Usługa Business Integration Service (BIS) umożliwia eksportowanie danych z baz danych oraz importowanie danych do baz danych. BIS może być używana między innymi do:
-
transferu starszych danych przed uruchomieniem produkcyjnym,
-
wymiany danych z systemami zewnętrznymi lub innymi systemami Comarch ERP Enterprise podczas pracy produkcyjnej,
-
masowych zmian danych w systemie.
Niniejszy dokument przedstawia podstawowe informacje o BIS oraz zawiera przegląd pozostałej dostępnej dokumentacji.
Grupa docelowa
- Konsultanci
- Twórcy aplikacji
Definicje pojęć
- Kontroler— jest to klasa Java realizująca import i eksport elementu biznesowego. Powiązane interfejsy to com.cisag.pgm.bi.ImportController i com.cisag.pgm.bi.ExportController. Kontroler zapewnia model danych, który ma być używany do importu/eksportu, a tym samym określa, ile obiektów, atrybutów i relacji jest dostępnych dla danej jednostki biznesowej. Model danych może się różnić dla importu i eksportu. W przypadku prostych jednostek biznesowych import/eksport może odbywać się bez kontrolera, tj. ogólnie.
- Rozszerzalny język znaczników (XML) — XML umożliwia zapisywanie ustrukturyzowanych danych w pliku tekstowym. Język opisu umożliwia definiowanie, przesyłanie, sprawdzanie i interpretowanie danych między aplikacjami i jest szczególnie odpowiedni do wymiany danych strukturalnych. W przypadku dokumentów XML, zawartość, struktura i informacje o reprezentacji są rozdzielone. XML jest koordynowany i zdefiniowany jako standard przez W3C.
- Język transformacji arkuszy stylów (XSLT) — XSLT to język programowania służący do przekształcania dokumentów XML. XSLT opiera się na logicznej strukturze drzewa dokumentu XML i służy do definiowania reguł konwersji. Opisuje konwersję dokumentu XML na inny dokument.
- Filtr — model danych BIS dla danej jednostki biznesowej może być bardzo obszerny. Filtr stanowi podzbiór modelu danych BIS dla określonego podmiotu gospodarczego. Określa on, które z obiektów, atrybutów i relacji podmiotu gospodarczego mają zostać uwzględnione w procesie importu lub eksportu.
- Plik błędu — dane pliku źródłowego zidentyfikowane jako nieprawidłowe są zapisywane w pliku błędów podczas importu danych w BIS. W zależności od rodzaju błędu, plik błędu może zostać poprawiony ręcznie i ponownie zaimportowany lub wczytany i przetworzony krok po kroku w aplikacji korygującej.
- Program korygujący — program korygujący to aplikacja dialogowa, która służy do interaktywnej edycji prostych plików błędów w systemie. Dla jednej jednostki biznesowej może istnieć jeden lub więcej programów korygujących. Program korygujący jest aplikacją odnoszącą się do określonej jednostki biznesowej (takiej jak aplikacja Partnerzy dla jednostki biznesowej com.cisag.app.general.obj.Partner), która jest otwierana w trybie specjalnym. W tym trybie instancje jednostki biznesowej z pliku błędu mogą być otwierane indywidualnie, przetwarzane interaktywnie i zapisywane.
- Plik źródłowy — plik źródłowy to plik, który jest odczytywany podczas importowania danych do BIS. Plik źródłowy zawsze zawiera tylko dane dla jednej kategorii jednostek biznesowych. W przypadku niektórych typów plików dane do zaimportowania mogą być rozproszone w kilku plikach źródłowych. W takim przypadku jeden z tych plików źródłowych jest głównym plikiem źródłowym, a pozostałe są połączonymi plikami źródłowymi. Podczas procesu importu główny plik źródłowy i połączone pliki źródłowe są łączone w celu utworzenia nowego pliku, który jest używany do wykonania rzeczywistego importu. Wszelkie dane z pliku źródłowego, których nie można pomyślnie zaimportować, są zapisywane w pliku błędów wraz z powiązanymi komunikatami o błędach.
- Tekst rozdzielany separatorami (CSV) — CSV to typ pliku, w którym wartości poszczególnych kolumn są oddzielone separatorem. Wiersze są oddzielone znakami końca wiersza. Separator musi być znany, aby plik mógł zostać zaimportowany. Typowymi separatorami są na przykład zwykły przecinek i średnik. Dane zapisane w tym formacie mogą być używane i przetwarzane w wielu programach. Prosta, niehierarchiczna struktura CSV sprawia, że ten typ pliku nie nadaje się do mapowania złożonych struktur danych.
- Unicode — Comarch ERP Enterprise korzysta z Unicode. Dlatego wszystkie znaki używane na całym świecie mogą być używane i drukowane na formularzach. Przed pojawieniem się Unicode potrzebnych było wiele różnych systemów kodowania do wyświetlania znaków. Żaden z tych systemów nie zawierał wystarczającej liczby znaków. W samej Unii Europejskiej potrzebnych było kilka systemów kodowania do wyświetlania różnych języków krajów członkowskich. Dzięki zastosowaniu Unicode, Comarch ERP Enterprise może być bezpośrednio zaimplementowany w różnych systemach. Różne kraje i języki nie stanowią problemu. Złożone adaptacje nie są wymagane, ponieważ Unicode umożliwia globalną wymianę tekstu bez utraty informacji. Unicode nadaje każdemu znakowi własny numer – niezależny od platformy, programu i języka.
- Tekst Unicode rozdzielany tabulatorami — ten typ pliku jest podobny do CSV, z tym wyjątkiem, że separatorem jest tabulator, a kod znaków to Unicode. Pliki w tym formacie mogą być używane między innymi w programie Microsoft Excel. Aby zapisać ten typ pliku w programie Excel, musisz określić typ pliku o tej samej nazwie w programie Excel.
- Schemat XML (XSD) — schemat XML (XML Schema Definition, XSD) to formalna specyfikacja reguł dokumentu XML wskazująca, które elementy i kombinacje elementów są dopuszczalne w dokumencie.
- Plik docelowy — plik utworzony podczas eksportu danych w BIS.
Wprowadzenie do usługi integracji biznesowej (BIS)
Usługa integracji biznesowej (BIS) jest uniwersalnym interfejsem wymiany danych w systemie.
BIS może zasadniczo współpracować ze wszystkimi jednostkami biznesowymi. Odpowiednie jednostki biznesowe ERP oficjalnie obsługiwane przez BIS są wymienione w artykule Interfejsy eksportu i importu.
Dostęp do BIS można uzyskać za pośrednictwem kilku różnych kanałów, co pozwala na korzystanie z niego ręcznie, automatycznie i kontrolowane przez system lub automatycznie poprzez zdalne wywoływanie.
BIS obsługuje różne typy plików dla eksportu i importu danych. Struktura danych jest określana przez model danych BIS danej jednostki biznesowej. Model danych BIS i typy plików opisano w rozdziałach Model danych BIS i Pliki źródłowe i pliki docelowe. Opis działania eksportu i importu można znaleźć w rozdziale Procesy eksportu i importu.
Za pomocą XSLT dane w BIS można przekształcić w inny format, dzięki czemu programy zewnętrzne nie są już zależne od formatu danych kontrolerów BIS. Podczas procesu eksportu dane mogą być konwertowane z formatu danych BIS wygenerowanego przez kontroler eksportu do innego formatu. Konwersja jest przeprowadzana zgodnie z określonym plikiem XSLT. Podczas importu dane są najpierw konwertowane z formatu zewnętrznego do formatu danych BIS, zanim zostaną przekazane do kontrolera importu.
Importowane dane przechodzą te same walidacje, co dane wprowadzane ręcznie. Zapobiega to importowaniu niespójnych danych. Jeśli wystąpią błędy importu, często możliwe jest poprawienie błędnych danych w tych samych aplikacjach, które są również używane do ręcznego wprowadzania danych, a następnie ich zapisanie.
Rejestrowanie importów i eksportów umożliwia wywołanie poprzednich takich procesów w systemie w celu wyświetlenia ich wyników lub innych szczegółów. Funkcja rejestrowania jest dostępna od wersji 4.4. Jej opis można znaleźć w rozdziale Rejestrowanie.
Dzięki adaptacji możliwe jest dostosowanie BIS do specjalnych wymagań w niektórych jednostkach biznesowych i wykorzystanie go dla dostosowanych jednostek biznesowych.
BIS za pośrednictwem różnych kanałów
Procesy importu i eksportu mogą odbywać się za pośrednictwem kilku różnych kanałów, w zależności od sposobu rozpoczęcia procesu.
Opcje oferowane przez BIS są wymienione poniżej:
| Proces | Eksport | Import |
|---|---|---|
| Ręcznie | aplikacja Eksport danych | aplikacja Import danych |
| Zautomatyzowany – sterowany przez Comarch ERP Enterprise | Eksport w ramach aktywności workflow | Import w ramach aktywności workflow |
| Eksport w tle jako seria uruchamiana według harmonogramu (zarejestrowany w aplikacji Eksport danych). | Import w tle jako seria uruchamiana według harmonogramu (zarejestrowany w aplikacji Import danych). | |
| Kolejność przetwarzania na podstawie aplikacji działającej w tle Automatyczny import danych (zarejestrowanej w aplikacji Automatyczny import danych). | ||
| Wydruk dokumentu źródłowego z ustawieniami eksportu | ||
| Zautomatyzowany jako połączenie zdalne | CORBA | CORBA |
| SOAP | SOAP | |
| Wyszukiwanie zdalne(CORBA i SOAP) |
Model danych BIS
Procesy importu lub eksportu za pośrednictwem BIS są zawsze przeprowadzane dla określonej jednostki biznesowej. Model danych BIS jednostki biznesowej określa, które dane jednostki biznesowej mogą być importowane lub eksportowane oraz jaki format mają te dane w plikach źródłowych lub docelowych.
Do specjalnych celów procesy importu mogą być przeprowadzane przy użyciu części zamiast jednostki biznesowej. Każda część, która może być użyta do importu w ten sposób, jest odpowiednio rejestrowana w kodzie aplikacji. Wpływ procesu importu na różne części jest również zdefiniowany w kodzie aplikacji.
Atrybuty i relacje
Model danych BIS zawiera obiekty biznesowe i związane z nimi atrybuty dostępne dla importu/eksportu danej jednostki biznesowej.
Można wyświetlić model danych BIS w aplikacjach Import danych i Eksport danych w zakładce Filtr. Najwyższym elementem w modelu danych BIS jest zawsze główny obiekt jednostki biznesowej. Podsumowując, model danych BIS składa się z następujących elementów:
- Atrybuty proste – każdy reprezentuje pojedynczą wartość możliwą do importu lub eksportu. W drzewie filtrów atrybuty proste są wyświetlane z polem wyboru.
- Atrybuty złożone (części) – zawierają dodatkowe elementy. Wraz z atrybutami, które obejmują, stanowią część obiektu biznesowego, w którym są wymienione. Reprezentowane są ikoną pliku. Zgodnie z konwencją ich nazwy są zapisywane małą literą na początku i bez kursywy.
- Relacje z innymi obiektami biznesowymi zależnymi – obiekty zależne są częścią jednostki biznesowej. Wyeksportowane obiekty zależne mogą być importowane razem z jednostką biznesową. Zgodnie z konwencją nazwy obiektów zależnych nie są pisane kursywą, a ich pierwsza litera jest wielka.
- Relacje z innymi obiektami biznesowymi niezależnymi – obiekty te nie są częścią jednostki biznesowej. Ich dane mogą być eksportowane razem z jednostką biznesową, jednak w kontekście importu służą wyłącznie do dostarczania kluczy zewnętrznych. Instancje obiektów, do których odwołuje się proces, muszą już istnieć w bazie danych. Zgodnie z konwencją nazwy obiektów niezależnych są zapisywane kursywą, a ich pierwsza litera jest wielka.
Złożone atrybuty i relacje zawierają dalsze atrybuty i relacje. W drzewie filtrów są one reprezentowane przez ikony plików.
Relacje mogą być pojedyncze lub wielokrotne. W przypadku relacji wielokrotnej instancja obiektu biznesowego (źródło relacji) może być powiązana z dowolną liczbą instancji (miejsce docelowe relacji). W drzewie filtrów pojedyncze relacje są oznaczone jako „1..1”, a relacje wielokrotne jako „1..n”.
Aby poznać znaczenie elementów modelu danych BIS dla określonej jednostki biznesowej, należy zapoznać się z dokumentacją tej jednostki biznesowej dotyczącą procedur wymiany danych. Niektóre z bardziej powszechnych elementów modelu danych BIS zostały opisane w rozdziale Specyficzne elementy modelu danych BIS.
Zewnętrzne klucze techniczne i biznesowe
Klucze zewnętrzne łączą obiekty różnych jednostek biznesowych. BIS obsługuje zewnętrzne klucze techniczne i zewnętrzne klucze biznesowe w modelu danych:
- Wymiana danych z systemami zewnętrznymi będzie zasadniczo wymagać zewnętrznych kluczy biznesowych, ponieważ zewnętrzne klucze techniczne są istotne tylko w obrębie systemu.
