznaczonego jako standardowy.



