Konfiguracja serwera
Po zainstalowaniu serwera Microsoft SQL Serwer należy zwrócić uwagę na kilka rzeczy:
- Zaznaczony parametr SQL Server and Windows Authentication mode
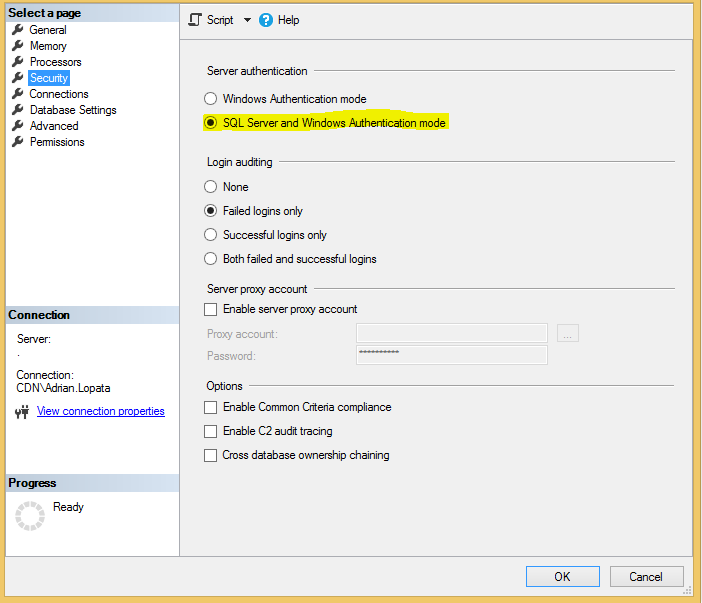
- Zmienić parametry serwera w zakładce Advanced:
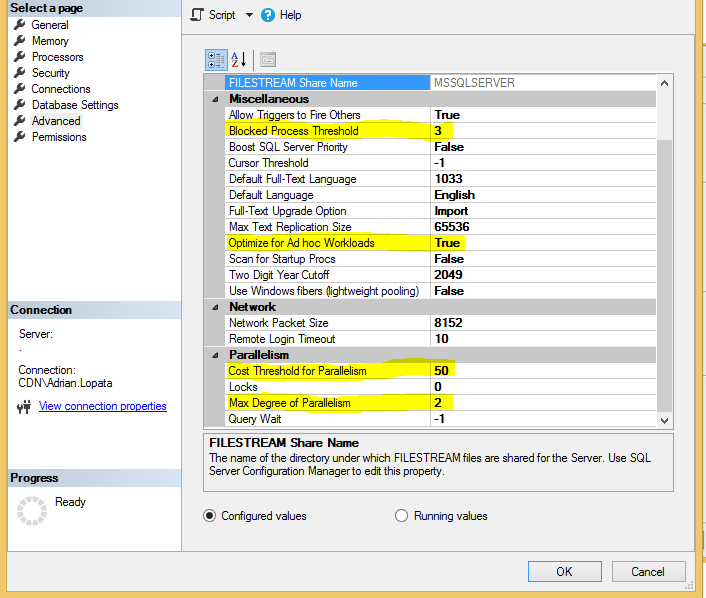
- Blocked Process Threshold – parametr, który odpowiada za rejestrację blokad przez dodatek SQL Server Profiler. Domyślnie ustawiona jest wartość 0 oznacza to, że żadne blokady nie są rejestrowane. Parametr wyrażony jest w sekundach. W tym przypadku będą rejestrowane blokady trwające 3 sekundy i więcej. Parametr ten nie ma bezpośtredniego wpływu na wydajność serwera.
- Optimize for Ad hoc Workloads – parameter, odpowiadający za przetrzymywanie pełnych zapytań wywoływanych Ad – hoc na serwerze. Domyślna wartość False. Parametr warto zmienić na True, ze względu na to, iż podczas pracy w Systemie Comarch ERP XL, wywoływana jest spora liczba zapytań Ad-hoc. Niektóre z nich bardzo rzadko, w związku z tym nie ma potrzeby przetrzymywania ich w buforze. Jeśli zapytanie pojawi się częściej, trafi wówczas w całości do bufora. Pozwoli to zaoszczędzić pamięć RAM na serwerze.
- Cost Threshold For Parallelism – parametr określający jak kosztowne zapytania mają być zrównoleglane. Dla Systemu Comarch ERP XL przyjmuje się że wartości te mogą przybierać wartości od 25 do 50. Przykładowe ustawienie 50 oznacza że tylko zapytania o wyliczonym koszcie przez SQL Server powyżej 50 będą zrównoleglane.