- W przypadku wymiany danych między systemami pożądane może być zachowanie kluczy technicznych. W takim przypadku należy uwzględnić te klucze w wymianie danych.
- Klucze zewnętrzne są zazwyczaj zawarte w modelu danych BIS w następujących formach:
- Klucz techniczny jest zwykle identyfikatorem GUID obiektu docelowego. W tym celu obiekt źródłowy zawiera atrybut typu GUID.
- Klucz biznesowy składa się z jednego lub kilku atrybutów obiektu docelowego. Relacja jest zawsze relacją niezależną. Zgodnie z konwencją, jego nazwa pochodzi od atrybutu źródłowego, ale pierwsza litera jest wielka.
Jeśli klucz biznesowy zawiera klucze zewnętrzne, muszą one zostać przekształcone w odpowiednie klucze biznesowe, aby uzyskać klucze biznesowe. Dotyczy to na przykład identyfikacji dokumentów, które składają się z typu zamówienia i numeru zamówienia. Klucz techniczny zamówienia zawiera identyfikator GUID typu zamówienia. Klucz biznesowy musi wykorzystywać odpowiedni identyfikator typu zamówienia.
Wielojęzyczność w modelu danych
Atrybuty wielojęzyczne
Atrybuty wielojęzyczne to atrybuty, dla których baza danych zawiera wartości w kilku językach. W panelu modelu danych BIS wielojęzyczne atrybuty łańcuchowe są oznaczone symbolem ml.
BIS umożliwia eksportowanie lub importowanie atrybutów wielojęzycznych w jednym lub wszystkich językach, w których są one dostępne w bazie danych. Aby to kontrolować, należy użyć ustawienia języka filtra, co opisane zostało w rozdziale Ustawienie języka.
Relacja Teksty
Zależna relacja Teksty zawarta w niektórych jednostkach biznesowych zapewnia dostęp do zawartości zakładki Teksty, która zawiera również teksty wielojęzyczne. Teksty te są eksportowane i importowane w formie wielojęzycznej, niezależnie od ustawień językowych filtra.
Filtry
Filtry określają zakres modelu danych BIS dostępny do wymiany danych. Filtry składają się z wyboru atrybutu i ustawienia języka.
Wybór atrybutów
Filtry zawierają wybór atrybutów z modelu danych BIS jednostki biznesowej, tak aby importowana/eksportowana była tylko określona częściowa ilość atrybutów jednostki biznesowej.
Konkretny opis wpływu wyboru atrybutów na procesy importu i eksportu można znaleźć w rozdziale Procesy importu i eksportu.
Ustawienie języka
Ustawienie języka filtra określa, w jaki sposób atrybuty wielojęzyczne są importowane lub eksportowane.
Przy ustawieniu Jeden język atrybuty wielojęzyczne są importowane lub eksportowane w standardowym języku bazy danych. W przypadku jednostek biznesowych w bazie danych OLTP lub OLAP język ten jest językiem treści bieżącej sesji, natomiast w przypadku jednostek biznesowych w bazie danych repozytorium jest to język wyświetlania sesji. Dotyczy to BIS we wszystkich wersjach do wersji 4.1 włącznie. Więcej informacji, w jaki sposób określany jest język treści lub język wyświetlania sesji, można znaleźć w rozdziale Definicja i wpływ języków sesji.
Przy ustawieniu Wielojęzyczny atrybuty wielojęzyczne są importowane lub eksportowane we wszystkich językach dostępnych w źródłowej bazie danych.
Format czasu
Format czasu filtru określa sposób, w jaki atrybuty czasowe są sortowane w plikach.
- Przy aktywnym ustawieniu Forma kompaktowa serializacja jest zgodna z systemem do wersji 4.1 włącznie.
- Przy ustawieniu Forma znormalizowana atrybuty czasu są dzielone na ich składniki (data, godzina, strefa czasowa) i serializowane w złożony sposób.
Aby uzyskać opis konkretnych efektów powyższych ustawień, należy przejść do rozdziału Daty i znaczniki czasu.
Ustawienie Forma znormalizowana jest bardziej praktyczne w przypadku ręcznej edycji. W kontekście EDI i starszych transferów danych z systemów zewnętrznych, musisz indywidualnie zdecydować, które ustawienie jest bardziej odpowiednie
Należy pamiętać, że format czasu dotyczy całego pliku.
Plik transformacji
Jako plik transformacji, plik XSLT określa sposób formatowania danych, w tym miejscu można wskazać URI pliku XSLT. Jeśli URI nie zostanie wskazany, dane nie zostaną przekształcone podczas importu/eksportu.
Korzystanie z filtrów
Można tworzyć i edytować filtry w aplikacjach Import danych i Eksport danych. Jeśli filtr jest otwarty w jednej z tych aplikacji, można zobaczyć wybrane atrybuty w zakładce Filtr, gdzie są one oznaczone znacznikami wyboru. Można wprowadzać zmiany w filtrze, zaznaczając i odznaczając atrybuty.
Możliwe jest zapisanie filtrów w bazie danych OLTP do późniejszego wykorzystania. Możesz zapisać dowolną liczbę filtrów dla jednej jednostki biznesowej.
Możliwe jest również eksportowanie filtrów do pliku lub importowanie ich z pliku. Opis tego procesu znajdziesz w można znaleźć w artykule Import filtra.
BIS ogólny lub z kontrolerami
Import lub eksport jednostek biznesowych jest obsługiwany przez ogólną funkcję importu/eksportu lub przez specjalne kontrolery. Kontroler jest klasą java kodu aplikacji realizującą import lub eksport określonej jednostki biznesowej. W aplikacjach Import danych i Eksport danych można sprawdzić, czy kontroler jest używany dla określonej jednostki biznesowej. Aby uzyskać więcej informacji, należy zapoznać się z artykułami Import danych i Eksport danych.
Funkcje ogólne charakteryzują się następującymi cechami:
- Ogólna funkcja eksportu umożliwia eksport dowolnej jednostki biznesowej.
- Ogólna funkcja importu umożliwia jedynie import jednostek biznesowych bez podmiotów zależnych.
- Ogólna funkcja eksportu w niektórych przypadkach umożliwia jedynie eksport kluczy technicznych (GUID). Dane mogą być zatem importowane tylko do tej samej bazy danych, z której zostały wyeksportowane.
Pliki źródłowe i pliki docelowe
Wymiana danych za pośrednictwem usługi integracji biznesowej odbywa się między bazą danych a plikami.
Źródła/przeznaczenia danych
BIS obsługuje systemowy Knowledge Store oraz lokalny system plików serwera aplikacji w celu umożliwienia odczytu i zapisu plików.
Ścieżki plików są wskazywane jako URI zgodnie ze schematem kstore:// lub file:///. Należy zwrócić uwagę, że schemat Knowledge Store używa dwóch ukośników, podczas gdy schemat systemu plików używa trzech.
Wersje 4.2 i wyższe obsługują kompresję GZIP. Jeśli w kontekście import rozszerzenie .gz zostanie dodane do standardowego rozszerzenia nazwy pliku, plik ten zostanie rozpoznany jako plik GZIP i zdekompresowany przed importem. W scenariuszu eksportu dodanie rozszerzenia .gz spowoduje, że eksportowane pliki zostaną skompresowane w formacie GZIP.
Gdy kilka plików ma zostać zaimportowanych jednocześnie (pliki połączone), możliwe jest wskazanie ich również w formacie GZIP. Jeśli zostanie utworzony plik błędu, zostanie on skompresowany tylko wtedy, gdy wskazana dla niego nazwa kończy się rozszerzeniem .gz. Pliki błędów nazwane automatycznie nigdy nie są kompresowane. Ułatwia to głównie ręczną edycję plików błędów w przypadku niepoprawnych błędów.
Typy plików
Dostępne typy plików to XML (*.xml), CSV, (*.csv) i tekst Unicode rozdzielany tabulatorami (*.xls). Poniższe sekcje zawierają opis tych typów plików oraz ich odpowiednich funkcji i ograniczeń.
Rozszerzalny język znaczników XML
Pliki XML mają zalety ze względu na ich znormalizowany charakter i powszechne użycie. Zaleca się korzystanie z XML, ponieważ umożliwia on użytkownikom zapisywanie danych o dowolnym poziomie złożoności w jednym pliku, określanie i sprawdzanie schematu pliku oraz integrowanie zmian w modelu danych bez trudności.
Wymiana danych w trybie wielojęzycznym jest możliwa tylko dla plików XML. Aby zobaczyć, jak pliki będą wyglądać w określonym formacie, wyeksportuj wybraną jednostkę biznesową w tym formacie.
Kolejną funkcją XML jest możliwość wygenerowania schematu XML, który pasuje do określonego pliku. Aby to zrobić, należy użyć aplikacji Eksport danych lub Import danych. Używany z zewnętrznymi programami, wygenerowany schemat XML może służyć do walidacji plików XML. Możliwe jest również generowanie plików importu w oparciu o schemat XML przy użyciu odpowiednich programów zewnętrznych. Podczas eksportowania danych generowanych jest kilka przykładowych plików.
Element <semiramis> w każdym pliku XML BIS zawiera nagłówek pliku z podstawowymi informacjami. Należy pamiętać, że w przypadku plików importu XML atrybut XML locale musi być wskazany w tej formie:
locale="en-US-XMLSchemaCompliant"
lub wcale (co miałoby ten sam efekt). Inne formy nie są obsługiwane i mogą prowadzić do błędów importu.
Tekst i Tekst Unicode
Typ pliku Tekst odpowiada plikom CSV powszechnie używanym przez oprogramowanie innych firm. Typ pliku Unicode jest wersją CSV obsługującą Unicode, zoptymalizowaną do użytku w programie Microsoft Excel.
Należy pamiętać o cechach opisanych w tej sekcji podczas korzystania z typów plików Tekst rozdzielany separatorami i Tekst Unicode rozdzielany tabulatorami.
Format pliku
Formaty plików typu Tekst i Unicode są określane przez używane kodowania, separatory i znaki rozpoznawania tekstu. Podczas gdy są one predefiniowane dla Unicode, mogą być dowolnie wybrane dla Tekstu.
Specyfika korzystania z separatorów i znaków rozpoznawania tekstu musi być przestrzegana tylko podczas edycji plików w edytorze tekstu. W programie Microsoft Excel są one uwzględniane automatycznie.
- Pliki, o których mowa, są plikami tekstowymi, które używają określonego kodowania (kodowania znaków). Typ pliku Unicode musi mieć specjalne kodowanie „UTF16LE z BOM”, aby znaki Unicode były poprawnie wyświetlane w programie Microsoft Excel. Możesz również ustawić to kodowanie dla pliku typu Tekst w celu utworzenia kompatybilnego formatu pliku.
- Separatory rozdzielają poszczególne wartości (kolumny) rekordu danych, z wyjątkiem sytuacji, gdy są używane w ramach wartości ujętej w znaki rozpoznawania tekstu.
- Objęcie wartości znakami rozpoznawania tekstu umożliwia użycie separatorów, znaków rozpoznawania tekstu i podziałów wierszy (tylko w pliku typu Unicode) jako części tych wartości. Wartości niezawierające wspomnianych znaków nie muszą być otoczone znakami rozpoznawania tekstu. Aby znak rozpoznawania tekstu został rozpoznany jako część wartości, musi zostać użyty dwukrotnie w tej wartości.
Należy upewnić się, że używane są właściwe ustawienia kodowania, separatora i znaku rozpoznawania tekstu dla typu pliku Tekst. Przede wszystkim ustawienia muszą odpowiadać ustawieniom pliku źródłowego do importu.
Jedna relacja wielokrotna na obiekt
Każdy plik źródłowy lub plik docelowy typu Tekst lub Unicode może zawierać dane dotyczące maksymalnie jednej relacji. W takim przypadku dany plik będzie zawierał oddzielny wiersz dla każdego obiektu docelowego relacji.
Poniżej zilustrowany został ten przypadek na przykładzie pliku Excel. Wspomniany plik został wyeksportowany z jednostki biznesowej Partnerzy, przy czym w filtrze aktywne były tylko wyświetlane atrybuty. Obiekt Partnerzy zawiera relację CommunicationData.
Plik zawiera oddzielną linię dla każdego obiektu docelowego relacji, tj. dla każdej instancji CommunicationData, nawet jeśli instancje są częścią tej samej instancji Partners. Cztery linie widoczne na poniższym zrzucie ekranu należą do tej samej instancji partnera z kluczem biznesowym 10010.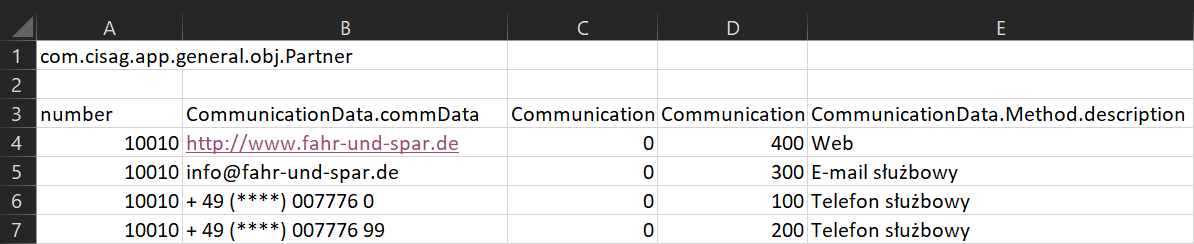
Każda instancja relacji wielopodmiotowej otrzymuje osobny wiersz w tabeli.
Przykład zostanie rozszerzony o dodatkowe atrybuty z głównego obiektu (takie jak numer), te atrybuty również zostaną powtórzone w każdym wierszu.
Kilka równoległych relacji wielokrotnych
Równoległe relacje są relacjami pochodzącymi z tego samego obiektu biznesowego. Relacja wielopoziomowa poniżej atrybutu tablicy z więcej niż jednym elementem jest również uważana za relację równoległą. Każdy plik może zawierać maksymalnie jedną równoległą relację. W przykładowym przypadku jednostki biznesowej Partnerzy z poprzedniej sekcji, oprócz CommunicationData istnieją dalsze powiązania równoległe. Dlatego kompletna jednostka biznesowa Partnerzy nie może być zawarta tylko w jednym pliku.
Oznacza to, że eksport jest możliwy tylko pod warunkiem, że filtr nie zawiera żadnych równoległych powiązań. Wynika z tego, że atrybuty aktywne dla danego obiektu nie mogą pochodzić z więcej niż jednej relacji. Wszelkie atrybuty z dodatkowych powiązań muszą zostać dezaktywowane. W przeciwnym razie pojawi się komunikat o błędzie. Jeśli ma zostać wyeksportowana więcej niż jedna równoległa relacja dla jednej jednostki biznesowej, należy to zrobić za pomocą kilku procesów eksportu, dostosowując filtry za każdym razem.
Importowanie więcej niż jednej równoległej relacji w jednym procesie importu jest możliwe tylko w przypadku importowania połączonych plików. W takim przypadku kilka plików jest importowanych dla jednej jednostki biznesowej w jednym procesie. Nie można zaimportować powiązanych plików.
Wiele powiązań bez zawartości
Jak wyjaśniono powyżej, na jeden plik może przypadać tylko jedna relacja. Opisane zostało również, w jaki sposób można wskazać wiele obiektów docelowych dla tej relacji.
W innym, specjalnym przypadku, żaden obiekt docelowy nie jest określony dla relacji, ale jednocześnie relacja jest aktywna w filtrze. Przykładem takiego przypadku może być zamówienie bez pozycji lub partner bez połączeń komunikacyjnych.
Jeśli te okoliczności mają zastosowanie do pliku importu, import może prowadzić do błędów zależnych częściowo od danej jednostki biznesowej. Wyświetlane komunikaty o błędach niekoniecznie muszą zawierać jakiekolwiek odniesienia do danej sytuacji.
Istnieją dwa możliwe rozwiązania:
- Możliwe jest całkowita dezaktywacja atrybutu z obiektu docelowego, pod warunkiem, że cały plik importu nie zawiera żadnych obiektów docelowych dla relacji wielokrotnej.
- Użycie typu pliku XML.
Edycja plików w programie Microsoft Excel
Podczas edycji plików należy zwrócić szczególną uwagę na:
- Definiowanie formatowania kolumn podczas otwierania pliku,
- Podziały wierszy w komórce,
- Zapisywanie plików,
- Zapisywanie plików z atrybutami czasu.
Definiowanie formatowania kolumn podczas otwierania pliku
Jeśli niektóre kolumny w pliku typu Tekst lub Unicode nie są prawidłowo wyświetlane w programie Microsoft Excel (np. jeśli tekst składający się tylko z liczb jest błędnie wyświetlany jako jedna liczba), należy wykonać następujące czynności:
- Należy otworzyć program Excel i wybrać pozycję menu Plik/Otwórz.
- Pojawi się okno dialogowe wyboru pliku.
- Wybierać plik, który ma zostać otworzony.
- Pojawi się okno dialogowe Kreator importu tekstu.
- Na pierwszej stronie okna dialogowego wybierać opcje Oryginalny typ danych: Rozdzielony i Rozpocznij import w wierszu: 1. Kliknij [Dalej], aby przejść do drugiej strony.
- Na drugiej stronie należy pozostawić opcję Traktuj kolejne ograniczniki jako jeden nieaktywną i, jeśli to konieczne, wybierać właściwy separator. Kliknąć [Dalej], aby przejść do trzeciej strony.
- Na trzeciej stronie można dostosować ustawienia formatowania poszczególnych kolumn. W tym celu należy zaznaczyć kolumnę i wybierać odpowiedni format danych z sekcji Format danych kolumny. Następnie wybrać format danych Tekst, aby zawartość kolumny nie była traktowana jako liczba lub data.
- Na koniec należy wybrać przycisk [Zakończ], aby otworzyć plik.
Podziały wierszy w komórce
Chociaż możliwe jest tworzenie podziałów wierszy w komórce za pomocą skrótu [Alt + Return], nie mogą one być importowane domyślnie. Jeśli ma to zastosowanie, należy pamiętać o uwagach z rozdziału Podziały wierszy w ciągu znaków.
Zapisywanie plików
Podczas zapisywania pliku w formacie Tekst lub Unicode może być konieczne potwierdzenie zapytania informującego, że zapisanie niektórych funkcji pliku może nie być możliwe.
Zapisywanie plików z atrybutami czasu
O ile nie zostanie określony format danych w kreatorze konwersji tekstu, jak opisano powyżej, Excel rozpozna wartości znaczników czasu jako godziny/daty.
Podczas zapisywania pliku Excel może nie zapisać znacznika czasu w formacie serializacji znaczników czasu, który jest udokumentowany w niniejszym dokumencie i wymagany do importu przez system. Może to również zależeć od używanych formatów komórek. Należy wybrać format danych Tekst w kreatorze konwersji tekstu, aby rozwiązać problem.
Podczas otwierania plików, które mają format czasu Forma znormalizowana, Excel przekonwertuje kolumnę data na zapis wernakularny. Aby temu zapobiec, można postępować zgodnie z powyższym opisem lub sformatować kolumny w zdefiniowanym przez użytkownika formacie danych RRRR-MM-DD po otwarciu pliku w programie Excel.
Formaty serializacji typów danych
Przegląd
W zależności od typu danych atrybutu, do wskazania wartości atrybutu w plikach używana jest określona serializacja. Poniższa tabela zawiera przegląd różnych typów danych i ich formatów serializacji.
Tabela zawiera również informacje, czy wartość pusta jest prawidłową wartością dla różnych typów danych. Więcej informacji na temat wartości pustych można znaleźć w rozdziel Puste wartości podczas importu.
| Atrybut | Wyświetlanie w filtrze | Format |
|---|---|---|
| String | str | Ciąg znaków o określonej maksymalnej długości. Szczegóły dotyczące obsługi znaków nowej linii oraz atrybutów wielojęzycznych zostały opisane w kolejnych rozdziałach. Wartość pusta jest wartością prawidłową i odpowiada pustemu ciągowi znaków. |
| Valueset | vset | Nazwa stałej wpisu Valueset. Dla Valuesetów wartość pusta jest również wartością prawidłową i odpowiada identyfikatorowi Valueset „0”. |
| boolean | bool | true, false |
| byte, short, int, long | byte, short, int, long | Liczba w zapisie dziesiętnym (patrz niżej). |
| Liczba dziesiętna | dec | Liczba w zapisie dziesiętnym (patrz niżej). |
| Czas/Data | Date, TimeStamp | Data z dokładnością do 1 dnia (wyświetlanie Date) lub znacznik czasu z dokładnością do 1 milisekundy (wyświetlanie TimeStamp), w określonej strefie czasowej. Sposób serializacji zależy od formatu czasu w filtrze i jest szczegółowo opisany w kolejnej sekcji. |
| GUID | guid | Ciąg GUID, cyfry szesnastkowe zapisane wielkimi literami. Wartość pusta i xsi:nil w typie danych XML są prawidłowymi wartościami i odpowiadają wartości null dla GUID. |
| BLOB | blob | Zawartość BLOB w oddzielnym pliku; ścieżka do tego pliku jest zawarta w pliku źródłowym lub docelowym. |
| Atrybut złożony (Part) | (Brak) | Atrybuty zawarte w Part są w XML zapisane jako elementy podrzędne, a w tekście/Unicode jako kolumny. Jeśli Part w bazie danych ma wartość null, to w XML jest przedstawiane jako xsi:nil, a w formacie tekstowym/Unicode jako puste kolumny. |
Część, która ma wartość null w bazie danych, pojawi się jako xsi:nil w pliku typu XML i jako puste kolumny w pliku typu Tekst/Unicode.
Formaty liczb, dat i znaczników czasu zależą od typu pliku i, częściowo, od języka treści użytkownika, jak wyjaśniono w następnych rozdziałach.
Podziały wierszy w ciągach znaków
Wartości atrybutów łańcuchowych mogą zasadniczo zawierać podziały wierszy. Jednak podziały linii mają sens tylko w atrybutach łańcuchowych, które są wyświetlane w polach wielowierszowych w interfejsie użytkownika systemu. Wszelkie podziały wierszy zawarte w atrybutach, które mają być wyświetlane lub edytowane w jednowierszowych polach tekstowych aplikacji dialogowych, zostaną usunięte podczas importowania tych atrybutów.
Podziały wierszy mogą być używane w plikach typu XML, ale nie w plikach typu Unicode i Tekst.
Plik typu XML używa podziałów wierszy systemu Windows, a także podziałów wierszy systemu Unix. Podczas eksportu podziały wierszy są konwertowane zgodnie z systemem operacyjnym serwera aplikacji. Import działa bez względu na rodzaj zastosowanego podziału wiersza.
Podczas importowania plików XML do oprogramowania innych firm należy pamiętać, że parsery XML zgodne ze standardami obsługują te dwa typy podziałów wierszy jednakowo, konwertując je wewnętrznie na podziały wierszy systemu Unix.
Podziały wierszy w plikach typu Tekst i Unicode są eksportowane jako spacje. Wszelkie podziały wierszy zawarte w pliku źródłowym zostaną zaimportowane jako spacje.
Atrybuty wielojęzyczne
Atrybuty wielojęzyczne są zawsze atrybutami typu String i są obsługiwane zgodnie z ustawieniami językowymi filtra podczas wymiany danych.
W ustawieniu językowym Jeden język zawartość pliku składa się z wartości tylko jednego języka. W takim przypadku serializacja odpowiada serializacji jednojęzycznych atrybutów łańcuchowych.
Ustawienie języka Wielojęzyczny jest możliwe tylko w przypadku pliku typu XML. W takim przypadku plik zawiera wartości we wszystkich językach bazy danych, przy czym każda wartość jest oznaczona językiem. Wszystkie wartości odnoszące się do tego samego atrybutu wielojęzycznego są zawarte w jednym pliku XML. Szczegóły serializacji można uzyskać ze schematu XML lub z wielojęzycznie wyeksportowanego pliku XML.
Liczby
W przypadku plików typu XML liczby są wyświetlane w formatach liczbowych ze specyfikacji schematu XML. Nie są używane separatory grup ani separatory tysięcy, a miejsce dziesiętne w ułamkach dziesiętnych jest oznaczone kropką.
W przypadku typów plików Tekst i Unicode obowiązuje format liczb zależny od języka, który wykorzystuje ustawienia lokalne JDK zainstalowane na danym serwerze aplikacji. W tym przypadku format zależy od języka treści sesji, podczas której przeprowadzany jest import lub eksport. Microsoft Excel jest zatem w stanie automatycznie rozpoznawać liczby w odpowiedniej wersji językowej. Separatory tysięcy i znaczniki dziesiętne zależą od języka treści bieżącej sesji. Używanie separatorów tysięcy jest opcjonalne w przypadku importu.
Poniższa tabela zawiera kilka przykładów liczb:
| Typ danych | Tekst XML | Tekst / Unicode Dotyczy języka niemieckiego |
|---|---|---|
| byte, short, int, long | 1000 | 1.000 |
| Liczba dziesiętna | 1000.12 | 1.000,12 |
Poniższe zakresy wartości mają zastosowanie do poszczególnych typów danych:
| Typ danych | Zakres wartości |
|---|---|
| byte | od -128 do 127 |
| short | od -32 768 do 32 767 |
| int | od -2 147 483 648 do 2 147 483 647 |
| long | od -9 223 372 036 854 775 808 do 9 223 372 036 854 775 807 |
| Liczba dziesiętna | Maksymalna liczba wszystkich cyfr oraz cyfr po przecinku jest wyświetlana w filtrze. |
Daty i znaczniki czasu
Serializacja atrybutów czasu, tj. atrybutów reprezentujących daty lub znaczniki czasu, zależy od formatu czasu filtra i typu danych atrybutu czasu. Istnieją następujące warianty atrybutów czasu:
| Wariant | Dokładność | Wyświetlanie | Strefa czasowa |
| TimeStamp | 1 milisekunda | TimeStamp | Brak odniesienia do strefy czasowej. |
| CisObjectDate CisObjectDateUntil |
1 dzień | Date | Strefa czasowa istnieje jeden raz na obiekt i obowiązuje dla wszystkich atrybutów tego wariantu. |
| CisObjectTimeStamp | 1 milisekunda | TimeStamp | |
| CisAttributeDate CisAttributeDateUntil |
1 dzień | Date | Strefa czasowa jest częścią atrybutu i obowiązuje wyłącznie dla tego atrybutu. |
| CisAttributeTimeStamp | 1 milisekunda | TimeStamp |
Począwszy od wersji 4.2, atrybuty czasu są zawsze wyświetlane jako proste atrybuty w panelu filtrów. Jednakże serializacja może być prosta lub złożona w zależności od wariantu i formatu czasu.