- Max Degree of Parallelism (Max DoP) – parametr określający ile vCPU lub CORE może wziąć udział w zrównoleglaniu zapytania. Domyślna wartość wynosi 0 oznacza to, że o tym ile rdzeni lub wątków zaangażować decyduje SLQ Server. Przyjmuje się że parametr ten nie powinien wynosić więcej niż połowa dostępnych wątków lub CORE dla serwera na którym zainstalowany jest Microsoft SQL Serwer.
- Do określenia rodzajów blokad możemy posłużyć się zapytaniem:
WITH [Waits]
AS (SELECT wait_type, wait_time_ms/ 1000.0 AS [WaitS],
(wait_time_ms – signal_wait_time_ms) / 1000.0 AS [ResourceS],
signal_wait_time_ms / 1000.0 AS [SignalS],
waiting_tasks_count AS [WaitCount],
100.0 * wait_time_ms / SUM (wait_time_ms) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY wait_time_ms DESC) AS [RowNum]
FROM sys.dm_os_wait_stats WITH (NOLOCK)
WHERE [wait_type] NOT IN (
N’BROKER_EVENTHANDLER’, N’BROKER_RECEIVE_WAITFOR’, N’BROKER_TASK_STOP’,
N’BROKER_TO_FLUSH’, N’BROKER_TRANSMITTER’, N’CHECKPOINT_QUEUE’,
N’CHKPT’, N’CLR_AUTO_EVENT’, N’CLR_MANUAL_EVENT’, N’CLR_SEMAPHORE’,
N’DBMIRROR_DBM_EVENT’, N’DBMIRROR_EVENTS_QUEUE’, N’DBMIRROR_WORKER_QUEUE’,
N’DBMIRRORING_CMD’, N’DIRTY_PAGE_POLL’, N’DISPATCHER_QUEUE_SEMAPHORE’,
N’EXECSYNC’, N’FSAGENT’, N’FT_IFTS_SCHEDULER_IDLE_WAIT’, N’FT_IFTSHC_MUTEX’,
N’HADR_CLUSAPI_CALL’, N’HADR_FILESTREAM_IOMGR_IOCOMPLETION’, N’HADR_LOGCAPTURE_WAIT’,
N’HADR_NOTIFICATION_DEQUEUE’, N’HADR_TIMER_TASK’, N’HADR_WORK_QUEUE’,
N’KSOURCE_WAKEUP’, N’LAZYWRITER_SLEEP’, N’LOGMGR_QUEUE’,
N’MEMORY_ALLOCATION_EXT’, N’ONDEMAND_TASK_QUEUE’,
N’PARALLEL_REDO_DRAIN_WORKER’, N’PARALLEL_REDO_LOG_CACHE’, N’PARALLEL_REDO_TRAN_LIST’,
N’PARALLEL_REDO_WORKER_SYNC’, N’PARALLEL_REDO_WORKER_WAIT_WORK’,
N’PREEMPTIVE_HADR_LEASE_MECHANISM’, N’PREEMPTIVE_SP_SERVER_DIAGNOSTICS’,
N’PREEMPTIVE_OS_LIBRARYOPS’, N’PREEMPTIVE_OS_COMOPS’, N’PREEMPTIVE_OS_CRYPTOPS’,
N’PREEMPTIVE_OS_PIPEOPS’, N’PREEMPTIVE_OS_AUTHENTICATIONOPS’,
N’PREEMPTIVE_OS_GENERICOPS’, N’PREEMPTIVE_OS_VERIFYTRUST’,
N’PREEMPTIVE_OS_FILEOPS’, N’PREEMPTIVE_OS_DEVICEOPS’, N’PREEMPTIVE_OS_QUERYREGISTRY’,
N’PREEMPTIVE_OS_WRITEFILE’,
N’PREEMPTIVE_XE_CALLBACKEXECUTE’, N’PREEMPTIVE_XE_DISPATCHER’,
N’PREEMPTIVE_XE_GETTARGETSTATE’, N’PREEMPTIVE_XE_SESSIONCOMMIT’,
N’PREEMPTIVE_XE_TARGETINIT’, N’PREEMPTIVE_XE_TARGETFINALIZE’,
N’PWAIT_ALL_COMPONENTS_INITIALIZED’, N’PWAIT_DIRECTLOGCONSUMER_GETNEXT’,
N’QDS_PERSIST_TASK_MAIN_LOOP_SLEEP’,
N’QDS_ASYNC_QUEUE’,
N’QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP’, N’REQUEST_FOR_DEADLOCK_SEARCH’,