Następne rozdziały opisują serializację w obu formatach czasu. Należy zwrócić uwagę na różnice w serializacji w odniesieniu do strefy czasowej, której podlega serializacja wycinka daty/czasu.
Format czasu Forma kompaktowa
W zależności od wariantu atrybutu czasu serializacja może być prosta lub złożona:
| Serializacja | Wariant Przykład atrybutu czasu attr |
| TimeStamp | Prosta serializacja z wartością znacznika czasu. Przykład w XML: <attr>2005-03-29T09:43:39.634Z</attr> W formatach danych Tekst oraz Unicode dostępna jest kolumna attr. W przypadku CisObjectDate, CisObjectDateUntil oraz CisObjectTimeStamp strefa czasowa jest przechowywana oddzielnie w atrybucie _timeZone i opisana w rozdziale Strefa czasowa obiektu. |
| CisObjectDate CisObjectDateUntil |
|
| CisObjectTimeStamp | |
| CisAttributeDate CisAttributeDateUntil |
Złożona serializacja składająca się z wartości znacznika czasu oraz strefy czasowej. Przykład w formacie XML: <attr> <timeStamp>2005-03-29T09:43:39.634Z</timeStamp> <timeZone>CET</timeZone> </attr>W formatach danych Tekst oraz Unicode dostępne są dwie kolumny: attr.timeStamp oraz attr.timeZone. |
| CisAttributeTimeStamp |
Serializacja wartości znacznika czasu zależy od typu pliku:
W przypadku pliku typu XML data i godzina są wskazywane w formacie ISO 8601 w strefie czasowej UTC. Strefa czasowa UTC jest wyróżniona literą „Z” na końcu daty. Odpowiada to typowi danych schematu XML xsd:dateTime.
Jeśli chodzi o typy plików Tekst i Unicode, data i godzina są wskazywane w formacie zależnym od języka. W tym przypadku format zależy od języka treści sesji, podczas której przeprowadzany jest import lub eksport. Dzięki temu daty są automatycznie rozpoznawane jako znaczniki czasu przez program Microsoft Excel w odpowiedniej wersji językowej. Data opisuje znacznik czasu w strefie czasowej serwera aplikacji, na którym przeprowadzany jest import lub eksport.
Poniższa tabela zawiera kilka przykładów typów plików, a także wartości trzech specjalnych znaczników czasu Undefined (nieokreślony), Minimum i Maximum.
| XML | Text, UnicodeDotyczy języka niemieckiego | |
| Przykład | 2005-03-29T09:43:39.634Z | 29.03.2005 11:43:39.634 |
| Niezdefiniowany znacznik czasu | 0001-12-31T23:00:01.000Z | 01.01.0002 00:00:01.000 |
| Minimalny znacznik czasu | 0001-12-31T23:00:02.000Z | 01.01.0002 00:00:02.000 |
| Maksymalny znacznik czasu | 4712-12-31T00:00:00.000Z | 31.12.4712 01:00:00.000 |
Należy pamiętać, że we wszystkich typach plików wartości znaczników czasu muszą być podawane w całości. Czas, sekundy lub milisekundy nie są opcjonalne. Co więcej, są one zawsze serializowane w strefie czasowej UTC dla plików typu XML, podczas gdy dla plików typu Tekst i Unicode są one zawsze serializowane w strefie czasowej serwera aplikacji – nie w strefie czasowej atrybutu czasu zawartego w postaci atrybutu _timeZone w przypadku wariantów CisObjectDate, CisObjectDateUntil i CisObjectTimeStamp oraz w formie atrybutu timeZone w przypadku wariantów CisAttributeDate, CisAttributeDateUntil i CisAttributeTimeStamp.
Format czasu Forma znormalizowana
W formacie czasu Forma znormalizowana atrybuty czasu zawsze mają strefę czasową, a ich data i godzina są zawsze odnotowywane w tej strefie czasowej.
Serializacja atrybutów czasu jest zawsze złożona w tym formacie czasu, co oznacza, że składa się z kilku atrybutów podrzędnych. Serializacja jest niezależna od typu pliku, ale zależy od precyzji. W przypadku atrybutów o dokładności day, atrybuty podrzędne time i dst są pomijane.
Serializacja złożona ma następującą strukturę:
| Atrybut podrzędny (Comarch ERP Enterprise / typ danych XML Schema) | Znaczenie i zachowanie |
|---|---|
| specialValue: vset | Specjalna wartość symboliczna Valueset (NONE, UNDEFINED_TIME_STAMP, MIN_TIME_STAMP, MAX_TIME_STAMP). Atrybut ma wartość NONE, jeśli złożony atrybut daty/czasu nie przyjmuje wartości symbolicznej. W przeciwnym przypadku atrybut ma inną wartość niż NONE, a atrybuty date oraz time pozostają puste. Znaczenie wartości symbolicznych: UNDEFINED_TIME_STAMP – nieokreślony znacznik czasu, MIN_TIME_STAMP – minimalny znacznik czasu, MAX_TIME_STAMP – maksymalny znacznik czasu. Import: Atrybut jest obowiązkowy i jest importowany standardowo. Błąd importu występuje, jeśli wartość tego atrybutu nie jest spójna z atrybutami date i time. |
| date: str/xsd:date | Data określona w strefie czasowej z atrybutu timeZone. Format: 2005-11-28 (zgodny z ISO 8601).Import: Atrybut jest obowiązkowy. Jeśli specialValue nie ma wartości NONE, atrybut musi być pusty. |
| time: str/xsd:time | Godzina w ciągu dnia określona w strefie czasowej z atrybutu timeZone oraz z ustawieniem czasu letniego z atrybutu dst. Format: 19:24:00 (ISO 8601) Format godziny w standardzie ISO 8601. Nie występuje w atrybutach daty. Import: Atrybut jest obowiązkowy. Jeśli specialValue nie ma wartości NONE, atrybut musi być pusty. |
| dst: boolean/xsd:boolean |
Określa, czy dla atrybutu time aktywne jest przesunięcie związane z czasem letnim. Nie występuje w atrybutach czasu o dokładności data, tj. w wariantach CisObjectDate/Until oraz CisAttributeDate/Until. Przy imporcie atrybut jest ignorowany. |
| timeZone: str(10)/xsd:string |
Identyfikator strefy czasowej. W wariancie TimeStamp jest to strefa czasowa kontekstu. W wariantach CisObjectDate/-TimeStamp jest to strefa czasowa obiektu. W wariantach CisAttributeDate/-TimeStamp jest to strefa czasowa złożonego atrybutu czasu. Import: Atrybut opcjonalny. Wartość domyślna: przy tworzeniu nowego wpisu inicjowana przez kontroler lub ustawiana na strefę czasową kontekstu; przy aktualizacji – zachowywana jest dotychczasowa wartość lub ustawiana strefa kontekstu. W wariancie TimeStamp wartość domyślna to zawsze strefa kontekstu; jest ona używana tylko do parsowania i nie jest zapisywana do bazy danych. Przy imporcie wariantów CisObjectDate/-TimeStamp strefa czasowa nie może być zmieniona – musi odpowiadać istniejącej lub inicjowanej przez kontroler; w przeciwnym przypadku występuje błąd importu. Przy imporcie wariantów CisAttributeDate/-TimeStamp strefa czasowa może zostać zmieniona. |
Przykłady w XML:
Atrybut z precyzją do dnia:
<cisObjectDateField>
<specialValue>NONE</specialValue>
<date>2005-03-29</date>
<timeZone>CET</timeZone>
</cisObjectDateField>
Atrybut z dokładnością do milisekund:
<cisObjectTimeStampField>
<specialValue>NONE</specialValue>
<date>2005-03-29</date>
<time>11:43:39.634</time>
<dst>true</dst>
<timeZone>CET</timeZone>
</cisObjectTimeStampField>
Puste wartości podczas importu
Wartości wskazane w pliku docelowym lub źródłowym w postaci pustego ciągu znaków lub jako ciąg znaków zawierający tylko spacje są nazywane wartościami pustymi. Puste wartości są prawidłowymi, możliwymi do zaimportowania wartościami dla niektórych typów danych. BIS jest zaprogramowany do obsługi pustych wartości w określony sposób.
W typach plików Tekst i Unicode wartości puste są tworzone przez nieokreślenie żadnej wartości dla rekordu danych w odpowiedniej kolumnie. W pliku typu XML wartości puste są tworzone przez brak wskazania wartości dla elementu XML.
Dla niektórych typów danych w pliku typu XML, puste wartości są dodatkowo oznaczone jako xsi:nil=”true”. Jest to konieczne, aby umożliwić walidację XML względem schematu XML. Jednakże, jeśli nie jest to inaczej udokumentowane, informacja ta nie ma żadnego specjalnego wpływu na import i dlatego jest opcjonalna.
Ze względu na specyfikę typów plików Tekst i Unicode, BIS akceptuje (lub ignoruje) wartości puste, nawet jeśli nie są one uważane za prawidłowe wartości dla danego typu danych. Na przykład części mające wartość „null” w bazie danych są eksportowane jako puste kolumny, nawet jeśli wartości puste nie są dozwolone dla tych kolumn ze względu na ich typy danych. Dzięki temu, że BIS akceptuje (lub ignoruje) te puste wartości, puste kolumny nie prowadzą do błędów przy ponownym imporcie takiego pliku.
Poniższa tabela opisuje sposób obsługi pustych wartości podczas importu różnych typów danych.
| Atrybut / Typ danych | Znaczenie i obsługa wartości pustych |
|---|---|
| String | Wartość pusta jest prawidłowa. Importowany jest pusty ciąg znaków. |
| Valueset | Wartość pusta jest prawidłowa. Importowana jest wartość „0”. |
| boolean | Wartość pusta nie jest prawidłowa i jest ignorowana podczas importu. |
| byte, short, int, long | Wartość pusta nie jest prawidłowa i jest ignorowana podczas importu. |
| Liczba dziesiętna | Wartość pusta nie jest prawidłowa i jest ignorowana podczas importu. |
| Czas/Data | Wartość pusta nie jest prawidłowa. Kompaktowa format czasu – warianty TimeStamp, CisObjectDate, CisObjectDateUntil, CisObjectTimeStamp: importowana jest wartość UNDEFINED_TIME_STAMP. Kompaktowy format czasu – warianty CisAttributeDate, CisAttributeDateUntil, CisAttributeTimeStamp: dla pustego znacznika czasu importowana jest wartość UNDEFINED_TIME_STAMP, a dla pustej strefy czasowej importowana jest strefa GMT. W formacie znormalizowanym: obsługa zgodna z powyższym opisem. |
| GUID | Wartość pusta jest prawidłowa. Importowana jest wartość null. |
| BLOB | Wartość pusta jest prawidłowa jako ścieżka do pliku z zawartością. Jeśli plik nie jest określony – jest to ignorowane. Jeśli określony plik nie istnieje – podczas importu pojawia się komunikat o błędzie. |
| Atrybut złożony (część) | Wartość pusta jest prawidłowa w formacie XML tylko wtedy, gdy ustawiono xsi:nil=”true”. W takim przypadku importowana jest wartość null dla części. W formatach Tekst i Unicode wartość null dla części nie może zostać ustawiona przez import. |
Ilekroć powyższa tabela stwierdza, że wartość pusta jest ignorowana, oznacza to, że wartość już ustawiona w bazie danych dla danego obiektu zostanie zachowana w przypadku aktualizacji danych. W przypadku, gdy obiekt zostanie nowo utworzony, otrzyma on wartość określoną dla niego przez odpowiedni kontroler.
Puste wartości GUID w kluczach
Puste wartości GUID nie są dozwolone w kluczach (klucz podstawowy, klucz biznesowy, klucz drugorzędny, klucz unikalny). Może to prowadzić do błędów importu, jeśli plik zawiera identyfikator GUID z pustymi wartościami jako część klucza i jeśli ten atrybut jest aktywny w pliku importu. Nie ma to wpływu na klucze zewnętrzne, pod warunkiem, że atrybut nie jest jednocześnie częścią jednego z kluczy wymienionych powyżej.
Podczas usuwania wartości GUID dla wyżej wymienionych kluczy z pliku importu, możesz usunąć cały atrybut GUID (dla typów plików Tekst i Unicode: należy usunąć kolumnę z pliku) lub dezaktywować atrybut w filtrze.
Skrócona notacja atrybutów
W pewnych okolicznościach atrybuty z relacji niezależnych mogą być zapisane w plikach w dwóch różnych notacjach. Te dwie notacje są identyczne w ich znaczeniu dla pliku. Ich jedyna różnica polega na ścieżce elementu oznaczającej atrybut w pliku.
Ścieżka elementu atrybutu wskazuje, poprzez które elementy modelu danych atrybut ten jest dostępny z głównego obiektu jednostki biznesowej. W plikach typu Tekst i Unicode ścieżka elementu jest zawarta jako nagłówek kolumny. W plikach typu XML ścieżka elementu wynika z łańcucha elementów XML, za pośrednictwem których element XML atrybutu jest dostępny z głównego obiektu.
W przypadku skróconej notacji, ścieżka elementu kończy się nazwą relacji, podczas gdy w przypadku notacji pełnej długości, po nazwie relacji następuje nazwa atrybutu. Poniższy przykład pokazuje obie notacje dla atrybutu o nazwie isoCode z relacji Language pobranej z obiektu biznesowego Partnerzy. Atrybut isoCode ma wartość de.
| XML | Tekst, UnicodePrzykłady zawierają nagłówek kolumny i przykładową wartość | |
| Zapis pełnej długości | <Language> <isoCode>de</isoCode> </Language> |
Language.isoCode de |
| Skrócony zapis | <Language>de</Language> | Language de |
Pełnowymiarowa notacja jest zwykle używana w plikach przetwarzanych przez BIS. Skrócona notacja może być używana w następujących przypadkach:
- relacja nie jest relacją zależną,
- związek nie jest związkiem wielokrotnym,
- atrybut jest atrybutem prosty,
- żaden inny atrybut nie jest używany w relacji i żadna inna relacja zawarta w pliku nie jest używana (atrybut jest jedynym elementem używanym w relacji).
Te dwie notacje są używane w następujący sposób:
- Od wersji 4.2 do eksportu używana jest tylko notacja pełnej długości.
- W przypadku importu dozwolone są obie notacje.
- Od wersji 4.2 schematy XML generowane przez system obsługują tylko notację pełnej długości.
Oczywiście skrócone notacje nie stanowią problemu w przypadku importowania do wersji 4.2 plików, które zostały wyeksportowane z wersji 4.1 lub starszych.
Walidacja względem schematu XML
Plik źródłowy XML, który został pomyślnie zweryfikowany pod kątem schematu XML wyznaczonego filtra importu, może zawsze zostać zaimportowany za pomocą tego filtra.
Pliki źródłowe używające skróconej notacji nie mogą zostać zweryfikowane względem schematu XML, ale mimo to mogą zostać zaimportowane.
Procesy importu i eksportu
Proces importu to proces importowania instancji jednostki biznesowej z pliku (pliku źródłowego) w bazie danych dla określonej jednostki biznesowej. Proces eksportu to proces eksportowania instancji obiektów biznesowych jednostki biznesowej do pliku.
W następnych kilku rozdziałach omówione zostaną tematy związane z importem i eksportem. Następnie opisany zostanie sposób działania procesów importu i eksportu.
Informacje ogólne
Rejestrowanie
Użytkownik może wybrać rejestrowanie procesów importu i eksportu. Jeśli rejestrowanie jest wyłączone, dziennik nie będzie zapisywany, a BIS będzie zachowywał się jak w wersji 4.3.
Każdy zarejestrowany import i eksport otrzymuje oddzielny wpis w dzienniku. Dziennik zawiera następujące informacje:
- Wynik lub status procesu eksportu/importu,
- Przetworzone pliki (plik eksportu, plik importu, plik błędu),
- Lista wyeksportowanych/zaimportowanych instancji,
- Komunikaty o błędach związane z instancjami (w przypadku błędów importu),
- Korekty przeprowadzone w przypadku nieprawidłowego importu.
Dziennik jest sukcesywnie zapisywany w bazie danych podczas procesu importu/eksportu. Umożliwia to monitorowanie postępu dłuższego importu danych w trakcie jego trwania. Po zakończeniu procesu można wyświetlić jego wynik.
Korekty niepoprawnych importów są własnymi procesami importu, wykorzystującymi pliki błędów jako pliki źródłowe. Jeśli korekta została wywołana za pośrednictwem dziennika, proces importu korekty jest rejestrowany w tym samym wpisie dziennika, co oryginalny proces importu.
Aplikacje i opcje korekty
Aplikacja Lista: Zapisy protokołu wymiany danych oferuje przegląd przeprowadzonych importów i eksportów. Istnieją różne sposoby zawężenia listy wpisów dziennika, np. poprzez filtrowanie tekstów komunikatów o błędach dotyczących nieprawidłowego importu. Jako konfigurowalna aplikacja typu lista, aplikacja może być również dostosowana do potrzeb użytkowników.
W aplikacji Zapisy protokołu wymiany danych użytkownicy mogą przeglądać szczegóły dotyczące poszczególnych wpisów dziennika. Szczegóły te obejmują ostatnio przeprowadzony proces dla wpisu dziennika, a także instancje w nim przetwarzane. Jeśli podczas importu tych instancji wystąpiły błędy, użytkownicy mogą również wyświetlić odpowiednie komunikaty o błędach.
Dziennik oferuje kilka różnych opcji korygowania nieprawidłowych importów. Korekty zainicjowane w jednej z wyżej wymienionych aplikacji są rejestrowane we wpisie dziennika oryginalnego importu. Jeśli przeprowadzono jakiekolwiek korekty, proces wyświetlany w aplikacjach Lista: Zapisy protokołu wymiany danych i Zapisy protokołu wymiany danych jest zawsze ostatnio zainicjowana korekta.
Aplikacja Zapisy protokołu wymiany danych umożliwia przechowywanie pliku eksportu/importu i, w razie potrzeby, najnowszego pliku błędu w Knowledge Store lub w systemie plików w celu dalszego przetwarzania w aplikacjach zewnętrznych.
Status
Całkowity status wpisu dziennika wymiany danych wskazuje, jak daleko posunęły się importy, eksporty i korekty.
- W opracowaniu, W opracowaniu (korekta) i W opracowaniu (program korygujący) — trwa proces dla wpisu dziennika wymiany danych
- Skutecznie — wszystkie instancje zostały pomyślnie wyeksportowane, zaimportowane lub skorygowane
- Błędnie — wystąpiły błędy. Różne przypadki błędów są rozróżniane na podstawie stanu ostatniego procesu.
- Zamknięte ręcznie — oznacza procesy wymiany danych, które na polecenie użytkownika nie mają być dalej przetwarzane.
Ostatni proces może mieć następujące statusy:
- W opracowaniu— przebieg jest przetwarzany.
- Zakończone pomyślnie — wszystkie instancje zostały pomyślnie wyeksportowane, zaimportowane lub poprawione
- Zakończone z błędami — wszystkie instancje zostały przetworzone, ale wystąpiły błędy
- Przerwane przez aplikację — uruchomienie zostało anulowane z powodu błędu programu. Wszystkie instancje mogły nie zostać przetworzone.
- Przerwane przez użytkownika — uruchomienie zostało przerwane na żądanie użytkownika
- Przerwane przez system — przetwarzanie nie mogło zostać ukończone z powodu awarii systemu. Status ten można określić dopiero po synchronizacji dziennika wymiany danych.
Ponieważ anulowane procesy importu mogą skutkować niekompletnymi plikami błędów lub ich całkowitym brakiem, korekty za pomocą dziennika wymiany danych nie są w takich przypadkach możliwe.
Synchronizacja dziennika
Ta czynność pozwala użytkownikom określić, czy procesy wymiany danych zostały anulowane z powodu awarii systemu.
Ograniczenia
Po włączeniu rejestrowania, rejestrowana jest również zawartość plików, co powoduje odpowiednie zwiększenie przestrzeni dyskowej wymaganej dla dziennika w bazie danych OLTP. Dziennik powinien być zatem regularnie reorganizowany, szczególnie po przetworzeniu dużych plików.
Aktywowane logowanie zwiększa liczbę dostępów zapisu do OLTP podczas procesów wymiany danych. W bazach danych z dużym obciążeniem przetwarzania może to negatywnie wpłynąć na wydajność w porównaniu do procesów wymiany danych z wyłączonym logowaniem.
Rejestrowanie zawartości plików nie jest przeznaczone do celów archiwizacji, ponieważ one również zostaną usunięte podczas reorganizacji.
Niektóre obiekty biznesowe zawierają atrybuty typu danych BLOB w swoim modelu danych BIS. Przykładem może być jednostka biznesowa Dokument (com.cisag.app.general.docman.obj.Document). Oddzielne pliki przechowujące zawartość obiektów BLOB nie są uwzględniane w dzienniku BIS. Korekta za pomocą dziennika BIS nie jest zatem możliwa w przypadku użycia takiego atrybutu.
Reorganizacja
Dziennik wymiany danych jest przechowywany w bazie danych OLTP. Powinien on być regularnie reorganizowany. W tym celu dostępna jest aplikacja do reorganizacji Reorganizacja pozycji protokołu wymiany danych. Aby uzyskać więcej informacji, należy zapoznać się z artykułem Reorganizacja pozycji protokołu wymiany danych.
Definicja i wpływ języków sesji
Ustawienia języka dla sesji, podczas której przeprowadzany jest import lub eksport, mają następujący wpływ na BIS:
- Serializacja niektórych typów danych w typach plików Tekst i Tekst Unicode zależy od języka zawartości sesji i została opisana w rozdziale Formaty serializacji typów danych.
- Serializacja atrybutów wielojęzycznych w jednym języku ustawieniu języka zależy od standardowego języka bazy danych, która jest źródłem eksportu / miejsca docelowego importu. W takim przypadku wartość atrybutu zostanie zaimportowana/wyeksportowana w standardowym języku. Dotyczy to wszystkich typów plików.
W przypadku jednostek biznesowych w bazie danych OLTP lub OLAP standardowym językiem bazy danych jest język treści sesji, a w przypadku jednostek biznesowych w bazie danych repozytorium jest to język wyświetlania sesji.
Język treści i język wyświetlania sesji są określane na różne sposoby, w zależności od kanału, za pośrednictwem którego sesja została zainicjowana:
- Jeśli chodzi o logowanie dialogowe i zdalne, oba języki są określane przez ustawienia użytkownika obowiązujące w momencie logowania dla użytkownika, dla którego sesja jest inicjowana. W przypadku logowania dialogowego użytkownicy mogą również zmieniać ustawienia podczas sesji.
- Zadania wykonywane w tle przyjmą ustawienia dla obu języków z sesji, w której zostały utworzone. Importy przetwarzane w zadaniach wsadowych utworzonych w aplikacji Import danych lub Automatyczny import danych będą zatem przyjmować ustawienia językowe z sesji dialogowej. Alternatywnie można jawnie określić język treści dla zadania w tle w oknie dialogowym.
Import
W trakcie procesu importu każda jednostka biznesowa z pliku źródłowego jest wczytywana, sprawdzana i, jeśli sprawdzenie zakończyło się pomyślnie, zapisywana w bazie danych. Jeśli sprawdzenie nie powiedzie się dla instancji jednostki biznesowej, oznacza to, że wystąpił błąd importu dla tej instancji, co spowoduje zapisanie instancji w pliku błędu, jak opisano poniżej. Należy zwrócić uwagę, że może się zdarzyć, że niektóre instancje z pliku źródłowego zostaną zaimportowane, podczas gdy inne instancje z tego samego pliku pokażą błędy importu.
Import ilości danych
To, które atrybuty z pliku źródłowego mają być używane do importu, zależy od samego pliku źródłowego, a także od filtra.
- Atrybuty z pliku źródłowego są używane tylko wtedy, gdy są aktywowane w filtrze.
- Atrybuty z pliku źródłowego, które są nieaktywne w filtrze, zostaną pominięte bez ostrzeżenia. Dotyczy to również atrybutów, które nie są zawarte w modelu danych jednostki biznesowej.
Podczas przeprowadzania importu należy upewnić się, że wszystkie atrybuty, które mają zostać zaimportować, są aktywowane w filtrze.
W wielu przypadkach można użyć standardowego filtra importu, w którym aktywowane są wszystkie atrybuty. Jeśli jednak istnieją pewne atrybuty, które nie mają zostać importowane z pliku źródłowego, należy użyć filtra, który został odpowiednio dostosowany. Należy zwrócić również uwagę na specyfikę typów plików Tekst i Unicode opisanych w rozdziale Tekst i Tekst Unicode.
Import jest możliwy tylko wtedy, gdy ustawienia języka i format czasu filtra i pliku są zgodne.
Gdy atrybut wielojęzyczny jest importowany z ustawieniem języka Jeden język, wartość wskazana w pliku zostanie użyta w języku treści sesji, w której odbywa się proces importu. Przy ustawieniu języka Wielojęzyczny atrybuty wielojęzyczne są importowane w następujący sposób:
- Wartości dla języka bazy danych są przyjmowane z pliku źródłowego.