N’RESOURCE_QUEUE’, N’SERVER_IDLE_CHECK’, N’SLEEP_BPOOL_FLUSH’, N’SLEEP_DBSTARTUP’,
N’SLEEP_DCOMSTARTUP’, N’SLEEP_MASTERDBREADY’, N’SLEEP_MASTERMDREADY’,
N’SLEEP_MASTERUPGRADED’, N’SLEEP_MSDBSTARTUP’, N’SLEEP_SYSTEMTASK’, N’SLEEP_TASK’,
N’SLEEP_TEMPDBSTARTUP’, N’SNI_HTTP_ACCEPT’, N’SP_SERVER_DIAGNOSTICS_SLEEP’,
N’SQLTRACE_BUFFER_FLUSH’, N’SQLTRACE_INCREMENTAL_FLUSH_SLEEP’, N’SQLTRACE_WAIT_ENTRIES’,
N’WAIT_FOR_RESULTS’, N’WAITFOR’, N’WAITFOR_TASKSHUTDOWN’, N’WAIT_XTP_HOST_WAIT’,
N’WAIT_XTP_OFFLINE_CKPT_NEW_LOG’, N’WAIT_XTP_CKPT_CLOSE’, N’WAIT_XTP_RECOVERY’,
N’XE_BUFFERMGR_ALLPROCESSED_EVENT’, N’XE_DISPATCHER_JOIN’,
N’XE_DISPATCHER_WAIT’, N’XE_LIVE_TARGET_TVF’, N’XE_TIMER_EVENT’)
AND waiting_tasks_count > 0)
SELECT
MAX (W1.wait_type) AS [WaitType],
CAST (MAX (W1.Percentage) AS DECIMAL (5,2)) AS [Wait Percentage],
CAST ((MAX (W1.WaitS) / MAX (W1.WaitCount)) AS DECIMAL (16,4)) AS [AvgWait_Sec],
CAST ((MAX (W1.ResourceS) / MAX (W1.WaitCount)) AS DECIMAL (16,4)) AS [AvgRes_Sec],
CAST ((MAX (W1.SignalS) / MAX (W1.WaitCount)) AS DECIMAL (16,4)) AS [AvgSig_Sec],
CAST (MAX (W1.WaitS) AS DECIMAL (16,2)) AS [Wait_Sec],
CAST (MAX (W1.ResourceS) AS DECIMAL (16,2)) AS [Resource_Sec],
CAST (MAX (W1.SignalS) AS DECIMAL (16,2)) AS [Signal_Sec],
MAX (W1.WaitCount) AS [Wait Count]
FROM Waits AS W1
INNER JOIN Waits AS W2
ON W2.RowNum <= W1.RowNum
GROUP BY W1.RowNum, W1.wait_type
HAVING SUM (W2.Percentage) – MAX (W1.Percentage) < 99 — percentage threshold
Bazy danych
Konfiguracja
- Dla baz danych pod względem wydajności oraz bezpieczeństwa jest ich na macierzy w RAID 01/10. To rozwiązanie kosztowne ale zapewnia najlepszą wydajność oraz bezpieczeństwo danych. Łączy zalety RAID 1 orz 0. RAID 5/6 to rozwiązanie kompromisowe pomiędzy bezpieczeństwem i wydajności a ceną. Rozwiązanie dla mniejszych baz.
- Bazy danych, logi oraz buckupy powinny znajdować się na osobnych dyskach (systemach dyskowych). Jeśli nie jest to możliwe bazy oraz logi mogą znajdować się w tej samej lokalizacji. Dla bezpieczeństwa backupy powinny być umieszczone na osobnym systemie dyskowym, aby w razie awarii można było przywrócić funkcjonowanie bazy danych. Kopie baz warto również przenosić na zewnętrzne nośniki.
- Baza TempDB – baza systemowa odpowiedzialna w dużej mierze za wydajność systemów. Jeśli jest taka możliwość baza powinna znajdować się na najszybszym dysku (systemie dyskowym).
- Warto podzielić ją na pliki, nie więcej niż vCPU (maszyny wirtualne) CORE (maszyny fizyczne) na serwerze.