- Wartości dla języków spoza bazy danych lub dla nieznanych języków są pomijane bez ostrzeżenia.
Tryby importu
Domyślnie import powoduje, że obiekty są aktualizowane lub nowo tworzone (standardowy tryb importu). Istnieją jednak inne tryby importu dostępne dla plików typu XML, które określają wpływ importu na importowane obiekty. Dla plików typu Tekst i Unicode dostępny jest tylko tryb standardowy.
Poniższa tabela zawiera przegląd różnych trybów importu. Importowane jednostki biznesowe zazwyczaj obsługują wszystkie te tryby. Wszelkie wyjątki od tej reguły są opisane w dokumentacji dotyczącej importu danych jednostek biznesowych.
| Tryb | Znaczenie | Wartość |
|---|---|---|
| Tryb standardowy | Tworzenie nowego obiektu lub aktualizacja istniejącego obiektu. | (brak – tryb domyślny) |
| Tylko tworzenie | Obiekt jest tworzony w bazie danych. Jeśli już istnieje, występuje błąd importu. | create |
| Tylko aktualizacja | Obiekt jest aktualizowany w bazie danych. Jeśli nie istnieje, występuje błąd importu. | update |
| Sprawdzenie | Wykonywane są jedynie kontrole poprawności, bez zapisywania obiektu do bazy danych. Jeśli kontrole wykażą błędy, obiekt jest rejestrowany wraz z komunikatami o błędach w pliku błędów. | validate |
| Usunięcie | Obiekt jest usuwany lub ustawiane jest dla niego oznaczenie usunięcia (w zależności od działania kontrolera). W tym trybie zazwyczaj wystarcza, aby w pliku źródłowym zawarte były tylko atrybuty kluczowe. | delete |
Tryb importu jest wskazywany w pliku importu za pomocą atrybutu XML mode. Atrybut ten jest wskazywany na elemencie XML dla obiektu głównego lub zależnego. Na przykład, oznaczenie elementu do usunięcia wyglądałoby następująco:
<Item mode="delete">
<numer>.....</numer>
......
W razie potrzeby atrybut XML musi być wskazany na każdym obiekcie w pliku importu. W ten sposób można ustawić różne tryby importu dla różnych obiektów.
Aby użyć trybu standardowego, należy pominąć atrybut XML mode lub ustawić jego wartość na pusty ciąg znaków.
Import połączonych plików
Korzystając z formatów Tekst rozdzielony separatorami i Tekst Unicode rozdzielany tabulatorami, można importować dodatkowe pliki wraz z głównym plikiem źródłowym.
Z takiego połączonego pliku importowane są dane dla określonego obiektu i wszelkich istniejących obiektów podrzędnych. Połączone pliki mogą być używane w następujących przypadkach:
- Obiekt jest obiektem docelowym wielu relacji głównego obiektu jednostki biznesowej.
- Obiekt jest dostępny za pośrednictwem kilku pojedynczych relacji i jednej relacji głównej jednostki biznesowej.
Natomiast połączone pliki nie mogą być używane do:
- obiektów docelowych pojedynczych relacji,
- obiektów docelowych wielu relacji, których obiekt źródłowy jest już importowany z połączonego pliku,
- głównego obiektu jednostki biznesowej.
Ścieżka obiektu dla połączonego pliku wskazuje relacje, za pośrednictwem których można uzyskać dostęp do najwyższego obiektu w połączonym pliku z głównego obiektu podmiotu gospodarczego. Przykład dla jednostki biznesowej Partnerzy:
- CommunicationData — jako obiekt docelowy relacji CommunicationData,
- Employee.PartnerRelations — relacja wielopoziomowa PartnerRelations jest dostępna za pośrednictwem pojedynczej relacji Employee; obiekt docelowy wspomnianej relacji wielopoziomowej tworzy łącze w tym przykładzie.
Należy pamiętać, że każda ścieżka obiektu sugerowana podczas procesu importu może być użyta tylko dla jednego połączonego pliku.
Automatyczna konwersja do XML
W przypadku plików typu Tekst i Unicode, główny plik źródłowy i wszelkie dodatkowe powiązane pliki źródłowe są konwertowane do jednego pliku XML na początku procesu importowania. Przekonwertowany plik jest tworzony w folderze zawierającym plik źródłowy/główny plik źródłowy. Nazwa nowego pliku jest oparta na nazwie pliku źródłowego, którego rozszerzenie jest zastępowane przez .converted.xml.
Zarówno plik źródłowy, jak i przekonwertowany plik będą nadal dostępne po zakończeniu procesu importowania. Przekonwertowany plik pozwala stwierdzić, czy wszystkie atrybuty zostały poprawnie przyjęte podczas odpowiedniego procesu importu z połączonymi plikami. Jeśli chcesz powtórzyć proces importu, możesz to zrobić zarówno z oryginalnymi plikami, jak i z przekonwertowanym plikiem.
Aspekty wydajności
Import plików typu Tekst lub Unicode zawsze rozpoczyna się od konwersji plików źródłowych do jednego pliku XML, jak opisano w rozdziale Automatyczna konwersja do XML. Dlatego zaleca się używanie pliku źródłowego XML na początku, gdy tylko jest to możliwe, aby zaoszczędzić dodatkowy czas wymagany do konwersji.
Zawsze, gdy dane dla określonej jednostki biznesowej są rozproszone w kilku plikach typu Tekst lub Unicode, powinno się skorzystać z opcji importowania połączonych plików, aby uniknąć konieczności importowania plików osobno, jeden po drugim. Pozwoli to znacznie zmniejszyć liczbę dostępów do bazy danych i zaoszczędzić czas.
Powiadomienie o udanym imporcie
Można zdecydować się na otrzymywanie powiadomień o powodzeniu lub niepowodzeniu procesów importu za pomocą Workflow Management. Czas i sposób powiadomienia zależy od użytkownika.
Na przykład, można wybrać, aby zadanie przepływu pracy było generowane dla Ciebie po każdym przeprowadzonym procesie importu. Te zadania przepływu pracy pojawią się następnie w panelu nawigacji (zakładka Wyszukaj zadania).
Za pomocą takiego zadania Workflow Management wysłanego do nich w związku z importem danych, użytkownicy mogą otworzyć aplikację systemową wyświetlającą szczegóły procesu importu i, jeśli to konieczne, mogą zainicjować korektę. W przypadku importów bez rejestrowania będzie to aplikacja Import danych, natomiast w przypadku importów z rejestrowaniem użytkownicy powinni wybrać aplikację Zapisy protokołu wymiany danych. Aby było to możliwe, wybrana aplikacja musi zostać określona w definicji aktywności jako aplikacja, która ma zostać otwarta.
Aby powiadomienie działało, definicja aktywności reagująca na zdarzenie przepływu pracy com.cisag.pgm.bi.ImportRunCompleted musi zostać utworzona i aktywowana dla Workflow Management. Aby uzyskać więcej informacji, należy zapoznać się z artykułem Interfejsy eksportu i importu, a także z dokumentacją dotyczącą Workflow Management.
Postępowanie w przypadku błędów importu
Plik błędu i rejestrowanie
Instancje obiektów biznesowych, które nie mogły zostać pomyślnie zweryfikowane podczas procesu importu, zostaną zapisane w pliku błędów. Plik błędu jest plikiem XML i ma taki sam format jak pasujący plik źródłowy XML dla danej jednostki biznesowej.
Ponadto komunikaty o błędach wygenerowane podczas walidacji są zapisywane w pliku błędów. Można je znaleźć bezpośrednio pod elementem XML nieprawidłowej instancji jednostki biznesowej, co umożliwia dopasowanie komunikatów o błędach do instancji, których dotyczą, nawet jeśli zaimportowano kilka instancji.
Po włączeniu rejestrowania, przetwarzane instancje zostaną wymienione w dzienniku. Nieprawidłowe instancje będą rejestrowane wraz z dotyczącymi ich komunikatami o błędach. Plik błędu jest również zapisywany w dzienniku i w razie potrzeby może być przechowywany w Knowledge Store lub w systemie plików.
Jeśli rejestrowanie nie jest włączone, plik błędu zostanie zapisany jako plik w Knowledge Store lub w systemie plików. Domyślną nazwą pliku błędu jest nazwa pliku źródłowego, którego oryginalne rozszerzenie zostało zastąpione rozszerzeniem .error.xml. W przypadkach, gdy plik źródłowy został przekonwertowany na XML, plik błędu będzie miał rozszerzenie .converted.error.xml.
Anulowane procesy importu
W pewnych okolicznościach, np. jeśli plik importu zawiera błędy składniowe, proces importu zostanie anulowany. W takim przypadku nie można zapewnić pełnego przetwarzania wszystkich instancji.
Anulowane procesy importu mogą skutkować brakującymi lub niekompletnymi plikami błędów. Ponowny import niekompletnego pliku błędu może nie być możliwy. Analiza błędów będzie musiała zostać przeprowadzona na podstawie pliku błędów, pliku importu i, w razie potrzeby, dziennika.
Poprawianie błędów importu
W poniższych trzech sekcjach opisano różne dostępne opcje korygowania błędów importu.
Korygowanie w aplikacji korygującej
Nieprawidłowe dane można poprawić w aplikacjach przeznaczonych dokładnie do tego celu (aplikacje korygujące). Zazwyczaj odpowiednią aplikacją korygującą jest aplikacja dialogowa danej jednostki biznesowej. Aplikacje przeznaczone do korygowania błędów są rejestrowane osobno jako służące do tego celu.
Korekta za pomocą aplikacji korygującej jest możliwa w następujących przypadkach:
- Proces importu został uruchomiony z włączonym logowaniem (w dowolnej aplikacji).
- Proces importu został uruchomiony w aplikacji Import danych z ustawieniem „Koryguj: Z aplikacją korygującą” i w trybie [Natychmiast].
- Proces importu został uruchomiony w aplikacji Import danych, w aplikacji działającej w tle Import danych w tle lub za pośrednictwem zdalnego BIS, w każdym przypadku z ustawieniem Popraw: Z Workflow Management i z włączonymi powiadomieniami o Workflow Management.
- Proces importu został uruchomiony w aplikacji Automatyczny import danych i aktywowano powiadomienia o Workflow Management.
Wskazówki dotyczące korzystania z aplikacji korygujących można znaleźć w rozdziale Aplikacje korekty operacyjnej.
Korekta w pliku błędów
Zawsze można skorygować plik błędu ręcznie, zamiast korzystać z aplikacji korygującej. Następnie można po prostu ponownie zaimportować poprawiony plik błędu zamiast pliku źródłowego.
- Przy włączonym rejestrowaniu, ręcznie poprawione pliki błędów mogą być importowane za pośrednictwem aplikacji Lista: Zapisy protokołu wymiany danych i Zapisy protokołu wymiany danych. Ustawienia importu zostaną wprowadzone automatycznie.
- Jeśli rejestrowanie jest wyłączone, należy użyć aplikacji Import danych i wybierać poprawiony plik błędu jako plik importu.
Korygowanie danych zależnych
Przyczyna błędów nie zawsze leży w danych importu – czasami niektóre dane muszą zostać wprowadzone lub zmienione w systemie, aby umożliwić import danych.
- Przy włączonym rejestrowaniu, pliki błędów mogą być importowane za pomocą aplikacji Lista: Zapisy protokołu wymiany danych i Zapisy protokołu wymiany danych. Ustawienia importu zostaną wprowadzone automatycznie.
- Jeśli rejestrowanie jest wyłączone, należy użyć aplikacji Import danych i wybierać plik błędu jako plik importu.
Korzystanie z filtrów importu
W przypadku importu rozpoczętego w aplikacji Import danych można użyć zapisanego filtra lub nowo utworzonego filtra, który nie został zapisany.
W przypadku korekt uruchamianych w aplikacji korekty lub w aplikacjach Lista: Zapisy protokołu wymiany danych i Zapisy protokołu wymiany danych obowiązują następujące zasady dotyczące korzystania z filtrów:
- Jeśli istniejący filtr jest używany w niezmienionej postaci, tj. jeśli aplikacja Import danych jest w trybie wyłączenia, baza danych przeładuje filtr dla każdego importu i każdej korekty. Wszelkie późniejsze zmiany w filtrze mogą zatem mieć wpływ na kolejne korekty.
Dotyczy to również automatycznych importów, niezależnie od sposobu ich uruchomienia. - Jeśli używany jest nowo utworzony, niezapisany filtr lub jeśli wprowadzono jakiekolwiek zmiany w otwartym filtrze bez jego zapisania, aplikacja będzie w trybie Nowy lub Edycja. W takim przypadku kopia ustawień filtra wyświetlana w aplikacji zostanie przekazana do zaimportowania. Późniejsze zmiany filtra nie będą zatem miały wpływu na korekty.
Zautomatyzowane importy powinny być zawsze przeprowadzane z oddzielnym filtrem, aby zapobiec niepożądanym zmianom. Również w przypadku importu automatycznego baza danych przeładuje filtr dla każdego procesu importu.
Dalsze opcje importu
Opisane poniżej funkcje służą w szczególności do ułatwienia importu dużych ilości danych i testowania scenariuszy importu.
Dane wyjściowe atrybutów niezałączonych
Ustawienie poziomu debugowania dla klasy ImportSupport umożliwia dokładniejsze monitorowanie procesów importu. Poziom można ustawić za pomocą tego polecenia powłoki narzędziowej:
dbgcls -class:com.cisag.pgm.bi.ImportSupport
Na poziomie debugowania WARNING, dane wyjściowe będą wyświetlane na konsoli, jeśli atrybuty z pliku źródłowego nie zostaną uwzględnione. Nieuwzględnienie atrybutu może być spowodowane dezaktywacją tego atrybutu w filtrze lub tym, że jednostka biznesowa nie zawiera atrybutu o tej nazwie. W tym drugim przypadku nazwa atrybutu może być błędnie wpisana w pliku źródłowym.
Wyświetlanie postępu importu
Z poziomem debugowania ustawionym za pomocą polecenia
dbgcls -class:com.cisag.pgm.bi.ImportSupport
(do wersji 4.3) lub
dbgcls -class:com.cisag.sys.Tool.bi.log.process.ImportProcessor
(począwszy od wersji 4.4)
Na poziomie debugowania INFO, jeden wynik na instancję jednostki biznesowej ze źródła jest tworzony na konsoli przed importem. Pozwala to na monitorowanie postępu dłuższych procesów importu.
Wyświetlanie komunikatów o błędach importu
Jeśli komunikaty o błędach i ostrzeżenia wyzwalane podczas importu mają być wyświetlane nie tylko w pliku błędów, ale także na konsoli i w dziennikach komunikatów, należy użyć polecenia toolshell podanego poniżej. Komunikaty o błędach i ostrzeżenia będą wyświetlane wraz ze śladem stosu.
dbgmsgmgr -loglevel:15 -traceLevel:15
Jest to szczególnie pomocne w przypadkach, gdy z powodu zagnieżdżonych wywołań komunikaty z klas logicznych mogą być wysyłane przez kontrolery, ale nie są odpowiednio brane pod uwagę, co skutkuje niepowodzeniem procesu importu bez wyraźnego powodu, tj. bez wyświetlania komunikatów o błędach w pliku błędów.
Automatyczny import
Dostępne są różne opcje importowania danych w określonym czasie lub po wystąpieniu określonego zdarzenia. To, z której z nich powinno się skorzystać, zależy od konkretnego scenariusza:
- W aplikacji Import danych można utworzyć zadanie wsadowe w celu zaimportowania pliku natychmiast, w określonym czasie lub okresowo (np. jako seria).
- W aplikacji Automatyczny import danych można utworzyć zadanie w tle do okresowego importowania wszystkich plików XML z określonego folderu. Jest to szczególnie przydatne w scenariuszach EDI, w których system automatycznie otrzymuje dane z systemów nadrzędnych.
- Za pomocą definicji aktywności można wywołać aplikację działającą w tle w celu importu. Aby uzyskać pełny opis, należy zapoznać się z artykułem Interfejsy programistyczne do wymiany danych.
Eksport
Eksport ilości danych
Korzystając z ograniczenia, określana są ograniczenia, które instancje jednostki biznesowej mają zostać wyeksportowane i w jakiej kolejności mają zostać zapisane w pliku eksportu. Odbywa się to za pomocą wyszukiwania OQL lub dynamicznej instrukcji OQL.
Za pomocą filtra określane jest, które atrybuty ma zawierać plik docelowy dla każdej wyeksportowanej instancji. Atrybuty aktywowane w filtrze zostaną wyeksportowane.
Ustawienie języka filtra pozwala określić, w jaki sposób mają być eksportowane atrybuty wielojęzyczne. Przy ustawieniu języka Jeden język eksportowana jest tylko wartość w standardowym języku bazy danych bieżącej sesji. Przy ustawieniu Wielojęzyczny eksportowane są wartości we wszystkich językach bazy danych.
Zaleca się utworzenie filtra dla eksportu i aktywowanie tylko niezbędnych atrybutów, aby zapobiec zaśmieceniu plików docelowych i ograniczyć rozmiar pliku.
Eksport automatyczny
Istnieje kilka różnych opcji eksportowania danych w określonym czasie lub po wystąpieniu określonych zdarzeń. To, z której z nich powinno się skorzystać, zależy od konkretnego scenariusza:
- W aplikacji Eksport danych można utworzyć zadanie w tle w celu wyeksportowania pliku natychmiast, w określonym czasie lub okresowo (tj. jako seria). Należy pamiętać, że jeśli plik już istnieje, za każdym razem zostanie nadpisany w procesie.
- Aplikacja Szablony dokumentów pozwala określić, czy dane dokumentu (np. faktury) mają być również eksportowane jako plik XML oraz zdefiniować punkty czasowe (z pierwszym wyjściem lub z pierwszym wyjściem i kopią wyjścia) oraz objętość eksportu XML. W tym przypadku zmienne mogą być używane do nazywania folderów i plików; istniejące pliki zostaną automatycznie przemianowane. Jest to szczególnie przydatne w scenariuszach EDI, w których system automatycznie przekazuje dane do systemów niższego szczebla.
- Za pomocą definicji aktywności można wywołać aplikację działającą w tle w celu eksportu. Pełny opis można znaleźć w artykule Interfejsy programistyczne do wymiany danych.
Uprawnienia w BIS
Wiele danych w systemie jest dostępnych za pośrednictwem BIS. Podczas eksportowania danych za pośrednictwem BIS użytkownicy mogą mieć dostęp do rekordów danych, których nie mogą otwierać zgodnie z obowiązującymi ustawieniami autoryzacji. Zakres, w jakim uprawnienia są brane pod uwagę podczas importu, zawsze zależy od eksportowanej jednostki biznesowej.
Jeśli chodzi o administrowanie systemem, powinno podjąć środki opisane poniżej, aby ograniczyć dostęp do BIS do autoryzowanych użytkowników.
Autoryzacja aplikacji
Uprawnienia do otwierania wymienionych poniżej aplikacji powinny być przyznawane wyłącznie użytkownikom, którzy muszą przeprowadzać import lub eksport danych.
Aby korzystać z BIS za pośrednictwem aplikacji dialogowych, można wprowadzić uprawnienia dla następujących aplikacji:
- Eksport danych (com.cisag.sys.Tool.bi.ui.ExportMaintenance),
- Import danych (com.cisag.sys.Tool.bi.ui.ImportMaintenance),
- Automatyczny import danych (com.cisag.sys.Tool.bi.ui.AutomaticImportMaintenance).
Do przeglądania dziennika wymiany danych i inicjowania korekt za pomocą dziennika wymiany danych:
- Lista: Zapisy protokołu wymiany danych (com.cisag.sys.Tool.bi.ui.ProcessProtocolCockpit),
- Zapisy protokołu wymiany danych (com.cisag.sys.Tool.bi.ui.ProcessRunMaintenance),
- Reorganizacja pozycji protokołu wymiany danych (com.cisag.sys.Tool.bi.log.ProcessProtocolReorganization).
Te dwie aplikacje działające w tle są odpowiednie do uruchamiania importów i eksportów za pośrednictwem przepływu pracy lub za pośrednictwem dostosowanych aplikacji:
- Eksport danych w tle (com.cisag.pgm.bi.Export)
- Import danych w tle (com.cisag.pgm.bi.Import)
Następujące aplikacje są istotne dla korzystania ze zdalnego BIS:
- Zdalny eksport danych (com.cisag.sys.Tool.bi.log.RemoteExport)
- Zdalny import danych (com.cisag.sys.Tool.bi.log.RemoteImport)
- Przeprowadź wyszukiwanie zdalnie (com.cisag.sys.Tool.bi.log.RemoteSearch)
Uprawnienia jednostek biznesowych
Użytkownicy dokonujący importu i eksportu danych za pośrednictwem BIS muszą być autoryzowani w odniesieniu do jednostek biznesowych, które mają być eksportowane/importowane.
Aby uzyskać ogólne informacje na temat autoryzacji, należy zapoznać się z artykułem Uprawnienia.
Aplikacje korekty operacyjnej
Jeśli podczas importu wystąpiły błędy, nieprawidłowe dane można zasadniczo poprawić bezpośrednio w systemie, jeśli wybrane zostanie ustawienie korekty Za pomocą obiegu pracy lub Za pomocą aplikacji korekt dla procesu importu. Należy jednak pamiętać, że w przypadku niektórych poważnych błędów nie można przeprowadzić korekty w aplikacji korekt. Możliwe przyczyny takich błędów obejmują nieprawidłowe składniowo pliki źródłowe lub użycie nieprawidłowego kodowania. W takich przypadkach plik źródłowy musi zostać ręcznie otwarty i poprawiony.
Po otwarciu aplikacji korekt wyświetlana jest pierwsza nieprawidłowa instancja jednostki biznesowej z pliku błędu, a komunikaty dotyczące brakujących lub nieprawidłowych informacji są wyświetlane w okienku nawigacji i jako czerwone narożniki w odpowiednich polach. Można teraz poprawić nieprawidłowe dane, a następnie zaakceptować zmiany.
Standardowy pasek narzędzi oferuje zestaw dodatkowych przycisków (opisanych w poniższej tabeli) do obsługi aplikacji korygującej. Gdy te przyciski będą dostępne, niektóre inne standardowe przyciski na standardowym pasku narzędzi zostaną kolejno dezaktywowane.
| Przycisk | Akcja |
| [Akceptuj] | Jeśli nieprawidłowe lub brakujące informacje zostały poprawione lub wprowadzone ręcznie, należy kliknąć ikonę, aby zapisać jednostkę biznesową. Zestaw danych zostanie wtedy faktycznie zaimportowany. Następnie zostanie otwarty kolejny zestaw danych z pliku błędów. |
| [Nie uwzględniaj] | Aktualny rekord danych zostanie usunięty z korekty, a następny rekord z pliku błędów zostanie otwarty. |
| [Następny plik] | Przechodzi do następnego błędnego rekordu danych. Aktualną instancję jednostki biznesowej można poprawić w późniejszym czasie. Po wyświetleniu ostatniej instancji z pliku błędów, po wybraniu tego przycisku ponownie pojawi się pierwsza dostępna instancja. |
Przyciski opisane powyżej zawsze wpływają na wszystkie dane instancji jednostki biznesowej otwartej w aplikacji korygującej. Na przykład akcja wykonana na zamówieniu sprzedaży będzie miała zastosowanie do wszystkich pozycji.
Gdy wszystkie nieprawidłowe instancje zostaną poprawione lub wyłączone z korekty, aplikacja automatycznie zakończy korektę, a dodatkowe przyciski znikną. Poprawione przypadki zostaną usunięte z pliku błędów. Jeśli wszystkie niepoprawne wystąpienia zostały poprawione, plik błędu zostanie usunięty.
Można zakończyć korektę samodzielnie, zamykając aplikację, nawet jeśli wszystkie instancje nie zostały jeszcze poprawione lub wyłączone z korekty. Po zakończeniu korekty, instancje poprawione lub wyłączone z korekty są ponownie usuwane z pliku błędów. Jeśli wszystkie nieprawidłowe instancje zostały poprawione, plik błędów zostanie usunięty. Jeśli w pliku błędów nadal znajdują się nieprawidłowe instancje i jeśli otworzona została aplikacja korekty za pośrednictwem aplikacji Import danych, będzie możliwe wznowienie korekty później za pośrednictwem zdarzenia przepływu pracy lub aplikacji Import danych.
Specyficzne elementy modelu danych BIS
W tym rozdziale opisano niektóre typowe elementy modeli danych BIS.
Strefa czasowa obiektu
Wszystkie obiekty biznesowe zawierające atrybuty daty/czasu w wariantach CisObjectDate, CisObjectDateUntil i CisObjectTimeStamp zawierają dodatkowo wygenerowany atrybut łańcuchowy _timeZone. Atrybut ten jest identyfikatorem strefy czasowej dla wszystkich atrybutów wymienionych wariantów z obiektu biznesowego.
Strefa czasowa obiektu nie jest importowana, a jedynie sprawdzana względem istniejącego obiektu. Strefa czasowa obiektów nowo utworzonych w procesie importu jest zazwyczaj określana przez kontroler z organizacji określonej dla obiektu w pliku źródłowym. Jeśli strefa czasowa pliku źródłowego i strefa czasowa obiektu nie są zgodne, import zostanie anulowany i pojawi się komunikat o błędzie.
Identyfikator bazy danych
Jednostki biznesowe zawierają atrybut managingSystem kategorii GUID, który z kolei zawiera identyfikator bazy danych w scenariuszach eksportu.
Atrybut ten nie może być używany do importu. Obiekty nowo utworzone podczas importu zawsze otrzymują identyfikator bazy danych, do której są importowane. Jeśli istniejący obiekt zostanie zaktualizowany w procesie importu, obiekt ten zachowa swój identyfikator bazy danych.