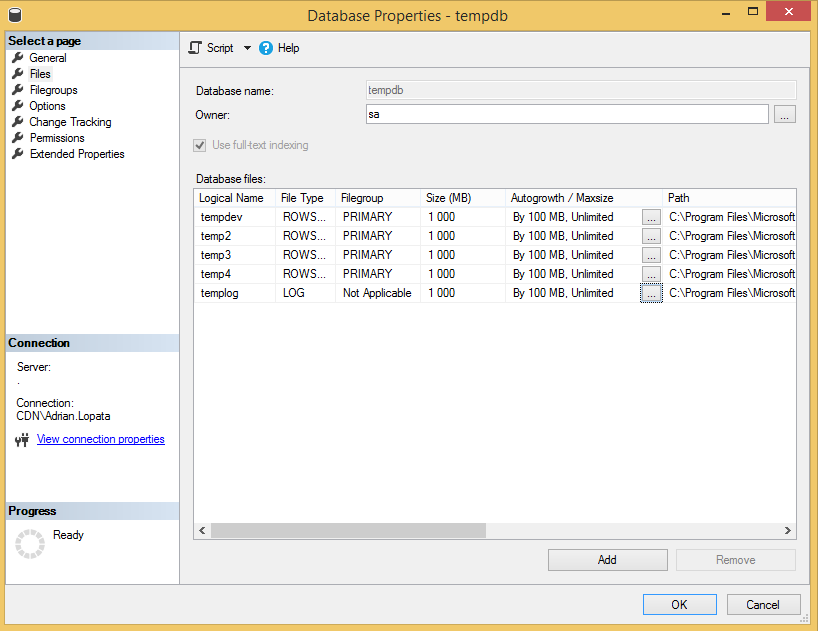
Przykładowe podzielenie plików. Ważne jest aby Size oraz autogrowth dla każdego Pliku miały takie same wartości.
Baza ta może znacznie się rozrosnąć przy dużych operacjach (np. odbudowa indeksów), więc należy jej zapewnić odpowiednią ilość miejsca.
Do wersji SQL 2014 włącznie po podziale baz na pliki należy ustawić flagi: T1117, T1118.
Serwisowanie bazy
Backupy
Backupy baz ich rodzaj i częstotliwość ustawia się zgodnie z oczekiwaniami Klienta. Rodzaje podstawowych kopii baz danych:
- Full – Kopia całej bazy danych, włącznie z procedurami funkcjami etc. Jeśli stosujemy inne rodzaje backupowania, to i tak co jakiś czas zaleca się wykonanie pełnej kopii bazy.
- Differential –Tworzenie kopii zapasowej tylko tych danych, które uległy zmianie od czasu ostatniej pełnej kopii zapasowej.
- Transaction log – backup loga bazy danych, log zawiera wszystkie informacje na temat operacji wykonanych na bazie danych (konieczne włączenie Recovery Model Full). Każda kolejna kopia zwiera informacje o zdarzeniach które wydarzyły się pomiędzy kolejnymi kopiami.
Aktualizacja statystyk oraz odbudowa indeksów
Od wersji 2016 SQL Server zmianie uległ algorytm dotyczący częstotliwości aktualizacji statystyk. W kolejnych wersjach działa on poprawnie. Jednak można w oknie serwisowym, po skończonej pracy przeprowadzić aktualizację statystyk, korzystając z Maintenance Plans lub wprowadzając do JOB’a polecenie T-SQL. Można również przeprowadzić reorganizacje największych i najbardziej pofragmentowanych indeksów (powyżej 2500 stron i stopień fragmentacji powyżej 5%).
Raz w tygodniu można wykonać reindeksację największych i najbardziej pofragmentowanych indeksów (2500 stron, stopień fragmentacji powyżej 50%).
Konfiguracja maszyn wirtualnych
W przypadku konfigurowania maszyn wirtualnych na serwerze, należy zwrócić uwagę na ilość przypisywanych gniazd procesorów dla wirtualnych CPU (vCPU).
Część wirtualizatorów dla jednego vCPU przypisuje pojedyncze gniazdo. W przypadku najnowszych wersji Microsoft SQL Server Standard maksymalna ilość obsługiwanych gniazd wynosi cztery.
 |
Przykład: Jeśli dla maszyny zostanie przypisanych 8 vCPU i 8 gniazd to SQL będzie wykorzystywał tylko 4 gniazda i 4 vCPU pozostałe cztery nie będą brały udziału w operacja wykonywanych na SQL Serwerze.
Dobrą praktyką jest przypisanie takiej ilości gniazd jaka znajduje się na maszynie fizycznej. Natomiast jeśli z jakiejś przyczyny zostanie przydzielona inna ilość to należy się stosować do założenia, że na 8 vCPU można przypisać jedno gniazdo (dla 16 vCPU – 2 gniazda itd.).a |