Waluta wewnętrzna
Wartości w walutach wewnętrznych (część com.cisag.app.general.obj.DomesticAmount) są reprezentowane w modelu danych BIS przez część z następującymi atrybutami i relacjami:
| Atrybut (ścieżka) | Typ danych | Relacja klucza obcego | Opis / znaczenie |
|---|---|---|---|
| amount1 | Liczba dziesiętna (21,6) | Kwota w walucie krajowej 1 | |
| currency1 | GUID | Currency1 | Waluta krajowa 1 |
| amount2 | Liczba dziesiętna (21,6) | Kwota w walucie krajowej 2 | |
| currency2 | GUID | Currency2 | Waluta krajowa 2 |
| amount3 | Liczba dziesiętna (21,6) | Kwota w walucie krajowej 3 | |
| currency3 | GUID | Currency3 | Waluta krajowa 3 |
| exact | Bajt | Bity 0–1 = wartość z exactAmountIndex; bity 2–7 = kombinacja walut krajowych | |
| exactAmountIndex | Bajt | Wskazuje, która wartość jest dokładna (tj. nie powstała w wyniku przeliczenia walut):1 = amount1,2 = amount2,3 = amount3,0 = żadna wartość nie jest dokładna |
Atrybuty currency1 do currency3 są identyfikatorami GUID, a relacje Currency1 do Currency3 są zewnętrznymi relacjami klucza do encji biznesowej com.cisag.app.general.obj.Currency.
Można zaimportować atrybuty amount1, amount2, amount3, a także exactAmountIndex, w tym jego wystąpienie w atrybucie exact.
Podobnie jak strefa czasowa obiektu, pozostałe atrybuty (trzy waluty wewnętrzne i kombinacja walut wewnętrznych) są sprawdzane tylko w odniesieniu do istniejącego obiektu podczas importu. W przypadku niezgodności import zostanie anulowany i pojawi się komunikat o błędzie. Należy pamiętać, że te atrybuty są ustawiane przez logikę biznesową podczas generowania obiektu.
Atrybut exact nie powinien być używany do importu. W razie potrzeby użyj zamiast tego exactAmountIndex i Currency1… Currency3.
Data przeliczenia waluty wewnętrznej
Wszystkie obiekty biznesowe zawierające waluty wewnętrzne (część com.cisag.app.general.obj.DomesticAmount) zawierają dodatkowo atrybut _conversionDate kategorii znacznika czasu. Jest to punkt czasowy konwersji dla walut wewnętrznych, który jest potrzebny do prawidłowego przeliczenia kwot w walucie wewnętrznej w przypadku zmiany kombinacji waluty wewnętrznej. Można go normalnie importować i eksportować.
Termin płatności
W przeciwieństwie do prostych wskazań daty lub godziny, termin płatności (część com.cisag.app.general.obj.PointInTime) jest złożonym typem danych zdolnym do odwzorowania zakresu czasu z pewną dokładnością, np. 01.02.2005 lub KW17/2005. Dokładność, np. dzień lub tydzień kalendarzowy, jest zapisywana w atrybucie accuracy. Wartość, np. 01.02.2005, jest zapisywana w znormalizowanym, technicznym formacie („01#02#2005”) w atrybucie value. Termin płatności może zawierać przesunięcie. To przesunięcie jest zapisywane w atrybucie offset, również w znormalizowanym, technicznym formacie. Na przykład, przesunięcie o jeden dzień odpowiada +1[D]. Wartość symboliczna w atrybucie value jest analizowana w odniesieniu do kalendarza w złożonym atrybucie calendar i jest przesunięta o wartość atrybutu offset, a wynikowy znacznik czasu jest zapisywany w atrybucie timestamp. W wyszukiwaniu terminów ten znacznik czasu jest uważany za reprezentatywną wartość dla całego terminu. Początek terminu płatności jest wskazywany przez znacznik czasu (atrybut timestamp), a jego czas trwania jest wskazywany przez dokładność (atrybut accuracy). Koniec zakresu czasu wynika z jego początku i czasu trwania.
Termin płatności zawiera dodatkowo wpis użytkownika dotyczący punktu początkowego czasu. Punkt początkowy jest obliczany na podstawie tego wpisu z uwzględnieniem dokładności, przesunięcia i kalendarza. Dokładność i przesunięcie wynikają z typu terminu.
| Atrybut (ścieżka) | Typ danych | Relacja klucza obcego | Opis / Znaczenie |
|---|---|---|---|
| accuracy | Wartość | Dokładność terminu. Możliwe wartości: TIME_STAMP (znacznik czasu), DATE (data), CALENDAR_WEEK (tydzień kalendarzowy), MONTH (miesiąc), QUARTER (kwartał), YEAR (rok). |
|
| calendar | Część kalendarza | Kalendarz będący podstawą obliczenia daty początkowej. | |
| value | String(30) | Wartość reprezentująca termin w znormalizowanym formacie technicznym wyszukiwania OQL, zależnym od dokładności. | |
| offset | String(20) | Przesunięcie względem wartości w celu obliczenia wartości dla atrybutu timestamp. | |
| timestamp | Znacznik czasu | Znacznik czasu reprezentujący termin przy wyszukiwaniu OQL. | |
| precision | Precision | Rodzaj terminu. |
Podczas importu atrybuty accuracy, calendar, offset, timestamp i precision są inicjowane przez kontroler z wartościami zależnymi od organizacji importowanej instancji. Jeśli dla calendar i precision zostaną wskazane inne dane niż zawarte w instancji po inicjacji, wartości te zostaną zignorowane.
W scenariuszach importu wartość atrybutu timestamp jest obliczana na podstawie atrybutu value wskazanego podczas importu. Wskazanie value jest zwykle wystarczające do importu. W związku z tym należy również wziąć pod uwagę dokumentację ERP dotyczącą wymiany danych danej jednostki biznesowej.
Format atrybutu value
Atrybut może być wskazany w jednym z następujących formatów:
| Dokładność | Format |
|---|---|
| Znacznik czasu | dd#MM#yyyy hh#mm#ss#SSS |
| Data | dd#MM#yyyy |
| Tydzień kalendarzowy | [$CALENDARWEEK]ww#yyyy |
| Miesiąc | [$MONTH]MM#yyyy |
| Kwartał | [$QUARTER]q#yyyy |
| Rok | [$YEAR]yyyy |
W poniższej tabeli wymieniono symbole składające się na powyższe formaty wraz z ich odpowiednimi znaczeniami.
| Symbol | Znaczenie |
|---|---|
| dd | Dzień (01–31) |
| MM | Miesiąc (01–12) |
| yyyy | Rok (cztery cyfry) |
| ww | Tydzień kalendarzowy (01–53) |
| q | Kwartał (1–4) |
| hh | Godzina (00–23) |
| mm | Minuta (00–59) |
| ss | Sekunda (00–59) |
| SSS | Milisekunda (000–999) |
Przykłady wartości: 15#04#2005 i [$CALENDARWEEK]15#2005
Format atrybutu offset
W przypadku przesunięcia możesz podać informacje o czasie względnym zgodnie z następującym wzorem:
<znak><liczba><jednostka>
Znak to + lub –. To wskazanie można powtórzyć dowolną liczbę razy. (Weź pod uwagę maksymalną długość przesunięcia).
| Symbol jednostki | Znaczenie |
|---|---|
| [ms] | Milisekundy |
| [s] | Sekundy |
| [m] | Minuty |
| [h] | Godziny |
| [D] | Dni |
| [M] | Miesiące |
| [W] | Tygodnie |
| [CW] | Tygodnie kalendarzowe |
| [Q] | Kwartały |
| [Y] | Lata |
Przykłady przesunięć:
| Przykład przesunięcia | Znaczenie |
|---|---|
| +2[D] | Dwa dni później |
| -4[CW]+1[D] | Cztery tygodnie kalendarzowe wcześniej, jeden dzień po rozpoczęciu tygodnia kalendarzowego |
Magazyn
Wiele jednostek biznesowych zawiera złożone atrybuty z opisem Magazyn…, składające się z dwóch prostych atrybutów łańcuchowych. Jednym z przykładów jest atrybut CustomerInvoice.details.storageArea.
Złożony atrybut magazynu może opisywać magazyn lub strefę magazynową. W zależności od tego, dwa proste atrybuty są używane w następujący sposób:
| Atrybut | Typ danych | Znaczenie |
|---|---|---|
| warehouse | str(4) | Identyfikator magazynu. Jeśli opisywana jest strefa magazynowa, atrybut ten wskazuje magazyn, w którym strefa się znajduje. |
| zone | str(4) | Identyfikator strefy magazynowej, jeśli jest ona opisywana w ramach magazynu. Atrybut pozostaje pusty, jeśli opisywany jest wyłącznie magazyn. |
Niezależnie od tego, czy istnieje relacja o tej samej nazwie dla danego atrybutu złożonego, zawsze powinno się używać tego atrybutu do importu i eksportu. Zawiera on już klucze funkcjonalne. Przeprowadzenie importu za pośrednictwem relacji jest generalnie niemożliwe.
Należy pamiętać, że może być konieczne ręczne dostosowanie filtra, aby atrybut był aktywny, a relacja nieaktywna.
Należy wziąć również pod uwagę dokumentację importu danej jednostki biznesowej.
Jednostka
Wiele jednostek biznesowych zawiera niezależne relacje z obiektem biznesowym Unit (com.cisag.app.general.obj.UnitOfMeasure). Poprzez te relacje, używane jednostki są dostępne wraz z ich kluczami biznesowymi.
Kluczem biznesowym jednostki jest kod jednostki. Kod jednostki jest używany na przykład w aplikacjach dialogowych. Aby uprościć obsługę jednostek w scenariuszach EDI, dostępne są dodatkowo kodowania jednostek. Kodowanie jednostek umożliwia wykorzystanie innych identyfikatorów niż kod jednostki do wymiany danych.
Kodowania jednostek dla istniejących jednostek są tworzone w aplikacji Rodzaje kodowania i są podsumowywane do rodzaju kodowania. W funkcji Podstawowe, w aplikacji Konfiguracja, można określić, czy i który typ kodowania ma być używany. Wskazany tam typ kodowania ma zastosowanie do całej bazy danych OLTP.
Rodzaje jednostek są dostępne jako atrybuty wielojęzyczne w bazie danych, a BIS zawsze używa ich w języku treści sesji, podczas której przeprowadzany jest import lub eksport. Z kolei kodowanie jednostek nie jest zależne od języka, oferując pewne korzyści dla EDI również w tym zakresie.
Poniższa tabela pokazuje atrybut zawarty jako identyfikacja w relacji. Atrybut ten może być eksportowany i importowany.
| Atrybut | Typ danych | Znaczenie |
|---|---|---|
| code | str(10) | Identyfikator jednostki. Jeżeli dla tej relacji dostępne są kodowania jednostek, w konfiguracji została wpisana odpowiednia metoda kodowania i w tej metodzie przypisano kodowanie jednostki, atrybut ten przyjmuje wartość tego kodowania jednostki. Kodowanie jednostki jest niezależne od języka treści. W przeciwnym przypadku atrybut zawiera kod jednostki w języku treści sesji, która wykonuje import lub eksport. Zachowanie tego atrybutu jest niezależne od ustawień językowych użytego filtra. |
Pozostałe atrybuty z tej relacji to atrybuty z obiektu biznesowego com.cisag.app.general.obj.UnitOfMeasure. W razie potrzeby można je również wyeksportować, ale nie mają one znaczenia dla importu.
Dalsza dokumentacja
Aby uzyskać więcej informacji na temat specjalnych tematów BIS, należy zapoznać się z następującymi dokumentami:
- Jednostki biznesowe obsługiwane przez BIS są wymienione w artykule Interfejsy eksportu i importu.
- Artykuły Eksport danych i Import danych opisują sposób ręcznego korzystania z BIS i edytowania filtrów.
- Artykuły dla zautomatyzowanego BIS:
- Aby uzyskać informacje na temat korzystania z Workflow Management, należy zapoznać się z dokumentacją Workflow Management.
- Aby uzyskać informacje na temat importowania danych jako zaplanowanych serii, należy zapoznać się z dokumentacją Import danych i Instrukcja obsługi.
- Aby uzyskać informacje na temat okresowego importowania wszystkich plików z określonego folderu, należy zapoznać się z artykułem Automatyczny import danych.
- Jeśli chodzi o eksport danych jako zaplanowanej serii, należy zapoznać się z artykułami Eksport danych i Instrukcja obsługi.
- Aby uzyskać informacje na temat eksportu w kontekście wyjścia dokumentu, należy zapoznać się z artykułem Szablony dokumentów.
- Jeśli chodzi o korzystanie z automatycznego BIS za pośrednictwem zdalnych wywołań, należy zapoznać się z artykułem Zdalne interfejsy BIS.
- Aby uzyskać informacje na temat importowania i eksportowania określonych jednostek biznesowych, należy zapoznać się z artykułami w folderze Wymiana danych.
- Informacje na temat interfejsów oferowanych przez BIS do celów rozwoju oprogramowania:
- Rozwój sterowników BIS
- Wykorzystanie BIS w kodzie aplikacji i w Workflow Management



